Prestaties van Azure Data Lake Storage Gen1 afstemmen
Data Lake Storage Gen1 ondersteunt hoge doorvoer voor I/O-intensieve analyses en gegevensverplaatsing. In Data Lake Storage Gen1 is het gebruik van alle beschikbare doorvoer (de hoeveelheid gegevens die per seconde kan worden gelezen of geschreven) belangrijk voor de beste prestaties. Dit wordt bereikt door zoveel mogelijk lees- en schrijfbewerkingen parallel uit te voeren.
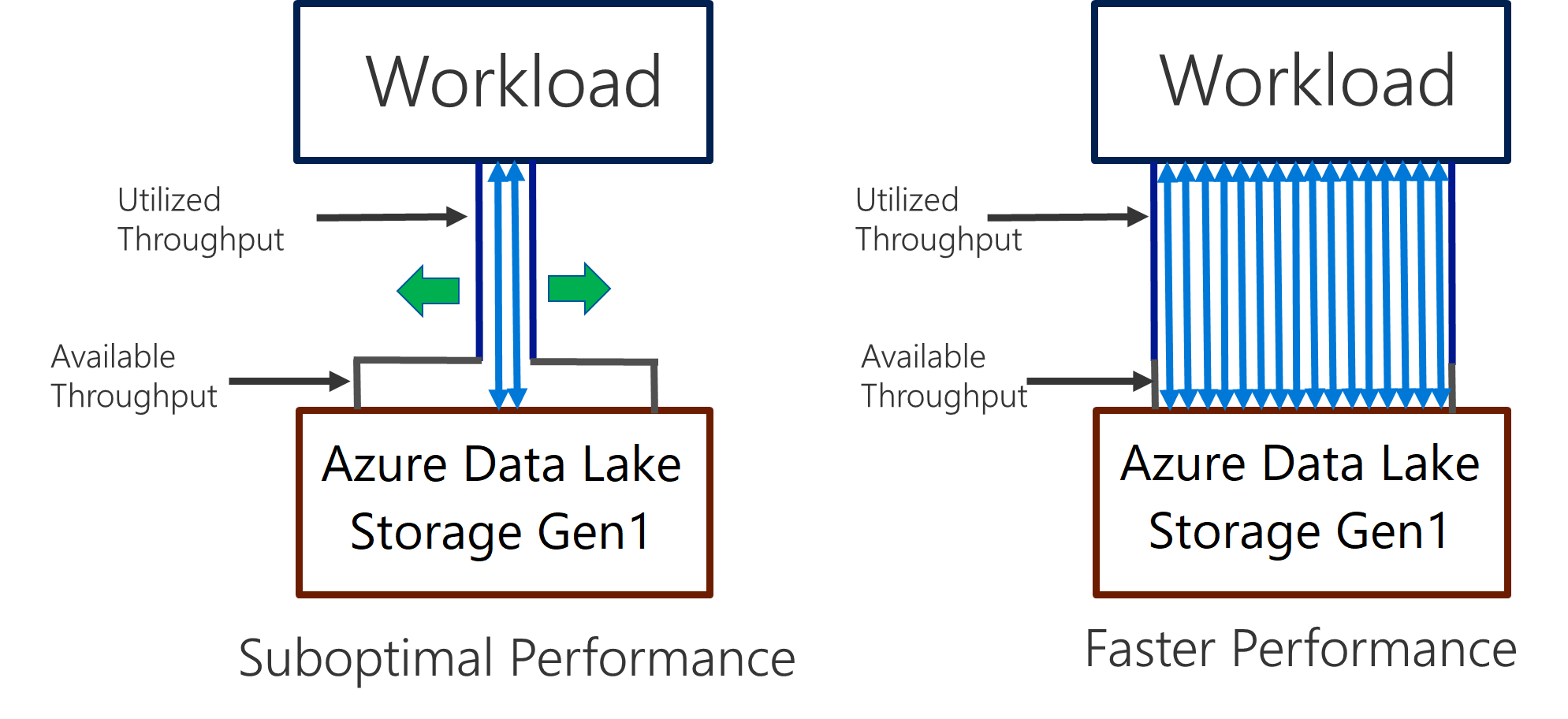
Data Lake Storage Gen1 kunt schalen om de benodigde doorvoer voor alle analysescenario's te bieden. Standaard biedt een Data Lake Storage Gen1-account automatisch voldoende doorvoer om te voldoen aan de behoeften van een brede categorie gebruiksvoorbeelden. Voor de gevallen waarin klanten tegen de standaardlimiet aanlopen, kan het Data Lake Storage Gen1-account worden geconfigureerd om meer doorvoer te bieden door contact op te vragen met Microsoft Ondersteuning.
