Aangepaste spraak-naar-tekstcontainers met Docker
De aangepaste spraak-naar-tekstcontainer transcribeert realtime spraak- of batchaudio-opnamen met tussenliggende resultaten. U kunt een aangepast model gebruiken dat u hebt gemaakt in de aangepaste spraakportal. In dit artikel leert u hoe u een aangepaste spraak-naar-tekstcontainer downloadt, installeert en uitvoert.
Voor meer informatie over vereisten, valideren dat een container wordt uitgevoerd, meerdere containers op dezelfde host uitvoeren en niet-verbonden containers uitvoeren, raadpleegt u Speech-containers installeren en uitvoeren met Docker.
Containerinstallatiekopieën
De containerinstallatiekopie voor aangepaste spraak-naar-tekst voor alle ondersteunde versies en landinstellingen vindt u in het MCR-syndicat (Microsoft Container Registry). Deze bevindt zich in de azure-cognitive-services/speechservices/ opslagplaats en heeft de naam custom-speech-to-text.

De volledig gekwalificeerde containerinstallatiekopieënnaam is. mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text Voeg een specifieke versie toe of voeg toe :latest om de meest recente versie op te halen.
| Versie | Pad |
|---|---|
| Laatste | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest |
| 4.6.0 | mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:4.6.0-amd64 |
Alle tags, met uitzondering van latest, hebben de volgende indeling en zijn hoofdlettergevoelig:
<major>.<minor>.<patch>-<platform>-<prerelease>
Notitie
De locale en voice voor aangepaste spraak-naar-tekstcontainers wordt bepaald door het aangepaste model dat door de container is opgenomen.
De tags zijn ook beschikbaar in JSON-indeling voor uw gemak. De hoofdtekst bevat het containerpad en de lijst met tags. De tags worden niet gesorteerd op versie, maar "latest" worden altijd opgenomen aan het einde van de lijst, zoals wordt weergegeven in dit fragment:
{
"name": "azure-cognitive-services/speechservices/custom-speech-to-text",
"tags": [
"2.10.0-amd64",
"2.11.0-amd64",
"2.12.0-amd64",
"2.12.1-amd64",
<--redacted for brevity-->
"latest"
]
}
De containerinstallatiekopie ophalen met docker pull
U hebt de vereisten nodig, inclusief vereiste hardware. Zie ook de aanbevolen toewijzing van resources voor elke Speech-container.
Gebruik de opdracht docker pull om een containerinstallatiekopie te downloaden uit Microsoft Container Registry:
docker pull mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text:latest
Notitie
De locale en voice voor aangepaste Spraak-containers wordt bepaald door het aangepaste model dat door de container is opgenomen.
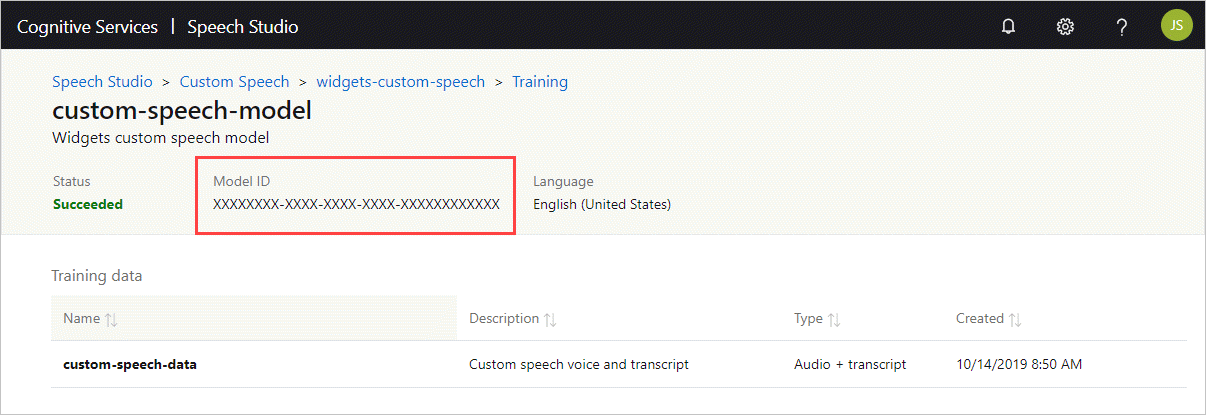
De model-id ophalen
Voordat u de container kunt uitvoeren , moet u de model-id van uw aangepaste model of een basismodel-id kennen. Wanneer u de container uitvoert, geeft u een van de model-id's op die u wilt downloaden en gebruiken.
Het aangepaste model moet worden getraind met behulp van Speech Studio. Zie de levenscyclus van het aangepaste spraakmodel voor informatie over het ophalen van de model-id.
