Gegevens migreren van Cassandra naar een Azure Cosmos DB voor Apache Cassandra-account met behulp van Azure Databricks
VAN TOEPASSING OP:![]() Cassandra
Cassandra
API voor Cassandra in Azure Cosmos DB is om verschillende redenen een uitstekende keuze geworden voor zakelijke workloads die worden uitgevoerd op Apache Cassandra:
Geen overhead voor beheer en bewaking: Het elimineert de overhead van het beheren en bewaken van instellingen voor besturingssysteem-, JVM- en YAML-bestanden en hun interacties.
Aanzienlijke kostenbesparingen: U kunt kosten besparen met De Azure Cosmos DB, waaronder de kosten van VM's, bandbreedte en eventuele toepasselijke licenties. U hoeft geen datacentra, servers, SSD-opslag, netwerk- en elektriciteitskosten te beheren.
Mogelijkheid om bestaande code en hulpprogramma's te gebruiken: Azure Cosmos DB biedt compatibiliteit op wire-protocolniveau met bestaande Cassandra-SDK's en hulpprogramma's. Deze compatibiliteit zorgt ervoor dat u uw bestaande codebasis kunt gebruiken met de Azure Cosmos DB voor Apache Cassandra met triviale wijzigingen.
Er zijn veel manieren om databaseworkloads van het ene platform naar het andere te migreren. Azure Databricks is een PaaS-aanbieding (Platform as a Service) voor Apache Spark die een manier biedt om offlinemigraties op grote schaal uit te voeren. In dit artikel worden de stappen beschreven die nodig zijn voor het migreren van gegevens van systeemeigen Apache Cassandra-keyspaces en -tabellen naar Azure Cosmos DB voor Apache Cassandra met behulp van Azure Databricks.
Vereisten
Een Azure Cosmos DB inrichten voor Apache Cassandra-account.
Bekijk de basisbeginselen van het maken van verbinding met een Azure Cosmos DB voor Apache Cassandra.
Bekijk de ondersteunde functies in Azure Cosmos DB voor Apache Cassandra om compatibiliteit te garanderen.
Zorg ervoor dat u al lege keyspaces en tabellen hebt gemaakt in uw Azure Cosmos DB-doelaccount voor Apache Cassandra.
Een Azure Databricks-cluster inrichten
U kunt de instructies volgen voor het inrichten van een Azure Databricks-cluster. We raden u aan Databricks-runtimeversie 7.5 te selecteren, die ondersteuning biedt voor Spark 3.0.
Afhankelijkheden toevoegen
U moet de Apache Spark Cassandra Connector-bibliotheek toevoegen aan uw cluster om verbinding te maken met zowel systeemeigen als Azure Cosmos DB Cassandra-eindpunten. Selecteer in uw cluster Bibliotheken>Nieuwe>Maven installeren en voeg vervolgens Maven-coördinaten toe com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 .
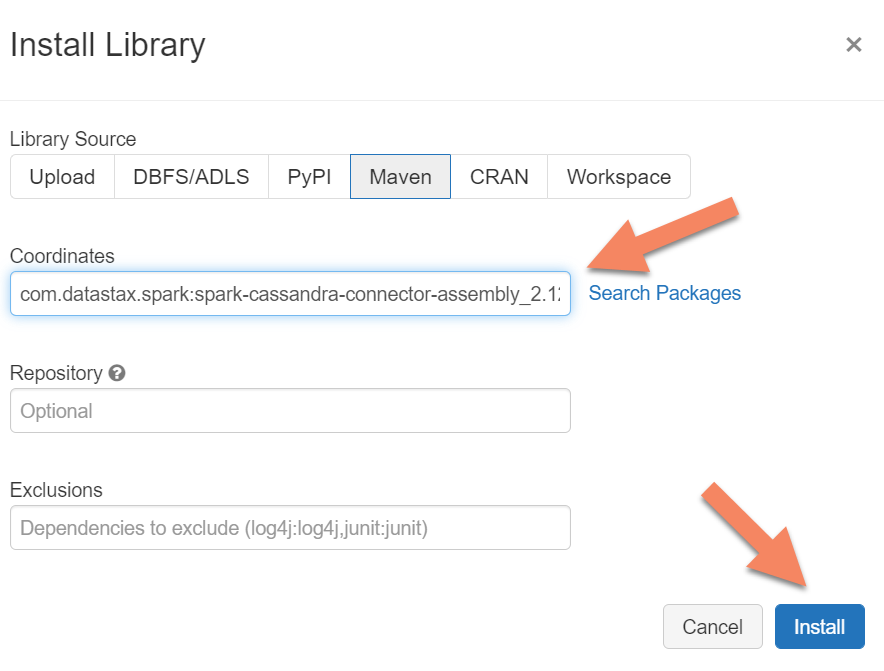
Selecteer Installeren en start het cluster opnieuw wanneer de installatie is voltooid.