Gegevensopname
Bij het opnemen van gegevens van een bronsysteem naar Data Lake Storage Gen1, is het belangrijk om er rekening mee te houden dat de bronhardware, de bronnetwerkhardware en de netwerkverbinding met Data Lake Storage Gen1 het knelpunt kunnen zijn.
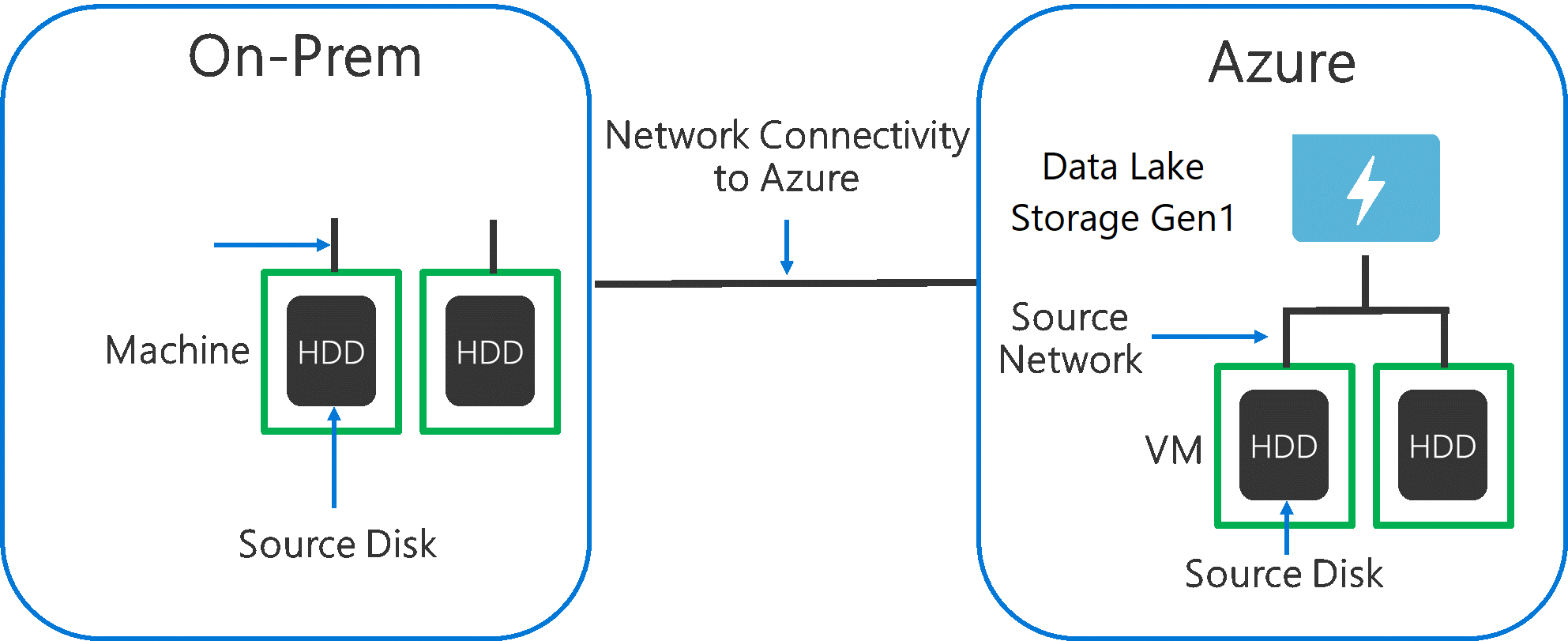
Het is belangrijk om ervoor te zorgen dat de gegevensverplaatsing niet wordt beïnvloed door deze factoren.
