Metrische rekengegevens weergeven
In dit artikel wordt uitgelegd hoe u het systeemeigen hulpprogramma voor metrische rekengegevens in de Gebruikersinterface van Azure Databricks kunt gebruiken om belangrijke hardware- en Spark-metrische gegevens te verzamelen. Elke berekening die databricks Runtime 13.3 LTS en hoger gebruikt, heeft standaard toegang tot deze metrische gegevens.
Metrische gegevens zijn bijna in realtime beschikbaar met een normale vertraging van minder dan één minuut. Metrische gegevens worden opgeslagen in door Azure Databricks beheerde opslag, niet in de opslag van de klant.
Hoe verschillen deze nieuwe metrische gegevens van Ganglia?
De nieuwe gebruikersinterface voor metrische rekengegevens heeft een uitgebreidere weergave van het resourcegebruik van uw cluster, waaronder Spark-verbruik en interne Databricks-processen. De Ganglia-gebruikersinterface meet daarentegen alleen het Spark-containerverbruik. Dit verschil kan leiden tot verschillen in de metrische waarden tussen de twee interfaces.
Toegang tot de gebruikersinterface voor metrische rekengegevens
De gebruikersinterface voor metrische rekengegevens weergeven:
- Klik op Compute in de zijbalk.
- Klik op de rekenresource waarvoor u metrische gegevens wilt weergeven.
- Klik op het tabblad Metrische gegevens .
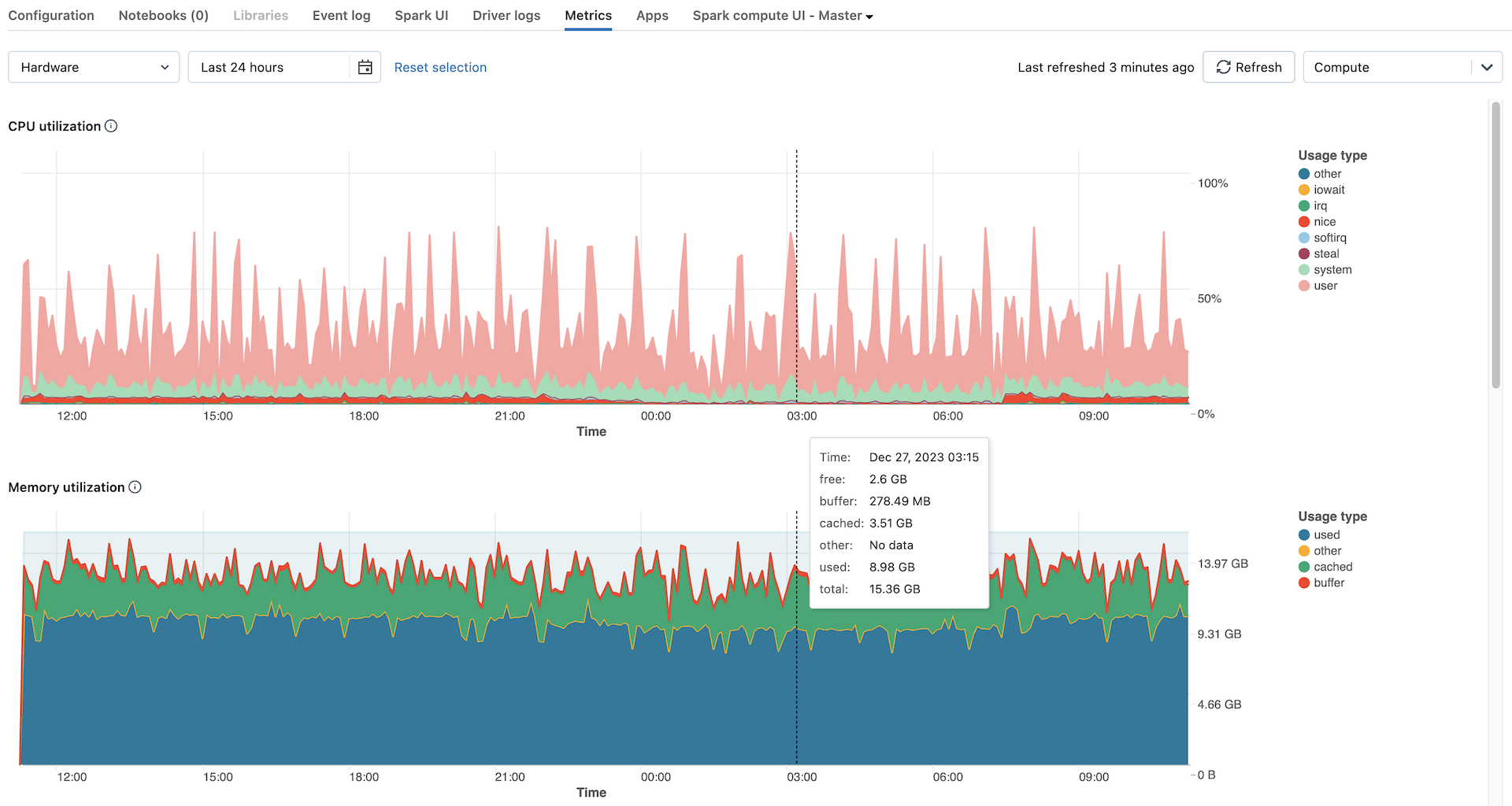
Metrische hardwaregegevens worden standaard weergegeven. Als u metrische Spark-gegevens wilt weergeven, klikt u op de vervolgkeuzelijst met het label Hardware en selecteert u Spark. U kunt ook GPU selecteren als het exemplaar GPU is ingeschakeld.
