Notebooks beheren
U kunt notebooks beheren via de UI, opdrachtregelinterface en de werkruimte-API. Dit artikel is gericht op het uitvoeren van notebooktaken met behulp van de gebruikersinterface. Zie Wat is de Databricks CLI ende naslaginformatie over de Werkruimte-API voor de andere methoden.
Een notitieblok maken
De knop Nieuw in de zijbalk van de werkruimte gebruiken
Als u een nieuw notitieblok wilt maken in de standaardmap, klikt u op ![]() Nieuw in de zijbalk en selecteert u Notitieblok in het menu.
Nieuw in de zijbalk en selecteert u Notitieblok in het menu.
Databricks maakt en opent een nieuw, leeg notitieblok in uw standaardmap. De standaardtaal is de taal die u het laatst hebt gebruikt en het notebook wordt automatisch gekoppeld aan de rekenresource die u het laatst hebt gebruikt.
Een notitieblok maken in elke map
U kunt een nieuw notitieblok maken in elke map (bijvoorbeeld in de gedeelde map) door de volgende stappen uit te voeren:
- Klik in de zijbalk op
 Werkruimte.
Werkruimte. - Klik met de rechtermuisknop op de naam van een map en selecteer Notitieblok maken>. Er wordt een leeg notitieblok geopend in de werkruimte.
Een notebook openen
Klik in uw werkruimte op een ![]() . Het notitieblokpad wordt weergegeven wanneer u de muisaanwijzer boven de titel van het notitieblok beweegt.
. Het notitieblokpad wordt weergegeven wanneer u de muisaanwijzer boven de titel van het notitieblok beweegt.
Een notebook verwijderen
Zie Mappen en Werkruimte-objectbewerkingen voor informatie over het openen van het werkruimtemenu en het verwijderen van notebooks of andere items in de werkruimte.
Notebookpad of URL kopiëren
Als u het pad of de URL van het notitieblok wilt ophalen zonder het notitieblok te openen, klikt u met de rechtermuisknop op de naam van het notitieblok en selecteert u Pad kopiëren of URL kopiëren>>.
De naam van een notebook wijzigen
Als u de titel van een geopend notitieblok wilt wijzigen, klikt u op de titel en bewerkt u inline of klikt u op Naam van bestand > wijzigen.
Toegang tot een notebook beheren
Als uw Azure Databricks-account het Premium-abonnement heeft, kunt u toegangsbeheer voor werkruimten gebruiken om te bepalen wie toegang heeft tot een notebook.
Editorinstellingen configureren
Editorinstellingen configureren:
- Klik op uw gebruikersnaam rechtsboven in de werkruimte en selecteer Instellingen in de vervolgkeuzelijst.
- Selecteer Ontwikkelaars in de zijbalk van Instellingen.
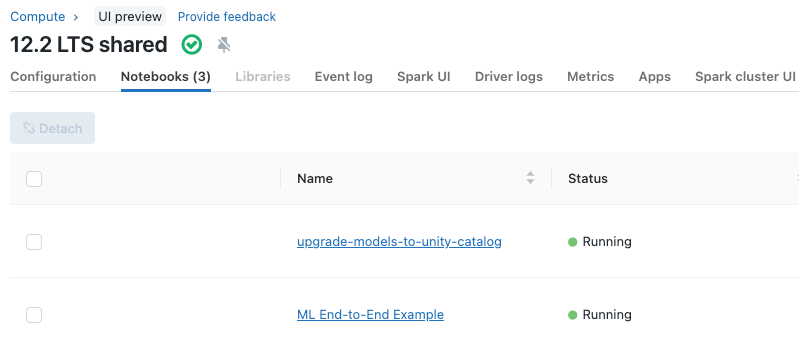
Notitieblokken weergeven die zijn gekoppeld aan een cluster
Op het tabblad Notitieblokken op de pagina met clusterdetails worden notitieblokken weergegeven die onlangs aan een cluster zijn gekoppeld. Op het tabblad wordt ook de status van het notitieblok weergegeven, samen met de laatste keer dat een opdracht is uitgevoerd vanuit het notebook.