Bronhardware
Of u nu on-premises machines of VM's in Azure gebruikt, u moet zorgvuldig de juiste hardware selecteren. Voor bronschijfhardware geeft u de voorkeur aan SCHIJVEN boven HDD's en kiest u schijfhardware met snellere spindels. Gebruik voor bronnetwerkhardware de snelst mogelijke NIC's. In Azure raden we Azure D14-VM's aan die over de juiste krachtige schijf- en netwerkhardware beschikken.
Netwerkverbinding met Data Lake Storage Gen1
De netwerkverbinding tussen uw brongegevens en Data Lake Storage Gen1 kan soms het knelpunt zijn. Wanneer uw brongegevens on-premises zijn, kunt u overwegen om een speciale koppeling met Azure ExpressRoute te gebruiken. Als uw brongegevens zich in Azure bevinden, zijn de prestaties het beste wanneer de gegevens zich in dezelfde Azure-regio bevinden als het Data Lake Storage Gen1-account.
Hulpprogramma's voor gegevensopname configureren voor maximale parallelle uitvoering
Nadat u de knelpunten van de bronhardware en netwerkverbinding hebt opgelost, bent u klaar om uw opnamehulpprogramma's te configureren. De volgende tabel bevat een overzicht van de belangrijkste instellingen voor verschillende populaire opnamehulpprogramma's en bevat uitgebreide artikelen over het afstemmen van prestaties. Raadpleeg dit artikel voor meer informatie over het hulpprogramma dat u voor uw scenario moet gebruiken.
| Hulpprogramma | Instellingen | Meer details |
|---|---|---|
| PowerShell | PerFileThreadCount, ConcurrentFileCount | Koppeling |
| AdlCopy | Azure Data Lake Analytics-eenheden | Koppeling |
| DistCp | -m (mapper) | Koppeling |
| Azure Data Factory | parallelCopies | Koppeling |
| Sqoop | fs.azure.block.size, -m (mapper) | Koppeling |
Uw gegevensset structuren
Wanneer gegevens worden opgeslagen in Data Lake Storage Gen1, zijn de bestandsgrootte, het aantal bestanden en de mapstructuur van invloed op de prestaties. In de volgende sectie worden de best practices op deze gebieden beschreven.
Bestandsgrootte
Analyse-engines zoals HDInsight en Azure Data Lake Analytics hebben doorgaans een overhead per bestand. Als u uw gegevens net zo veel kleine bestanden opslaat, kan dit de prestaties negatief beïnvloeden.
Over het algemeen kunt u uw gegevens ordenen in grotere bestanden voor betere prestaties. Als vuistregel kunt u gegevenssets ordenen in bestanden van 256 MB of groter. In sommige gevallen, zoals afbeeldingen en binaire gegevens, is het niet mogelijk om ze parallel te verwerken. In deze gevallen is het raadzaam om afzonderlijke bestanden onder 2 GB te houden.
Soms hebben gegevenspijplijnen beperkte controle over de onbewerkte gegevens die veel kleine bestanden bevatten. Het wordt aanbevolen om een 'kookproces' te hebben dat grotere bestanden genereert voor gebruik voor downstreamtoepassingen.
Tijdreeksgegevens in mappen ordenen
Voor Hive- en ADLA-workloads kan het verwijderen van partities van tijdreeksgegevens sommige query's helpen om alleen een subset van de gegevens te lezen, waardoor de prestaties worden verbeterd.
Pijplijnen die tijdreeksgegevens opnemen, plaatsen hun bestanden vaak met een gestructureerde naamgeving voor bestanden en mappen. Hier volgt een veelvoorkomend voorbeeld van gegevens die zijn gestructureerd op datum: \DataSet\JJJJ\MM\DD\datafile_YYYY_MM_DD.tsv.
U ziet dat de datum/tijd-informatie zowel als mappen als in de bestandsnaam wordt weergegeven.
Voor datum en tijd is het volgende een veelvoorkomend patroon: \DataSet\JJJJ\MM\DD\UU\mm\datafile_YYYY_MM_DD_HH_mm.tsv.
Nogmaals, de keuze die u maakt met de map en bestandsorganisatie moet worden geoptimaliseerd voor de grotere bestandsgrootten en een redelijk aantal bestanden in elke map.
