Werken met bestanden in Azure Databricks
Azure Databricks biedt meerdere hulpprogramma's en API's voor interactie met bestanden op de volgende locaties:
- Unity Catalog-volumes
- Werkruimtebestanden
- Cloudopslag van objecten
- DBFS-koppelingen en DBFS-hoofdmap
- Tijdelijke opslag die is gekoppeld aan het stuurprogrammaknooppunt van het cluster
Dit artikel bevat voorbeelden voor interactie met bestanden op deze locaties voor de volgende hulpprogramma's:
- Apache Spark
- Spark SQL en Databricks SQL
- Utitlities van het Databricks-bestandssysteem (
dbutils.fsof%fs) - Databricks-CLI
- Databricks REST API
- Bash-shellopdrachten (
%sh) - Installatie van notebook-scoped bibliotheek met behulp van
%pip - Pandas
- OSS Python-hulpprogramma's voor bestandsbeheer en -verwerking
Belangrijk
Bestandsbewerkingen waarvoor FUSE-toegang tot gegevens is vereist, hebben geen rechtstreeks toegang tot de opslag van cloudobjecten met behulp van URI's. Databricks raadt het gebruik van Unity Catalog-volumes aan om de toegang tot deze locaties voor FUSE te configureren.
Scala biedt geen ondersteuning voor FUSE voor Unity Catalog-volumes of werkruimtebestanden op rekenkracht die zijn geconfigureerd met de modus voor toegang van één gebruiker of clusters zonder Unity Catalog. Scala ondersteunt FUSE voor Unity Catalog-volumes en werkruimtebestanden op rekenkracht die zijn geconfigureerd met Unity Catalog en de modus voor gedeelde toegang.
Moet ik een URI-schema opgeven voor toegang tot gegevens?
Paden voor gegevenstoegang in Azure Databricks volgen een van de volgende standaarden:
Paden in URI-stijl bevatten een URI-schema. Voor databricks-systeemeigen oplossingen voor gegevenstoegang zijn URI-schema's optioneel voor de meeste gebruiksvoorbeelden. Wanneer u rechtstreeks toegang hebt tot gegevens in de opslag van cloudobjecten, moet u het juiste URI-schema opgeven voor het opslagtype.

POSIX-paden bieden gegevenstoegang ten opzichte van de hoofdmap van het stuurprogramma (
/). POSIX-paden vereisen nooit een schema. U kunt Unity Catalog-volumes of DBFS-koppelingen gebruiken om POSIX-stijl toegang te bieden tot gegevens in cloudobjectopslag. Voor veel ML-frameworks en andere OSS Python-modules is FUSE vereist en kunnen alleen PADEN in POSIX-stijl worden gebruikt.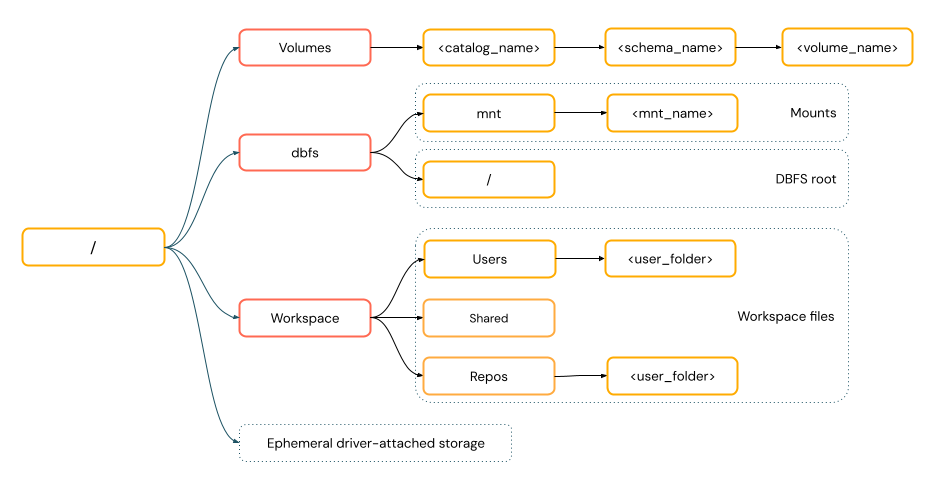
Werken met bestanden in Unity Catalog-volumes
Databricks raadt het gebruik van Unity Catalog-volumes aan om toegang te configureren tot niet-tabellaire gegevensbestanden die zijn opgeslagen in cloudobjectopslag. Zie Maken en werken met volumes.