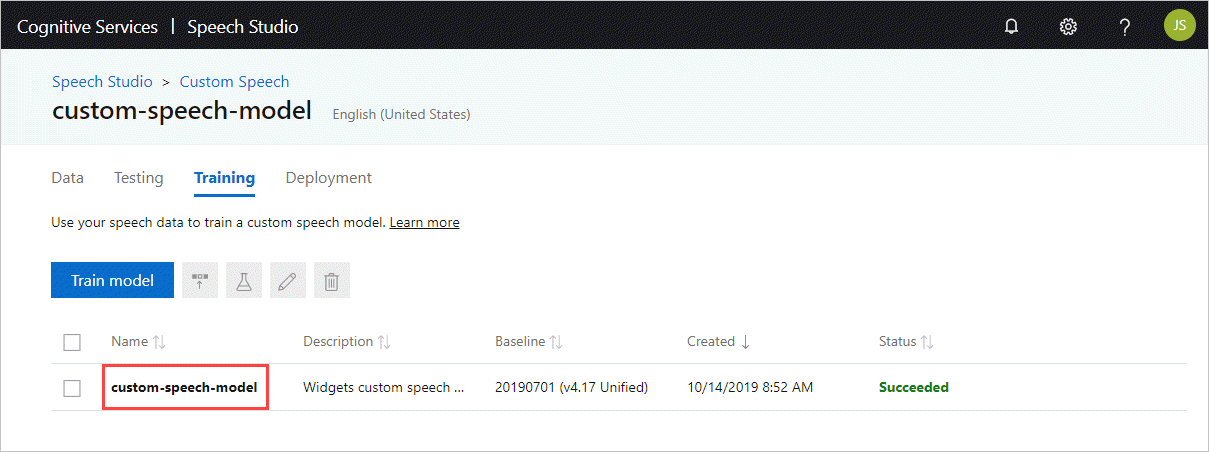
Haal de model-id op die moet worden gebruikt als het argument voor de ModelId parameter van de docker run opdracht.
Model downloaden weergeven
Voordat u de container uitvoert , kunt u desgewenst de beschikbare informatie over weergavemodellen ophalen en ervoor kiezen om deze modellen te downloaden in uw spraak-naar-tekstcontainer om de uiteindelijke uitvoer te verbeteren. Het downloaden van het weergavemodel is beschikbaar met containerversie 3.1.0 en hoger van custom-speech-to-text.
Notitie
Hoewel u de docker run opdracht gebruikt, wordt de container niet gestart voor de service.
U kunt een of meer van deze weergavemodeltypen opvragen of downloaden: Rescoring (Rescore), Interpunctie (Punct), hersegmentatie (Resegment) en wfstitn (Wfstitn). Anders kunt u de FullDisplay optie (met of zonder de andere typen) gebruiken om alle typen weergavemodellen op te vragen of te downloaden.
Stel de opdracht in BaseModelLocale om een query uit te voeren op het meest recente beschikbare weergavemodel op de doellandinstelling. Als u meerdere weergavemodeltypen opneemt, retourneert de opdracht de meest recente beschikbare weergavemodellen voor elk type. Voorbeeld:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
BaseModelLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Stel het DisplayLocale in om het meest recente beschikbare weergavemodel op de doellandinstelling te downloaden. Wanneer u instelt DisplayLocale, moet u ook een door spaties gescheiden subset van weergavemodellen opgeven FullDisplay . Met de opdracht wordt het meest recente beschikbare weergavemodel gedownload voor elk opgegeven type. Voorbeeld:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
Punct Rescore Resegment Wfstitn \ # Specify `FullDisplay` or a space-separated subset of display models
DisplayLocale={LOCALE} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Stel één model-id-parameter in om een specifiek weergavemodel te downloaden: Rescoring (RescoreId), Interpunctie (PunctId), hersegmentatie (ResegmentId) of wfstitn (WfstitnId). Dit is vergelijkbaar met hoe u een basismodel downloadt via de ModelId parameter. Als u bijvoorbeeld een weergavemodel voor het wijzigen van het formaat wilt downloaden, kunt u de volgende opdracht gebruiken met de RescoreId parameter:
docker run --rm -it \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
RescoreId={RESCORE_MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Notitie
Als u meer dan één query of downloadparameter instelt, krijgt de opdracht prioriteit in deze volgorde: BaseModelLocale, model-id en vervolgens DisplayLocale (alleen van toepassing op weergavemodellen).
De container uitvoeren met docker-uitvoering
Gebruik de opdracht docker run om de container voor de service uit te voeren.
De volgende tabel vertegenwoordigt de verschillende docker run parameters en de bijbehorende beschrijvingen:
| Parameter | Description |
|---|---|
{VOLUME_MOUNT} |
De hostcomputervolumekoppeling, die Docker gebruikt om het aangepaste model te behouden. Een voorbeeld is c:\CustomSpeech waar het c:\ station zich op de hostcomputer bevindt. |
{MODEL_ID} |
De aangepaste spraak- of basismodel-id. Zie De model-id ophalen voor meer informatie. |
{ENDPOINT_URI} |
Het eindpunt is vereist voor het meten en factureren. Zie factureringsargumenten voor meer informatie. |
{API_KEY} |
De API-sleutel is vereist. Zie factureringsargumenten voor meer informatie. |
Wanneer u de aangepaste spraak-naar-tekstcontainer uitvoert, configureert u de poort, het geheugen en de CPU op basis van de aangepaste spraak naar tekstcontainervereisten en aanbevelingen.
