Zelfstudie: Een end-to-end gegevenspijplijn maken om verkoopinzichten af te leiden in Azure HDInsight
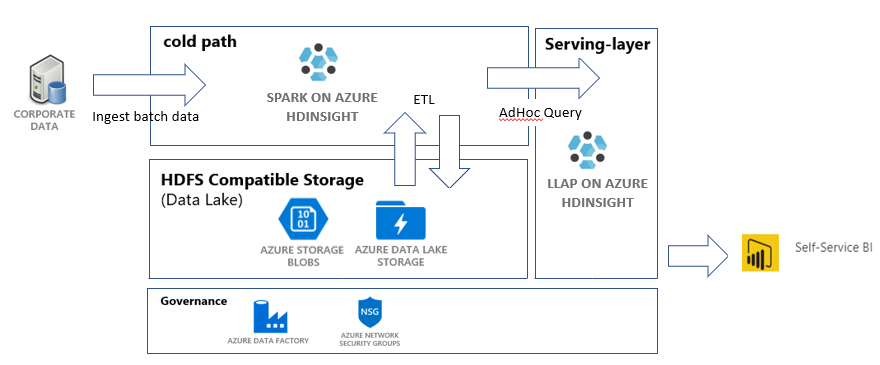
In deze zelfstudie bouwt u een end-to-end gegevenspijplijn waarmee de ETL-bewerkingen uitpakken, transformeren en laden worden uitgevoerd. De pijplijn maakt gebruik van Apache Spark en Apache Hive-clusters die worden uitgevoerd op Azure HDInsight voor het uitvoeren van query's en het bewerken van de gegevens. U kunt ook gebruikmaken van technologieën zoals Azure Data Lake Storage Gen2 voor gegevensopslag en Power BI voor visualisatie.
In deze gegevenspijplijn worden de gegevens uit verschillende winkels gecombineerd, worden alle ongewenste gegevens verwijderd, worden nieuwe gegevens toegevoegd en wordt deze weer in uw opslag geladen om zakelijke inzichten te visualiseren. Lees meer over ETL-pijplijnen in Uitpakken, transformeren en laden (ETL).
Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
Vereisten
Azure CLI - ten minste versie 2.2.0. Raadpleeg De Azure CLI installeren.
jq, een opdrachtregel-JSON-processor. Zie https://stedolan.github.io/jq/.
Een lid van de Ingebouwde Azure-rol - eigenaar.
Als u PowerShell gebruikt om de Data Factory-pijplijn te activeren, hebt u de AZ-module nodig.
Power BI Desktop om zakelijke inzichten te visualiseren aan het einde van deze zelfstudie.
Resources maken
De opslagplaats klonen met scripts en gegevens
Aanmelden bij uw Azure-abonnement. Als u Azure Cloud Shell wilt gebruiken, selecteert u Probeer het in de rechterbovenhoek van het codeblok. Anders voert u de onderstaande opdracht in:
az login # If you have multiple subscriptions, set the one to use # az account set --subscription "SUBSCRIPTIONID"Zorg ervoor dat u lid bent van de Azure-rol Eigenaar. Vervang
user@contoso.comdoor uw account en voer de volgende opdracht in:az role assignment list \ --assignee "user@contoso.com" \ --role "Owner"Als er geen record wordt geretourneerd, bent u geen lid en kunt u deze zelfstudie niet voltooien.
Download de gegevens en scripts voor deze zelfstudie vanuit de ETL-opslagplaats voor verkoopinzichten van HDInsight. Voer de volgende opdracht in:
git clone https://github.com/Azure-Samples/hdinsight-sales-insights-etl.git cd hdinsight-sales-insights-etlZorg dat
salesdata scripts templatesis gemaakt. Controleer met de volgende opdracht:ls
Implementeer Azure-resources die nodig zijn voor de pijplijn
Voer de machtigingen voor uitvoeren voor alle scripts uit door het volgende in te voeren:
chmod +x scripts/*.shStel de variabele in voor de resourcegroep. Vervang
RESOURCE_GROUP_NAMEdoor de naam van een bestaande of nieuwe resourcegroep en voer de volgende opdracht in:RESOURCE_GROUP="RESOURCE_GROUP_NAME"Voer het script uit. Vervang
LOCATIONdoor een gewenste waarde en voer de volgende opdracht in:./scripts/resources.sh $RESOURCE_GROUP LOCATIONAls u niet zeker weet welke regio u moet opgeven, kunt u een lijst met ondersteunde regio's voor uw abonnement ophalen met de opdracht az account list-locations.
Met deze opdracht worden de volgende resources geïmplementeerd:
- Een Azure Blob Storage-account. Dit account bevat de verkoopgegevens van het bedrijf.
