Statuscontroles
CycleCloud biedt twee mechanismen voor het controleren van de status van VM's: Statuscontroles van knooppunten is een nieuwere functie die de controles uitvoert tijdens de inrichtingsfase en voorkomt dat de beschadigde VM's worden toegevoegd, terwijl HealthCheck deze periodiek uitvoert nadat de VM als een knooppunt aan het cluster is toegevoegd.
Statuscontroles van knooppunten
Statuscontroles voor knooppunten kunnen beschadigde hardware detecteren voordat een VM lid mag worden van een CycleCloud-cluster. Met de huidige versie van deze functie worden statuscontrolescripts uitgevoerd die zijn ingebouwd in de officiële AzureHPC-installatiekopieën die u kunt vinden onder /opt/azurehpc/test/azurehpc-health-checks/. De bron voor deze scripts bevindt zich in de opslagplaats AzureHPC Node Health Checks, maar houd er rekening mee dat de versie die is ingebouwd in de versie van de AzureHPC-installatiekopie van uw cluster mogelijk niet de meest recente versie is die beschikbaar is in de opslagplaats.
Vereisten
De huidige versie van Node Health Checks ondersteunt alleen AzureHPC-installatiekopieën die zijn uitgebracht na 7 november 2023 (met azurehpc-health-checks versie v2.0.6 of hoger) en aangepaste installatiekopieën die hiervan zijn afgeleid. Statuscontroles van knooppunten worden momenteel niet ondersteund in Windows.
Statuscontroles van knooppunten voor Slurm-clusters inschakelen
Het formulier voor het maken van een Slurm-cluster biedt een selectievakje om statuscontroles van knooppunten op het tabblad Geavanceerde instellingen in te schakelen. Als u het selectievakje inschakelt, worden statuscontroles van knooppunten ingeschakeld voor de HPC-knooppuntmatrix van het cluster. Als u statuscontroles van knooppunten wilt inschakelen voor andere knooppuntmatrices (of voor andere clustertypen), moet u een aangepaste clustersjabloon gebruiken.
Statuscontroles van knooppunten kunnen worden uitgeschakeld in een actief cluster door het selectievakje uit te schakelen. U hoeft de knooppuntmatrix niet omlaag te schalen om de wijzigingen door te voeren.
Inzicht in de resultaten van knooppuntstatuscontroles
Nadat een VM de statuscontroles heeft doorgegeven, gaat deze verder met de softwareconfiguratiefase.
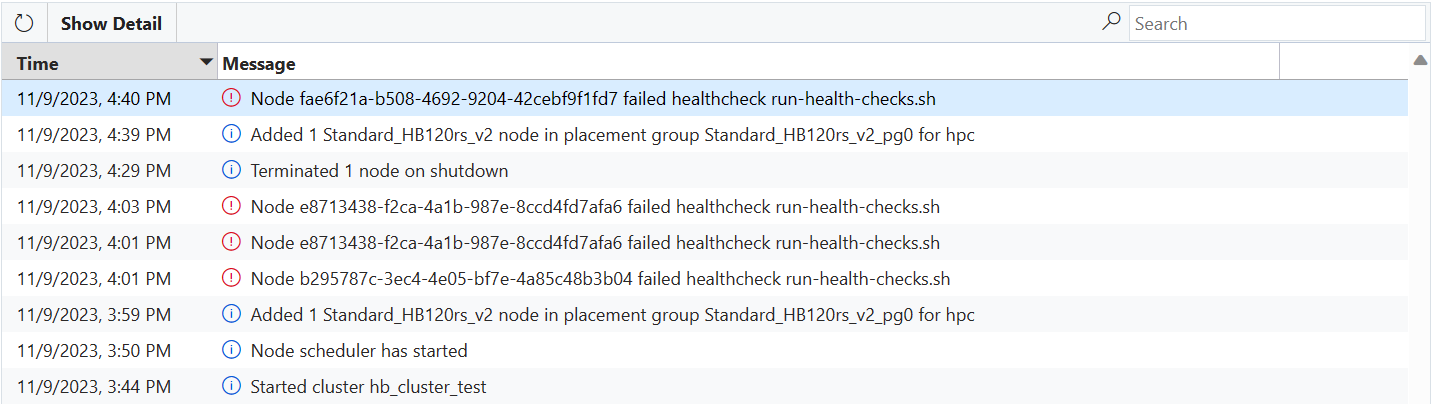
Als een vm een van de statuscontrolescripts mislukt, wordt er een foutbericht verzonden naar CycleCloud en wordt automatisch voorkomen dat de VM lid kan worden van het cluster.
Als de VM is gestart in een NodeArray met over-inrichting ingeschakeld (bijvoorbeeld de Slurm hpc Node Array), moet de VM automatisch worden vervangen als onderdeel van over-inrichting. In dat geval is er geen actie vereist en worden de vm's met een goede status geselecteerd om lid te worden van het cluster (hoewel u een foutbericht ziet op de clusterpagina dat aangeeft dat een of meer VM's controles zijn mislukt).
Als de VM wordt gestart voor één knooppunt, een knooppuntmatrix waarvoor over-inrichting is uitgeschakeld (bijvoorbeeld de Slurm htc Node Array), of als meer VM's de statuscontroles mislukken dan wordt ondersteund door over-inrichting, wordt het knooppunt verplaatst naar de status Mislukt en mislukt de toewijzing. CycleCloud kan proberen een nieuwe installatiekop up van de VM te maken om het probleem op te lossen, maar als het opnieuw instellen van de installatiekopieën mislukt, moet het knooppunt worden beëindigd en vervangen (handmatig door een beheerder of automatisch door de automatische schaalaanpassing).
