Gegevensobjecten in databricks lakehouse
Databricks Lakehouse organiseert gegevens die zijn opgeslagen met Delta Lake in de cloudobjectopslag met vertrouwde relaties zoals database, tabellen en weergaven. Dit model combineert veel van de voordelen van een datawarehouse voor ondernemingen met de schaalbaarheid en flexibiliteit van een data lake. Meer informatie over hoe dit model werkt en de relatie tussen objectgegevens en metagegevens, zodat u best practices kunt toepassen bij het ontwerpen en implementeren van Databricks Lakehouse voor uw organisatie.
Welke gegevensobjecten bevinden zich in databricks lakehouse?
De Databricks Lakehouse-architectuur combineert gegevens die zijn opgeslagen met het Delta Lake-protocol in cloudobjectopslag met metagegevens die zijn geregistreerd in een metastore. Er zijn vijf primaire objecten in het Databricks Lakehouse:
- Catalogus: een groepering van databases.
- Database of schema: een groepering van objecten in een catalogus. Databases bevatten tabellen, weergaven en functies.
- Tabel: een verzameling rijen en kolommen die zijn opgeslagen als gegevensbestanden in objectopslag.
- Weergave: een opgeslagen query meestal op basis van een of meer tabellen of gegevensbronnen.
- Functie: opgeslagen logica die een scalaire waarde of set rijen retourneert.
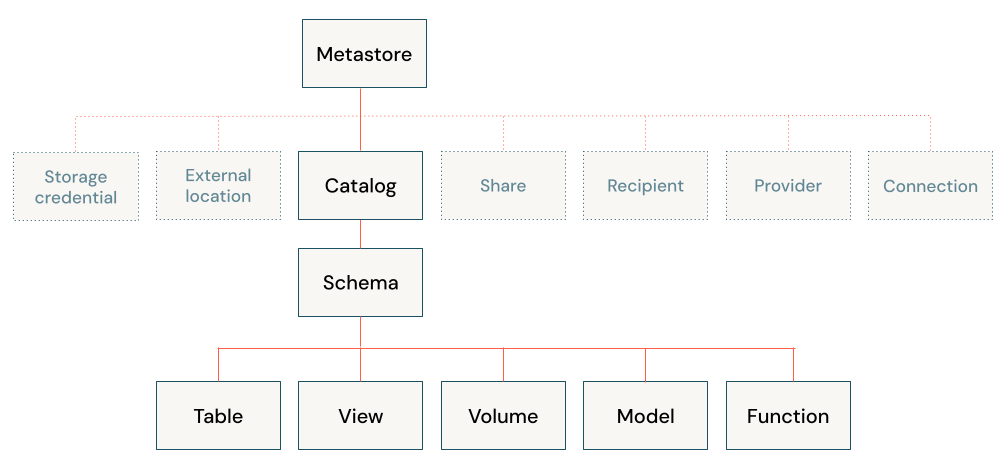
Zie het beveiligbare objectenmodel voor informatie over het beveiligen van objecten met Unity Catalog.
Wat is een metastore?
De metastore bevat alle metagegevens die gegevensobjecten in het lakehouse definiëren. Azure Databricks biedt de volgende metastore-opties:
Unity Catalog-metastore: Unity Catalog biedt gecentraliseerd toegangsbeheer, controle, herkomst en mogelijkheden voor gegevensdetectie. U maakt Unity Catalog-metastores op het niveau van het Azure Databricks-account en één metastore kan worden gebruikt in meerdere werkruimten.
Elke Unity Catalog-metastore wordt geconfigureerd met een hoofdopslaglocatie in een Azure Data Lake Storage Gen2-container in uw Azure-account. Deze opslaglocatie wordt standaard gebruikt voor het opslaan van gegevens voor beheerde tabellen.
