Logboeken beheren voor een HDInsight-cluster
Een HDInsight-cluster produceert verschillende logboekbestanden. Apache Hadoop en gerelateerde services, zoals Apache Spark, produceren bijvoorbeeld gedetailleerde logboeken voor taakuitvoering. Logboekbestandsbeheer maakt deel uit van het onderhouden van een gezond HDInsight-cluster. Er kunnen ook wettelijke vereisten zijn voor logboekarchivering. Vanwege het aantal en de grootte van logboekbestanden helpt het optimaliseren van logboekopslag en archivering bij het beheer van servicekosten.
Het beheren van HDInsight-clusterlogboeken omvat het bewaren van informatie over alle aspecten van de clusteromgeving. Deze informatie omvat alle bijbehorende Azure Service-logboeken, clusterconfiguratie, taakuitvoeringsgegevens, eventuele foutstatussen en andere gegevens, indien nodig.
Typische stappen in HDInsight-logboekbeheer zijn:
- Stap 1: Bewaarbeleid voor logboeken bepalen
- Stap 2: Configuratielogboeken voor clusterserviceversies beheren
- Stap 3: Logboekbestanden voor het uitvoeren van clustertaken beheren
- Stap 4: Opslaggrootten en kosten van logboekvolumes voorspellen
- Stap 5: Beleidsregels en processen voor logboekarchief bepalen
Stap 1: Bewaarbeleid voor logboeken bepalen
De eerste stap bij het maken van een strategie voor het beheren van HDInsight-clusters is het verzamelen van informatie over bedrijfsscenario's en opslagvereisten voor taakuitvoeringsgeschiedenis.
Clusterdetails
De volgende clusterdetails zijn handig bij het verzamelen van informatie in uw strategie voor logboekbeheer. Verzamel deze informatie van alle HDInsight-clusters die u in een bepaald Azure-account hebt gemaakt.
- Clusternaam
- Clusterregio en Azure-beschikbaarheidszone
- Clusterstatus, inclusief details van de laatste statuswijziging
- Type en het aantal HDInsight-exemplaren dat is opgegeven voor de hoofd-, kern- en taakknooppunten
U kunt de meeste van deze informatie op het hoogste niveau ophalen met behulp van Azure Portal. U kunt ook Azure CLI gebruiken om informatie over uw HDInsight-cluster(s) op te halen:
az hdinsight list --resource-group <ResourceGroup>
az hdinsight show --resource-group <ResourceGroup> --name <ClusterName>
U kunt PowerShell ook gebruiken om deze informatie weer te geven. Zie Apache Manage Hadoop-clusters in HDInsight met behulp van Azure PowerShell voor meer informatie.
Inzicht in de workloads die worden uitgevoerd op uw clusters
Het is belangrijk om inzicht te hebben in de workloadtypen die worden uitgevoerd op uw HDInsight-cluster(s) om de juiste strategieën voor logboekregistratie voor elk type te ontwerpen.
- Zijn de workloads experimenteel (zoals ontwikkeling of test) of productiekwaliteit?
- Hoe vaak worden de workloads van productiekwaliteit normaal uitgevoerd?
- Zijn een van de werkbelastingen resource-intensief en/of langlopend?
- Maakt een van de workloads gebruik van een complexe set Hadoop-services waarvoor meerdere soorten logboeken worden geproduceerd?
- Zijn aan een van de workloads vereisten voor het uitvoeren van herkomstvereisten voor regelgeving gekoppeld?
Voorbeeld van bewaarpatronen en procedures voor logboeken
Overweeg het bijhouden van gegevensherkomsten te onderhouden door een id toe te voegen aan elke logboekvermelding of via andere technieken. Hiermee kunt u de oorspronkelijke bron van de gegevens en de bewerking traceren en de gegevens in elke fase volgen om de consistentie en geldigheid ervan te begrijpen.
Overweeg hoe u logboeken van het cluster of van meer dan één cluster kunt verzamelen en deze kunt sorteren voor doeleinden zoals controle, bewaking, planning en waarschuwingen. U kunt een aangepaste oplossing gebruiken om de logboekbestanden regelmatig te openen en te downloaden en deze te combineren en te analyseren om een dashboardweergave te bieden. U kunt ook andere mogelijkheden toevoegen voor waarschuwingen voor beveiligings- of foutdetectie. U kunt deze hulpprogramma's bouwen met behulp van PowerShell, de HDInsight SDK's of code die toegang heeft tot het klassieke Azure-implementatiemodel.
