Binair bestand
Databricks Runtime ondersteunt de binaire bestandsgegevensbron , die binaire bestanden leest en elk bestand converteert naar één record die de onbewerkte inhoud en metagegevens van het bestand bevat. De gegevensbron van het binaire bestand produceert een DataFrame met de volgende kolommen en mogelijk partitiekolommen:
path (StringType): het pad van het bestand.modificationTime (TimestampType): De wijzigingstijd van het bestand. In sommige Hadoop FileSystem-implementaties is deze parameter mogelijk niet beschikbaar en wordt de waarde ingesteld op een standaardwaarde.length (LongType): De lengte van het bestand in bytes.content (BinaryType): De inhoud van het bestand.
Als u binaire bestanden wilt lezen, geeft u de gegevensbron format op als binaryFile.
Afbeeldingen
Databricks raadt u aan de binaire bestandsgegevensbron te gebruiken om afbeeldingsgegevens te laden.
De Databricks-functie display ondersteunt het weergeven van afbeeldingsgegevens die zijn geladen met behulp van de binaire gegevensbron.
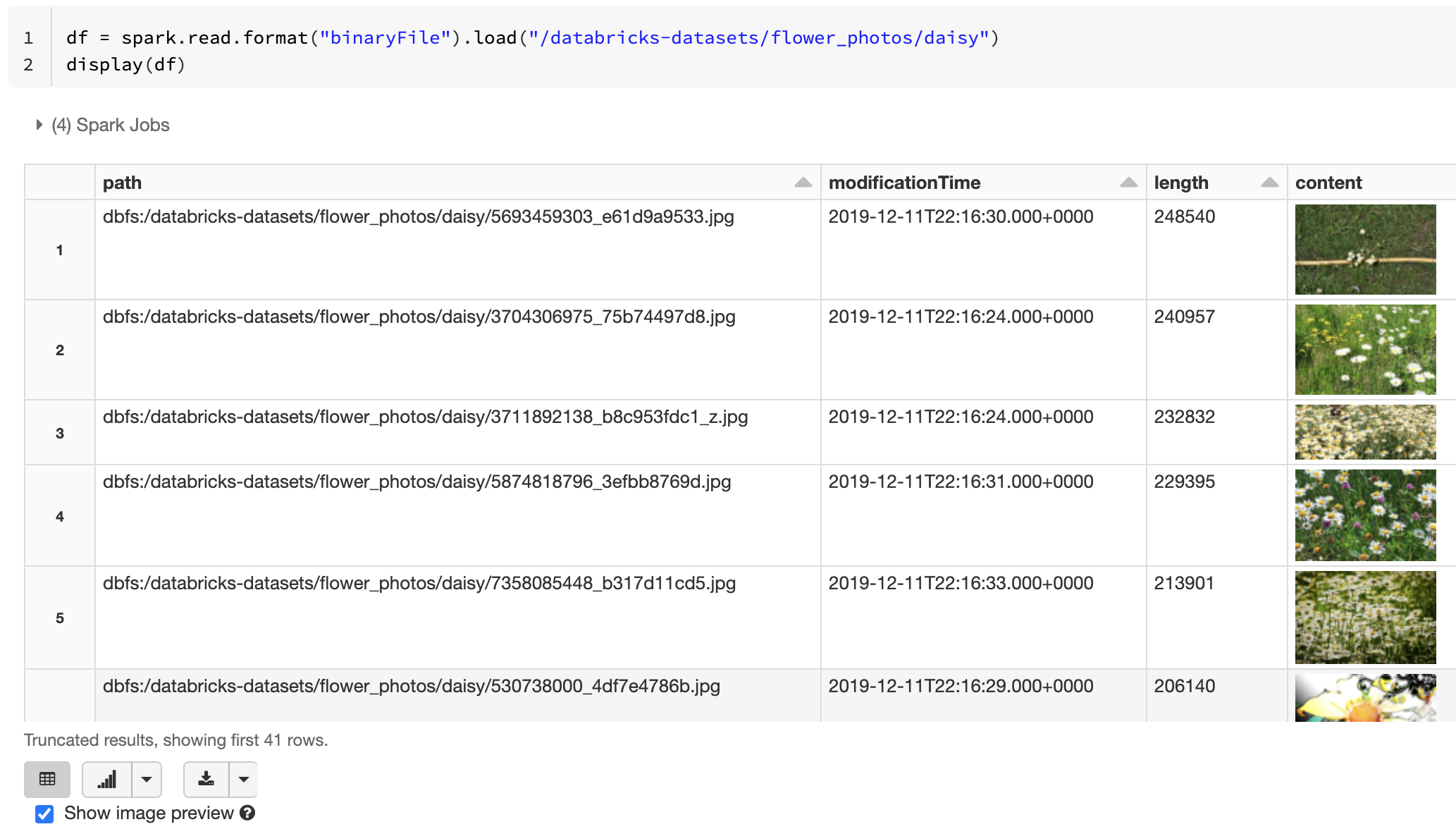
Als alle geladen bestanden een bestandsnaam hebben met een afbeeldingsextensie, wordt het voorbeeld van de installatiekopieën automatisch ingeschakeld:
df = spark.read.format("binaryFile").load("<path-to-image-dir>")
display(df) # image thumbnails are rendered in the "content" column
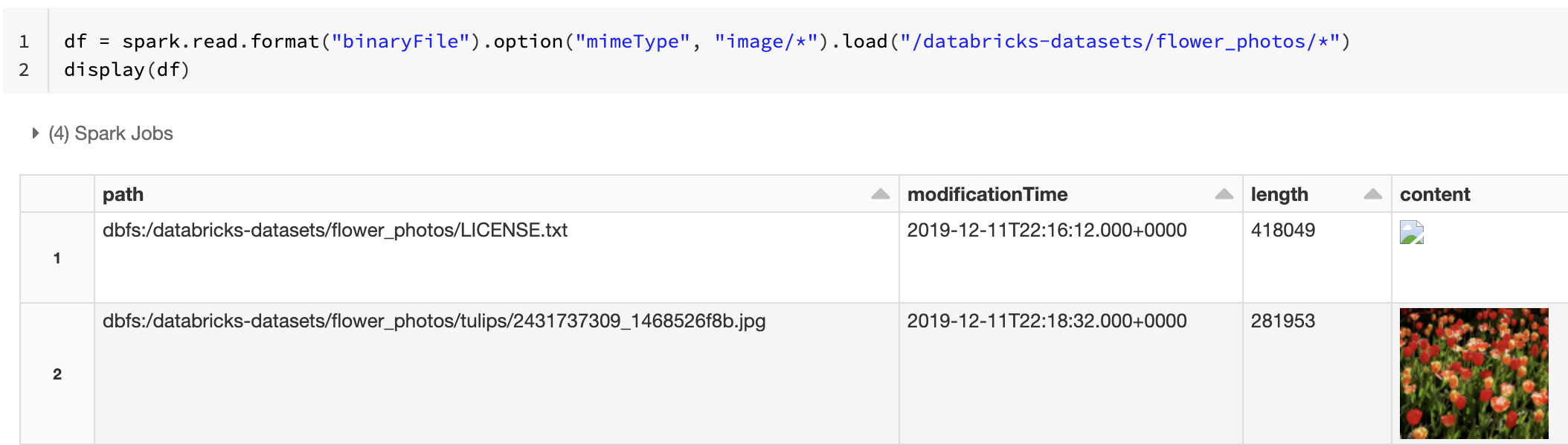
U kunt ook de preview-functionaliteit van de afbeelding afdwingen met behulp van de mimeType optie met een tekenreekswaarde "image/*" om aantekeningen te maken op de binaire kolom. Afbeeldingen worden gedecodeerd op basis van hun indelingsgegevens in de binaire inhoud. Ondersteunde afbeeldingstypen zijn bmp, gifen jpegpng. Niet-ondersteunde bestanden worden weergegeven als een pictogram van een gebroken afbeelding.
