functies voor prestatieoptimalisatie Copy-activiteit
VAN TOEPASSING OP: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tip
Probeer Data Factory uit in Microsoft Fabric, een alles-in-één analyseoplossing voor ondernemingen. Microsoft Fabric omvat alles, van gegevensverplaatsing tot gegevenswetenschap, realtime analyses, business intelligence en rapportage. Meer informatie over het gratis starten van een nieuwe proefversie .
In dit artikel vindt u een overzicht van de functies voor het optimaliseren van de prestaties van kopieeractiviteiten die u kunt gebruiken in Azure Data Factory- en Synapse-pijplijnen.
Prestatiefuncties configureren met de gebruikersinterface
Wanneer u een Copy-activiteit selecteert op het canvas van de pijplijneditor en het tabblad Instellingen in het activiteitenconfiguratiegebied onder het canvas kiest, ziet u opties voor het configureren van alle prestatiefuncties die hieronder worden beschreven.
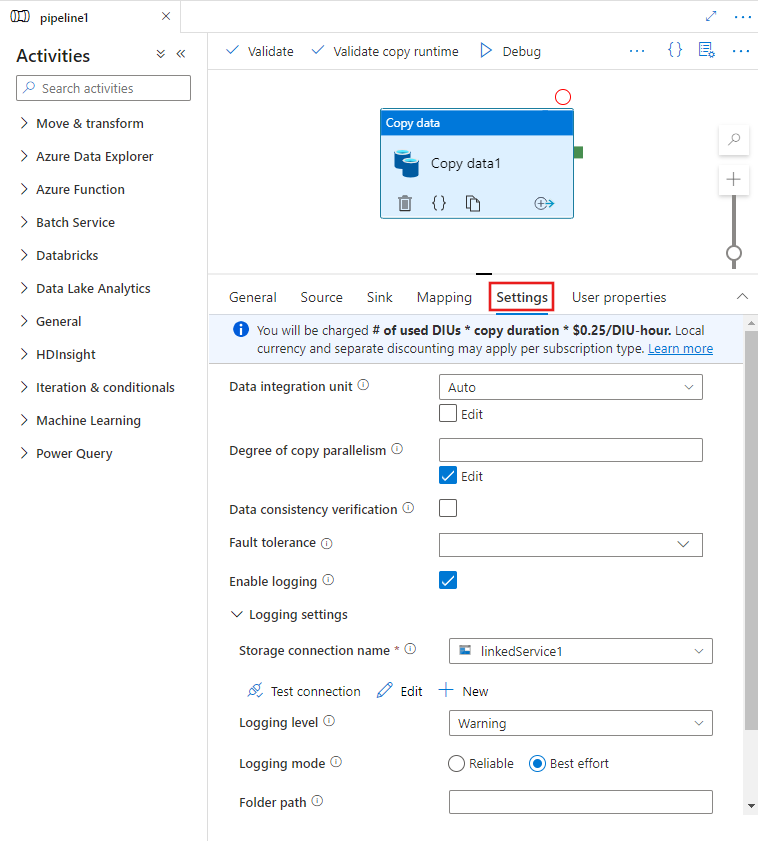
Eenheden voor gegevensintegratie
Een Data-Integratie eenheid is een meting die de macht (een combinatie van CPU-, geheugen- en netwerkresourcetoewijzing) van één eenheid binnen de service vertegenwoordigt. Data-Integratie eenheid is alleen van toepassing op Azure Integration Runtime, maar niet zelf-hostende Integration Runtime.
De toegestane DIU's voor het uitvoeren van een kopieeractiviteit liggen tussen 2 en 256. Als dit niet is opgegeven of als u auto kiest in de gebruikersinterface, past de service dynamisch de optimale DIU-instelling toe op basis van uw bron-sinkpaar en gegevenspatroon. De volgende tabel bevat de ondersteunde DIU-bereiken en het standaardgedrag in verschillende kopieerscenario's:
| Scenario kopiëren | Ondersteund DIU-bereik | Standaard-DIU's bepaald door de service |
|---|---|---|
| Tussen bestandsarchieven | - Kopiëren van of naar één bestand: 2-4 - Kopiëren van en naar meerdere bestanden: 2-256, afhankelijk van het aantal en de grootte van de bestanden Als u bijvoorbeeld gegevens kopieert uit een map met 4 grote bestanden en ervoor kiest om de hiërarchie te behouden, is de maximale effectieve DIU 16; wanneer u ervoor kiest om het bestand samen te voegen, is de maximale effectieve DIU 4. |
Afhankelijk van het aantal bestanden en de grootte van de bestanden tussen 4 en 32 |
| Van bestandsarchief naar niet-bestandsarchief | - Kopiëren van één bestand: 2-4 - Kopiëren uit meerdere bestanden: 2-256, afhankelijk van het aantal en de grootte van de bestanden Als u bijvoorbeeld gegevens kopieert uit een map met 4 grote bestanden, is de maximale effectieve DIU 16. |
- Kopiëren naar Azure SQL Database of Azure Cosmos DB: tussen 4 en 16, afhankelijk van de sinklaag (DTU's/RU's) en het bronbestandspatroon - Kopiëren naar Azure Synapse Analytics met behulp van de PolyBase- of COPY-instructie: 2 - Ander scenario: 4 |
| Van niet-bestandsarchief naar bestandsarchief | - Kopiëren uit gegevensarchieven met partitieopties (waaronder Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server en Teradata): 2-256 bij het schrijven naar een map en 2-4 bij het schrijven naar één bestand. Opmerking per brongegevenspartitie kan maximaal 4 DIUs gebruiken. - Andere scenario's: 2-4 |
- Kopiëren van REST of HTTP: 1 - Kopiëren van Amazon Redshift met behulp van UNLOAD: 2 - Ander scenario: 4 |
| Tussen niet-bestandsarchieven | - Kopiëren uit gegevensarchieven met partitieopties (waaronder Azure Database for PostgreSQL, Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SQL Server en Teradata): 2-256 bij het schrijven naar een map en 2-4 bij het schrijven naar één bestand. Opmerking per brongegevenspartitie kan maximaal 4 DIUs gebruiken. - Andere scenario's: 2-4 |
- Kopiëren van REST of HTTP: 1 - Ander scenario: 4 |
U kunt de DIU's zien die worden gebruikt voor elke kopieeruitvoering in de weergave controle van de kopieeractiviteit of de uitvoer van de activiteit. Zie Copy-activiteit bewaking voor meer informatie. Als u deze standaardwaarde wilt overschrijven, geeft u als volgt een waarde voor de dataIntegrationUnits eigenschap op. Het werkelijke aantal DIU's dat door de kopieerbewerking tijdens runtime wordt gebruikt, is gelijk aan of kleiner dan de geconfigureerde waarde, afhankelijk van uw gegevenspatroon.
Er worden kosten in rekening gebracht voor het aantal gebruikte DIU's * kopieerduur * eenheidsprijs/DIU-uur. Bekijk hier de huidige prijzen. Lokale valuta en afzonderlijke korting kunnen per abonnementstype worden toegepast.
Voorbeeld:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"dataIntegrationUnits": 128
}
}
]
Schaalbaarheid van zelf-hostende Integration Runtime
Als u een hogere doorvoer wilt bereiken, kunt u de zelf-hostende IR omhoog of uitschalen:
- Als de CPU en het beschikbare geheugen op het zelf-hostende IR-knooppunt niet volledig worden gebruikt, maar de uitvoering van gelijktijdige taken de limiet bereikt, moet u omhoog schalen door het aantal gelijktijdige taken te verhogen dat op een knooppunt kan worden uitgevoerd. Zie hier voor instructies.
- Als de CPU daarentegen hoog is op het zelf-hostende IR-knooppunt of het beschikbare geheugen laag is, kunt u een nieuw knooppunt toevoegen om de belasting over de meerdere knooppunten uit te schalen. Zie hier voor instructies.
In de volgende scenario's kan de uitvoering van één kopieeractiviteit gebruikmaken van meerdere zelf-hostende IR-knooppunten:
- Kopieer gegevens uit op bestanden gebaseerde archieven, afhankelijk van het aantal en de grootte van de bestanden.
- Kopieer gegevens uit gegevensarchief met partitieopties (waaronder Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server en Teradata), afhankelijk van het aantal gegevenspartities.
Parallelle kopie
U kunt parallelle kopie (parallelCopieseigenschap in de JSON-definitie van de Copy-activiteit instellen of Degree of parallelism instellen op het tabblad Instellingen van de eigenschappen van de Copy-activiteit in de gebruikersinterface) voor kopieeractiviteit om aan te geven welke parallellisme u wilt gebruiken voor de kopieeractiviteit. U kunt deze eigenschap beschouwen als het maximum aantal threads in de kopieeractiviteit die van uw bron lezen of schrijven naar uw sinkgegevensarchieven parallel.
De parallelle kopie is orthogonaal voor Data-Integratie eenheden of zelf-hostende IR-knooppunten. Het wordt geteld voor alle DIUs- of zelf-hostende IR-knooppunten.
Voor elke uitvoering van de kopieeractiviteit past de service standaard dynamisch de optimale instelling voor parallelle kopieerbewerkingen toe op basis van uw bron-sinkpaar en gegevenspatroon.
Tip
Het standaardgedrag van parallelle kopie geeft meestal de beste doorvoer, die automatisch wordt bepaald door de service op basis van uw bron-sinkpaar, gegevenspatroon en aantal DIU's of het aantal CPU-/geheugen-/knooppunten van de zelf-hostende IR. Raadpleeg De prestaties van kopieeractiviteiten oplossen wanneer u parallelle kopie wilt afstemmen.
De volgende tabel bevat het gedrag van parallelle kopieerbewerkingen:
| Scenario kopiëren | Gedrag van parallelle kopieerbewerkingen |
|---|---|
| Tussen bestandsarchieven | parallelCopies bepaalt de parallelle uitvoering op bestandsniveau. De segmentering binnen elk bestand vindt automatisch en transparant plaats. Het is ontworpen om de beste geschikte segmentgrootte te gebruiken voor een bepaald gegevensarchieftype om gegevens parallel te laden. Het werkelijke aantal parallelle kopieën dat tijdens de uitvoering wordt gebruikt, is niet meer dan het aantal bestanden dat u hebt. Als het kopieergedrag mergeFile is in de bestandssink, kan de kopieeractiviteit niet profiteren van parallelle uitvoering op bestandsniveau. |
| Van bestandsarchief naar niet-bestandsarchief | - Bij het kopiëren van gegevens naar Azure SQL Database of Azure Cosmos DB is standaard parallelle kopie ook afhankelijk van de sinklaag (aantal DTU's/RU's). - Bij het kopiëren van gegevens naar Azure Table is standaard parallelle kopie 4. |
| Van niet-bestandsarchief naar bestandsarchief | - Bij het kopiëren van gegevens uit een gegevensarchief met partitieopties (waaronder Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS voor Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS voor SQL Server en Teradata), is standaard parallel kopiëren 4. Het werkelijke aantal parallelle kopieën dat tijdens runtime wordt gebruikt, is niet meer dan het aantal gegevenspartities dat u hebt. Wanneer u zelf-hostende Integration Runtime gebruikt en kopieert naar Azure Blob/ADLS Gen2, moet u er rekening mee houden dat de maximale effectieve parallelle kopie 4 of 5 per IR-knooppunt is. - Voor andere scenario's wordt parallelle kopie niet van kracht. Zelfs als parallellisme is opgegeven, wordt deze niet toegepast. |
| Tussen niet-bestandsarchieven | - Bij het kopiëren van gegevens naar Azure SQL Database of Azure Cosmos DB is standaard parallelle kopie ook afhankelijk van de sinklaag (aantal DTU's/RU's). - Bij het kopiëren van gegevens uit een gegevensarchief met partitieopties (waaronder Azure SQL Database, Azure SQL Managed Instance, Azure Synapse Analytics, Oracle, Amazon RDS voor Oracle, Netezza, SAP HANA, SAP Open Hub, SAP Table, SQL Server, Amazon RDS voor SQL Server en Teradata), is standaard parallel kopiëren 4. - Bij het kopiëren van gegevens naar Azure Table is standaard parallelle kopie 4. |
Als u de belasting wilt beheren op computers waarop uw gegevensarchieven worden gehost of om de kopieerprestaties af te stemmen, kunt u de standaardwaarde overschrijven en een waarde voor de parallelCopies eigenschap opgeven. De waarde moet een geheel getal groter dan of gelijk aan 1 zijn. Tijdens runtime gebruikt de kopieeractiviteit voor de beste prestaties een waarde die kleiner is dan of gelijk is aan de waarde die u hebt ingesteld.
Wanneer u een waarde voor de parallelCopies eigenschap opgeeft, moet u rekening houden met de belastingsverhoging voor uw bron- en sinkgegevensarchieven. Houd ook rekening met de toename van de belasting voor de zelf-hostende Integration Runtime als de kopieeractiviteit er door wordt gemachtigd. Deze belastingsverhoging vindt vooral plaats wanneer u meerdere activiteiten of gelijktijdige uitvoeringen hebt van dezelfde activiteiten die worden uitgevoerd op hetzelfde gegevensarchief. Als u merkt dat het gegevensarchief of de zelf-hostende Integration Runtime wordt overweldigd door de belasting, verlaagt u de waarde om de parallelCopies belasting te verlichten.
Voorbeeld:
"activities":[
{
"name": "Sample copy activity",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "BlobSource",
},
"sink": {
"type": "AzureDataLakeStoreSink"
},
"parallelCopies": 32
}
}
]
Gefaseerde kopie
Wanneer u gegevens kopieert uit een brongegevensarchief naar een sinkgegevensarchief, kunt u ervoor kiezen om Azure Blob Storage of Azure Data Lake Storage Gen2 te gebruiken als een tijdelijke faseringsopslag. Fasering is vooral handig in de volgende gevallen:
- U wilt gegevens uit verschillende gegevensarchieven opnemen in Azure Synapse Analytics via PolyBase, gegevens kopiëren van/naar Snowflake of gegevens opnemen van Amazon Redshift/HDFS. Meer informatie vindt u in:
- U wilt geen andere poorten dan poort 80 en poort 443 in uw firewall openen vanwege it-beleid van het bedrijf. Wanneer u bijvoorbeeld gegevens kopieert uit een on-premises gegevensarchief naar een Azure SQL Database of een Azure Synapse Analytics, moet u uitgaande TCP-communicatie activeren op poort 1433 voor zowel de Windows-firewall als uw bedrijfsfirewall. In dit scenario kan gefaseerde kopie profiteren van de zelf-hostende Integration Runtime om eerst gegevens te kopiëren naar een faseringsopslag via HTTP of HTTPS op poort 443 en vervolgens de gegevens uit fasering in SQL Database of Azure Synapse Analytics te laden. In deze stroom hoeft u poort 1433 niet in te schakelen.
- Soms duurt het even om een hybride gegevensverplaatsing uit te voeren (dat wil gezegd, om te kopiëren van een on-premises gegevensarchief naar een gegevensarchief in de cloud) via een trage netwerkverbinding. Om de prestaties te verbeteren, kunt u gefaseerde kopie gebruiken om de on-premises gegevens te comprimeren, zodat het minder tijd kost om gegevens naar het faseringsgegevensarchief in de cloud te verplaatsen. Vervolgens kunt u de gegevens in het faseringsarchief decomprimeren voordat u in het doelgegevensarchief laadt.
Hoe gefaseerde kopie werkt
Wanneer u de faseringsfunctie activeert, worden eerst de gegevens uit het brongegevensarchief gekopieerd naar de faseringsopslag (bring your own Azure Blob of Azure Data Lake Storage Gen2). Vervolgens worden de gegevens gekopieerd van de fasering naar het sink-gegevensarchief. De kopieeractiviteit beheert automatisch de stroom in twee fasen voor u en schoont ook tijdelijke gegevens op uit de faseringsopslag nadat de gegevensverplaatsing is voltooid.

U moet verwijderingsmachtigingen verlenen aan uw Azure Data Factory in uw faseringsopslag, zodat de tijdelijke gegevens kunnen worden opgeschoond nadat de kopieeractiviteit is uitgevoerd.