Notitie
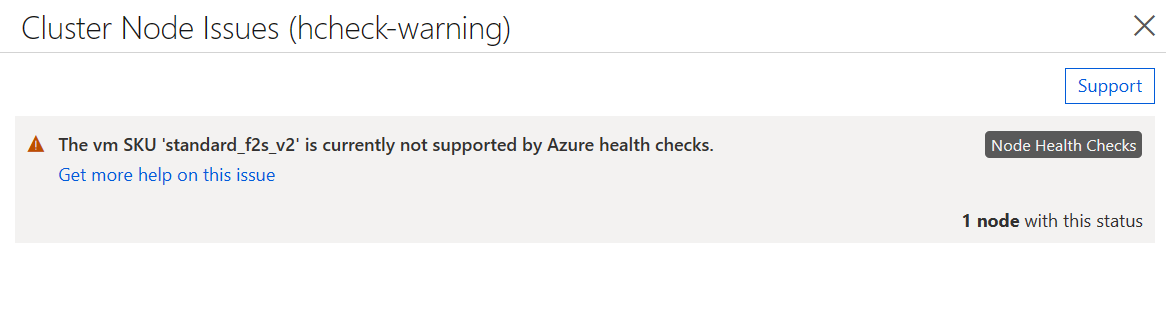
Als u Statuscontroles van knooppunten hebt ingeschakeld, maar de VM-installatiekopieën niet voldoen aan de bovenstaande vereisten, mogen alle VM's lid worden van het cluster, maar bevat de status een waarschuwing die aangeeft dat controles niet worden ondersteund.
Kenmerkreferentie
| Kenmerk | Type | Definitie |
|---|---|---|
| EnableNodeHealthChecks | Booleaans | (Optioneel) Statuscontroles van knooppunten bij opstarten inschakelen voor dit knooppunt of dit knooppuntmatrix |
Statuscontrole
Azure CycleCloud biedt een mechanisme voor het beëindigen van virtuele machines (VM's) met een slechte status met de naam HealthCheck. Zowel door het systeem als door de gebruiker gedefinieerde scripts (Python en Bash) worden periodiek uitgevoerd (5 minuten in Windows, 10 minuten in Linux) om de algehele status van een VM te bepalen. Met HealthCheck kunnen beheerders voorwaarden definiëren waaronder VM's moeten worden beëindigd zonder handmatig te hoeven controleren en herstellen.
Ingebouwde HealthCheck-scripts
Vm's met CycleCloud worden geleverd met twee standaard HealthCheck-scripts:
- Het converge_timeout script beëindigt een exemplaar dat de softwareconfiguratie niet binnen vier uur na het starten heeft voltooid. Deze time-outperiode kan worden bepaald met de
cyclecloud.keepalive.timeoutinstelling (gedefinieerd in seconden). - Het scheduled_shutdown-script zoekt naar makerbestanden in $JETPACK_HOME/run/scheduled_shutdown die één regel bevatten die een afsluittijd in Unix-tijdstempelseconden en een optionele tweede regel met een uitleg bevat. Wanneer de huidige tijd later is dan de vroegste tijdstempel in de bestanden, wordt de VM als beschadigd beschouwd.
Uitleg
De HealthCheck-scripts bevinden zich in de map $JETPACK_HOME/config/healthcheck.d . Linux ondersteunt zowel Python- als Bash-scripts, terwijl Windows alleen Python-scripts ondersteunt. Het script moet de status van de VM bepalen. Als wordt vastgesteld dat de VM niet in orde is, moet het script worden afgesloten met de status 254, die voor CycleCloud aangeeft dat de VM niet in orde is en moet worden beëindigd.
Wanneer u bent aangemeld bij een VM waarop HealthCheck wordt uitgevoerd, kunt u voorkomen dat de VM wordt afgesloten door de opdracht jetpack keepalive uit te voeren. Op Linux-exemplaren kunt u een tijdsbestek opgeven in uren of forever terwijl u Windows forever gebruikt, is de enige optie.
Notitie
Wanneer wordt vastgesteld dat een VM niet in orde is, doet de HealthCheck-agent een aanvraag voor CycleCloud om de VM te beëindigen. De VM wordt nooit lokaal afgesloten via shutdown de opdracht . In het geval dat de VM niet kan communiceren met CycleCloud, blijft de VM actief, ook al is deze beschadigd totdat CycleCloud kan worden bereikt.
Voorbeeld
Als eenvoudig voorbeeld schrijven we een HealthCheck-script dat ervoor zorgt dat een Virtuele Linux-machine langer dan 24 uur niet actief is. Dit script kan worden gebruikt om verwijderingen met lage prioriteit te simuleren om te testen hoe een werkstroom reageert op een verwijderde VM. Dit script wordt geplaatst in /opt/cycle/jetpack/config/healthcheck.d/healthcheck_example.sh
#!/bin/bash
# Get the uptime of the system (in seconds) and check to see if it is
# greater than 86,400 (24 hours in seconds). If it is, exit 254 to
# signal that the VM is unhealthy.
if (( $(cat /proc/uptime | awk '{print ($1 > 86400)}'))); then
exit 254
fi
Notitie
Dit script kan op een VM worden geplaatst via CycleCloud Project of door het rechtstreeks toe te voegen bij het maken van een aangepaste installatiekopieën.