Zelfstudie: Een Scala Maven-toepassing maken voor Apache Spark in HDInsight met behulp van IntelliJ
In deze zelfstudie leert u hoe u met behulp van Apache Maven met IntelliJ IDEA een Apache Spark-toepassing maakt die is geschreven in Scala. In het artikel wordt Apache Maven als het buildsysteem gebruikt. En er wordt begonnen met een bestaand Maven-archetype voor Scala dat door IntelliJ IDEA wordt verstrekt. Het maken van een Scala-toepassing in IntelliJ IDEA omvat de volgende stappen:
- Maven gebruiken als het buildsysteem.
- POM-bestand (Project Object Model) bijwerken om afhankelijkheden van Spark-module om te zetten.
- De toepassing schrijven in Scala.
- Een JAR-bestand genereren dat kan worden verstuurd naar HDInsight Spark-clusters.
- De toepassing uitvoeren in een Spark-cluster met behulp van Livy.
In deze zelfstudie leert u het volgende:
- Scala-invoegtoepassing voor IntelliJ IDEA installeren
- IntelliJ gebruiken voor het ontwikkelen van een Scala Maven-toepassing
- Een zelfstandig Scala-project maken
Vereisten
Een Apache Spark-cluster in HDInsight. Zie Apache Spark-clusters maken in Azure HDInsight voor instructies.
Oracle Java Development Kit. In deze zelfstudie wordt gebruikgemaakt van Java-versie 8.0.202.
Een Java-IDE. In dit artikel wordt gebruikgemaakt van IntelliJ IDEA Community 2018.3.4.
Azure-toolkit voor IntelliJ. Zie Installing the Azure Toolkit for IntelliJ (De Azure Toolkit voor IntelliJ installeren).
Scala-invoegtoepassing voor IntelliJ IDEA installeren
Voer de volgende stappen uit om de Scala-invoegtoepassing te installeren:
Open IntelliJ IDEA.
Ga op het welkomstscherm naar Configure>Plugins om het venster Plugins te openen.
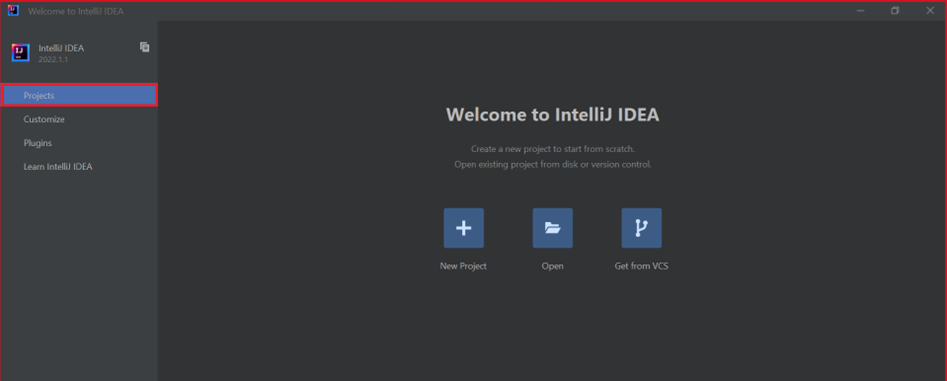
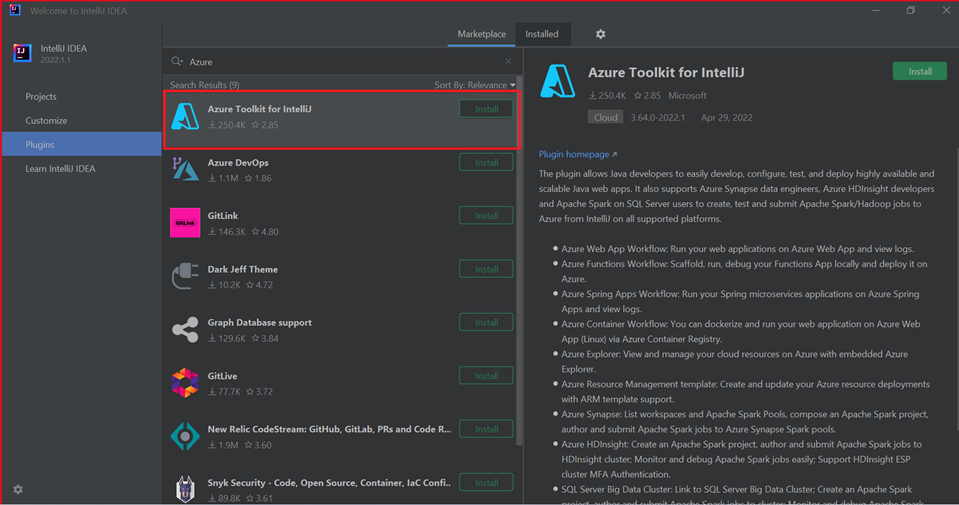
Selecteer Installeren voor Azure Toolkit voor IntelliJ.