Metrische gegevens filteren op tijdsperiode
U kunt historische metrische gegevens weergeven door een tijdsbereik te selecteren met behulp van het filter voor datumkiezer. Metrische gegevens worden elke minuut verzameld, zodat u kunt filteren op elk dag-, uur- of minuutbereik van de afgelopen 30 dagen. Klik op het agendapictogram om een keuze te maken uit vooraf gedefinieerde gegevensbereiken of klik in het tekstvak om aangepaste waarden te definiëren.
Notitie
De tijdsintervallen die in de grafieken worden weergegeven, worden aangepast op basis van de tijdsduur die u bekijkt. De meeste metrische gegevens zijn gemiddelden op basis van het tijdsinterval dat u momenteel bekijkt.
U kunt ook de meest recente metrische gegevens ophalen door op de knop Vernieuwen te klikken.
Metrische gegevens weergeven op knooppuntniveau
U kunt metrische gegevens voor afzonderlijke knooppunten weergeven door te klikken op de vervolgkeuzelijst Compute en het knooppunt te selecteren waarvoor u metrische gegevens wilt weergeven. GPU-metrische gegevens zijn alleen beschikbaar op het niveau van afzonderlijke knooppunten. Metrische Spark-gegevens zijn niet beschikbaar voor afzonderlijke knooppunten.
Notitie
Als u geen specifiek knooppunt selecteert, wordt het resultaat gemiddeld berekend op alle knooppunten in een cluster (inclusief het stuurprogramma).
Grafieken met metrische hardwaregegevens
De volgende grafieken met metrische hardware zijn beschikbaar om weer te geven in de gebruikersinterface voor metrische rekengegevens:
- Distributie van serverbelasting: in deze grafiek ziet u het CPU-gebruik in de afgelopen minuut voor elk knooppunt.
- CPU-gebruik: het percentage tijd dat de CPU in elke modus heeft besteed, op basis van de totale kosten voor CPU-seconden. De metrische waarde wordt gemiddeld berekend op basis van het tijdsinterval dat in de grafiek wordt weergegeven. Hier volgen de bijgehouden modi:
- gast: Als u VM's uitvoert, gebruikt de CPU die VM's
- iowait: Tijd besteed aan wachten op I/O
- inactief: tijd dat de CPU niets te doen had
- irq: Tijd besteed aan onderbrekingsaanvragen
- leuk: Tijd die wordt gebruikt door processen die een positieve aardigheid hebben, wat een lagere prioriteit betekent dan andere taken
- softirq: Tijd besteed aan software-interruptaanvragen
- stelen: Als u een virtuele machine bent, kunt u andere VM's 'gestolen' van uw CPU's
- systeem: De tijd die in de kernel is besteed
- gebruiker: De tijd die is besteed in userland
- Geheugengebruik: het totale geheugengebruik per modus, gemeten in bytes en gemiddeld op basis van het tijdsinterval dat in de grafiek wordt weergegeven. De volgende gebruikstypen worden bijgehouden:
- gebruikt: Gebruikt geheugen (inclusief geheugen dat wordt gebruikt door achtergrondprocessen die worden uitgevoerd op een rekenproces)
- gratis: Ongebruikt geheugen
- buffer: geheugen gebruikt door kernelbuffers
- in de cache opgeslagen: geheugen dat wordt gebruikt door de cache van het bestandssysteem op het niveau van het besturingssysteem
- Geheugenwisselingsgebruik: het totale geheugenwisselingsgebruik per modus, gemeten in bytes en gemiddeld op basis van het tijdsinterval dat in de grafiek wordt weergegeven.
