Lees- en schrijfbewerkingen voor Delta-tabellen
Delta Lake is diep geïntegreerd met Spark Structured Streaming via readStream en writeStream. Delta Lake overwint veel van de beperkingen die doorgaans worden geassocieerd met streamingsystemen en bestanden, waaronder:
- Het samenvoegen van kleine bestanden die worden geproduceerd door opname met lage latentie.
- Het 'exactly-once' verwerken met meer dan één stroom (of gelijktijdige batchtaken).
- Efficiënt detecteren welke bestanden nieuw zijn bij het gebruik van bestanden als bron voor een stream.
Notitie
In dit artikel wordt beschreven hoe u Delta Lake-tabellen gebruikt als streamingbronnen en sinks. Zie Gegevens laden met behulp van streamingtabellen in Databricks SQL voor meer informatie over het laden van gegevens met behulp van streamingtabellen in Databricks SQL.
Delta-tabel als bron
Gestructureerde streaming leest incrementeel Delta-tabellen. Hoewel een streamingquery actief is voor een Delta-tabel, worden nieuwe records idempotent verwerkt als nieuwe tabelversies doorvoeren naar de brontabel.
In de volgende codevoorbeelden ziet u hoe u een streaming-leesbewerking configureert met behulp van de tabelnaam of het bestandspad.
Python
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Scala
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Belangrijk
Als het schema voor een Delta-tabel wordt gewijzigd nadat een streaming-leesbewerking voor de tabel is gestart, mislukt de query. Voor de meeste schemawijzigingen kunt u de stream opnieuw starten om niet-overeenkomende schema's op te lossen en door te gaan met de verwerking.
In Databricks Runtime 12.2 LTS en hieronder kunt u niet streamen vanuit een Delta-tabel waarvoor kolomtoewijzing is ingeschakeld die niet-additieve schemaontwikkeling heeft ondergaan, zoals het wijzigen of verwijderen van kolommen. Zie Streaming met kolomtoewijzing en schemawijzigingen voor meer informatie.
Invoersnelheid beperken
De volgende opties zijn beschikbaar voor het beheren van microbatches:
maxFilesPerTrigger: hoeveel nieuwe bestanden in elke microbatch moeten worden overwogen. De standaardwaarde is 1000.maxBytesPerTrigger: Hoeveel gegevens worden verwerkt in elke microbatch. Met deze optie stelt u een 'voorlopig maximum' in, wat betekent dat een batch ongeveer deze hoeveelheid gegevens verwerkt en meer dan de limiet kan verwerken om de streamingquery vooruit te laten gaan in gevallen waarin de kleinste invoereenheid groter is dan deze limiet. Dit is niet standaard ingesteld.
Als u in combinatie met maxFilesPerTriggerde microbatch gegevens verwerkt maxBytesPerTrigger totdat de maxFilesPerTrigger of maxBytesPerTrigger limiet is bereikt.
Notitie
In gevallen waarin de brontabeltransacties worden opgeschoond vanwege de logRetentionDurationconfiguratie en de streamingquery deze versies probeert te verwerken, kan de query standaard geen gegevensverlies voorkomen. U kunt de optie failOnDataLoss instellen om false verloren gegevens te negeren en door te gaan met verwerken.
Een CDC-feed (Delta Lake Change Data Capture) streamen
Delta Lake-wijzigingenfeed registreert wijzigingen in een Delta-tabel, inclusief updates en verwijderingen. Wanneer deze functie is ingeschakeld, kunt u streamen vanuit een wijzigingengegevensfeed en logica schrijven voor het verwerken van invoegingen, updates en verwijderingen in downstreamtabellen. Hoewel de gegevensuitvoer van wijzigingenfeeds enigszins verschilt van de Delta-tabel die wordt beschreven, biedt dit een oplossing voor het doorgeven van incrementele wijzigingen aan downstreamtabellen in een medal queryarchitectuur.
Belangrijk
In Databricks Runtime 12.2 LTS en hieronder kunt u niet streamen vanuit de wijzigingengegevensfeed voor een Delta-tabel waarvoor kolomtoewijzing is ingeschakeld die niet-additieve schemaontwikkeling heeft ondergaan, zoals het wijzigen of verwijderen van kolommen. Zie Streaming met kolomtoewijzing en schemawijzigingen.
Updates en verwijderingen negeren
Structured Streaming verwerkt geen invoer die geen toevoeg is en genereert een uitzondering als er wijzigingen optreden in de tabel die als bron wordt gebruikt. Er zijn twee belangrijke strategieën voor het verwerken van wijzigingen die niet automatisch downstream kunnen worden doorgegeven:
- U kunt de uitvoer en het controlepunt verwijderen en de stream opnieuw starten vanaf het begin.
- U kunt een van deze twee opties instellen:
ignoreDeletes: transacties negeren die gegevens op partitiegrenzen verwijderen.skipChangeCommits: transacties negeren die bestaande records verwijderen of wijzigen.skipChangeCommitsondergaatignoreDeletes.
Notitie
In Databricks Runtime 12.2 LTS en hoger skipChangeCommits wordt de vorige instelling ignoreChangesafgeschaft. In Databricks Runtime 11.3 LTS en lager ignoreChanges is dit de enige ondersteunde optie.
De semantiek voor ignoreChanges verschilt sterk van skipChangeCommits. Met ignoreChanges ingeschakeld worden herschreven gegevensbestanden in de brontabel opnieuw verzonden na een bewerking voor het wijzigen van gegevens, zoals UPDATE, MERGE INTO( DELETE binnen partities) of OVERWRITE. Ongewijzigde rijen worden vaak samen met nieuwe rijen verzonden, dus downstreamgebruikers moeten dubbele waarden kunnen verwerken. Verwijderingen worden niet downstream doorgegeven. ignoreChanges ondergaat ignoreDeletes.
skipChangeCommits negeert bewerkingen voor het wijzigen van bestanden volledig. Gegevensbestanden die in de brontabel worden herschreven als gevolg van het wijzigen van gegevens, zoals UPDATE, MERGE INTO, DELETEen OVERWRITE , worden volledig genegeerd. Als u wijzigingen in upstream-brontabellen wilt weergeven, moet u afzonderlijke logica implementeren om deze wijzigingen door te geven.
Workloads die zijn geconfigureerd met ignoreChanges continue werking met behulp van bekende semantiek, maar Databricks raadt het gebruik skipChangeCommits aan voor alle nieuwe workloads. Voor het migreren van workloads die worden gebruikt ignoreChanges om herstructureringslogica te skipChangeCommits vereisen.
Opmerking
Stel dat u een tabel user_events hebt met date, user_emailen action kolommen die zijn gepartitioneerd door date. U streamt uit de user_events tabel en u moet er gegevens uit verwijderen vanwege de AVG.
Wanneer u op partitiegrenzen verwijdert (dat wil gezegd, de WHERE bestanden zich in een partitiekolom bevinden), worden de bestanden al gesegmenteerd op waarde, zodat de verwijdering deze bestanden alleen uit de metagegevens verwijdert. Wanneer u een volledige partitie met gegevens verwijdert, kunt u het volgende gebruiken:
spark.readStream.format("delta")
.option("ignoreDeletes", "true")
.load("/tmp/delta/user_events")
Als u gegevens in meerdere partities verwijdert (in dit voorbeeld filteren op user_email), gebruikt u de volgende syntaxis:
spark.readStream.format("delta")
.option("skipChangeCommits", "true")
.load("/tmp/delta/user_events")
Als u een user_email bijwerkt met de UPDATE instructie, wordt het bestand met de user_email betreffende instructie herschreven. Gebruik skipChangeCommits dit om de gewijzigde gegevensbestanden te negeren.
Beginpositie opgeven
U kunt de volgende opties gebruiken om het beginpunt van de Delta Lake-streamingbron op te geven zonder de hele tabel te verwerken.
startingVersion: De Delta Lake-versie om van te beginnen. Databricks raadt aan deze optie voor de meeste workloads weg te laten. Als deze niet is ingesteld, begint de stream vanaf de meest recente beschikbare versie, inclusief een volledige momentopname van de tabel op dat moment.Indien opgegeven, leest de stream alle wijzigingen in de Delta-tabel vanaf de opgegeven versie (inclusief). Als de opgegeven versie niet meer beschikbaar is, kan de stream niet worden gestart. U kunt de doorvoerversies verkrijgen uit de
versionkolom van de uitvoer van de opdracht DESCRIBE HISTORY .Als u alleen de meest recente wijzigingen wilt retourneren, geeft u op
latest.startingTimestamp: het tijdstempel waaruit moet worden gestart. Alle tabelwijzigingen die zijn doorgevoerd op of na de tijdstempel (inclusief) worden gelezen door de streaminglezer. Als de opgegeven tijdstempel voorafgaat aan alle tabeldoorvoeringen, begint de streaming-leesbewerking met de vroegste beschikbare tijdstempel. Een van de volgende:- Een tijdstempeltekenreeks. Bijvoorbeeld:
"2019-01-01T00:00:00.000Z". - Een datumtekenreeks. Bijvoorbeeld:
"2019-01-01".
- Een tijdstempeltekenreeks. Bijvoorbeeld:
U kunt beide opties niet tegelijk instellen. Ze worden alleen van kracht wanneer een nieuwe streamingquery wordt gestart. Als een streamingquery is gestart en de voortgang is vastgelegd in het controlepunt, worden deze opties genegeerd.
Belangrijk
Hoewel u de streamingbron vanuit een opgegeven versie of tijdstempel kunt starten, is het schema van de streamingbron altijd het meest recente schema van de Delta-tabel. U moet ervoor zorgen dat er geen incompatibele schemawijziging in de Delta-tabel is na de opgegeven versie of tijdstempel. Anders kan de streamingbron onjuiste resultaten retourneren bij het lezen van de gegevens met een onjuist schema.
Opmerking
Stel dat u een tabel user_eventshebt. Als u wijzigingen wilt lezen sinds versie 5, gebruikt u:
spark.readStream.format("delta")
.option("startingVersion", "5")
.load("/tmp/delta/user_events")
Als u wijzigingen wilt lezen sinds 2018-10-18, gebruikt u:
spark.readStream.format("delta")
.option("startingTimestamp", "2018-10-18")
.load("/tmp/delta/user_events")
Eerste momentopname verwerken zonder dat gegevens worden verwijderd
Notitie
Deze functie is beschikbaar in Databricks Runtime 11.3 LTS en hoger. Deze functie is beschikbaar als openbare preview.
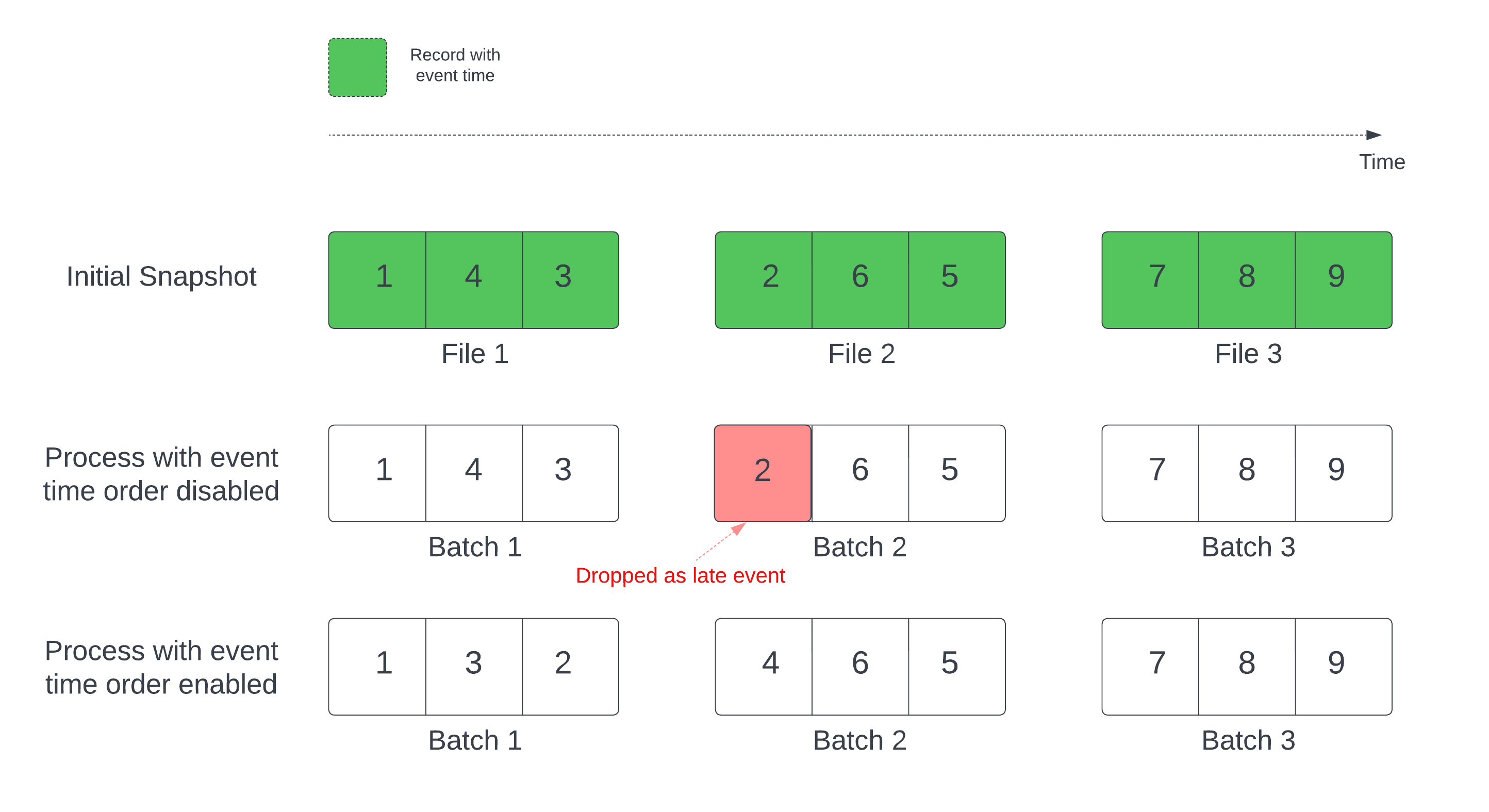
Wanneer u een Delta-tabel als stroombron gebruikt, verwerkt de query eerst alle gegevens die aanwezig zijn in de tabel. De Delta-tabel in deze versie wordt de eerste momentopname genoemd. Standaard worden de gegevensbestanden van de Delta-tabel verwerkt op basis van welk bestand het laatst is gewijzigd. De laatste wijzigingstijd vertegenwoordigt echter niet noodzakelijkerwijs de volgorde van de gebeurtenistijd van de record.
In een stateful streamingquery met een gedefinieerd watermerk kunnen het verwerken van bestanden door wijzigingstijd ertoe leiden dat records in de verkeerde volgorde worden verwerkt. Dit kan ertoe leiden dat records worden verwijderd als latere gebeurtenissen door het watermerk.
U kunt het probleem met gegevensuitval voorkomen door de volgende optie in te schakelen:
- withEventTimeOrder: Hiermee wordt aangegeven of de eerste momentopname moet worden verwerkt met gebeurtenistijdvolgorde.
Als gebeurtenistijdvolgorde is ingeschakeld, wordt het tijdsbereik van de eerste momentopnamegegevens onderverdeeld in tijdbuckets. Elke microbatch verwerkt een bucket door gegevens binnen het tijdsbereik te filteren. De configuratieopties maxFilesPerTrigger en maxBytesPerTrigger zijn nog steeds van toepassing om de microbatchgrootte te beheren, maar alleen op een geschatte manier vanwege de aard van de verwerking.
In de onderstaande afbeelding ziet u dit proces:
Belangrijke informatie over deze functie:
- Het probleem met het verwijderen van gegevens treedt alleen op wanneer de eerste Delta-momentopname van een stateful streaming-query wordt verwerkt in de standaardvolgorde.
- U kunt niet wijzigen
withEventTimeOrderzodra de streamquery is gestart terwijl de eerste momentopname nog steeds wordt verwerkt. Als u opnieuw wilt opstarten metwithEventTimeOrdergewijzigd, moet u het controlepunt verwijderen. - Als u een streamquery uitvoert waarvoorEventTimeOrder is ingeschakeld, kunt u deze niet downgraden naar een DBR-versie die deze functie pas ondersteunt als de eerste momentopnameverwerking is voltooid. Als u een downgrade wilt uitvoeren, kunt u wachten tot de eerste momentopname is voltooid of het controlepunt verwijderen en de query opnieuw starten.
- Deze functie wordt niet ondersteund in de volgende ongebruikelijke scenario's:
- De gebeurtenistijdkolom is een gegenereerde kolom en er zijn niet-projectietransformaties tussen de Delta-bron en het watermerk.
- Er is een watermerk met meer dan één Delta-bron in de stroomquery.
- Als gebeurtenistijdvolgorde is ingeschakeld, kunnen de prestaties van de initiële verwerking van de Delta-momentopname langzamer zijn.
- Elke microbatch scant de eerste momentopname om gegevens binnen het bijbehorende tijdsbereik van de gebeurtenis te filteren. Voor een snellere filteractie is het raadzaam om een Delta-bronkolom te gebruiken als gebeurtenistijd, zodat gegevens kunnen worden overgeslagen (controleer het overslaan van gegevens voor Delta Lake wanneer deze van toepassing is). Daarnaast kan tabelpartitionering langs de kolom gebeurtenistijd de verwerking verder versnellen. U kunt de Spark-gebruikersinterface controleren om te zien hoeveel Delta-bestanden worden gescand op een specifieke microbatch.
Opmerking
Stel dat u een tabel user_events met een event_time kolom hebt. Uw streamingquery is een aggregatiequery. Als u er zeker van wilt zijn dat er geen gegevens worden wegvallen tijdens de eerste momentopnameverwerking, kunt u het volgende gebruiken:
spark.readStream.format("delta")
.option("withEventTimeOrder", "true")
.load("/tmp/delta/user_events")
.withWatermark("event_time", "10 seconds")
Notitie
U kunt dit ook inschakelen met Spark-configuratie op het cluster dat van toepassing is op alle streamingquery's: spark.databricks.delta.withEventTimeOrder.enabled true
Delta-tabel als sink
U kunt ook gegevens naar een Delta-tabel schrijven met structured streaming. Met het transactielogboek kan Delta Lake exact één keer verwerken, zelfs wanneer er andere streams of batchquery's gelijktijdig worden uitgevoerd op de tabel.
Notitie
De functie Delta Lake VACUUM verwijdert alle bestanden die niet worden beheerd door Delta Lake, maar slaat alle mappen over die beginnen met _. U kunt controlepunten veilig opslaan naast andere gegevens en metagegevens voor een Delta-tabel met behulp van een mapstructuur, zoals <table-name>/_checkpoints.
Metrische gegevens voor
U vindt het aantal bytes en het aantal bestanden dat nog moet worden verwerkt in een streamingqueryproces als de numBytesOutstanding metrische numFilesOutstanding gegevens. Aanvullende metrische gegevens zijn onder andere:
numNewListedFiles: Het aantal Delta Lake-bestanden dat is vermeld om de achterstand voor deze batch te berekenen.backlogEndOffset: De tabelversie die wordt gebruikt om de achterstand te berekenen.
Als u de stream uitvoert in een notebook, ziet u deze metrische gegevens op het tabblad Onbewerkte gegevens in het voortgangsdashboard voor streamingquery's:
{
"sources" : [
{
"description" : "DeltaSource[file:/path/to/source]",
"metrics" : {
"numBytesOutstanding" : "3456",
"numFilesOutstanding" : "8"
},
}
]
}
Toevoegmodus
Standaard worden stromen uitgevoerd in de toevoegmodus, waarmee nieuwe records aan de tabel worden toegevoegd.
U kunt de padmethode gebruiken:
Python
(events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/_checkpoints/")
.start("/delta/events")
)
Scala
events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.start("/tmp/delta/events")
of de toTable methode, als volgt:
Python
(events.writeStream
.format("delta")
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
Scala
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Volledige modus
U kunt Structured Streaming ook gebruiken om de hele tabel te vervangen door elke batch. Een voorbeeld van een use case is het berekenen van een samenvatting met behulp van aggregatie:
Python
(spark.readStream
.format("delta")
.load("/tmp/delta/events")
.groupBy("customerId")
.count()
.writeStream
.format("delta")
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.start("/tmp/delta/eventsByCustomer")
)
Scala
spark.readStream
.format("delta")
.load("/tmp/delta/events")
.groupBy("customerId")
.count()
.writeStream
.format("delta")
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.start("/tmp/delta/eventsByCustomer")
In het voorgaande voorbeeld wordt continu een tabel bijgewerkt die het geaggregeerde aantal gebeurtenissen per klant bevat.
Voor toepassingen met meer soepele latentievereisten kunt u rekenresources besparen met eenmalige triggers. Gebruik deze om samenvattingsaggregatietabellen volgens een bepaalde planning bij te werken, waarbij alleen nieuwe gegevens worden verwerkt die sinds de laatste update zijn aangekomen.
Stream-static joins uitvoeren
U kunt vertrouwen op de transactionele garanties en het versiebeheerprotocol van Delta Lake om stream-statische joins uit te voeren. Een stroom-statische join voegt de meest recente geldige versie van een Delta-tabel (de statische gegevens) toe aan een gegevensstroom met behulp van een stateless join.
Wanneer Azure Databricks een microbatch met gegevens verwerkt in een stroomstatische join, wordt de meest recente geldige versie van gegevens uit de statische Delta-tabel samengevoegd met de records die aanwezig zijn in de huidige microbatch. Omdat de join staatloos is, hoeft u geen watermerken te configureren en resultaten met lage latentie te verwerken. De gegevens in de statische Delta-tabel die in de join worden gebruikt, moeten langzaam worden gewijzigd.
streamingDF = spark.readStream.table("orders")
staticDF = spark.read.table("customers")
query = (streamingDF
.join(staticDF, streamingDF.customer_id==staticDF.id, "inner")
.writeStream
.option("checkpointLocation", checkpoint_path)
.table("orders_with_customer_info")
)
Upsert van streamingquery's met behulp van foreachBatch
U kunt een combinatie van merge en foreachBatch complexe upserts schrijven vanuit een streamingquery naar een Delta-tabel. Zie foreachBatch gebruiken om naar willekeurige gegevens-sinks te schrijven.
Dit patroon heeft veel toepassingen, waaronder de volgende:
- Streamingaggregaties schrijven in de updatemodus: dit is veel efficiënter dan de volledige modus.
- Een stroom databasewijzigingen schrijven in een Delta-tabel: de samenvoegquery voor het schrijven van wijzigingsgegevens kan worden gebruikt
foreachBatchom continu een stroom wijzigingen toe te passen op een Delta-tabel. - Een gegevensstroom schrijven naar een Delta-tabel met ontdubbeling: De samenvoegquery alleen-invoegen voor ontdubbeling kan worden gebruikt
foreachBatchom continu gegevens (met duplicaten) naar een Delta-tabel te schrijven met automatische ontdubbeling.
Notitie
- Zorg ervoor dat uw
mergeinstructieforeachBatchidempotent is als het opnieuw opstarten van de streamingquery de bewerking meerdere keren op dezelfde batch met gegevens kan toepassen. - Wanneer
mergedeze wordt gebruiktforeachBatch, kan de invoergegevenssnelheid van de streamingquery (gerapporteerd viaStreamingQueryProgressen zichtbaar in de grafiek van de notebooksnelheid) worden gerapporteerd als een veelvoud van de werkelijke snelheid waarmee gegevens worden gegenereerd bij de bron. Dit komt doordatmergede invoergegevens meerdere keren leest, waardoor de metrische invoergegevens worden vermenigvuldigd. Als dit een knelpunt is, kunt u de batch DataFrame vóórmergein de cache opslaan en de cache vervolgens namergeuit de cache halen.
In het volgende voorbeeld ziet u hoe u SQL kunt gebruiken om foreachBatch deze taak uit te voeren:
Scala
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
U kunt er ook voor kiezen om de Delta Lake-API's te gebruiken om streaming-upserts uit te voeren, zoals in het volgende voorbeeld:
Scala
import io.delta.tables.*
val deltaTable = DeltaTable.forPath(spark, "/data/aggregates")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
Python
from delta.tables import *
deltaTable = DeltaTable.forPath(spark, "/data/aggregates")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.format("delta")
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Idempotente tabelschrijfbewerkingen in foreachBatch
Notitie
Databricks raadt u aan een afzonderlijke streaming-schrijfbewerking te configureren voor elke sink die u wilt bijwerken. Als foreachBatch u naar meerdere tabellen schrijft, worden schrijfbewerkingen geserialiseerd, waardoor parallelizaiton wordt verminderd en de algehele latentie toeneemt.
Delta-tabellen ondersteunen de volgende DataFrameWriter opties om schrijfbewerkingen naar meerdere tabellen binnen foreachBatch idempotent te maken:
txnAppId: Een unieke tekenreeks die u kunt doorgeven aan elke DataFrame-schrijfbewerking. U kunt bijvoorbeeld de StreamingQuery-id gebruiken alstxnAppId.txnVersion: Een monotonisch toenemend getal dat fungeert als transactieversie.
Delta Lake gebruikt de combinatie van txnAppId en txnVersion om dubbele schrijfbewerkingen te identificeren en te negeren.
Als een batch-schrijfbewerking wordt onderbroken door een fout, gebruikt het opnieuw uitvoeren van de batch dezelfde toepassing en batch-id om de runtime te helpen dubbele schrijfbewerkingen correct te identificeren en te negeren. Toepassings-id (txnAppId) kan elke door de gebruiker gegenereerde unieke tekenreeks zijn en hoeft niet gerelateerd te zijn aan de stream-id. Zie foreachBatch gebruiken om naar willekeurige gegevens-sinks te schrijven.
Waarschuwing
Als u het streamingcontrolepunt verwijdert en de query opnieuw start met een nieuw controlepunt, moet u een ander txnAppIditem opgeven. Nieuwe controlepunten beginnen met een batch-id van 0. Delta Lake gebruikt de batch-id en txnAppId als een unieke sleutel en slaat batches met al geziene waarden over.
In het volgende codevoorbeeld ziet u dit patroon:
Python
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
Scala
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}