Hier volgt een voorbeeldopdracht docker run met tijdelijke aanduidingen. U moet de waarden en MODEL_IDENDPOINT_URIAPI_KEY waarden VOLUME_MOUNTopgeven:
docker run --rm -it -p 5000:5000 --memory 8g --cpus 4 \
-v {VOLUME_MOUNT}:/usr/local/models \
mcr.microsoft.com/azure-cognitive-services/speechservices/custom-speech-to-text \
ModelId={MODEL_ID} \
Eula=accept \
Billing={ENDPOINT_URI} \
ApiKey={API_KEY}
Met deze opdracht gebeurt het volgende:
- Voert een aangepaste spraak-naar-tekstcontainer uit vanuit de containerinstallatiekopie.
- Wijst 4 CPU-kernen en 8 GB geheugen toe.
- Laadt de aangepaste spraak naar het tekstmodel van de volumeinvoerkoppeling, bijvoorbeeld C:\CustomSpeech.
- Maakt TCP-poort 5000 beschikbaar en wijst een pseudo-TTY toe voor de container.
- Downloadt het model op basis van de
ModelId(indien niet gevonden op de volumekoppeling). - Als het aangepaste model eerder is gedownload, wordt het
ModelIdgenegeerd. - Hiermee wordt de container automatisch verwijderd nadat deze is afgesloten. De containerinstallatiekopie is nog steeds beschikbaar op de hostcomputer.
Zie Speech-containers installeren en uitvoeren met Docker voor meer informatie over docker run spraakcontainers.
De container gebruiken
Spraakcontainers bieden websocket-api's voor query-eindpunten die toegankelijk zijn via de Speech SDK en Speech CLI. De Speech SDK en Speech CLI maken standaard gebruik van de openbare Speech-service. Als u de container wilt gebruiken, moet u de initialisatiemethode wijzigen.
Belangrijk
Wanneer u de Speech-service met containers gebruikt, moet u hostverificatie gebruiken. Als u de sleutel en regio configureert, worden aanvragen naar de openbare Spraak-service verzonden. Resultaten van de Speech-service zijn mogelijk niet wat u verwacht. Aanvragen van niet-verbonden containers mislukken.
In plaats van deze azure-cloud-initialisatieconfiguratie te gebruiken:
var config = SpeechConfig.FromSubscription(...);
Gebruik deze configuratie met de containerhost:
var config = SpeechConfig.FromHost(
new Uri("ws://localhost:5000"));
In plaats van deze azure-cloud-initialisatieconfiguratie te gebruiken:
auto speechConfig = SpeechConfig::FromSubscription(...);
Gebruik deze configuratie met de containerhost:
auto speechConfig = SpeechConfig::FromHost("ws://localhost:5000");
In plaats van deze azure-cloud-initialisatieconfiguratie te gebruiken:
speechConfig, err := speech.NewSpeechConfigFromSubscription(...)
Gebruik deze configuratie met de containerhost:
speechConfig, err := speech.NewSpeechConfigFromHost("ws://localhost:5000")
In plaats van deze azure-cloud-initialisatieconfiguratie te gebruiken:
SpeechConfig speechConfig = SpeechConfig.fromSubscription(...);
Gebruik deze configuratie met de containerhost:
SpeechConfig speechConfig = SpeechConfig.fromHost("ws://localhost:5000");
In plaats van deze azure-cloud-initialisatieconfiguratie te gebruiken:
const speechConfig = sdk.SpeechConfig.fromSubscription(...);
Gebruik deze configuratie met de containerhost:
const speechConfig = sdk.SpeechConfig.fromHost("ws://localhost:5000");
In plaats van deze azure-cloud-initialisatieconfiguratie te gebruiken:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithSubscription:...];
Gebruik deze configuratie met de containerhost:
SPXSpeechConfiguration *speechConfig = [[SPXSpeechConfiguration alloc] initWithHost:"ws://localhost:5000"];
In plaats van deze azure-cloud-initialisatieconfiguratie te gebruiken:
let speechConfig = SPXSpeechConfiguration(subscription: "", region: "");
Gebruik deze configuratie met de containerhost:
let speechConfig = SPXSpeechConfiguration(host: "ws://localhost:5000");
In plaats van deze azure-cloud-initialisatieconfiguratie te gebruiken:
speech_config = speechsdk.SpeechConfig(
subscription=speech_key, region=service_region)
Gebruik deze configuratie met het containereindpunt:
speech_config = speechsdk.SpeechConfig(
host="ws://localhost:5000")
Wanneer u de Speech CLI in een container gebruikt, neemt u de --host ws://localhost:5000/ optie op. U moet ook opgeven --key none om ervoor te zorgen dat de CLI geen spraaksleutel probeert te gebruiken voor verificatie. Zie Aan de slag met de Azure AI Speech CLI voor informatie over het configureren van de Speech CLI.
Probeer de snelstart voor spraak-naar-tekst met behulp van hostverificatie in plaats van sleutel en regio.
Volgende stappen
- Zie het overzicht van Spraakcontainers
- Configureer containers voor configuratie-instellingen controleren
- Meer Azure AI-containers gebruiken