I/O-intensieve taken optimaliseren voor Hadoop- en Spark-workloads in HDInsight
Taken kunnen in een van de volgende drie categorieën worden onderverdeeld:
- CPU-intensief. Deze taken hebben lange rekentijden met minimale I/O-tijden. Voorbeelden hiervan zijn machine learning en taken voor het verwerken van natuurlijke taal.
- Geheugenintensief. Deze taken gebruiken veel geheugen. Voorbeelden zijn PageRank en realtime analysetaken.
- I/O intensief. Deze taken besteden het grootste deel van hun tijd aan I/O. Een veelvoorkomend voorbeeld is een kopieertaak waarmee alleen lees- en schrijfbewerkingen worden uitgevoerd. Andere voorbeelden zijn gegevensvoorbereidingstaken die talloze gegevens lezen, een gegevenstransformatie uitvoeren en de gegevens vervolgens terugschrijven naar het archief.
De volgende richtlijnen zijn alleen van toepassing op I/O-intensieve taken.
Algemene overwegingen voor een HDInsight-cluster
- HDInsight-versies. Gebruik de nieuwste versie van HDInsight voor de beste prestaties.
- Regio 's. Plaats het Data Lake Storage Gen1-account in dezelfde regio als het HDInsight-cluster.
Een HDInsight-cluster bestaat uit twee hoofdknooppunten en enkele werkknooppunten. Elk werkknooppunt biedt een specifiek aantal kernen en geheugen, dat wordt bepaald door het VM-type. Bij het uitvoeren van een taak is YARN de resourceonderhandelaar die het beschikbare geheugen en de kernen toewijst om containers te maken. Elke container voert de taken uit die nodig zijn om de taak te voltooien. Containers worden parallel uitgevoerd om taken snel te verwerken. Daarom worden de prestaties verbeterd door zoveel mogelijk parallelle containers uit te voeren.
Er zijn drie lagen in een HDInsight-cluster die kunnen worden afgestemd om het aantal containers te verhogen en alle beschikbare doorvoer te gebruiken.
- Fysieke laag
- YARN-laag
- Workloadlaag
Fysieke laag
Voer een cluster uit met meer knooppunten en/of grotere VM's. Met een groter cluster kunt u meer YARN-containers uitvoeren, zoals wordt weergegeven in de onderstaande afbeelding.

Vm's met meer netwerkbandbreedte gebruiken. De hoeveelheid netwerkbandbreedte kan een knelpunt zijn als er minder netwerkbandbreedte is dan Data Lake Storage Gen1 doorvoer. Verschillende VM's hebben verschillende netwerkbandbreedtegrootten. Kies een VM-type met de grootst mogelijke netwerkbandbreedte.
YARN-laag
Gebruik kleinere YARN-containers. Verklein de grootte van elke YARN-container om meer containers met dezelfde hoeveelheid resources te maken.
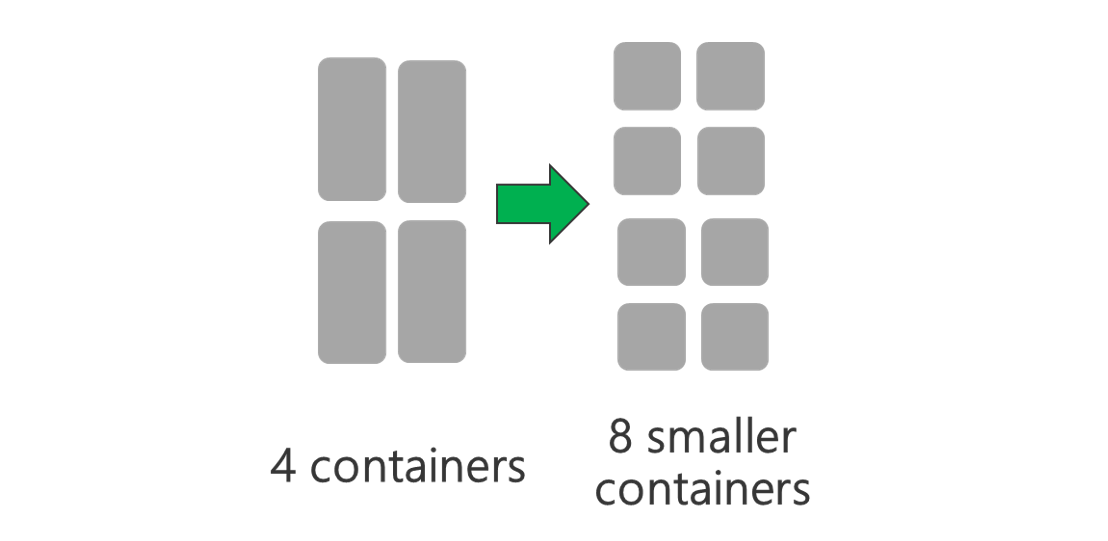
Afhankelijk van uw workload is er altijd een minimale YARN-containergrootte nodig. Als u een te kleine container kiest, ondervinden uw taken problemen met onvoldoende geheugen. Normaal gesproken mogen YARN-containers niet kleiner zijn dan 1 GB. Het is gebruikelijk om YARN-containers van 3 GB te zien. Voor sommige workloads hebt u mogelijk grotere YARN-containers nodig.