In Unity Catalog zijn gegevens standaard beveiligd. In eerste instantie hebben gebruikers geen toegang tot gegevens in een metastore. Toegang kan worden verleend door een metastore-beheerder of de eigenaar van een object. Beveiligbare objecten in Unity Catalog zijn hiërarchisch en bevoegdheden worden naar beneden overgenomen. Unity Catalog biedt één locatie voor het beheren van beleid voor gegevenstoegang. Gebruikers hebben toegang tot gegevens in Unity Catalog vanuit elke werkruimte waaraan de metastore is gekoppeld. Zie Bevoegdheden beheren in Unity Catalog voor meer informatie.
Ingebouwde Hive-metastore (verouderd):elke Azure Databricks-werkruimte bevat een ingebouwde Hive-metastore als beheerde service. Een exemplaar van de metastore wordt geïmplementeerd in elk cluster en krijgt veilig toegang tot metagegevens vanuit een centrale opslagplaats voor elke klantwerkruimte.
De Hive-metastore biedt een minder gecentraliseerd gegevensbeheermodel dan Unity Catalog. Met een cluster hebben alle gebruikers standaard toegang tot alle gegevens die worden beheerd door de ingebouwde Hive-metastore van de werkruimte, tenzij toegangsbeheer voor tabellen is ingeschakeld voor dat cluster. Zie Toegangsbeheer voor Hive-metastore-tabellen (verouderd) voor meer informatie.
Besturingselementen voor toegang tot tabellen worden niet op accountniveau opgeslagen en daarom moeten ze afzonderlijk worden geconfigureerd voor elke werkruimte. Als u wilt profiteren van het gecentraliseerde en gestroomlijnde model voor gegevensbeheer dat wordt geleverd door Unity Catalog, raadt Databricks u aan om de tabellen die worden beheerd door de Hive-metastore van uw werkruimte te upgraden naar de Unity Catalog-metastore.
Externe Hive-metastore (verouderd): u kunt ook uw eigen metastore meenemen naar Azure Databricks. Azure Databricks-clusters kunnen verbinding maken met bestaande externe Apache Hive-metastores. U kunt toegangsbeheer voor tabellen gebruiken om machtigingen in een externe metastore te beheren. Besturingselementen voor toegang tot tabellen worden niet opgeslagen in de externe metastore en moeten daarom afzonderlijk worden geconfigureerd voor elke werkruimte. Databricks raadt u aan om in plaats daarvan Unity Catalog te gebruiken voor het eenvouds- en accountbeheermodel.
Ongeacht de metastore die u gebruikt, slaat Azure Databricks alle tabelgegevens op in objectopslag in uw cloudaccount.
Wat is een catalogus?
Een catalogus is de hoogste abstractie (of grofste korrel) in het relationele Databricks Lakehouse-model. Elke database wordt gekoppeld aan een catalogus. Catalogi bestaan als objecten in een metastore.
Vóór de introductie van Unity Catalog heeft Azure Databricks een naamruimte met twee lagen gebruikt. Catalogi zijn de derde laag in het unity-catalogusnamenpacingmodel:
catalog_name.database_name.table_name
De ingebouwde Hive-metastore ondersteunt slechts één catalogus. hive_metastore
Wat is een database?
Een database is een verzameling gegevensobjecten, zoals tabellen of weergaven (ook wel 'relaties' genoemd) en functies. In Azure Databricks worden de termen 'schema' en 'database' door elkaar gebruikt (terwijl in veel relationele systemen een database een verzameling schema's is).
Databases worden altijd gekoppeld aan een locatie in de opslag van cloudobjecten. U kunt desgewenst een database LOCATION opgeven bij het registreren van een database, rekening houdend met het volgende:
- De
LOCATIONgekoppelde aan een database wordt altijd beschouwd als een beheerde locatie. - Als u een database maakt, worden er geen bestanden op de doellocatie gemaakt.
- De
LOCATIONdatabase bepaalt de standaardlocatie voor gegevens van alle tabellen die zijn geregistreerd bij die database. - Als u een database hebt verwijderd, worden alle gegevens en bestanden die zijn opgeslagen op een beheerde locatie recursief verwijderd.