| Hulpprogramma | Opmerking |
|---|---|
| Apache Spark | spark.read.format("json").load("/Volumes/my_catalog/my_schema/my_volume/data.json").show() |
| Spark SQL en Databricks SQL | SELECT * FROM csv.`/Volumes/my_catalog/my_schema/my_volume/data.csv`; LIST '/Volumes/my_catalog/my_schema/my_volume/'; |
| Hulpprogramma's voor databricks-bestandssysteem | dbutils.fs.ls("/Volumes/my_catalog/my_schema/my_volume/") %fs ls /Volumes/my_catalog/my_schema/my_volume/ |
| Databricks-CLI | databricks fs cp /path/to/local/file dbfs:/Volumes/my_catalog/my_schema/my_volume/ |
| Databricks REST API | POST https://<databricks-instance>/api/2.1/jobs/create {"name": "A multitask job", "tasks": [{..."libraries": [{"jar": "/Volumes/dev/environment/libraries/logging/Logging.jar"}],},...]} |
| Bash-shellopdrachten | %sh curl http://<address>/text.zip -o /Volumes/my_catalog/my_schema/my_volume/tmp/text.zip |
| Bibliotheekinstallaties | %pip install /Volumes/my_catalog/my_schema/my_volume/my_library.whl |
| Pandas | df = pd.read_csv('/Volumes/my_catalog/my_schema/my_volume/data.csv') |
| OSS Python | os.listdir('/Volumes/my_catalog/my_schema/my_volume/path/to/directory') |
Notitie
Het dbfs:/ schema is vereist bij het werken met de Databricks CLI.
Beperkingen voor volumes
Volumes hebben de volgende beperkingen:
Schrijfbewerkingen voor direct toevoegen of niet-sequentiële (willekeurige) schrijfbewerkingen, zoals het schrijven van Zip- en Excel-bestanden, worden niet ondersteund. Voor direct toevoegen of willekeurige schrijfworkloads moet u eerst de bewerkingen uitvoeren op een lokale schijf en vervolgens de resultaten kopiëren naar Unity Catalog-volumes. Voorbeeld:
# python import xlsxwriter from shutil import copyfile workbook = xlsxwriter.Workbook('/local_disk0/tmp/excel.xlsx') worksheet = workbook.add_worksheet() worksheet.write(0, 0, "Key") worksheet.write(0, 1, "Value") workbook.close() copyfile('/local_disk0/tmp/excel.xlsx', '/Volumes/my_catalog/my_schema/my_volume/excel.xlsx')Sparse-bestanden worden niet ondersteund. Als u sparse-bestanden wilt kopiëren, gebruikt u
cp --sparse=never:$ cp sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file error writing '/dbfs/sparse.file': Operation not supported $ cp --sparse=never sparse.file /Volumes/my_catalog/my_schema/my_volume/sparse.file
Werken met werkruimtebestanden
Databricks-werkruimtebestanden zijn de set bestanden in een werkruimte die geen notebooks zijn. U kunt werkruimtebestanden gebruiken om gegevens en andere bestanden op te slaan en te openen die naast notebooks en andere werkruimteassets zijn opgeslagen. Omdat werkruimtebestanden groottebeperkingen hebben, raadt Databricks aan om hier alleen kleine gegevensbestanden op te slaan voor ontwikkeling en testen.