Notitie
Zorg ervoor dat u het Databricks-cluster opnieuw start nadat de Cassandra Connector-bibliotheek is geïnstalleerd.
Waarschuwing
De voorbeelden in dit artikel zijn getest met Spark-versie 3.0.1 en de bijbehorende Cassandra Spark Connector com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0. Latere versies van Spark en/of de Cassandra-connector werken mogelijk niet zoals verwacht.
Scala Notebook maken voor migratie
Maak een Scala Notebook in Databricks. Vervang uw cassandra-bron- en doelconfiguraties door de bijbehorende referenties, en bron- en doelsleutelruimten en -tabellen. Voer vervolgens de volgende code uit:
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val nativeCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val cosmosCassandra = Map(
"spark.cassandra.connection.host" -> "<USERNAME>.cassandra.cosmos.azure.com",
"spark.cassandra.connection.port" -> "10350",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
//"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1", // Spark 3.x
"spark.cassandra.connection.connections_per_executor_max"-> "1", // Spark 2.x
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from native Cassandra
val DFfromNativeCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(nativeCassandra)
.load
//Write to CosmosCassandra
DFfromNativeCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(cosmosCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Notitie
De spark.cassandra.output.batch.size.rows waarden en spark.cassandra.output.concurrent.writes het aantal werkrollen in uw Spark-cluster zijn belangrijke configuraties die u kunt afstemmen om snelheidsbeperking te voorkomen. Snelheidsbeperking treedt op wanneer aanvragen voor Azure Cosmos DB de ingerichte doorvoer of aanvraageenheden (RU's) overschrijden. Mogelijk moet u deze instellingen aanpassen, afhankelijk van het aantal uitvoerders in het Spark-cluster en mogelijk de grootte (en dus de RU-kosten) van elke record die naar de doeltabellen wordt geschreven.
Problemen oplossen
Snelheidsbeperking (fout 429)
Mogelijk ziet u een 429-foutcode of 'aanvraagsnelheid is groot', zelfs als u de instellingen hebt teruggebracht tot de minimumwaarden. De volgende scenario's kunnen snelheidsbeperking veroorzaken:
De aan de tabel toegewezen doorvoer is minder dan 6000 aanvraageenheden. Zelfs bij minimale instellingen kan Spark schrijven met een snelheid van ongeveer 6000 aanvraageenheden of meer. Als u een tabel in een keyspace met gedeelde doorvoer hebt ingericht, is het mogelijk dat deze tabel minder dan 6000 RU's beschikbaar heeft tijdens runtime.
Zorg ervoor dat de tabel waarnaar u migreert ten minste 6000 RU's beschikbaar heeft wanneer u de migratie uitvoert. Wijs indien nodig toegewezen aanvraageenheden toe aan die tabel.
Overmatige scheeftrekken van gegevens met een groot gegevensvolume. Als u een grote hoeveelheid gegevens naar een bepaalde tabel wilt migreren, maar een aanzienlijke scheefheid in de gegevens hebt (dat wil gezegd dat er een groot aantal records wordt geschreven voor dezelfde partitiesleutelwaarde), kunt u nog steeds last hebben van snelheidsbeperking, zelfs als er meerdere aanvraageenheden in uw tabel zijn ingericht. Aanvraageenheden worden gelijkmatig verdeeld over fysieke partities en scheeftrekken van zware gegevens kunnen een knelpunt van aanvragen naar één partitie veroorzaken.
In dit scenario vermindert u de doorvoerinstellingen tot een minimum in Spark en dwingt u af dat de migratie langzaam wordt uitgevoerd. Dit scenario kan vaker voorkomen wanneer u referentie- of besturingstabellen migreert, waarbij de toegang minder vaak voorkomt en de scheefheid hoog kan zijn. Als er echter een aanzienlijke scheefheid aanwezig is in een ander type tabel, kunt u het gegevensmodel controleren om dynamische partitieproblemen voor uw workload te voorkomen tijdens steady-state-bewerkingen.