Verhoog het aantal kernen per YARN-container. Verhoog het aantal kernen dat aan elke container is toegewezen om het aantal parallelle taken te verhogen dat in elke container wordt uitgevoerd. Dit werkt voor toepassingen zoals Spark, die meerdere taken per container uitvoeren. Voor toepassingen zoals Hive die één thread in elke container uitvoeren, is het beter om meer containers te hebben in plaats van meer kernen per container.
Workloadlaag
Gebruik alle beschikbare containers. Stel het aantal taken in op gelijk of groter dan het aantal beschikbare containers, zodat alle resources worden gebruikt.
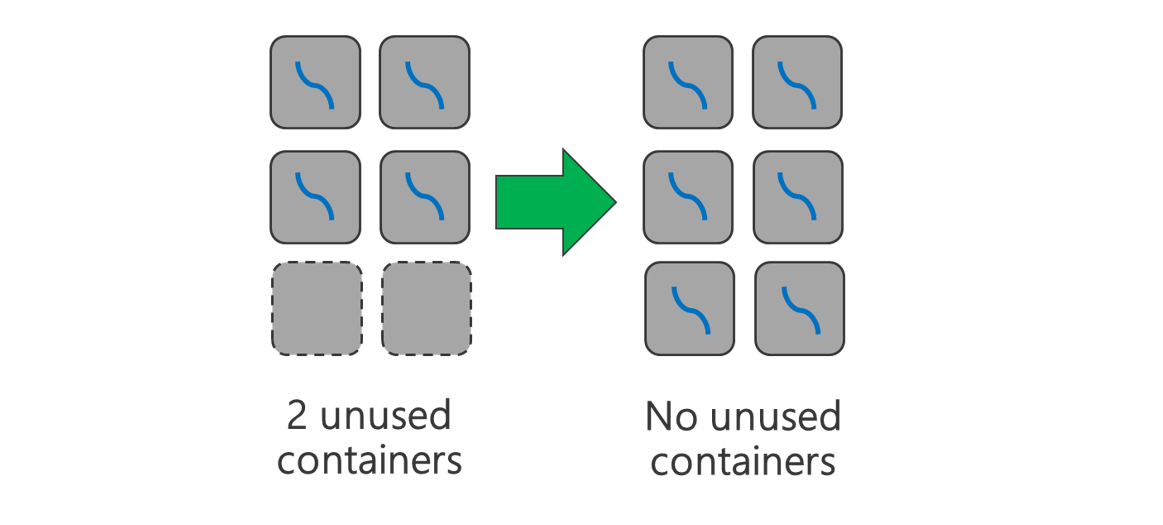
Mislukte taken zijn kostbaar. Als elke taak een grote hoeveelheid gegevens bevat om te verwerken, resulteert het mislukken van een taak in een dure nieuwe poging. Daarom is het beter om meer taken te maken, die elk een kleine hoeveelheid gegevens verwerkt.
Naast de bovenstaande algemene richtlijnen heeft elke toepassing verschillende parameters beschikbaar om af te stemmen op die specifieke toepassing. De onderstaande tabel bevat enkele parameters en koppelingen om aan de slag te gaan met het afstemmen van prestaties voor elke toepassing.
| Workload | Parameter voor het instellen van taken |
|---|---|
| Spark in HDInsight |
|
| Hive in HDInsight |
|
| MapReduce in HDInsight |
|
| Storm op HDInsight |
|