- Een Azure Data Lake Storage Gen2-account. Dit account wordt gebruikt als het opslagaccount voor beide HDInsight-clusters. Meer informatie over HDInsight en Data Lake Storage Gen2 vindt u in Azure HDInsight-integratie met Data Lake Storage Gen2.
- Een door een gebruiker toegewezen beheerde identiteit. Dit account geeft de HDInsight-clusters toegang tot het Data Lake Storage Gen2-account.
- Een Apache Spark-cluster. Dit cluster wordt gebruikt om de onbewerkte gegevens op te schonen en te transformeren.
- Een Interactive Query-cluster in Apache Hive. Met dit cluster kunt u query's uitvoeren op de verkoopgegevens en deze visualiseren met Power BI.
- Een virtueel Azure-netwerk dat wordt ondersteund door netwerkbeveiligingsgroep (NSG)-regels. Met dit virtuele netwerk kunnen clusters communiceren en hun communicatie beveiligen.
Het maken van een cluster kan ongeveer 20 minuten duren.
Het standaardwachtwoord voor SSH-toegang tot de clusters is Thisisapassword1. Als u het wachtwoord wilt wijzigen, gaat u naar het bestand ./templates/resourcesparameters_remainder.json en wijzigt u het wachtwoord voor de parameters sparksshPassword, sparkClusterLoginPassword, llapClusterLoginPassword en llapsshPassword.
Implementatie controleren en resourcegegevens verzamelen
Als u de status van uw implementatie wilt controleren, gaat u naar de resourcegroep op de Azure-portal. Selecteer onder InstellingenImplementaties en vervolgens uw implementatie. Hier ziet u de resources die zijn geïmplementeerd en de resources die nog worden uitgevoerd.
Voer de volgende opdracht in om de namen van de clusters weer te geven:
SPARK_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.sparkClusterName.value') LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') echo "Spark Cluster" $SPARK_CLUSTER_NAME echo "LLAP cluster" $LLAP_CLUSTER_NAMEAls u het Azure-opslagaccount en de toegangssleutel wilt weergeven, voert u de volgende opdracht in:
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value') blobKey=$(az storage account keys list \ --account-name $BLOB_STORAGE_NAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $BLOB_STORAGE_NAME echo $BLOB_KEYAls u het Data Lake Storage Gen2-account en de toegangssleutel wilt weergeven, voert u de volgende opdracht in:
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value') ADLSKEY=$(az storage account keys list \ --account-name $ADLSGEN2STORAGENAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $ADLSGEN2STORAGENAME echo $ADLSKEY
Een data factory maken
Azure Data Factory is een hulpprogramma waarmee Azure-pijplijnen kunnen worden geautomatiseerd. Het is niet de enige manier om deze taken uit te voeren, maar het is een uitstekende manier om de processen te automatiseren. Raadpleeg de Documentatie voor Azure Data Factory voor meer informatie over Azure Data Factory.
Deze data factory heeft één pijplijn met twee activiteiten:
- Met de eerste activiteit worden de gegevens van Azure Blob-opslag gekopieerd naar het Data Lake Storage Gen 2-opslagaccount om gegevensopname te simuleren.
- Met de tweede activiteit worden de gegevens in het Spark-cluster getransformeerd. Met het script worden de gegevens getransformeerd door ongewenste kolommen te verwijderen. Er wordt ook een nieuwe kolom toegevoegd die de omzet berekent die door één transactie wordt gegenereerd.
Als u uw Azure Data Factory-pijplijn wilt instellen, voert u de onderstaande opdracht uit. U moet nog steeds de map hdinsight-sales-insights-etl zijn.
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value')
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value')
./scripts/adf.sh $RESOURCE_GROUP $ADLSGEN2STORAGENAME $BLOB_STORAGE_NAME
Dit script doet het volgende dingen:
- Hiermee maakt u een service-principal met machtigingen
Storage Blob Data Contributorvoor het Data Lake Storage Gen2-opslagaccount. - Hiermee wordt een verificatietoken opgehaald om POST-aanvragen te autoriseren naar het Data Lake Storage Gen2-bestandssysteem REST API.
- Hiermee wordt de werkelijke naam van uw Data Lake Storage Gen2-opslagaccount in de bestanden
sparktransform.pyenquery.hqlingevuld. - Hiermee worden opslagsleutels voor de Data Lake Storage Gen2- en Blob Storage-accounts opgehaald.
- Hiermee maakt u een nieuwe resource-implementatie om een Azure Data Factory-pijplijn te maken, met gekoppelde services en activiteiten. De opslagsleutels worden doorgegeven als parameters aan het sjabloonbestand, zodat de gekoppelde services op de juiste wijze toegang hebben tot de opslagaccounts.
De gegevens pijplijnuitvoeren
De Data Factory-activiteiten activeren
Met de eerste activiteit in de Data Factory-pijplijn die u hebt gemaakt, worden de gegevens uit de Blob-opslag naar Data Lake Storage Gen2 verplaatst. Met de tweede activiteit worden de Spark-transformaties op de gegevens toegepast en worden de getransformeerde CSV-bestanden op een nieuwe locatie opgeslagen. Het uitvoeren van de volledige pijplijn kan enkele minuten duren.
Voer de volgende opdracht in om de Data Factory-naam op te halen:
cat resourcesoutputs_adf.json | jq -r '.properties.outputs.factoryName.value'
Als u de pijplijn wilt activeren, kunt u het volgende doen:
Activeer de Data Factory-pijplijn in PowerShell. Vervang
RESOURCEGROUPenDataFactoryNamemet de juiste waarden en voer vervolgens de volgende opdrachten uit:# If you have multiple subscriptions, set the one to use # Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>" $resourceGroup="RESOURCEGROUP" $dataFactory="DataFactoryName" $pipeline =Invoke-AzDataFactoryV2Pipeline ` -ResourceGroupName $resourceGroup ` -DataFactory $dataFactory ` -PipelineName "IngestAndTransform" Get-AzDataFactoryV2PipelineRun ` -ResourceGroupName $resourceGroup ` -DataFactoryName $dataFactory ` -PipelineRunId $pipelineVoer
Get-AzDataFactoryV2PipelineRunopnieuw uit indien nodig om de voortgang te controleren.Or
Open de data factory en selecteer Auteur & controle. Activeer de pijplijn
IngestAndTransformvanuit de portal. Zie Apache Hadoop-clusters op aanvraag maken in HDInsight met behulp van Azure Data Factory voor meer informatie over het activeren van pijplijnen via de portal.
Om te controleren of de pijplijn is uitgevoerd, kunt u een van de volgende stappen uitvoeren:
- Ga naar de sectie Controle in uw data factory via de portal.
- Ga in Azure Storage Explorer naar uw Data Lake Storage Gen 2-opslagaccount. Ga naar het bestandssysteem
files, ga naar de maptransformeden controleer de inhoud om te zien of de pijplijn is geslaagd.
Zie dit artikel over het gebruik van Jupyter Notebook voor andere manieren om gegevens te transformeren met behulp van HDInsight.
Een tabel op het Interactive Query-cluster maken om gegevens op Power BI weer te geven
Kopieer het bestand
query.hqlnaar het LLAP-cluster met behulp van SCP. Voer de opdracht in:LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') scp scripts/query.hql sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.net:/home/sshuser/Herinnering: het standaardwachtwoord is
Thisisapassword1.Gebruik SSH om toegang te krijgen tot het LLAP-cluster. Voer de opdracht in:
ssh sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.netGebruik de volgende opdracht om het script uit te voeren:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -f query.hqlMet dit script wordt een beheerde tabel gemaakt op het interactieve querycluster waartoe u toegang hebt via Power BI.
Een Power BI-dashboard maken op basis van verkoopgegevens
Open Power BI Desktop.
Ga in het menu naar Gegevens ophalen>Meer...>Azure>HDInsight Interactive Query.
Selecteer Verbinding maken.
In het dialoogvenster HDInsight Interactive Query:
- Geef in het tekstvak Server de naam van uw LLAP-cluster op in de indeling van
https://LLAPCLUSTERNAME.azurehdinsight.net. - Voer in het tekstvak database
defaultin. - Selecteer OK.
- Geef in het tekstvak Server de naam van uw LLAP-cluster op in de indeling van
In het dialoogvenster AzureHive:
- Voer in het tekstvak Gebruikersnaam
adminin. - Voer in het tekstvak Wachtwoord
Thisisapassword1in. - Selecteer Verbinding maken.
- Voer in het tekstvak Gebruikersnaam
Selecteer in Navigator
salesen/ofsales_rawom een voorbeeld van de gegevens weer te geven. Nadat de gegevens zijn geladen, kunt u experimenteren met het dashboard dat u wilt maken. Zie de volgende koppelingen om aan de slag te gaan met Power BI-dashboards:
Resources opschonen
Als u deze toepassing niet meer wilt gebruiken, verwijdert u alle resources met behulp van de volgende opdracht, zodat er geen kosten in rekening worden gebracht.
Om de resourcegroep te verwijderen, voert u de volgende opdracht uit:
az group delete -n $RESOURCE_GROUPAls u de service-principal wilt verwijderen, voert u de volgende opdrachten in:
SERVICE_PRINCIPAL=$(cat serviceprincipal.json | jq -r '.name') az ad sp delete --id $SERVICE_PRINCIPAL