Wanneer u gegevensverplaatsing activeert met behulp van een faseringsarchief, kunt u opgeven of u de gegevens wilt comprimeren voordat u gegevens van het brongegevensarchief naar het faseringsarchief verplaatst en vervolgens gedecomprimeerd voordat u gegevens verplaatst van een tussentijds of faserend gegevensarchief naar het sink-gegevensarchief.
Op dit moment kunt u geen gegevens kopiëren tussen twee gegevensarchieven die zijn verbonden via verschillende zelf-hostende IR's, niet met of zonder gefaseerde kopie. Voor dit scenario kunt u twee expliciet gekoppelde kopieeractiviteiten configureren om te kopiëren van bron naar fasering en vervolgens van fasering naar sink.
Configuratie
Configureer de instelling enableStaging in de kopieeractiviteit om op te geven of u wilt dat de gegevens in de opslag worden gefaseerd voordat u deze in een doelgegevensarchief laadt. Wanneer u enableStagingTRUEinstelt, geeft u de aanvullende eigenschappen op die worden vermeld in de volgende tabel.
| Eigenschappen | Beschrijving | Default value | Vereist |
|---|---|---|---|
| enableStaging | Geef op of u gegevens wilt kopiëren via een tussentijdse faseringsopslag. | Onwaar | Nee |
| linkedServiceName | Geef de naam op van een gekoppelde Azure Blob Storage- of Azure Data Lake Storage Gen2-service , die verwijst naar het opslagexemplaren dat u als tijdelijke faseringsopslag gebruikt. | N.v.t. | Ja, wanneer enableStaging is ingesteld op TRUE |
| path | Geef het pad op dat u de gefaseerde gegevens wilt bevatten. Als u geen pad opgeeft, maakt de service een container voor het opslaan van tijdelijke gegevens. | N.v.t. | Nee |
| enableCompression | Hiermee geeft u op of gegevens moeten worden gecomprimeerd voordat ze naar de bestemming worden gekopieerd. Deze instelling vermindert het aantal gegevens dat wordt overgedragen. | Onwaar | Nr. |
Notitie
Als u gefaseerde kopie gebruikt waarvoor compressie is ingeschakeld, wordt de service-principal of MSI-verificatie voor de gekoppelde faseringsblobservice niet ondersteund.
Hier volgt een voorbeelddefinitie van een kopieeractiviteit met de eigenschappen die in de voorgaande tabel worden beschreven:
"activities":[
{
"name": "CopyActivityWithStaging",
"type": "Copy",
"inputs": [...],
"outputs": [...],
"typeProperties": {
"source": {
"type": "OracleSource",
},
"sink": {
"type": "SqlDWSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "stagingcontainer/path"
}
}
}
]
Gevolgen voor gefaseerde kopiefacturering
Er worden kosten in rekening gebracht op basis van twee stappen: kopieerduur en kopieertype.
- Wanneer u fasering gebruikt tijdens een cloudkopie, die gegevens kopieert uit een cloudgegevensarchief naar een ander cloudgegevensarchief, worden beide fasen die worden ondersteund door Azure Integration Runtime, in rekening gebracht voor de [som van de kopieerduur voor stap 1 en stap 2] x [prijs voor kopieereenheden in de cloud].
- Wanneer u fasering gebruikt tijdens een hybride kopie, die gegevens kopieert van een on-premises gegevensarchief naar een gegevensarchief in de cloud, wordt er één fase in rekening gebracht door een zelf-hostende Integration Runtime. Er worden kosten in rekening gebracht voor [duur van hybride kopie] x [prijs van hybride kopieereenheden] + [duur van cloudkopieereenheid] x [prijs van cloudkopie-eenheid].
Gerelateerde inhoud
Zie de andere artikelen over kopieeractiviteiten:
- overzicht van Copy-activiteit
- Handleiding voor prestaties en schaalbaarheid van kopieeractiviteit
- Problemen met prestaties van kopieeractiviteit oplossen
- Azure Data Factory gebruiken om gegevens te migreren van uw data lake of datawarehouse naar Azure
- Gegevens migreren van Amazon S3 naar Azure Storage