Gegevens migreren van MongoDB naar een Azure Cosmos DB voor MongoDB-account met behulp van Azure Databricks
VAN TOEPASSING OP: ![]() MongoDB
MongoDB
Deze migratiehandleiding maakt deel uit van de reeksen over het migreren van databases van MongoDB naar de Azure Cosmos DB-API voor MongoDB. De kritieke migratiestappen zijn vóór de migratie, migratie en na de migratie, zoals hieronder wordt weergegeven.
Gegevensmigratie met Behulp van Azure Databricks
Azure Databricks is een PaaS-aanbieding (Platform as a Service) voor Apache Spark. Het biedt een manier om offlinemigraties uit te voeren op een grootschalige gegevensset. U kunt Azure Databricks gebruiken om een offlinemigratie van databases van MongoDB naar Azure Cosmos DB voor MongoDB uit te voeren.
In deze zelfstudie leert u het volgende:
Een Azure Databricks-cluster inrichten
Afhankelijkheden toevoegen
Scala- of Python-notebook maken en uitvoeren
De migratieprestaties optimaliseren
Problemen met snelheidsbeperking oplossen die kunnen worden waargenomen tijdens de migratie
Vereisten
Voor het voltooien van deze zelfstudie hebt u het volgende nodig:
- Voltooi de stappen vóór de migratie , zoals het schatten van doorvoer en het kiezen van een shardsleutel.
- Maak een Azure Cosmos DB voor MongoDB-account.
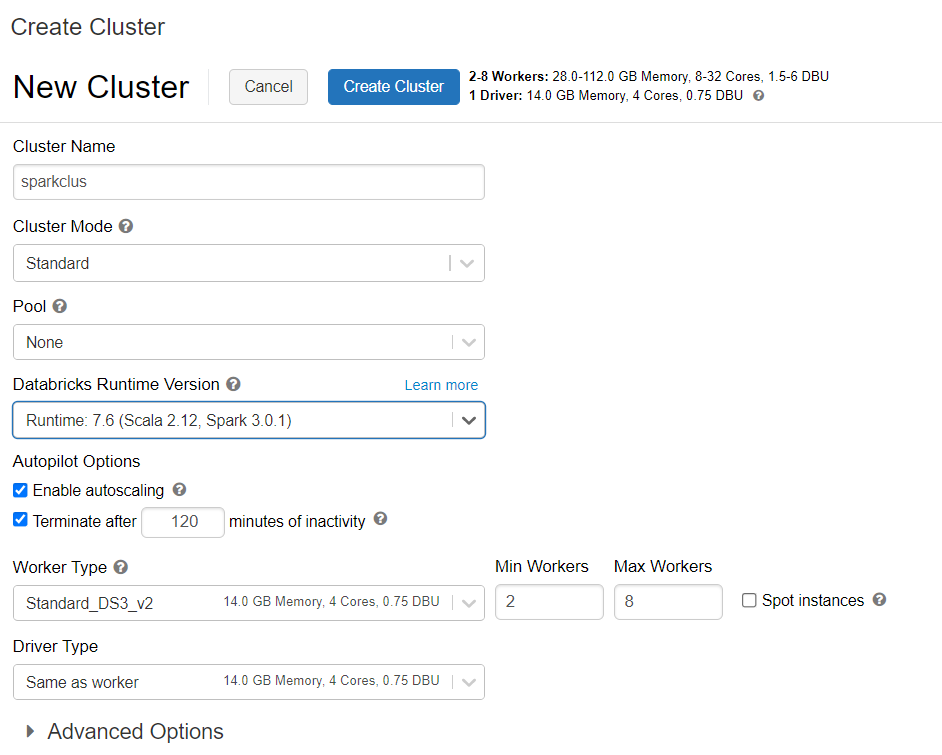
Een Azure Databricks-cluster inrichten
U kunt de instructies volgen voor het inrichten van een Azure Databricks-cluster. U wordt aangeraden Databricks Runtime versie 7.6 te selecteren, die ondersteuning biedt voor Spark 3.0.