Deze interactie tussen locaties die worden beheerd door database- en gegevensbestanden is erg belangrijk. Om te voorkomen dat u per ongeluk gegevens verwijdert:
- Deel geen databaselocaties in meerdere databasedefinities.
- Registreer geen database op een locatie die al gegevens bevat.
- Als u de levenscyclus van gegevens onafhankelijk van de database wilt beheren, slaat u gegevens op op een locatie die niet is genest onder databaselocaties.
Wat is een tabel?
Een Azure Databricks-tabel is een verzameling gestructureerde gegevens. Een Delta-tabel slaat gegevens op als een map met bestanden in de opslag van cloudobjecten en registreert metagegevens van tabellen in de metastore binnen een catalogus en schema. Omdat Delta Lake de standaardopslagprovider is voor tabellen die zijn gemaakt in Azure Databricks, zijn alle tabellen die in Databricks zijn gemaakt standaard Delta-tabellen. Omdat Delta-tabellen gegevens opslaan in cloudobjectopslag en verwijzingen naar gegevens bieden via een metastore, hebben gebruikers in een organisatie toegang tot gegevens met behulp van hun favoriete API's; op Databricks omvat dit SQL, Python, PySpark, Scala en R.
Houd er rekening mee dat het mogelijk is om tabellen te maken in Databricks die geen Delta-tabellen zijn. Deze tabellen worden niet ondersteund door Delta Lake en bieden geen ACID-transacties en geoptimaliseerde prestaties van Delta-tabellen. Tabellen die in deze categorie vallen, zijn tabellen die zijn geregistreerd op basis van gegevens in externe systemen en tabellen die zijn geregistreerd in andere bestandsindelingen in de data lake. Zie Verbinding maken naar gegevensbronnen.
Er zijn twee soorten tabellen in Databricks,beheerde en niet-beheerde (of externe) tabellen.
Notitie
Het onderscheid tussen livetabellen in Delta Live Tables en het streamen van livetabellen wordt niet afgedwongen vanuit het perspectief van de tabel.
Wat is een beheerde tabel?
Azure Databricks beheert zowel de metagegevens als de gegevens voor een beheerde tabel; wanneer u een tabel neer zet, verwijdert u ook de onderliggende gegevens. Gegevensanalisten en andere gebruikers die voornamelijk in SQL werken, geven mogelijk de voorkeur aan dit gedrag. Beheerde tabellen zijn de standaardtabellen bij het maken van een tabel. De gegevens voor een beheerde tabel bevinden zich in de LOCATION database waarin deze is geregistreerd. Deze beheerde relatie tussen de gegevenslocatie en de database betekent dat u alle gegevens opnieuw naar de nieuwe locatie moet schrijven om een beheerde tabel naar een nieuwe database te verplaatsen.
Er zijn verschillende manieren om beheerde tabellen te maken, waaronder:
CREATE TABLE table_name AS SELECT * FROM another_table
CREATE TABLE table_name (field_name1 INT, field_name2 STRING)
df.write.saveAsTable("table_name")
Wat is een onbeheerde tabel?
Azure Databricks beheert alleen de metagegevens voor niet-beheerde (externe) tabellen; wanneer u een tabel neer zet, heeft dit geen invloed op de onderliggende gegevens. Niet-beheerde tabellen geven altijd een LOCATION waarde op tijdens het maken van tabellen. U kunt een bestaande map met gegevensbestanden registreren als een tabel of een pad opgeven wanneer een tabel voor het eerst wordt gedefinieerd. Omdat gegevens en metagegevens onafhankelijk van elkaar worden beheerd, kunt u de naam van een tabel wijzigen of deze registreren bij een nieuwe database zonder dat u gegevens hoeft te verplaatsen. Data engineers geven vaak de voorkeur aan onbeheerde tabellen en de flexibiliteit die ze bieden voor productiegegevens.
Er zijn verschillende manieren om niet-beheerde tabellen te maken, waaronder:
CREATE TABLE table_name
USING DELTA
LOCATION '/path/to/existing/data'
CREATE TABLE table_name
(field_name1 INT, field_name2 STRING)
LOCATION '/path/to/empty/directory'
df.write.option("path", "/path/to/empty/directory").saveAsTable("table_name")
Wat is een weergave?