| Hulpprogramma | Opmerking |
|---|---|
| Apache Spark | spark.read.format("json").load("file:/Workspace/Users/<user-folder>/data.json").show() |
| Spark SQL en Databricks SQL | SELECT * FROM json.`file:/Workspace/Users/<user-folder>/file.json`; |
| Hulpprogramma's voor databricks-bestandssysteem | dbutils.fs.ls("file:/Workspace/Users/<user-folder>/") %fs ls file:/Workspace/Users/<user-folder>/ |
| Databricks-CLI | databricks workspace list |
| Databricks REST API | POST https://<databricks-instance>/api/2.0/workspace/delete {"path": "/Workspace/Shared/code.py", "recursive": "false"} |
| Bash-shellopdrachten | %sh curl http://<address>/text.zip -o /Workspace/Users/<user-folder>/text.zip |
| Bibliotheekinstallaties | %pip install /Workspace/Users/<user-folder>/my_library.whl |
| Pandas | df = pd.read_csv('/Workspace/Users/<user-folder>/data.csv') |
| OSS Python | os.listdir('/Workspace/Users/<user-folder>/path/to/directory') |
Notitie
Het file:/ schema is vereist bij het werken met Databricks Utilities, Apache Spark of SQL.
Beperkingen voor werkruimtebestanden
Werkruimtebestanden hebben de volgende beperkingen:
De grootte van het werkruimtebestand is beperkt tot 500 MB vanuit de gebruikersinterface. De maximale bestandsgrootte die is toegestaan bij het schrijven vanuit een cluster is 256 MB.
Als uw werkstroom gebruikmaakt van broncode in een externe Git-opslagplaats, kunt u niet naar de huidige map schrijven of schrijven met behulp van een relatief pad. Schrijf gegevens naar andere locatieopties.
U kunt geen opdrachten gebruiken
gitwanneer u opslaat in werkruimtebestanden. Het maken van.gitmappen is niet toegestaan in werkruimtebestanden.Er is beperkte ondersteuning voor bewerkingen van werkruimtebestanden van serverloze berekeningen.
Uitvoerders kunnen niet schrijven naar werkruimtebestanden.
symlinks worden niet ondersteund.
Werkruimtebestanden kunnen niet worden geopend vanuit door de gebruiker gedefinieerde functies (UDF's) op clusters met de modus voor gedeelde toegang.
Waar gaan verwijderde werkruimtebestanden naartoe?
Als u een werkruimtebestand verwijdert, wordt het naar de prullenbak verzonden. U kunt bestanden herstellen of permanent verwijderen uit de prullenbak met behulp van de gebruikersinterface.
Zie Een object verwijderen.
Werken met bestanden in cloudobjectopslag
Databricks raadt het gebruik van Unity Catalog-volumes aan om beveiligde toegang tot bestanden in cloudobjectopslag te configureren. Als u ervoor kiest om rechtstreeks toegang te krijgen tot gegevens in cloudobjectopslag met behulp van URI's, moet u machtigingen configureren. Zie Externe locaties, externe tabellen en externe volumes beheren.
In de volgende voorbeelden worden URI's gebruikt voor toegang tot gegevens in de opslag van cloudobjecten:
| Hulpprogramma | Opmerking |
|---|---|
| Apache Spark | spark.read.format("json").load("abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json").show() |
| Spark SQL en Databricks SQL | SELECT * FROM csv.`abfss://container-name@storage-account-name.dfs.core.windows.net/path/file.json`; LIST 'abfss://container-name@storage-account-name.dfs.core.windows.net/path'; |
| Hulpprogramma's voor databricks-bestandssysteem | dbutils.fs.ls("abfss://container-name@storage-account-name.dfs.core.windows.net/path/") %fs ls abfss://container-name@storage-account-name.dfs.core.windows.net/path/ |
| Databricks-CLI | Niet ondersteund |
| Databricks REST API | Niet ondersteund |
| Bash-shellopdrachten | Niet ondersteund |
| Bibliotheekinstallaties | %pip install abfss://container-name@storage-account-name.dfs.core.windows.net/path/to/library.whl |
| Pandas | Niet ondersteund |
| OSS Python | Niet ondersteund |
Notitie
Opslag van cloudobjecten biedt geen ondersteuning voor referentiepassthrough.