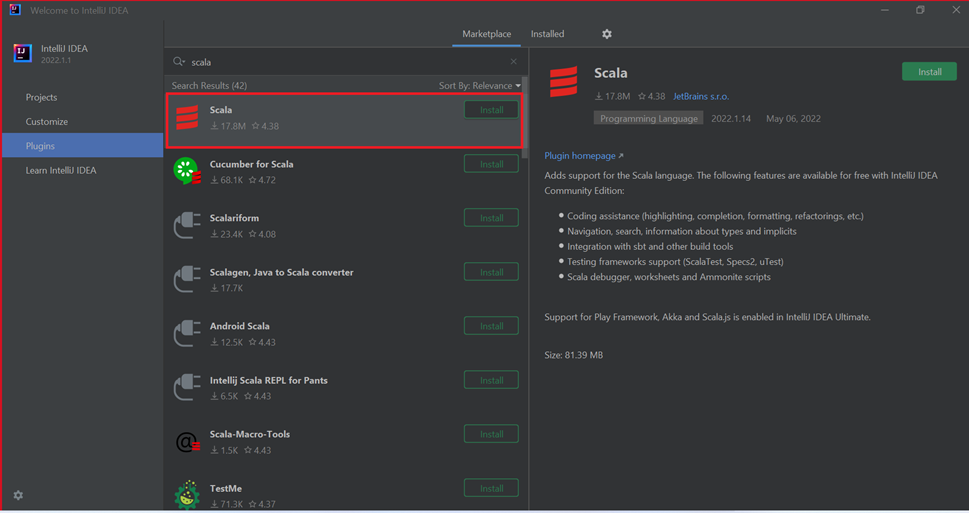
Selecteer Install voor de Scala-invoegtoepassing die in het nieuwe venster wordt weergegeven.
Als de invoegtoepassing is geïnstalleerd, moet u de IDE opnieuw starten.
IntelliJ gebruiken om een toepassing te maken
Start IntelliJ IDEA en selecteer Create New Project om het venster New Project te openen.
Selecteer Apache Spark/HDInsight in het linkerdeelvenster.
Selecteer Spark Project (Scala) in het hoofdvenster.
Selecteer in de vervolgkeuzelijst Build-hulpprogramma een van de volgende waarden:
- Maven, voor de ondersteuning van de wizard Scala-project maken.
- SBT, voor het beheren van de afhankelijkheden en het maken van het Scala-project.
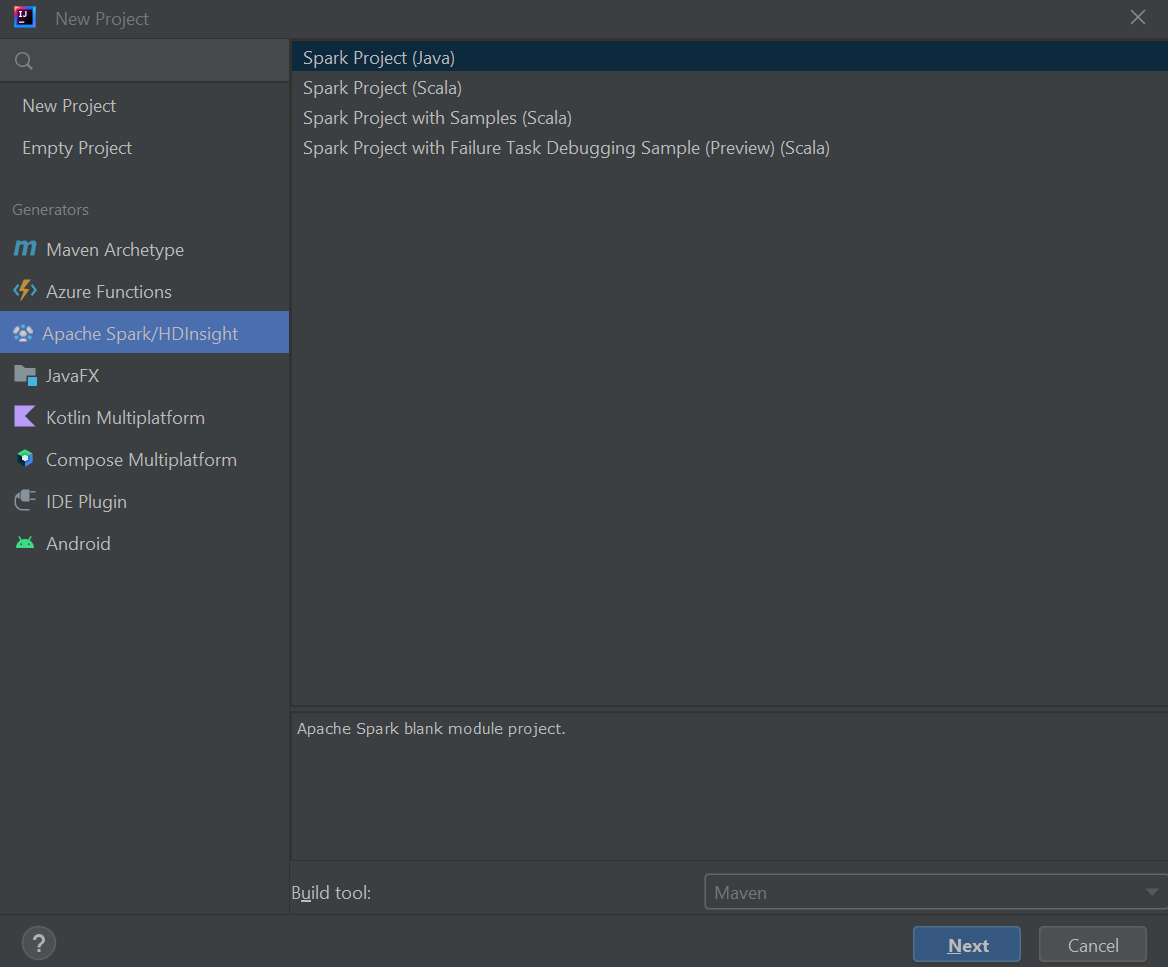
Selecteer Volgende.
Geef in het venster New project de volgende gegevens op:
Eigenschappen Beschrijving Projectnaam Voer een naam in. Projectlocatie Voer de locatie in om uw project in op te slaan. Project SDK Als u IDEA voor het eerst gebruikt, is dit veld leeg. Selecteer New... en ga naar uw JDK. Spark-versie De wizard voor het maken van het project integreert de juiste versie voor Spark SDK en Scala SDK. Selecteer Spark 1.x als de Spark-clusterversie ouder is dan 2.0. Selecteer anders Spark 2.x. In dit voorbeeld wordt Spark 2.3.0 (Scala 2.11.8) gebruikt. 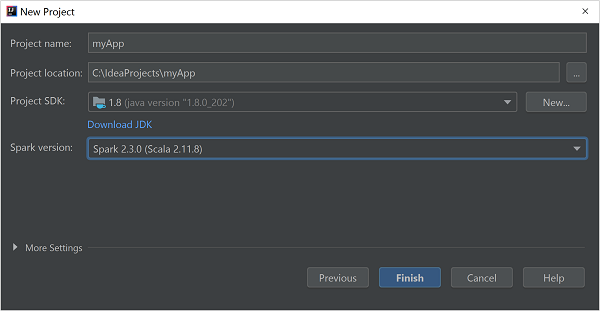
Selecteer Voltooien.
Een zelfstandig Scala-project maken
Start IntelliJ IDEA en selecteer Create New Project om het venster New Project te openen.
Selecteer Maven in het linkerdeelvenster.
Geef een Project SDK op. Selecteer New... als het veld leeg is en ga naar de installatiemap van Java.
Schakel het selectievakje Create from archetype in.
Selecteer
org.scala-tools.archetypes:scala-archetype-simplein de lijst met archetypen. Met dit archetype maakt u de juiste mapstructuur en worden de vereiste standaardafhankelijkheden voor het schrijven van het Scala-programma gedownload.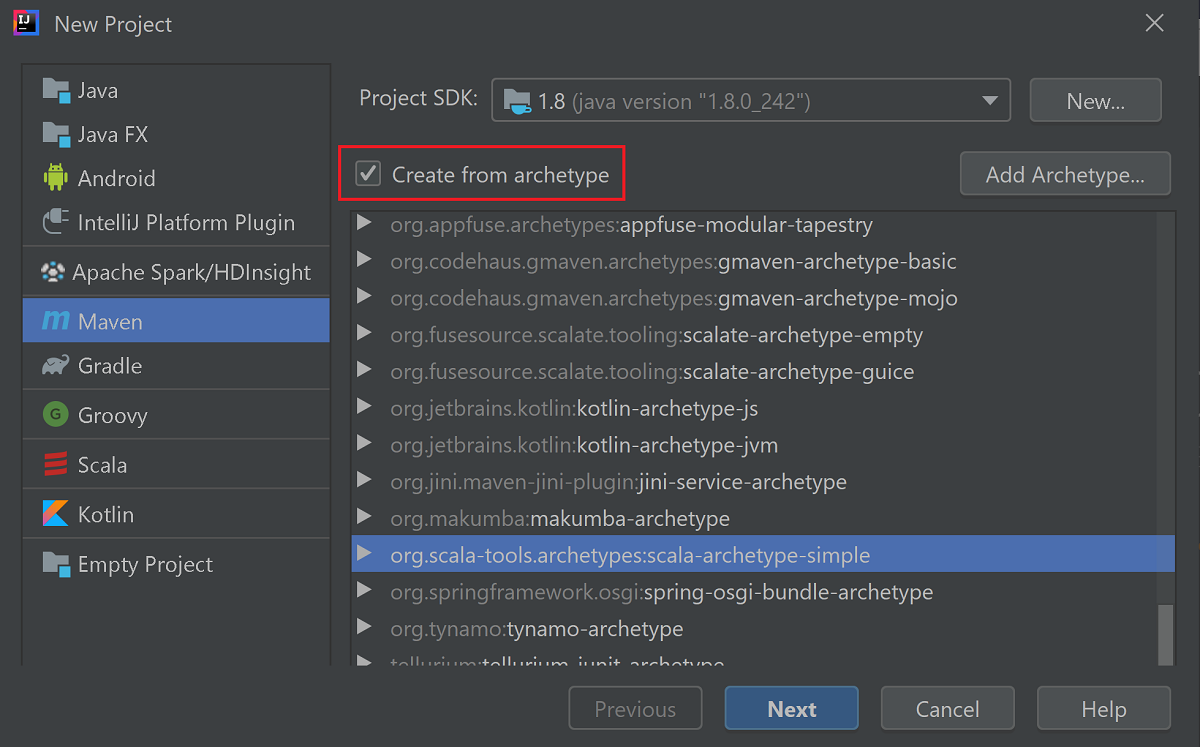
Selecteer Volgende.
Vouw Artefactcoördinaten uit. Geef relevante waarden op voor GroupId en ArtifactId. Naam en Locatie worden automatisch ingevuld. In deze zelfstudie worden de volgende waarden gebruikt:
- GroupId: com.microsoft.spark.example
- ArtifactId: SparkSimpleApp
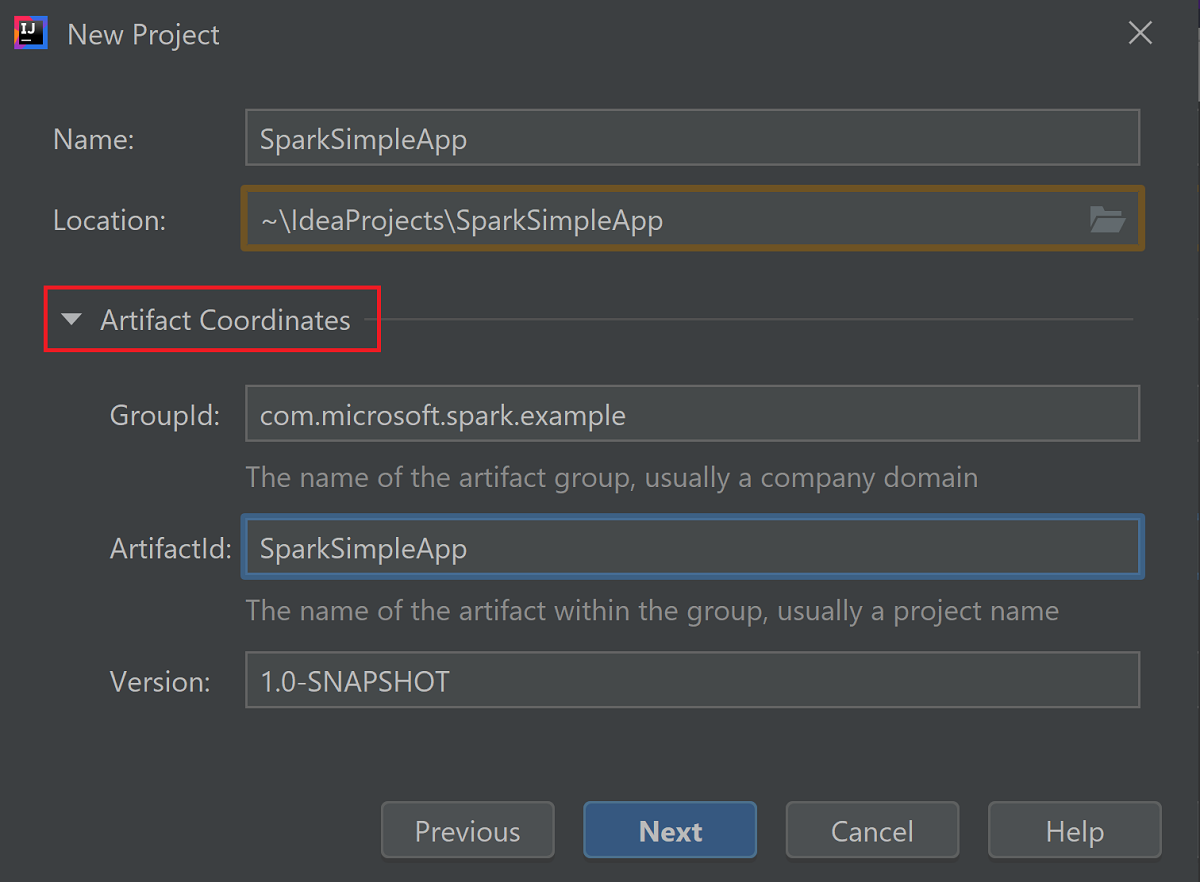
Selecteer Volgende.
Controleer de instellingen en selecteer vervolgens Next.
Controleer de naam en de locatie van het project en selecteer vervolgens Finish. Het duurt enkele minuten voordat het project is geïmporteerd.
Als het project is geïmporteerd, gaat u in het linkerdeelvenster naar SparkSimpleApp>src>test>scala>com>microsoft>spark>example. Klik met de rechtermuisknop op MySpec en selecteer Verwijderen.... U hebt dit bestand niet nodig voor de toepassing. Selecteer OK in het dialoogvenster.
In de latere stappen gaat u het bestand pom.xml bijwerken om de afhankelijkheden voor de Spark Scala-toepassing te definiëren. Om deze afhankelijkheden automatisch te downloaden en om te zetten, moet u Maven configureren.
Selecteer in het menu File de optie Settings om het venster Settings te openen.
Ga in het venster Settings naar Build, Execution, Deployment>Build Tools>Maven>Importing.
Schakel het selectievakje Import Maven projects automatically in.
Selecteer Apply en vervolgens OK. U keert dan terug naar het projectvenster.
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::Ga in het linkerdeelvenster naar src>main>scala>com.microsoft.spark.example en dubbelklik op App om App.scala te openen.
Vervang de bestaande voorbeeldcode door de volgende code en sla de wijzigingen op. Deze code leest de gegevens uit de HVAC.csv (beschikbaar op alle HDInsight Spark-clusters). Hiermee worden de rijen opgehaald die slechts één cijfer in de zesde kolom hebben. En de uitvoer wordt geschreven naar /HVACOut- onder de standaardopslagcontainer voor het cluster.
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }Dubbelklik in het linkerdeelvenster op pom.xml.
Voeg binnen
<project>\<properties>de volgende segmenten toe:<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version>Voeg binnen
<project>\<dependencies>de volgende segmenten toe:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml.Maak het JAR-bestand. IntelliJ IDEA maakt het mogelijk om het JAR-bestand te maken als een artefact van een project. Voer de volgende stappen uit.
Selecteer Project Structure... in het menu File.
Ga in het venster Project Structure naar Artifacts>het plusteken +>JAR>From modules with dependencies....
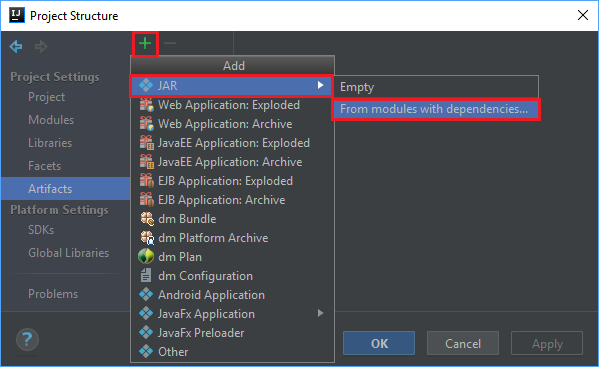
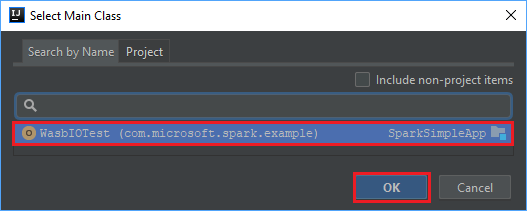
Selecteer in het venster Create JAR from Modules het mappictogram in het tekstvak Main Class.
Selecteer in het venster Select Main Class de klasse die standaard wordt weergegeven en selecteer vervolgens OK.
Controleer of in het venster Create JAR from Modules de optie extract to the target JAR is geselecteerd en selecteer vervolgens OK. Met deze instelling wordt er één JAR gemaakt met alle afhankelijkheden.

Het tabblad Output Layout geeft een overzicht van alle JAR-bestanden die zijn opgenomen als onderdeel van het Maven-project. U kunt de bestanden selecteren en verwijderen waarvan de Scala-toepassing niet direct afhankelijk is. Voor de toepassing die u hier maakt, kunt u alle bestanden behalve het laatste bestand (SparkSimpleApp compile output) verwijderen. Selecteer de JAR-bestanden die u wilt verwijderen en selecteer vervolgens het minteken -.
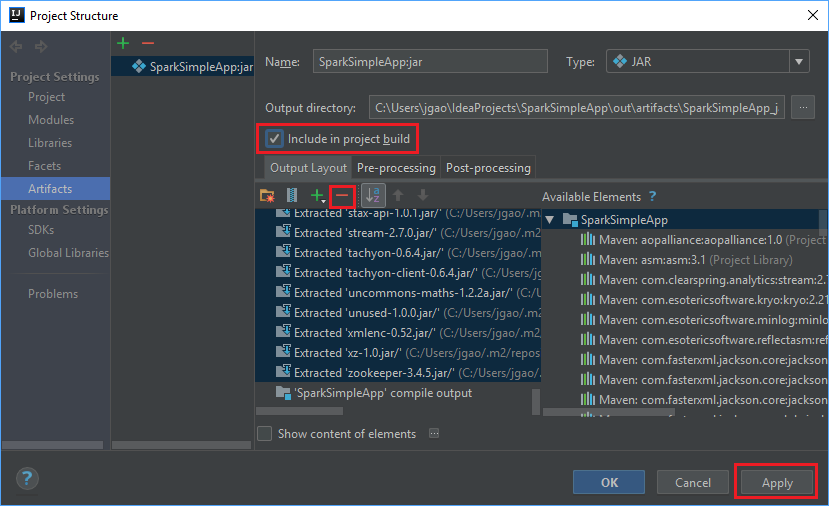
Zorg ervoor dat het selectievakje Include in project build is geselecteerd. Deze optie zorgt ervoor dat het JAR-bestand telkens wanneer het project wordt gebouwd of bijgewerkt, wordt gemaakt. Selecteer Apply en vervolgens OK.
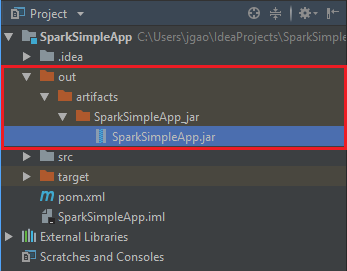
Ga naar Build>Build Artifacts>Build om het JAR-bestand te maken. Het project wordt in circa dertig seconden gecompileerd. Het bestand wordt opgeslagen in \out\artifacts.
De toepassing uitvoeren in het Apache Spark-cluster
U kunt de volgende methoden gebruiken om de toepassing uit te voeren in het cluster:
Kopieer het JAR-bestand van de toepassing naar de Azure-opslagblob die aan het cluster is gekoppeld. Dit kan met AzCopy, een opdrachtregelprogramma. Er zijn echter een heleboel clients die u kunt gebruiken om gegevens te uploaden. Meer informatie hierover vindt u in Gegevens voor Apache Hadoop-taken uploaden in HDInsight.
Gebruik Apache Livy om een toepassingstaak op afstand te versturen naar het Spark-cluster. Spark-clusters in HDInsight ondersteunen Livy voor het aanbieden van REST-eindpunten waarmee Spark-taken op afstand kunnen worden verzonden. Zie Apache Livy met Spark-clusters in HDInsight gebruiken om Apache Spark-taken op afstand te verzenden voor meer informatie.
Resources opschonen
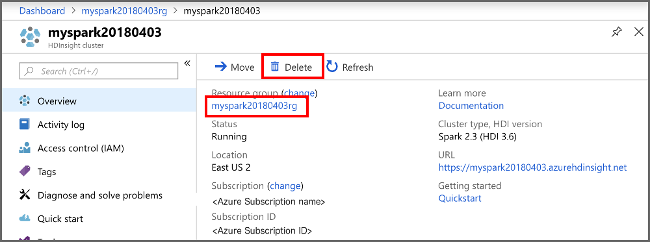
Als u deze toepassing verder niet meer gebruikt, verwijdert u het cluster dat u hebt gemaakt, via de volgende stappen:
Meld u aan bij het Azure-portaal.
Typ HDInsight in het Zoekvak bovenaan.
Selecteer onder Services de optie HDInsight-clusters.
Selecteer in de lijst met HDInsight-clusters die wordt weergegeven, de ... naast het cluster dat u voor deze zelfstudie hebt gemaakt.
Selecteer Verwijderen. Selecteer Ja.
Volgende stap
In dit artikel hebt u geleerd hoe u een Apache Spark Scala-toepassing maakt. Ga naar het volgende artikel om te leren hoe u deze toepassing uitvoert in een HDInsight Spark-cluster met behulp van Livy.