In een weergave wordt de tekst voor een query opgeslagen op basis van een of meer gegevensbronnen of tabellen in de metastore. In Databricks is een weergave gelijk aan een Spark DataFrame dat als een object in een database wordt bewaard. In tegenstelling tot DataFrames kunt u vanuit elk deel van het Databricks-product query's uitvoeren op weergaven, ervan uitgaande dat u hiervoor toestemming hebt. Het maken van een weergave verwerkt of schrijft geen gegevens; alleen de querytekst is geregistreerd bij de metastore in de bijbehorende database.
Wat is een tijdelijke weergave?
Een tijdelijke weergave heeft een beperkt bereik en persistentie en is niet geregistreerd bij een schema of catalogus. De levensduur van een tijdelijke weergave verschilt op basis van de omgeving die u gebruikt:
- In notebooks en taken zijn tijdelijke weergaven afgestemd op het notebook- of scriptniveau. Er kan niet naar worden verwezen buiten het notitieblok waarin ze worden gedeclareerd en die niet meer bestaan wanneer het notebook loskoppelt van het cluster.
- In Databricks SQL zijn tijdelijke weergaven gericht op het queryniveau. Meerdere instructies binnen dezelfde query kunnen de tijdelijke weergave gebruiken, maar deze kunnen niet worden verwezen in andere query's, zelfs niet binnen hetzelfde dashboard.
- Globale tijdelijke weergaven zijn gericht op clusterniveau en kunnen worden gedeeld tussen notebooks of taken die rekenresources delen. Databricks raadt aan weergaven met de juiste tabel-ACL's te gebruiken in plaats van globale tijdelijke weergaven.
Wat is een functie?
Met Functies kunt u door de gebruiker gedefinieerde logica koppelen aan een database. Functies kunnen scalaire waarden of sets rijen retourneren. Functies worden gebruikt om gegevens samen te voegen. Met Azure Databricks kunt u functies opslaan in verschillende talen, afhankelijk van uw uitvoeringscontext, waarbij SQL breed wordt ondersteund. U kunt functies gebruiken om beheerde toegang te bieden tot aangepaste logica in verschillende contexten op het Databricks-product.
Hoe werken relationele objecten in Delta Live Tables?
Delta Live Tables maakt gebruik van declaratieve syntaxis voor het definiëren en beheren van DDL, DML en infrastructuurimplementatie. Delta Live Tables maakt gebruik van het concept van een 'virtueel schema' tijdens het plannen en uitvoeren van logica. Delta Live-tabellen kunnen communiceren met andere databases in uw Databricks-omgeving en Delta Live Tables kunnen tabellen publiceren en behouden voor het uitvoeren van query's ergens anders door een doeldatabase op te geven in de configuratie-instellingen van de pijplijn.
Alle tabellen die zijn gemaakt in Delta Live Tables zijn Delta-tabellen. Wanneer u Unity Catalog met Delta Live Tables gebruikt, worden alle tabellen beheerd met Unity Catalog. Als Unity Catalog niet actief is, kunnen tabellen worden gedeclareerd als beheerde of niet-beheerde tabellen.
Hoewel weergaven kunnen worden gedeclareerd in Delta Live Tables, moeten deze worden beschouwd als tijdelijke weergaven die zijn gericht op de pijplijn. Tijdelijke tabellen in Delta Live Tables zijn een uniek concept: deze tabellen bevatten gegevens voor opslag, maar publiceren geen gegevens naar de doeldatabase.
Sommige bewerkingen, zoals APPLY CHANGES INTO, registreren zowel een tabel als weergave voor de database. De tabelnaam begint met een onderstrepingsteken (_) en de weergave heeft de tabelnaam gedeclareerd als het doel van de APPLY CHANGES INTO bewerking. De weergave voert een query uit op de bijbehorende verborgen tabel om de resultaten te materialiseren.