Werken met bestanden in DBFS-koppelingen en DBFS-hoofdmap
DBFS-koppelingen zijn niet beveiligbaar met behulp van Unity Catalog en worden niet meer aanbevolen door Databricks. Gegevens die zijn opgeslagen in de DBFS-hoofdmap, zijn toegankelijk voor alle gebruikers in de werkruimte. Databricks raadt aan om gevoelige of productiecode of gegevens op te slaan in de DBFS-hoofdmap. Zie Wat is het Databricks File System (DBFS)?.
| Hulpprogramma | Opmerking |
|---|---|
| Apache Spark | spark.read.format("json").load("/mnt/path/to/data.json").show() |
| Spark SQL en Databricks SQL | SELECT * FROM json.`/mnt/path/to/data.json`; |
| Hulpprogramma's voor databricks-bestandssysteem | dbutils.fs.ls("/mnt/path") %fs ls /mnt/path |
| Databricks-CLI | databricks fs cp dbfs:/mnt/path/to/remote/file /path/to/local/file |
| Databricks REST API | POST https://<host>/api/2.0/dbfs/delete --data '{ "path": "/tmp/HelloWorld.txt" }' |
| Bash-shellopdrachten | %sh curl http://<address>/text.zip > /dbfs/mnt/tmp/text.zip |
| Bibliotheekinstallaties | %pip install /dbfs/mnt/path/to/my_library.whl |
| Pandas | df = pd.read_csv('/dbfs/mnt/path/to/data.csv') |
| OSS Python | os.listdir('/dbfs/mnt/path/to/directory') |
Notitie
Het dbfs:/ schema is vereist bij het werken met de Databricks CLI.
Werken met bestanden in tijdelijke opslag die is gekoppeld aan het stuurprogrammaknooppunt
De ephermale opslag die aan het stuurprogrammaknooppunt is gekoppeld, is blokopslag met systeemeigen toegang tot op POSIX gebaseerde padtoegang. Alle gegevens die op deze locatie zijn opgeslagen, verdwijnen wanneer een cluster wordt beëindigd of opnieuw wordt opgestart.
| Hulpprogramma | Opmerking |
|---|---|
| Apache Spark | Niet ondersteund |
| Spark SQL en Databricks SQL | Niet ondersteund |
| Hulpprogramma's voor databricks-bestandssysteem | dbutils.fs.ls("file:/path") %fs ls file:/path |
| Databricks-CLI | Niet ondersteund |
| Databricks REST API | Niet ondersteund |
| Bash-shellopdrachten | %sh curl http://<address>/text.zip > /tmp/text.zip |
| Bibliotheekinstallaties | Niet ondersteund |
| Pandas | df = pd.read_csv('/path/to/data.csv') |
| OSS Python | os.listdir('/path/to/directory') |
Notitie
Het file:/ schema is vereist bij het werken met Databricks Utilities.
Gegevens verplaatsen van tijdelijke opslag naar volumes
Mogelijk wilt u toegang krijgen tot gegevens die zijn gedownload of opgeslagen in tijdelijke opslag met behulp van Apache Spark. Omdat tijdelijke opslag is gekoppeld aan het stuurprogramma en Spark een gedistribueerde verwerkingsengine is, hebben niet alle bewerkingen hier rechtstreeks toegang tot gegevens. Als u gegevens wilt verplaatsen van het bestandssysteem van het stuurprogramma naar Unity Catalog-volumes, kunt u bestanden kopiëren met behulp van magic-opdrachten of de Databricks-hulpprogramma's, zoals in de volgende voorbeelden:
dbutils.fs.cp ("file:/<path>", "/Volumes/<catalog>/<schema>/<volume>/<path>")
%sh cp /<path> /Volumes/<catalog>/<schema>/<volume>/<path>
%fs cp file:/<path> /Volumes/<catalog>/<schema>/<volume>/<path>
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor