HDInsight-cluster migreren naar een nieuwere versie
Om te profiteren van de nieuwste HDInsight-functies raden we u aan om HDInsight-clusters regelmatig te migreren naar de nieuwste versie. HDInsight biedt geen ondersteuning voor in-place upgrades waarbij een bestaand cluster wordt bijgewerkt naar een nieuwere onderdeelversie. U moet een nieuw cluster maken met het gewenste onderdeel en de platformversie en vervolgens uw toepassingen migreren om het nieuwe cluster te gebruiken. Volg de onderstaande richtlijnen om uw HDInsight-clusterversies te migreren.
Notitie
Als u een Hive-cluster maakt met een primaire opslagcontainer, kopieert u dit vanuit een bestaand HDInsight-cluster. Kopieer de volledige inhoud niet. Kopieer alleen de gegevensmappen die zijn geconfigureerd.
Migratietaken
De werkstroom voor het upgraden van HDInsight-cluster is als volgt.
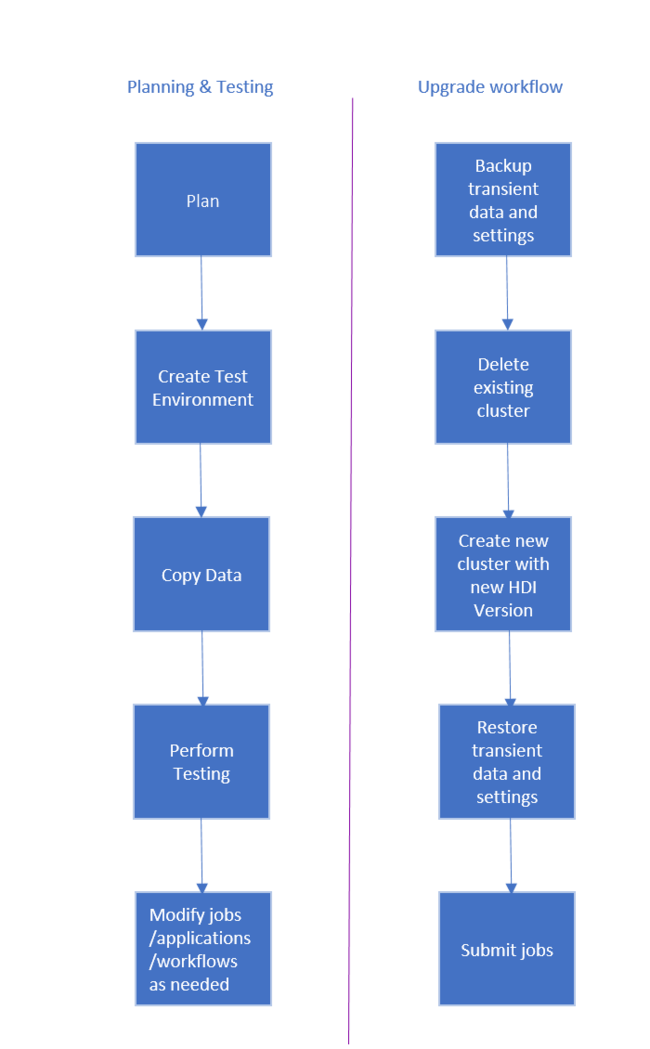
- Lees elke sectie van dit document om inzicht te hebben in wijzigingen die mogelijk nodig zijn bij het upgraden van uw HDInsight-cluster.
- Maak een cluster als test-/kwaliteitscontroleomgeving. Voor meer informatie over het maken van een cluster raadpleegt u Meer informatie over het maken van HDInsight-clusters op basis van Linux
- Kopieer bestaande taken, gegevensbronnen en sinks naar de nieuwe omgeving.
- Voer validatietests uit om ervoor te zorgen dat uw taken werken zoals verwacht op het nieuwe cluster.
Zodra u hebt gecontroleerd of alles werkt zoals verwacht, plant u downtime voor de migratie. Tijdens deze downtime voert u de volgende acties uit:
- Maak een back-up van tijdelijke gegevens die lokaal zijn opgeslagen op de clusterknooppunten. Als u bijvoorbeeld gegevens rechtstreeks op een hoofdknooppunt hebt opgeslagen.
- Verwijder het bestaande cluster.
- Maak een cluster in hetzelfde VNET-subnet met de nieuwste (of ondersteunde) HDI-versie met hetzelfde standaardgegevensarchief dat door het vorige cluster is gebruikt. Hierdoor kan het nieuwe cluster blijven werken met uw bestaande productiegegevens.
- Importeer eventuele tijdelijke gegevens waarvan u een back-up hebt gemaakt.
- Taken starten/doorgaan met verwerken met behulp van het nieuwe cluster.
Richtlijnen voor specifieke workload
De volgende documenten bevatten richtlijnen voor het migreren van specifieke workloads:
Back-up maken en herstellen
Upgradescenario's
Zoals hierboven vermeld, raadt Microsoft aan hdInsight-clusters regelmatig te migreren naar de nieuwste versie om te profiteren van nieuwe functies en oplossingen. Zie de volgende lijst met redenen waarom we vragen om een cluster te verwijderen en opnieuw te implementeren:
- De clusterversie is buiten gebruik gesteld of als u een clusterprobleem hebt dat zou worden opgelost met een nieuwere versie.
- De hoofdoorzaak van een clusterprobleem wordt bepaald om een ondersized VM te relateren. Bekijk de aanbevolen knooppuntconfiguratie van Microsoft.
- Een klant opent een ondersteuningsaanvraag en het technische team van Microsoft bepaalt dat het probleem al is opgelost in een nieuwere clusterversie.
- Een standaard metastore-database (Ambari, Hive, Oozie, Ranger) heeft de gebruikslimiet bereikt. Microsoft vraagt u het cluster opnieuw te maken met behulp van een aangepaste metastore-database .
- De hoofdoorzaak van een clusterprobleem is het gevolg van een niet-ondersteunde bewerking. Hier volgen enkele veelvoorkomende niet-ondersteunde bewerkingen:
- Een service verplaatsen of toevoegen in Ambari. Zie de informatie over de clusterservices in Ambari. Een van de acties die beschikbaar zijn in het menu Serviceacties is [Servicenaam] verplaatsen. Een andere actie is [Servicenaam] toevoegen. Beide opties worden niet ondersteund.
- Python-pakketbeschadiging. HDInsight-clusters zijn afhankelijk van de ingebouwde Python-omgevingen, Python 2.7 en Python 3.5. Het rechtstreeks installeren van aangepaste pakketten in deze standaard ingebouwde omgevingen kan onverwachte wijzigingen in bibliotheekversies veroorzaken en het cluster verbreken. Meer informatie over het veilig installeren van aangepaste externe Python-pakketten voor uw Spark-toepassingen.
- Software van derden. Klanten hebben de mogelijkheid om software van derden te installeren op hun HDInsight-clusters; We raden u echter aan het cluster opnieuw te maken als het de bestaande functionaliteit onderbreekt.
- Meerdere workloads in hetzelfde cluster. In HDInsight 4.0 heeft de Hive Warehouse-Verbinding maken or afzonderlijke clusters nodig voor Spark- en Interactive Query-workloads. Volg deze stappen om beide clusters in Te stellen in Azure HDInsight. Op dezelfde manier vereist de integratie van Spark met HBASE twee verschillende clusters.
- Het aangepaste Ambari DB-wachtwoord is gewijzigd. Het Ambari DB-wachtwoord wordt ingesteld tijdens het maken van het cluster en er is geen huidig mechanisme om het bij te werken. Als een klant het cluster implementeert met een aangepaste Ambari-database, hebben ze de mogelijkheid om het DB-wachtwoord in de SQL-database te wijzigen. Er is echter geen manier om dit wachtwoord voor een actief HDInsight-cluster bij te werken.
- HDInsight Load Balancers wijzigen. De HDInsight-load balancers die automatisch worden geïmplementeerd voor Ambari- en SSH-toegang , mogen niet worden gewijzigd of verwijderd. Als u de HDInsight-load balancer(s) wijzigt en de clusterfunctionaliteit wordt verbroken, wordt u aangeraden het cluster opnieuw te implementeren.