Overweeg of een bewakingsoplossing of -service een nuttig voordeel zou zijn. Microsoft System Center biedt een HDInsight-management pack. U kunt ook hulpprogramma's van derden zoals Apache Chukwa en Ganglia gebruiken om logboeken te verzamelen en te centraliseren. Veel bedrijven bieden services voor het bewaken van big data-oplossingen op basis van Hadoop, bijvoorbeeld:
CenterityCompuware APM, Sematext SPM en Zettaset Orchestrator.
Stap 2: Clusterserviceversies beheren en logboeken weergeven
Een typisch HDInsight-cluster maakt gebruik van verschillende services en opensource-softwarepakketten (zoals Apache HBase, Apache Spark, enzovoort). Voor sommige werkbelastingen, zoals bio-informatica, moet u mogelijk de geschiedenis van het serviceconfiguratielogboek bewaren naast taakuitvoeringslogboeken.
Clusterconfiguratie-instellingen weergeven met de Ambari-gebruikersinterface
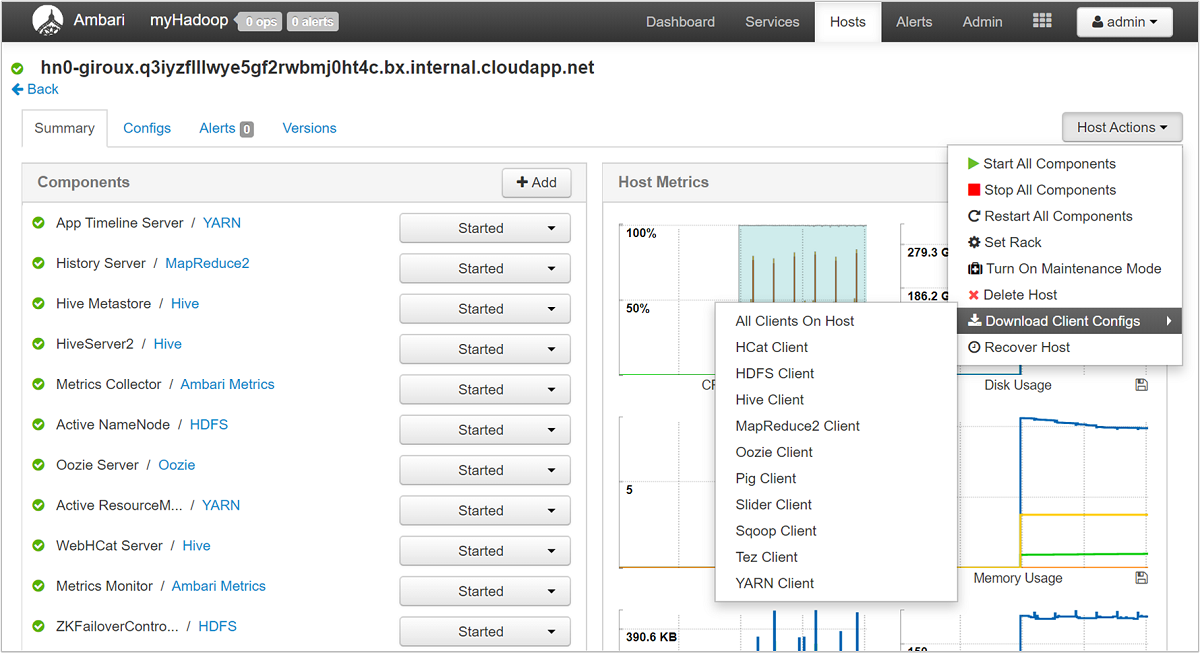
Apache Ambari vereenvoudigt het beheer, de configuratie en de bewaking van een HDInsight-cluster door een webgebruikersinterface en een REST API te bieden. Ambari is opgenomen in HDInsight-clusters op basis van Linux. Selecteer het deelvenster Clusterdashboard op de HDInsight-pagina van Azure Portal om de koppelingspagina Clusterdashboards te openen. Selecteer vervolgens het dashboardvenster van het HDInsight-cluster om de Ambari-gebruikersinterface te openen. U wordt gevraagd om uw aanmeldingsreferenties voor het cluster.
Als u een lijst met serviceweergaven wilt openen, selecteert u het deelvenster Ambari-weergaven op de azure-portalpagina voor HDInsight. Deze lijst varieert, afhankelijk van de bibliotheken die u hebt geïnstalleerd. U ziet bijvoorbeeld YARN Queue Manager, Hive-weergave en Tez-weergave. Selecteer een servicekoppeling om configuratie- en servicegegevens weer te geven. De pagina Ambari UI Stack en Versie bevat informatie over de configuratie en versiegeschiedenis van de clusterservices. Als u naar deze sectie van de Ambari-gebruikersinterface wilt navigeren, selecteert u het menu Beheer en vervolgens Stacks en Versies. Selecteer het tabblad Versies om informatie over de serviceversie weer te geven.

Met behulp van de Ambari-gebruikersinterface kunt u de configuratie downloaden voor alle (of alle) services die worden uitgevoerd op een bepaalde host (of knooppunt) in het cluster. Selecteer het menu Hosts en vervolgens de koppeling voor de host van belang. Selecteer op de pagina van die host de knop Hostacties en download clientconfiguraties.
De scriptactielogboeken weergeven
HdInsight-scriptacties voeren scripts uit op een cluster, handmatig of wanneer deze zijn opgegeven. Scriptacties kunnen bijvoorbeeld worden gebruikt om andere software op het cluster te installeren of om configuratie-instellingen van de standaardwaarden te wijzigen. Scriptactielogboeken kunnen inzicht bieden in fouten die zijn opgetreden tijdens de installatie van het cluster, en ook de wijzigingen in de configuratie-instellingen die van invloed kunnen zijn op de prestaties en beschikbaarheid van het cluster. Als u de status van een scriptactie wilt zien, selecteert u de knop Ops in uw Ambari-gebruikersinterface of opent u de statuslogboeken in het standaardopslagaccount. De opslaglogboeken zijn beschikbaar op /STORAGE_ACCOUNT_NAME/DEFAULT_CONTAINER_NAME/custom-scriptaction-logs/CLUSTER_NAME/DATE.
Statuslogboeken van Ambari-waarschuwingen weergeven
Apache Ambari schrijft waarschuwingsstatuswijzigingen naar ambari-alerts.log. Het volledige pad is /var/log/ambari-server/ambari-alerts.log. Als u foutopsporing voor het logboek wilt inschakelen, wijzigt u een eigenschap in Wijzigen en voert u de volgende vermelding in /etc/ambari-server/conf/log4j.properties.# Log alert state changes :
log4j.logger.alerts=INFO,alerts
to
log4j.logger.alerts=DEBUG,alerts
Stap 3: De logboekbestanden voor de uitvoering van de clustertaak beheren
De volgende stap is het controleren van de logboekbestanden voor taakuitvoering voor de verschillende services. Services kunnen Apache HBase, Apache Spark en vele andere omvatten. Een Hadoop-cluster produceert een groot aantal uitgebreide logboeken, zodat het bepalen welke logboeken nuttig zijn (en die niet) tijdrovend kunnen zijn. Inzicht in het systeem voor logboekregistratie is belangrijk voor het doelbeheer van logboekbestanden. De volgende afbeelding is een voorbeeld van een logboekbestand.

Toegang tot de Hadoop-logboekbestanden
HDInsight slaat de logboekbestanden zowel op in het clusterbestandssysteem als in Azure Storage. U kunt logboekbestanden in het cluster onderzoeken door een SSH-verbinding met het cluster te openen en door het bestandssysteem te bladeren, of door de Hadoop YARN-statusportal te gebruiken op de externe hoofdknooppuntserver. U kunt de logboekbestanden in Azure Storage onderzoeken met behulp van een van de hulpprogramma's die toegang hebben tot en downloaden van gegevens uit Azure Storage. Voorbeelden zijn AzCopy, CloudXplorer en Visual Studio Server Explorer. U kunt ook PowerShell en de Azure Storage-clientbibliotheken of de Azure .NET SDK's gebruiken om toegang te krijgen tot gegevens in Azure Blob Storage.
Hadoop voert het werk van de taken uit als taakpogingen op verschillende knooppunten in het cluster. HDInsight kan speculatieve taakpogingen initiëren, waardoor alle andere taakpogingen worden beëindigd die niet eerst worden voltooid. Dit genereert aanzienlijke activiteiten die on-the-fly zijn geregistreerd bij de controller, stderr en syslog-logboekbestanden. Bovendien worden meerdere taakpogingen tegelijkertijd uitgevoerd, maar een logboekbestand kan alleen lineair resultaten weergeven.
HDInsight-logboeken die zijn geschreven naar Azure Blob Storage
HDInsight-clusters zijn geconfigureerd voor het schrijven van taaklogboeken naar een Azure Blob Storage-account voor elke taak die wordt verzonden met behulp van de Azure PowerShell-cmdlets of de API's voor het verzenden van .NET-taken. Als u taken via SSH naar het cluster verzendt, worden de gegevens voor de logboekregistratie van de uitvoering opgeslagen in de Azure-tabellen, zoals beschreven in de vorige sectie.
Naast de kernlogboekbestanden die door HDInsight worden gegenereerd, genereren geïnstalleerde services zoals YARN ook logboekbestanden voor taakuitvoering. Het aantal en het type logboekbestanden is afhankelijk van de geïnstalleerde services. Algemene services zijn Apache HBase, Apache Spark, enzovoort. Onderzoek de taaklogboekuitvoeringsbestanden voor elke service om inzicht te hebben in de algemene logboekbestanden die beschikbaar zijn in uw cluster. Elke service heeft zijn eigen unieke methoden voor logboekregistratie en locaties voor het opslaan van logboekbestanden. In de volgende sectie worden details voor het openen van de meest voorkomende logboekbestanden van de service (vanuit YARN) besproken.
HDInsight-logboeken gegenereerd door YARN
YARN voegt logboeken samen voor alle containers op een werkknooppunt en slaat deze logboeken op als één samengevoegd logboekbestand per werkknooppunt. Dat logboek wordt opgeslagen in het standaardbestandssysteem nadat een toepassing is voltooid. Uw toepassing kan honderden of duizenden containers gebruiken, maar logboeken voor alle containers die op één werkknooppunt worden uitgevoerd, worden altijd samengevoegd tot één bestand. Er is slechts één logboek per werkknooppunt dat door uw toepassing wordt gebruikt. Logboekaggregatie wordt standaard ingeschakeld op HDInsight-clusters versie 3.0 en hoger. Geaggregeerde logboeken bevinden zich in de standaardopslag voor het cluster.
/app-logs/<user>/logs/<applicationId>
De samengevoegde logboeken kunnen niet rechtstreeks worden gelezen, omdat ze zijn geschreven in een binaire indeling die door de TFile container wordt geïndexeerd. Gebruik de YARN-logboeken ResourceManager of CLI-hulpprogramma's om deze logboeken weer te geven als tekst zonder opmaak voor toepassingen of containers die van belang zijn.
YARN CLI-hulpprogramma's
Als u de YARN CLI-hulpprogramma's wilt gebruiken, moet u eerst verbinding maken met het HDInsight-cluster met behulp van SSH. Geef de , <user-who-started-the-application>, <containerId>en <worker-node-address> informatie <applicationId>op bij het uitvoeren van deze opdrachten. U kunt de logboeken weergeven als tekst zonder opmaak met een van de volgende opdrachten:
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application>
yarn logs -applicationId <applicationId> -appOwner <user-who-started-the-application> -containerId <containerId> -nodeAddress <worker-node-address>
YARN Resource Manager-gebruikersinterface
De GEBRUIKERSinterface van YARN Resource Manager wordt uitgevoerd op het hoofdknooppunt van het cluster en wordt geopend via de Ambari-webgebruikersinterface. Gebruik de volgende stappen om de YARN-logboeken weer te geven:
- Navigeer in een webbrowser naar
https://CLUSTERNAME.azurehdinsight.net. Vervang CLUSTERNAME door de naam van uw HDInsight-cluster. - Selecteer YARN in de lijst met services aan de linkerkant.
- Selecteer in de vervolgkeuzelijst Snelle koppelingen een van de hoofdknooppunten van het cluster en selecteer vervolgens Resource Manager-logboeken. U ziet een lijst met koppelingen naar YARN-logboeken.