df = spark.read.format("binaryFile").option("mimeType", "image/*").load("<path-to-dir>")
display(df) # unsupported files are displayed as a broken image icon
Zie de referentieoplossing voor afbeeldingstoepassingen voor de aanbevolen werkstroom voor het verwerken van afbeeldingsgegevens.
Opties
Als u bestanden wilt laden met paden die overeenkomen met een bepaald glob-patroon terwijl het gedrag van partitiedetectie behouden blijft, kunt u de pathGlobFilter optie gebruiken. De volgende code leest alle JPG-bestanden uit de invoermap met partitiedetectie:
df = spark.read.format("binaryFile").option("pathGlobFilter", "*.jpg").load("<path-to-dir>")
Als u partitiedetectie wilt negeren en recursief bestanden wilt zoeken in de invoermap, gebruikt u de recursiveFileLookup optie. Met deze optie wordt gezocht in geneste mappen, zelfs als hun namen geen partitienaamschema volgen, zoals date=2019-07-01.
De volgende code leest alle JPG-bestanden recursief uit de invoermap en negeert partitiedetectie:
df = spark.read.format("binaryFile") \
.option("pathGlobFilter", "*.jpg") \
.option("recursiveFileLookup", "true") \
.load("<path-to-dir>")
Er bestaan vergelijkbare API's voor Scala, Java en R.
Notitie
Om de leesprestaties te verbeteren wanneer u gegevens terug laadt, raadt Azure Databricks aan om compressie uit te schakelen wanneer u gegevens opslaat die zijn geladen vanuit binaire bestanden:
spark.conf.set("spark.sql.parquet.compression.codec", "uncompressed")
df.write.format("delta").save("<path-to-table>")