Afhankelijkheden toevoegen
Voeg de MongoDB-Verbinding maken or voor Spark-bibliotheek toe aan uw cluster om verbinding te maken met zowel systeemeigen MongoDB- als Azure Cosmos DB voor MongoDB-eindpunten. Selecteer In uw cluster Bibliotheken>installeren nieuwe>Maven en voeg vervolgens Maven-coördinaten toe.org.mongodb.spark:mongo-spark-connector_2.12:3.0.1
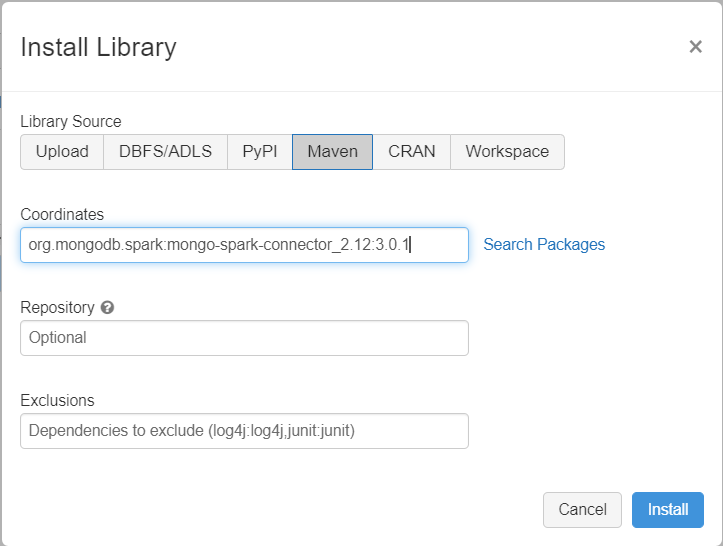
Selecteer Installeren en start het cluster opnieuw wanneer de installatie is voltooid.
Notitie
Zorg ervoor dat u het Databricks-cluster opnieuw start nadat de MongoDB-Verbinding maken or voor de Spark-bibliotheek is geïnstalleerd.
Daarna kunt u een Scala- of Python-notebook maken voor migratie.
Scala-notebook maken voor migratie
Maak een Scala Notebook in Databricks. Zorg ervoor dat u de juiste waarden voor de variabelen invoert voordat u de volgende code uitvoert:
import com.mongodb.spark._
import com.mongodb.spark.config._
import org.apache.spark._
import org.apache.spark.sql._
var sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
var sourceDb = "<DB NAME>"
var sourceCollection = "<COLLECTIONNAME>"
var targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
var targetDb = "<DB NAME>"
var targetCollection = "<COLLECTIONNAME>"
val readConfig = ReadConfig(Map(
"spark.mongodb.input.uri" -> sourceConnectionString,
"spark.mongodb.input.database" -> sourceDb,
"spark.mongodb.input.collection" -> sourceCollection,
))
val writeConfig = WriteConfig(Map(
"spark.mongodb.output.uri" -> targetConnectionString,
"spark.mongodb.output.database" -> targetDb,
"spark.mongodb.output.collection" -> targetCollection,
"spark.mongodb.output.maxBatchSize" -> "8000"
))
val sparkSession = SparkSession
.builder()
.appName("Data transfer using spark")
.getOrCreate()
val customRdd = MongoSpark.load(sparkSession, readConfig)
MongoSpark.save(customRdd, writeConfig)
Python-notebook maken voor migratie
Maak een Python-notebook in Databricks. Zorg ervoor dat u de juiste waarden voor de variabelen invoert voordat u de volgende code uitvoert:
from pyspark.sql import SparkSession
sourceConnectionString = "mongodb://<USERNAME>:<PASSWORD>@<HOST>:<PORT>/<AUTHDB>"
sourceDb = "<DB NAME>"
sourceCollection = "<COLLECTIONNAME>"
targetConnectionString = "mongodb://<ACCOUNTNAME>:<PASSWORD>@<ACCOUNTNAME>.mongo.cosmos.azure.com:10255/?ssl=true&replicaSet=globaldb&retrywrites=false&maxIdleTimeMS=120000&appName=@<ACCOUNTNAME>@"
targetDb = "<DB NAME>"
targetCollection = "<COLLECTIONNAME>"
my_spark = SparkSession \
.builder \
.appName("myApp") \
.getOrCreate()
df = my_spark.read.format("com.mongodb.spark.sql.DefaultSource").option("uri", sourceConnectionString).option("database", sourceDb).option("collection", sourceCollection).load()
df.write.format("mongo").mode("append").option("uri", targetConnectionString).option("maxBatchSize",2500).option("database", targetDb).option("collection", targetCollection).save()
De migratieprestaties optimaliseren
De migratieprestaties kunnen worden aangepast via deze configuraties:
Aantal werkrollen en kernen in het Spark-cluster: Meer werkrollen betekenen meer rekenhards voor het uitvoeren van taken.
maxBatchSize: De
maxBatchSizewaarde bepaalt de snelheid waarmee gegevens worden opgeslagen in de Azure Cosmos DB-doelverzameling. Als de maxBatchSize echter te hoog is voor de doorvoer van de verzameling, kan dit fouten veroorzaken bij het beperken van frequenties .U moet het aantal werkrollen en maxBatchSize aanpassen, afhankelijk van het aantal uitvoerders in het Spark-cluster, mogelijk de grootte (en daarom de RU-kosten) van elk document dat wordt geschreven en de doorvoerlimieten voor de doelverzameling.
Tip
maxBatchSize = Verzamelingsdoorvoer / ( RU-kosten voor 1 document * aantal Spark-werkrollen * aantal CPU-kernen per werkrol )
MongoDB Spark-partitioner en partitionKey: De standaardpartitioner die wordt gebruikt, is MongoDefaultPartitioner en de standaardpartitiesleutel is _id. Partitioner kan worden gewijzigd door waarde
MongoSamplePartitionertoe te wijzen aan de eigenschap invoerconfiguratiespark.mongodb.input.partitioner. Op dezelfde manier kan partitionKey worden gewijzigd door de juiste veldnaam toe te wijzen aan de invoerconfiguratie-eigenschapspark.mongodb.input.partitioner.partitionKey. Met de juiste partitionKey kunt u voorkomen dat gegevens scheeftrekken (een groot aantal records dat wordt geschreven voor dezelfde shardsleutelwaarde).Schakel indexen uit tijdens gegevensoverdracht: Voor grote hoeveelheden gegevensmigratie kunt u overwegen om indexen uit te schakelen, met speciale jokertekens voor de doelverzameling. Indexen verhogen de RU-kosten voor het schrijven van elk document. Het vrijmaken van deze RU's kan helpen de gegevensoverdrachtsnelheid te verbeteren. U kunt de indexen inschakelen zodra de gegevens zijn gemigreerd.
Problemen oplossen
Time-outfout (foutcode 50)
Mogelijk ziet u een 50-foutcode voor bewerkingen in de Azure Cosmos DB voor MongoDB-database. De volgende scenario's kunnen time-outfouten veroorzaken:
- De toegewezen doorvoer aan de database is laag: zorg ervoor dat aan de doelverzameling voldoende doorvoer is toegewezen.
- Overmatige scheeftrekken van gegevens met een groot gegevensvolume. Als u een grote hoeveelheid gegevens hebt om naar een bepaalde tabel te migreren, maar een aanzienlijke scheefheid in de gegevens heeft, kunt u nog steeds een snelheidsbeperking ervaren, zelfs als u meerdere aanvraageenheden hebt ingericht in uw tabel. Aanvraageenheden worden gelijkmatig verdeeld over fysieke partities en zware gegevensverschil kan een knelpunt van aanvragen tot één shard veroorzaken. Scheeftrekken van gegevens betekent een groot aantal records voor dezelfde shardsleutelwaarde.
Snelheidsbeperking (foutcode 16500)
Mogelijk ziet u een foutcode van 16500 voor bewerkingen in de Azure Cosmos DB voor MongoDB-database. Dit zijn frequentiebeperkingsfouten en kunnen worden waargenomen op oudere accounts of accounts waarbij de functie voor opnieuw proberen aan de serverzijde is uitgeschakeld.
- Schakel nieuwe pogingen aan de serverzijde in: schakel de SSR-functie (Server Side Retry) in en laat de server de frequentielimiet automatisch opnieuw proberen.
Optimalisatie na migratie
Nadat u de gegevens hebt gemigreerd, kunt u verbinding maken met Azure Cosmos DB en de gegevens beheren. U kunt ook andere stappen na de migratie volgen, zoals het indexeringsbeleid optimaliseren, het standaardconsistentieniveau bijwerken of globale distributie configureren voor uw Azure Cosmos DB-account. Zie het artikel Optimalisatie na migratie voor meer informatie.
Aanvullende bronnen
- Wilt u capaciteitsplanning uitvoeren voor een migratie naar Azure Cosmos DB?
- Als alles wat u weet het aantal vcores en servers in uw bestaande databasecluster is, leest u meer over het schatten van aanvraageenheden met behulp van vCores of vCPU's
- Als u typische aanvraagtarieven voor uw huidige databaseworkload kent, leest u meer over het schatten van aanvraageenheden met behulp van azure Cosmos DB-capaciteitsplanner