Stap 4: Opslaggrootten en kosten van logboekvolumes voorspellen
Nadat u de vorige stappen hebt voltooid, hebt u inzicht in de typen en volumes logboekbestanden die uw HDInsight-cluster(s) produceert.
Analyseer vervolgens het volume van logboekgegevens in opslaglocaties voor sleutellogboeken gedurende een bepaalde periode. U kunt bijvoorbeeld volume- en groei analyseren over perioden van 30-60-90 dagen. Noteer deze informatie in een spreadsheet of gebruik andere hulpprogramma's, zoals Visual Studio, Azure Storage Explorer of Power Query voor Excel. ```
U hebt nu voldoende informatie om een strategie voor logboekbeheer te maken voor de sleutellogboeken. Gebruik uw spreadsheet (of hulpprogramma van keuze) om in de toekomst de kosten voor de Azure-service voor logboekgrootte en logboekopslag te voorspellen. Overweeg ook eventuele logboekretentievereisten voor de set logboeken die u bekijkt. U kunt nu toekomstige kosten voor logboekopslag opnieuw maken, nadat u hebt bepaald welke logboekbestanden kunnen worden verwijderd (indien van toepassing) en welke logboeken moeten worden bewaard en gearchiveerd in goedkopere Azure Storage.
Stap 5: Beleidsregels en processen voor logboekarchief bepalen
Nadat u hebt bepaald welke logboekbestanden kunnen worden verwijderd, kunt u logboekparameters voor veel Hadoop-services aanpassen om logboekbestanden automatisch te verwijderen na een opgegeven periode.
Voor bepaalde logboekbestanden kunt u een lagere archiveringsbenadering voor logboekbestanden gebruiken. Voor activiteitenlogboeken van Azure Resource Manager kunt u deze aanpak verkennen met behulp van Azure Portal. Stel archivering van de Resource Manager-logboeken in door de koppeling Activiteitenlogboek te selecteren in Azure Portal voor uw HDInsight-exemplaar. Selecteer boven aan de zoekpagina van het activiteitenlogboek het menu-item Exporteren om het deelvenster Activiteitenlogboek exporteren te openen. Vul het abonnement, de regio in, of u wilt exporteren naar een opslagaccount en hoeveel dagen de logboeken moeten worden bewaard. In hetzelfde deelvenster kunt u ook aangeven of u wilt exporteren naar een Event Hub.

U kunt ook logboekarchivering uitvoeren met PowerShell.
Toegang tot metrische gegevens van Azure Storage
Azure Storage kan worden geconfigureerd voor logboekopslagbewerkingen en -toegang. U kunt deze gedetailleerde logboeken gebruiken voor capaciteitsbewaking en -planning en voor het controleren van aanvragen voor opslag. De vastgelegde informatie bevat latentiegegevens, zodat u de prestaties van uw oplossingen kunt bewaken en verfijnen. U kunt de .NET SDK voor Hadoop gebruiken om de logboekbestanden te onderzoeken die zijn gegenereerd voor Azure Storage die de gegevens voor een HDInsight-cluster bevat.
De grootte en het aantal back-upindexen voor oude logboekbestanden beheren
Als u de grootte en het aantal bewaarde logboekbestanden wilt beheren, stelt u de volgende eigenschappen van:RollingFileAppender
maxFileSizeis de kritieke grootte van het bestand, dat het bestand wordt samengerold. De standaardwaarde is 10 MB.maxBackupIndexgeeft het aantal back-upbestanden op dat moet worden gemaakt, standaard 1.
Andere technieken voor logboekbeheer
Om te voorkomen dat er onvoldoende schijfruimte beschikbaar is, kunt u sommige hulpprogramma's van het besturingssysteem, zoals logrotate , gebruiken om logboekbestanden te verwerken. U kunt configureren logrotate om dagelijks uit te voeren, logboekbestanden te comprimeren en oude bestanden te verwijderen. Uw aanpak is afhankelijk van uw vereisten, zoals hoe lang de logboekbestanden op lokale knooppunten moeten worden bewaard.
U kunt ook controleren of DEBUG-logboekregistratie is ingeschakeld voor een of meer services, waardoor de grootte van het uitvoerlogboek aanzienlijk wordt verhoogd.
Als u de logboeken van alle knooppunten naar één centrale locatie wilt verzamelen, kunt u een gegevensstroom maken, zoals het opnemen van alle logboekvermeldingen in Solr.