- Vrije bestandssysteemruimte: het totale gebruik van het bestandssysteem per koppelpunt, gemeten in bytes en gemiddeld op basis van het tijdsinterval dat in de grafiek wordt weergegeven.
- Ontvangen via het netwerk: het aantal bytes dat door elk apparaat is ontvangen via het netwerk, gemiddeld op basis van het tijdsinterval dat in de grafiek wordt weergegeven.
- Verzonden via het netwerk: het aantal bytes dat wordt verzonden via het netwerk door elk apparaat, gemiddeld op basis van het tijdsinterval dat in de grafiek wordt weergegeven.
- Aantal actieve knooppunten: dit toont het aantal actieve knooppunten op elke tijdstempel voor de opgegeven rekenkracht.
Grafieken met metrische Spark-gegevens
De volgende grafieken met metrische Spark-gegevens zijn beschikbaar om weer te geven in de gebruikersinterface voor metrische rekengegevens:
- Distributie van serverbelasting: in deze grafiek ziet u het CPU-gebruik in de afgelopen minuut voor elk knooppunt.
- Actieve taken: het totale aantal taken dat op een bepaald moment wordt uitgevoerd, gemiddeld op basis van het tijdsinterval dat in de grafiek wordt weergegeven.
- Totaal aantal mislukte taken: het totale aantal taken dat is mislukt in uitvoerders, gemiddeld op basis van het tijdsinterval dat in de grafiek wordt weergegeven.
- Totaal voltooide taken: het totale aantal taken dat is voltooid in uitvoerders, gemiddeld op basis van het tijdsinterval dat in de grafiek wordt weergegeven.
- Totaal aantal taken: Het totale aantal taken (uitvoeren, mislukt en voltooid) in uitvoerders, gemiddeld op basis van het tijdsinterval dat in de grafiek wordt weergegeven.
- Totaal aantal willekeurige leesbewerkingen: de totale grootte van leesgegevens in willekeurige volgorde, gemeten in bytes en gemiddeld op basis van het tijdsinterval dat in de grafiek wordt weergegeven.
Shuffle readbetekent de som van geserialiseerde leesgegevens op alle uitvoerders aan het begin van een fase. - Totale willekeurige schrijfbewerking: de totale grootte van schrijfgegevens in willekeurige volgorde, gemeten in bytes en gemiddeld op basis van het tijdsinterval dat in de grafiek wordt weergegeven.
Shuffle Writeis de som van alle geschreven geserialiseerde gegevens op alle uitvoerders voordat ze worden verzonden (normaal aan het einde van een fase). - Totale duur van de taak: de totale verstreken tijd die de JVM heeft besteed aan het uitvoeren van taken op uitvoerders, gemeten in seconden en gemiddeld op basis van het tijdsinterval dat in de grafiek wordt weergegeven.
Metrische GPU-grafieken
De volgende metrische GPU-grafieken zijn beschikbaar om weer te geven in de gebruikersinterface voor metrische rekengegevens:
- Distributie van serverbelasting: in deze grafiek ziet u het CPU-gebruik in de afgelopen minuut voor elk knooppunt.
- Gebruik per GPU-decoder: het percentage gpu-decodergebruik, gemiddeld op basis van het tijdsinterval dat in de grafiek wordt weergegeven.
- Gebruik per GPU-encoder: het percentage gpu-encodergebruik, gemiddeld op basis van het tijdsinterval dat in de grafiek wordt weergegeven.
- Per GPU-frame buffergeheugengebruik bytes: het geheugengebruik van de framebuffer, gemeten in bytes en gemiddeld op basis van het tijdsinterval dat in de grafiek wordt weergegeven.
- Geheugengebruik per GPU: het percentage GPU-geheugengebruik, gemiddeld op basis van het tijdsinterval dat in de grafiek wordt weergegeven.
- Gebruik per GPU: het percentage GPU-gebruik, gemiddeld berekend op basis van het tijdsinterval dat in de grafiek wordt weergegeven.
Probleemoplossing
Als u onvolledige of ontbrekende metrische gegevens voor een periode ziet, kan dit een van de volgende problemen zijn:
- Een storing in de Databricks-service die verantwoordelijk is voor het opvragen en opslaan van metrische gegevens.
- Netwerkproblemen aan de kant van de klant.
- De berekening is of heeft een slechte status.
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor