Voorbeeld van Apache Spark-streaming (DStream) met Apache Kafka in HDInsight
Meer informatie over het gebruik van Apache Spark om gegevens te streamen naar of uit Apache Kafka in HDInsight met behulp van DStreams. In dit voorbeeld wordt een Jupyter Notebook gebruikt dat wordt uitgevoerd op het Spark-cluster.
Notitie
Met de stappen in dit document wordt een Azure-resourcegroep gemaakt die zowel een Spark in HDInsight- als een Kafka in HDInsight-cluster bevat. Deze clusters bevinden zich beide binnen een Azure Virtual Network, waardoor het Spark-cluster rechtstreeks kan communiceren met het Kafka-cluster.
Nadat u de stappen in dit document hebt doorlopen, moet u niet vergeten de clusters te verwijderen om overtollige kosten te voorkomen.
Belangrijk
In dit voorbeeld wordt DStreams gebruikt. Dit is een oudere Spark-streamingtechnologie. Zie het Spark Structured Streaming-document met Apache Kafka voor een voorbeeld dat gebruikmaakt van nieuwere Spark-streamingfuncties.
De clusters maken
Apache Kafka in HDInsight biedt geen toegang tot de Kafka-brokers via het openbare internet. Alles wat met Kafka praat, moet zich in hetzelfde virtuele Azure-netwerk bevinden als de knooppunten in het Kafka-cluster. In dit voorbeeld bevinden de Kafka- en Spark-clusters zich in een virtueel Azure-netwerk. In het volgende diagram ziet u hoe de communicatie tussen de clusters verloopt:
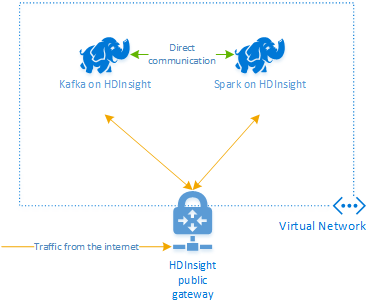
Notitie
Hoewel Kafka zelf beperkt is tot communicatie binnen het virtuele netwerk, kunnen andere services op het cluster, zoals SSH en Ambari, worden geopend via internet. Zie Poorten en URI's die worden gebruikt door HDInsight voor meer informatie over de openbare poorten die beschikbaar zijn voor HDInsight.
Hoewel u handmatig een virtueel Azure-netwerk, Kafka en Spark-clusters kunt maken, is het eenvoudiger om een Azure Resource Manager-sjabloon te gebruiken. Gebruik de volgende stappen om een virtueel Azure-netwerk, Kafka en Spark-clusters te implementeren in uw Azure-abonnement.
Gebruik de volgende knop om u aan te melden bij Azure en de sjabloon in de Azure Portal te openen.

Waarschuwing
Om de beschikbaarheid van Kafka in HDInsight te garanderen, moet uw cluster ten minste vier werkknooppunten bevatten. Met deze sjabloon maakt u een Kafka-cluster met vier werkknooppunten.
Met deze sjabloon maakt u een HDInsight 4.0-cluster voor kafka en Spark.
Gebruik de volgende informatie om de vermeldingen in de sectie Aangepaste implementatie in te vullen:
Eigenschappen Weergegeven als Resourcegroep Maak een groep of selecteer een bestaande groep. Locatie Selecteer een locatie die geografisch dicht bij u in de buurt ligt. Naam van basiscluster Deze waarde wordt gebruikt als de basisnaam voor de Spark- en Kafka-clusters. Als u bijvoorbeeld hdistreaming invoert, wordt een Spark-cluster gemaakt met de naam spark-hdistreaming en een Kafka-cluster met de naam kafka-hdistreaming. Gebruikersnaam voor clusteraanmelding De gebruikersnaam van de beheerder voor de Spark- en Kafka-clusters. Wachtwoord voor clusteraanmelding Het beheerderswachtwoord voor de Spark- en Kafka-clusters. SSH-gebruikersnaam De SSH-gebruiker die moet worden gemaakt voor de Spark- en Kafka-clusters. SSH-wachtwoord Het wachtwoord voor de SSH-gebruiker voor de Spark- en Kafka-clusters. 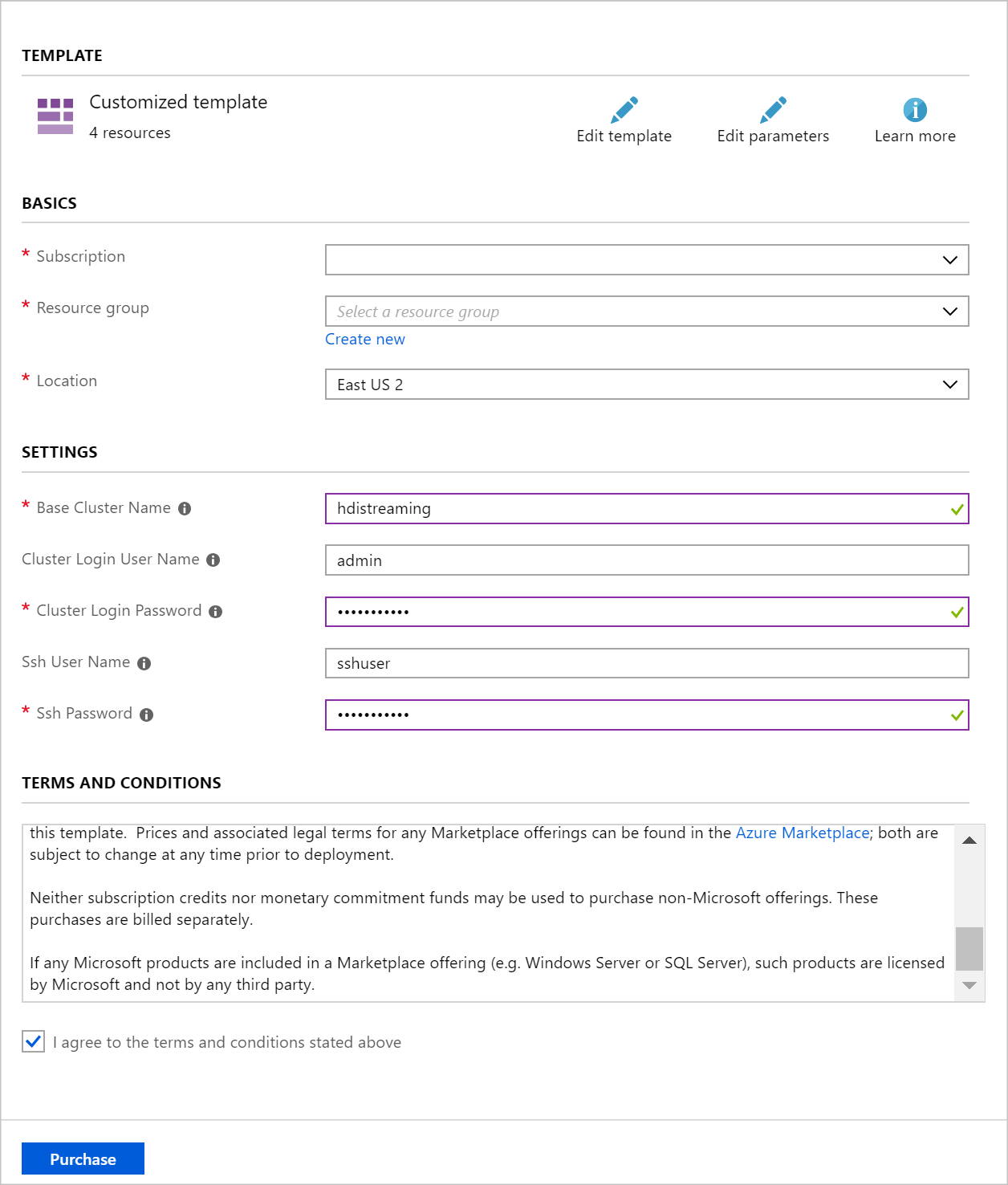
Lees de voorwaarden en schakel vervolgens het selectievakje Ik ga akkoord met de bovenstaande voorwaarden in.
Selecteer Tot slot Aankoop. Het duurt ongeveer 20 minuten om de clusters te maken.
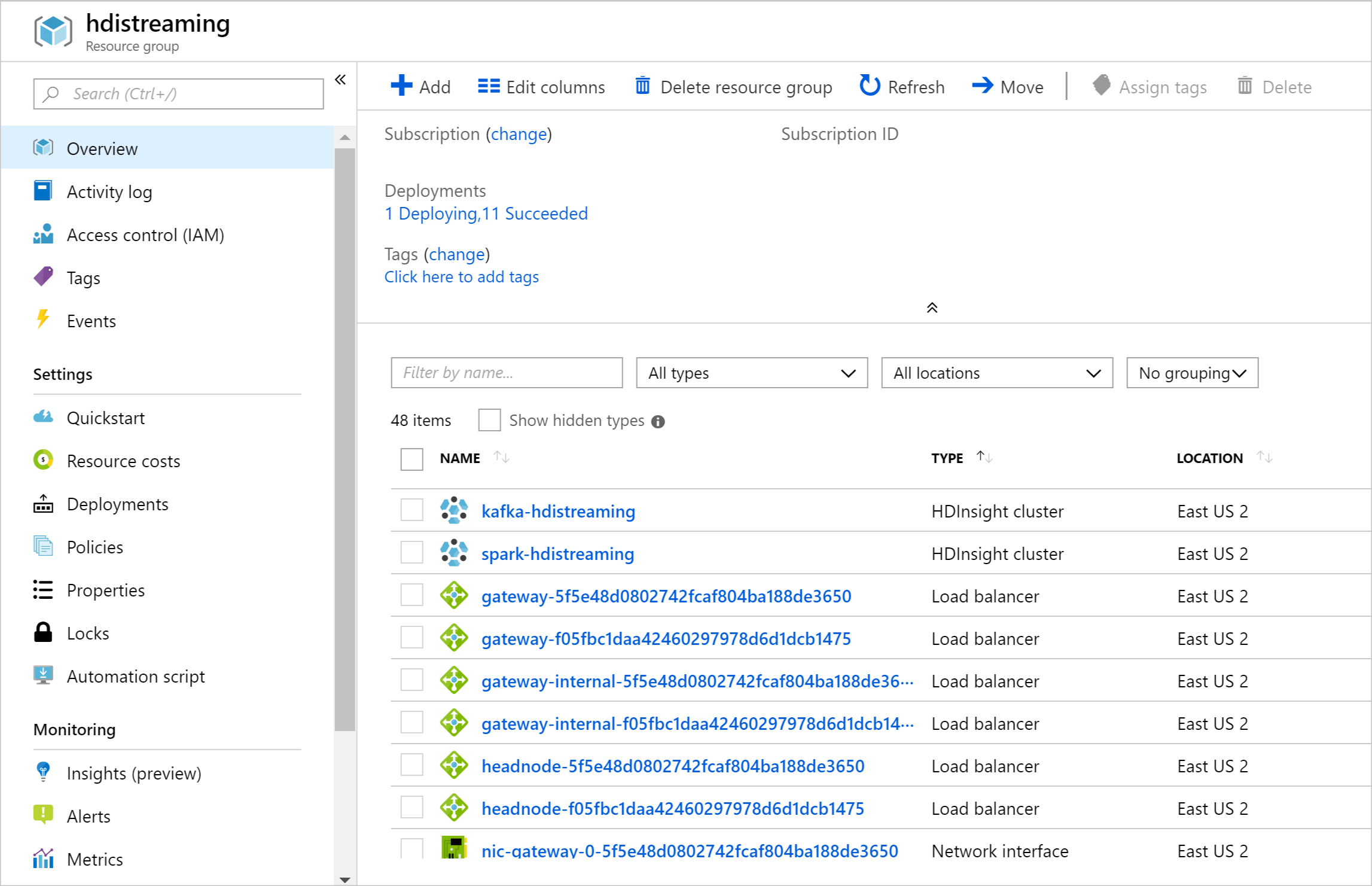
Zodra de resources zijn gemaakt, wordt er een overzichtspagina weergegeven.
Belangrijk
U ziet dat de namen van de HDInsight-clusters spark-BASENAME en kafka-BASENAME zijn, waarbij BASENAME de naam is die u hebt opgegeven voor de sjabloon. U gebruikt deze namen in latere stappen wanneer u verbinding maakt met de clusters.
De notebooks gebruiken
De code voor het voorbeeld in dit document is beschikbaar op https://github.com/Azure-Samples/hdinsight-spark-scala-kafka.
Het cluster verwijderen
Waarschuwing
HDInsight-clusters worden pro rato per minuut gefactureerd, ongeacht of u er wel of niet gebruik van maakt. Verwijder uw cluster daarom als u er klaar mee bent. Zie how to delete an HDInsight cluster (een HDInsight-cluster verwijderen).
Omdat met de stappen in dit document beide clusters in dezelfde Azure-resourcegroep worden gemaakt, kunt u de resourcegroep verwijderen in Azure Portal. Als u de groep verwijdert, worden alle resources verwijderd die zijn gemaakt door dit document, het virtuele Azure-netwerk en het opslagaccount dat door de clusters wordt gebruikt.
Volgende stappen
In dit voorbeeld hebt u geleerd hoe u Spark kunt gebruiken om kafka te lezen en te schrijven. Gebruik de volgende koppelingen om andere manieren te ontdekken om met Kafka te werken: