In dit artikel vindt u een technisch overzicht van het gebruik van Microsoft Azure om risicorastercomputing in het bankwezen te ondersteunen en te verbeteren. In het artikel worden aanbevolen systemen en architecturen op hoog niveau verkend.
Dit document is bedoeld voor oplossingsarchitecten en in sommige gevallen technische besluitvormers, die een uitgebreide informatie willen over voorgestelde oplossingen voor risicocomputing.
Inleiding
Financiële risicoanalysemodellen worden doorgaans verwerkt als batchtaken. Ze hebben zware rekenbelastingen die een hoge vraag naar rekenkracht, gegevenstoegang en analyse genereren. De vraag naar berekeningen van risicorasterberekeningen groeit vaak in de loop van de tijd en de behoefte aan rekenresources neemt hierdoor toe.
Het brede scala aan beschikbare producten en services in Azure betekent dat er meer dan één oplossing voor de meeste problemen kan zijn. Dit artikel bevat een overzicht van de technologieën, patronen en procedures die het effectiefst zijn voor een oplossing voor het berekenen van risicorasters in het bankwezen die gebruikmaakt van Microsoft Azure Batch.
Azure Batch is een gratis service die rendabele en veilige oplossingen biedt. De oplossingen zijn voor zowel de infrastructuur als de verschillende fasen van batchverwerking die doorgaans worden gebruikt met modellen voor risicorastercomputing. Azure Batch kan de huidige investeringen in on-premises rekenresources uitbreiden, uitbreiden of zelfs vervangen met behulp van hybride netwerken of door het hele Batch-proces naar Azure te verplaatsen. Gegevens kunnen omhoog en omlaag gaan vanuit de cloud of on-premises blijven. Andere gegevens kunnen worden verwerkt door rekenknooppunten in een burst-to-cloud-model wanneer on-premises resources laag zijn.
Anatomie van een Azure Batch-uitvoering
Er zijn doorgaans ten minste twee toepassingen betrokken bij een Batch-uitvoering. Eén toepassing, die doorgaans wordt uitgevoerd op een hoofdknooppunt, verzendt de taak naar de pool en organiseert soms de rekenknooppunten. De indeling kan ook worden geconfigureerd via Azure Portal. De andere toepassing wordt uitgevoerd door de rekenknooppunten als taak (zie afbeelding 1).
De rekenknooppunttoepassing voert de taak uit van parallelle verwerking risicomodelleringsbestanden. Er kan meer dan één toepassing zijn geïnstalleerd en uitgevoerd op de rekenknooppunten.
Deze toepassingen kunnen worden geüpload via de Batch-API, rechtstreeks via Azure Portal of via de Azure CLI-opdrachten voor Batch.
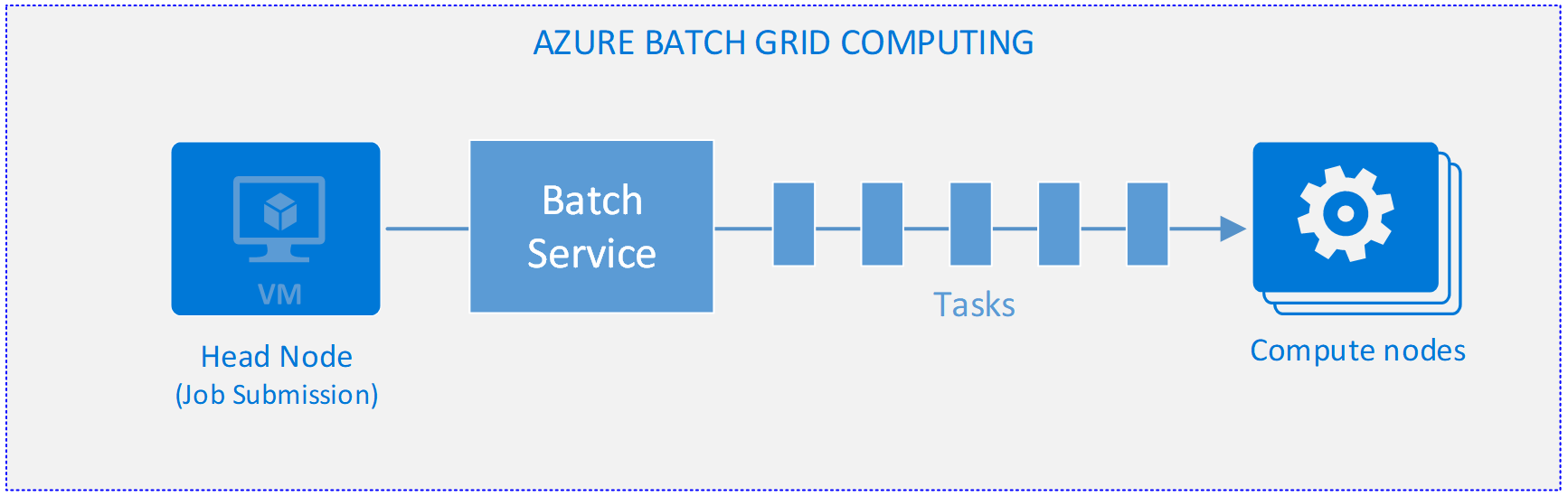
Afbeelding 1: Azure Batch-rastercomputing
Een Azure Batch-uitvoering bestaat uit verschillende logische elementen. In afbeelding 2 ziet u het logische model van een batchtaak. Een pool is een container voor de VM's die betrokken zijn bij de Batch-uitvoering en richt de rekenknooppunt-VM's in. Een pool is ook de container voor de toepassingen die op de rekenknooppunten zijn geïnstalleerd. Taken worden gemaakt en uitgevoerd binnen de pool. Taken worden uitgevoerd door de taken. Taken zijn een uitvoering van de werkroltoepassing en worden aangeroepen door een opdrachtregelinstructie.
De werkroltoepassing wordt geïnstalleerd op het rekenknooppunt wanneer deze wordt gemaakt.
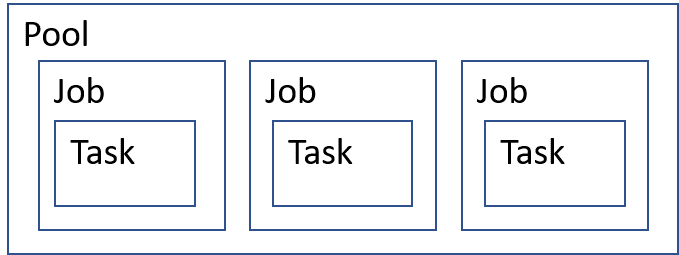
Afbeelding 2: Conceptmodel logische batch
Wanneer de taak wordt uitgevoerd, richt de pool alle werkrol-VM's in die nodig zijn en worden de werkroltoepassingen geïnstalleerd. De taak wijst taken toe aan die rekenknooppunten, die op hun beurt een opdrachtregelinstructie (CLI) uitvoeren. Het CLI-script roept doorgaans de geïnstalleerde toepassingen of scripts aan.
Het gebruik van Batch volgt doorgaans een prototypisch patroon, dat als volgt wordt beschreven:
- Maak een resourcegroep die de Batch-assets bevat.
- Maak binnen de resourcegroep een Batch-account.
- Maak een gekoppeld opslagaccount.
- Maak een pool waarin u de werkrol-VM's kunt inrichten.
- Upload de rekenknooppunttoepassing of scripts naar de pool.
- Maak een taak om taken toe te wijzen aan de VM's in de pool.
- Voeg de taak toe aan de pool.
- Start de Batch-uitvoering.
- Met de taak worden taken in de wachtrij geplaatst die moeten worden uitgevoerd op de rekenknooppunten.
- Rekenknooppunten voeren de taken uit zodra de VM's beschikbaar komen.
Een afbeelding van dit proces wordt weergegeven in afbeelding 3.
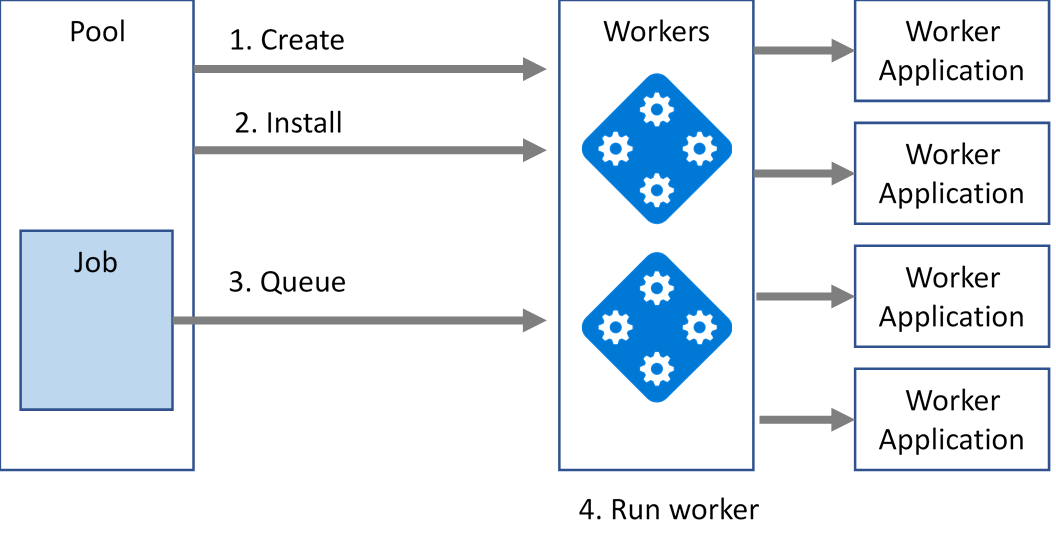
Afbeelding 3: Conceptmodel logische batch
Zodra taken zijn voltooid, kan het handig zijn om de rekenknooppunten te verwijderen zodat er geen kosten in rekening worden gebracht terwijl ze niet in gebruik zijn. Als u ze via code of de portal wilt verwijderen, kunt u de groep verwijderen, waardoor de werkrol-VM's worden verwijderd.
Voor gedetailleerdere instructies over hoe u aan de slag kunt gaan met Batch, doorloopt u met quickstarts van 5 minuten het proces in verschillende talen en ziet u ook hoe u De Azure-portal gebruikt.
Batchprocesplanning
Azure Batch heeft een ingebouwde scheduler, zodat elke uitvoering kan worden gepland in de portal of via API's. De Batch-taakplanner kan meerdere planningen definiëren om meerdere taken te activeren. Elke taak heeft zijn eigen eigenschappen, zoals wat u moet doen wanneer de taak begint en eindigt. Taakplanningen kunnen worden ingesteld op terugkerende intervallen of voor een eenmalige uitvoering.
Veel bankrastercomputingsystemen hebben al hun eigen planningsservice. Het is mogelijk dat mijn planner niet direct naar Azure hoeft te worden verplaatst. Dit kan naadloos werken omdat Azure Batch handmatig of via een SDK kan worden aangeroepen. Met deze mogelijkheid kan de planning nog steeds on-premises plaatsvinden en kunnen workloads worden verwerkt in Azure.
Batchverwerking kan plaatsvinden volgens een vooraf bepaald schema of op aanvraag. In beide gevallen hoeft u vm's van rekenknooppunten niet actief te houden wanneer ze niet worden gebruikt. Wanneer u honderden, zo niet duizenden, rekenknooppunten van vm's gebruikt, kunnen aanzienlijke kostenbesparingen worden gerealiseerd door de inrichting van de servers ongedaan te maken wanneer ze klaar zijn met het uitvoeren van hun taken in de wachtrij.
Rekenknooppunttoepassingen
Rekenknooppunten hebben een toepassing nodig om uit te voeren wanneer een taak wordt aangeroepen. Deze toepassingen worden door het bedrijf geschreven om de verwerkingstaken uit te voeren wanneer ze op de werkrollen zijn geïnstalleerd. In risicorastercomputing voor bankscenario's neemt deze toepassing vaak de taak op zich om gegevens te transformeren in indelingen die speciaal geschikt zijn voor downstreamanalyses of andere verwerkingen.
Wanneer u de toepassing aan de groep levert voor distributie naar rekenknooppunten, wordt deze geüpload in een toepassingspakket. Een toepassingspakket kan een andere versie van een eerder geüpload toepassingspakket zijn. Er kunnen meer dan één toepassingspakket worden geïnstalleerd op één rekenknooppunt. De taak bevat de toepassingenpakketten die op de werkmachines moeten worden geladen.
Implementatie van toepassingspakketten kan ook worden beheerd door versie. Als meerdere versies van een toepassingspakket in een pool zijn geladen, kan een specifieke versie worden aangewezen voor gebruik in een Batch-uitvoering, zoals wordt weergegeven in afbeelding 4. Dit kan nodig zijn in auditomgevingen of wanneer het bedrijf een eerdere uitvoering wil reproduceren. Het kan ook worden gebruikt voor terugdraaidoeleinden als er een fout wordt geïntroduceerd in de werkroltoepassing.
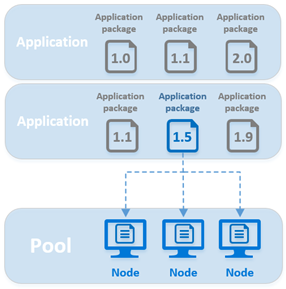
Afbeelding 4: Taaktoepassingen voor rekenknooppuntversies versiebeheer
Een toepassingspakket wordt als een .zip-bestand geüpload naar de groep. Het bestand bevat de binaire bestanden van de toepassing en de ondersteunende bestanden die nodig zijn voor taken om de toepassing uit te voeren. Er zijn twee bereiken voor toepassingspakketten. U kunt een toepassingspakket aanwijzen binnen het bereik van de pool of in het bereik van taken.
Toepassingspakketten groep
Deze pakketten worden geïmplementeerd op elk rekenknooppunt in de pool. Wanneer een VM voor rekenknooppunten wordt ingericht, opnieuw wordt opgestart of opnieuw wordt geïnstalleerd, wordt er een nieuwe kopie van een groeptoepassingspakketten geïnstalleerd als er een bijgewerkte toepassing bestaat. Een of meer toepassingspakketten kunnen worden toegewezen aan een pool, wat betekent dat de rekenknooppunten alle pakketten krijgen toegewezen.
Taaktoepassingspakketten
Toepassingspakketten die gericht zijn op het taakniveau, worden alleen geïnstalleerd op rekenknooppunten die zijn gepland om een taak uit te voeren. Taaktoepassingen zijn bedoeld voor gebruik wanneer meer dan één taak in één pool wordt uitgevoerd.
Taaktoepassingen zijn handig bij het samenvoegen van gegevens die worden geproduceerd door taken op poolniveau. Deze toepassingen kunnen relevant zijn in scenario's voor risicorastercomputing. Een taaktoepassing kan bijvoorbeeld een set risicoberekeningen uitvoeren waarmee gegevens worden gegenereerd die later in de werkstroom voor risicoberekening moeten worden gebruikt.
Batchtaken schalen
Banken voeren vaak een risicoanalysebatch uit in het weekend of 's nachts wanneer rekenresources te weinig worden gebruikt. Hoewel dit model voor sommigen werkt, kan het snel worden ontgroeid, waardoor er meer kapitaal nodig is om meer werkmachines aan het raster toe te voegen.
Als Het uitvoeren van Azure Batch-taken te lang duurt of als u meer rekenkracht in uw Batch-uitvoeringen wilt, biedt Azure verschillende opties.
- Wijs meer rekenknooppuntmachines toe om uit te schalen.
- Wijs krachtigere rekenknooppuntmachines toe om omhoog te schalen. Azure-machines kunnen worden ingericht om te voldoen aan hoge prestatiebehoeften van kernen en geheugen, en zelfs GPU-rekenkracht.
Opmerking: Het gebruik van Microsoft HPC Pack met Batch is een complexer model en wordt niet besproken in dit artikel.
In een Batch-verwerkingscluster hebt u mogelijk slechts twee verwerkings-VM's. Of u kunt duizenden gelijktijdige taken uitvoeren op duizenden VM-rekenknooppunten, met tienduizenden kernen. Elke VIRTUELE machine is verantwoordelijk voor het uitvoeren van één taak tegelijk. Het aantal VIRTUELE machines in een pool kan handmatig of automatisch worden geschaald, zoals is geconfigureerd wanneer de belasting toeneemt of afneemt.
Burst naar cloud
Wanneer rekenresources in een on-premises raster laag zijn vanwege het uitvoeren van een grote analysetaak, biedt 'burst to cloud' een manier om deze resources te verbeteren door meer rekenknooppunten toe te voegen in Azure. Burst naar de cloud is een model waarin privéclouds of infrastructuur hun workload naar cloudservers distribueren wanneer de vraag hoog is voor on-premises resources.
Deze rekenknooppunten kunnen vooraf worden geconfigureerd als virtuele Linux- of Windows-machines die moeten worden ingericht in het IaaS-platform van Azure. Verder kunnen servers worden ingericht en automatisch geconfigureerd voor gebruik met bestaande investeringen zoals Tibco Gridserver en IBM Symphony.
Formules automatisch schalen
Deze elasticiteit kan worden geconfigureerd in Azure Portal of met behulp van formules voor automatisch schalen. Formules voor automatisch schalen zijn scripts die worden geüpload naar de Batch-verwerkingsplanner voor fijnmazige controle over batchgedrag. Automatisch schalen op een pool rekenknooppunten wordt uitgevoerd door de knooppunten te koppelen aan formules voor automatisch schalen.
Het volgende voorbeeld is van een formule voor automatisch schalen, waarmee automatisch schalen wordt om te beginnen met één VIRTUELE machine en naar behoefte maximaal 50 VM's worden geschaald. Wanneer taken zijn voltooid, worden VM's één voor één gratis en wordt de pool kleiner door de formule voor automatisch schalen.
startingNumberOfVMs = 1;
maxNumberofVMs = 50;
pendingTaskSamplePercent = $PendingTasks.GetSamplePercent(180 * TimeInterval_Second);
pendingTaskSamples = pendingTaskSamplePercent < 70 ? startingNumberOfVMs : avg($PendingTasks.GetSample(180 * TimeInterval_Second));
$TargetDedicatedNodes=min(maxNumberofVMs, pendingTaskSamples);
Andere schaaltechnieken
Automatisch schalen kan ook worden ingeschakeld met de PowerShell-cmdlet Enable-AzureBatchAutoScale. Met de cmdlet Enable-AzureBatchAutoScale kunt u automatisch schalen van de opgegeven pool inschakelen. Hier volgt een voorbeeld.
- Met de eerste opdracht wordt een formule gedefinieerd en vervolgens opgeslagen in de
$Formulavariabele. - Met de tweede opdracht kunt u automatisch schalen inschakelen voor de pool met de naam
RiskGridPoolmet behulp van de formule in$Formula.
C:\> $Formula = ‘startingNumberOfVMs = 1;
maxNumberofVMs = 50;
pendingTaskSamplePercent = $PendingTasks.GetSamplePercent(180 * TimeInterval_Second?WT.mc_id=gridbanksg-docs-dastarr);
pendingTaskSamples = pendingTaskSamplePercent < 70 ? startingNumberOfVMs : avg($PendingTasks.GetSample(180 * TimeInterval_Second));
$TargetDedicatedNodes=min(maxNumberofVMs, pendingTaskSamples);’;
C:\> Enable-AzureBatchAutoScale -Id "RiskGridPool" -AutoScaleFormula $Formula -BatchContext $Context
Schalen kan ook worden uitgevoerd met behulp van de Azure CLI met de az batch pool resize opdracht en via Azure Portal.
Gegevensopslag en -retentie
Zodra gegevens zijn opgenomen en verwerkt door een rekenknooppunt, kunnen de resulterende uitvoergegevens worden opgeslagen in een database. De uitvoergegevens kunnen verder worden verwerkt en geanalyseerd of getransformeerd na opname, vóór opslag, om ervoor te zorgen dat de juiste indelingen voor downstreamverwerking worden gegarandeerd. Microsoft Azure biedt verschillende opslagopties. De keuze van welke technologie voor gegevensopslag moet worden gebruikt , is grotendeels afhankelijk van analyse- en of rapportagebehoeften in downstreamprocessen.
Wanneer u een hybride netwerk gebruikt, is het doel voor gegevensopslag mogelijk on-premises. Wanneer u Batch via een hybride netwerk gebruikt, kunnen rekenknooppunten gegevens terugschrijven naar een on-premises gegevensarchief zonder een op Azure gebaseerde opslaglocatie te gebruiken. Werkrollen kunnen ook schrijven naar Azure File Storage, die kunnen worden gekoppeld als een schijf op een on-premises computer. Met deze installatie kunt u eenvoudig toegang krijgen door elk proces dat werkt met de bestanden on-premises.
Controle en logboekregistratie
Om toekomstige uitvoeringen van de Batch-taak te optimaliseren, moeten gegevens worden vastgelegd om gebieden van optimalisatie te identificeren. Als werknemers bijvoorbeeld bijna CPU-capaciteit hebben, kunnen het toevoegen van kernen aan de rekenknooppunten helpen voorkomen dat er CPU-afhankelijk is en de taak sneller kan worden voltooid. Elke toepassing die in de Batch-taak wordt uitgevoerd, heeft zijn eigen kenmerken en de optimalisaties die zijn aangebracht op de VM's in de Batch-uitvoeringen kunnen verschillen. Voor geheugenintensieve taken kan meer geheugen worden toegewezen door de machines in de volgende uitvoering anders te configureren.
Logboekregistratie kan worden uitgevoerd door de rekenknooppunt- en rasterhoofdtoepassingen of door een taak met diagnostische logboekregistratie van Batch. Logboekinformatie over de prestaties van de Batch-uitvoeringen kan worden geconfigureerd om te bepalen welke gebieden moeten worden verbeterd voor betere prestaties en snellere voltooiing van taken.
Aangepaste Batch-bewaking en logboekregistratie
De toepassingen voor het beheren van toepassingen en rekenknooppunten kunnen deze gegevens genereren en opslaan voor verdere analyse. Gegevens die nuttig zijn gevonden bij het optimaliseren van Batch-taken zijn onder andere:
- Begin- en eindtijden voor elke taak
- De tijd dat elk rekenknooppunt actief is en taken uitvoert
- De tijd dat elk rekenknooppunt actief is en geen taken uitvoert
- De totale uitvoeringstijd van de batchtaak
Diagnostische logboekregistratie in Batch
Er is een alternatief voor het gebruik van de controller- en rekenknooppunttoepassingen om instrumentatiegegevens te verzenden. Logboekregistratie van diagnostische gegevens in Batch kan veel van de uitvoeringsgegevens vastleggen. Diagnostische logboekregistratie in Batch is niet standaard ingeschakeld en moet zijn ingeschakeld voor het Batch-account.
Diagnostische logboekregistratie in Batch biedt een aanzienlijke hoeveelheid gegevens die kan helpen bij het vastleggen van problemen en het optimaliseren van Batch-uitvoeringen. Begin- en eindtijden voor taken, kernaantal, totaal aantal knooppunten en vele andere metrische gegevens.
Voor batchlogboekregistratie is een opslagbestemming vereist voor de logboeken die worden verzonden, waardoor gebeurtenissen worden opgeslagen die worden geproduceerd door de Batch-uitvoering, zoals het maken van een pool, het uitvoeren van taken, het uitvoeren van taken, enzovoort. Naast het opslaan van diagnostische logboekgebeurtenissen in een Azure Storage-account, kunnen batchservicelogboekgebeurtenissen worden gestreamd naar een exemplaar van Azure Event Hubs. De gebeurtenissen kunnen vervolgens worden verzonden naar Azure Log Analytics.
Met deze gegevens kunnen kern-computing- en hoofdknooppunttoepassingen worden geoptimaliseerd. Dit kan de kosten verlagen, omdat de inrichting van werkrol-VM's sneller wordt gedeprovisioned, wanneer ze niet meer nodig zijn, in plaats van te wachten tot het einde van de Batch-uitvoering is voltooid.
Hulpprogramma's voor Batch-beheer
Azure Portal biedt een Batch-bewakingsdashboard met informatie over Batch wanneer taken worden uitgevoerd en zelfs het quotumgebruik van accounts. Het is voldoende voor veel Batch-taaktoepassingen.
Naast de hulpprogramma's voor Batch-beheer en visualisatie die beschikbaar zijn in Azure Portal, is er een gratis opensource-hulpprogramma, Batch Explorer, voor het beheren van Batch. Dit is een zelfstandig clienthulpprogramma voor het maken, opsporen en bewaken van Azure Batch-toepassingen. Download een installatiepakket voor Mac, Linux of Windows.
Netwerkmodellen
Voor risicoanalyse moeten vaak honderden, zo niet duizenden, documenten worden opgenomen in het risicorastercomputingsproces. Deze bestanden bevinden zich vaak on-premises in een bestandsarchief, netwerkshare of andere opslagplaats. Wanneer u vm's op basis van Azure gebruikt om deze bestanden te openen en te verwerken, is het vaak handig om het on-premises netwerk naadloos te verbinden met het Azure-netwerk, zodat bestandstoegang eenvoudig en snel is. Deze aanpak kan zelfs betekenen dat er geen codewijzigingen nodig zijn voor de code die de verwerking op de rekenknooppunten uitvoert.
Azure biedt twee modellen voor het veilig en betrouwbaar verbinden van huidige on-premises systemen met Azure, Microsoft Azure ExpressRoute en VPN Gateway. Beide bieden veilige betrouwbare connectiviteit, hoewel er verschillen zijn in implementatie, prestaties en andere kenmerken.
U kunt ook het hoofdknooppunt van het risicoraster on-premises gebruiken en de Batch-taak uitvoeren via de REST API's of SDK's in .NET en andere talen.
Er zijn andere technieken voor het overbruggen van de kloof tussen Azure- en on-premises resources zonder een hybride netwerkoplossing. Hieronder vindt u meer informatie.
ExpressRoute
ExpressRoute verbindt uw on-premises netwerk of datacenternetwerk met Azure via een privéverbinding die wordt gefaciliteerd door een connectiviteitspartner, zoals uw huidige internetprovider. Hierdoor kunnen beide netwerken elkaar zien als hetzelfde netwerkexemplaren, waardoor naadloze toegang tussen netwerken mogelijk is. Netwerkintegratie is essentieel wanneer u bestaande on-premises systemen wilt integreren met een Azure-netwerk en ExpressRoute de snelste verbindingssnelheden biedt.
Meer informatie over prijzen voor Azure ExpressRoute vindt u hier.
VPN Gateway
Een VPN Gateway is een andere manier om uw netwerk te verbinden met Azure. Het nadeel van dit model is dat verkeer via internet stroomt. De verbinding kan als gevolg hiervan minder tolerant zijn en netwerksnelheden kunnen die van ExpressRoute niet bereiken, maar dit is mogelijk geen belemmering voor een scenario voor risicorastercomputing, omdat het lezen van gegevensbestanden doorgaans een snelle bewerking is.
Meer informatie over prijzen voor VPN Gateway vindt u hier.
Opties voor connectiviteitsgegevens
Er zijn in wezen twee modellen voor het uitbreiden van uw netwerk naar Azure, zoals wordt weergegeven in afbeelding 5.
- Virtuele gateway : site-naar-site
- ExpressRoute : Exchange- of ISP-provider
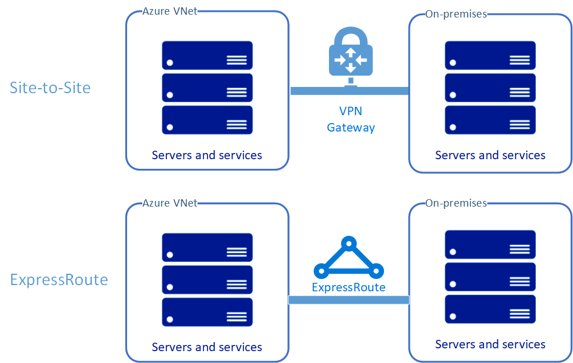
Afbeelding 5: Site-naar-site en ExpressRoute
Site-naar-site-integratie van virtuele gateway
Een site-naar-site-VPN-gateway verbindt uw on-premises netwerk met een Azure-VNet. Dit overbrugt de kloof tussen netwerken, waardoor ze in feite delen van hetzelfde netwerk maken, met tweerichtingstoegang tot resources, servers en artefacten. Hiermee hebt u rechtstreeks toegang tot gegevensbestanden van de Azure-werkrol-VM's waarop de batchtaak voor risicorastercomputing wordt uitgevoerd.
ExpressRoute-integratie
Een ExpressRoute-verbinding die wordt gefaciliteerd door een Azure-partnernetwerkprovider realiseert dezelfde voordelen als een site-naar-site-verbinding, maar met hogere snelheden en betrouwbaarheid.
Meer informatie over ExpressRoute-connectiviteitsmodellen.
Batchverwerking zonder een hybride Azure-netwerk
Een ander Batch-scenario is het uploaden van alle gegevensbestanden naar Azure Storage voor latere verwerking door rekenmachines op basis van Azure. Bestandsopslag en Blob Storage zijn waarschijnlijk kandidaten voor het opslaan van gegevens van risicorastercomputing.
In dit scenario wonen de taakcontroller en alle rekenknooppunten in Azure, zoals weergegeven in afbeelding 6. De waarschijnlijke bestemming voor verwerkte gegevens is een Azure-gegevensarchief, ter voorbereiding op verdere verwerking door Azure Machine Learning-oplossingen of andere systemen. Deze aanvullende verwerking valt buiten het bereik van dit artikel.
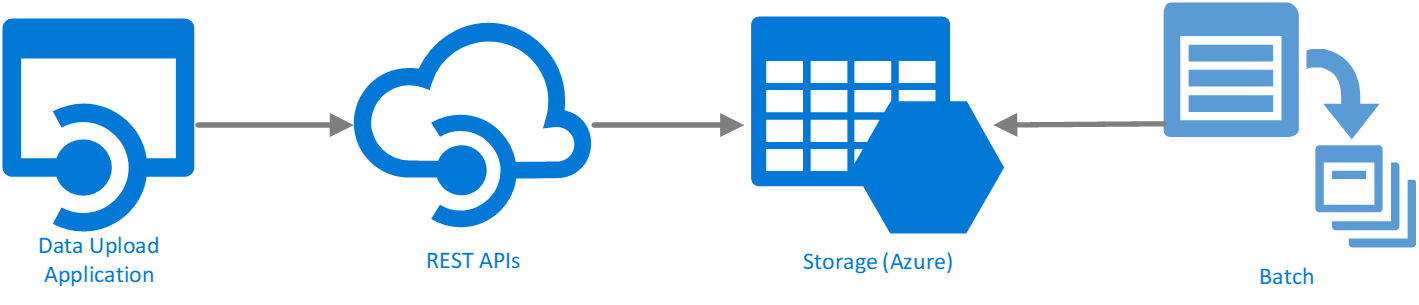
Afbeelding 6: Batchupload naar uitvoeringslevenscyclus
Resources voor hybride netwerkconnectiviteit
In uw situatie kunnen verschillende configuraties van toepassing zijn. Zie het artikel Verbinding maken een on-premises netwerk met Azure door de groep patronen en procedures om u te helpen bij beslissingen en architectuurrichtlijnen met betrekking tot het verbinden van netwerkconnectiviteit met Azure.
- Zie dit artikel voor alternatieven voor VPN Gateway-configuratie.
- Meer informatie over ExpressRoute-connectiviteitsmodellen.
- ExpressRoute-prijzen berekenen.
- Prijzen voor VPN Gateway berekenen.
Beveiligingsoverwegingen
Er kan een virtueel Azure-netwerk (VNet) worden gemaakt en de rekenknooppunten van de pool die erin zijn gemaakt. Dit biedt een extra isolatieniveau voor de Batch-uitvoeringen en staat verificatie toe met behulp van Microsoft Entra-id. Zie De netwerkconfiguratie van de pool voor meer informatie.
Er zijn twee manieren om een Batch-toepassing te verifiëren met behulp van Microsoft Entra-id:
Geïntegreerde verificatie. Een batchtoepassing met Behulp van Microsoft Entra-accounts kan het account gebruiken om resources te verkrijgen voor gegevensarchieven en andere resources.
Service-principal. Microsoft Entra-service-principals definiëren toegangsbeleid en machtigingen voor gebruikers en toepassingen. Een service-principal biedt gebruikers verificatie met behulp van een geheime sleutel die is gekoppeld aan die toepassing. Hierdoor kan een toepassing zonder toezicht worden geverifieerd met een geheime sleutel. Een service-principal definieert het beleid en de machtigingen voor een toepassing die de toepassing vertegenwoordigt bij het openen van resources tijdens runtime. Klik hier voor meer informatie.
Zie dit artikel voor meer informatie over beveiliging in batchverwerking met Microsoft Entra-id.
De Batch-service kan ook worden geverifieerd met een gedeelde sleutel. Voor de verificatieservice moeten twee headerwaarden worden toegevoegd aan de HTTP-aanvraag, gegevens en autorisatie. Zie hier voor meer informatie over verificatie met gedeelde sleutels.
Kostenoptimalisatie
Er worden geen kosten in rekening gebracht voor het gebruik van Azure Batch. U betaalt alleen voor de onderliggende resources die worden verbruikt, zoals uptime van virtuele machines, opslag en netwerken. De vm's van het rekenknooppunt kosten echter nog steeds geld wanneer ze inactief zijn, dus het is een goed idee om de inrichting van machines ongedaan te maken wanneer ze niet meer nodig zijn. Dit wordt vaak gedaan door de pool te verwijderen die ze bevat.
Wanneer u een pool maakt, kunt u opgeven welke typen rekenknooppunten u wilt en het aantal knooppunten. De twee typen rekenknooppunten zijn als volgt:
Toegewezen rekenknooppunten zijn gereserveerd voor uw workloads. Ze zijn duurder dan knooppunten met een lage prioriteit, maar ze worden gegarandeerd nooit verschoven.
Rekenknooppunten met lage prioriteit profiteren van overtollige capaciteit in Azure om Batch-workloads uit te voeren. Knooppunten met lage prioriteit zijn minder duur per uur dan toegewezen knooppunten en maken workloads mogelijk met veel rekencapaciteit. Zie voor meer informatie VM's met lage prioriteit gebruiken met Batch.
Toegewezen en knooppunten met lage prioriteit kunnen zich in dezelfde pool bevinden.
Zie Batch-prijzen voor informatie over prijzen voor rekenknooppunten met lage prioriteit en toegewezen rekenknooppunten.
Bij het gebruik van de Batch Diagnostic Logging-service worden er kosten in rekening gebracht voor de gegevens die naar Azure Storage worden verzonden. Dit zijn opslaggegevens zoals andere gegevens en de prijzen worden beïnvloed door de hoeveelheid diagnostische gegevens die worden bewaard.
Aan de slag
Hoewel er veel plaatsen zijn om aan de slag te gaan met een complex domein zoals Batch-computing voor risicorastercomputing, zijn hier enkele logische uitgangspunten om de Batch-technologie beter te begrijpen.
De Documentatie van Azure Batch is een uitstekende plek om te beginnen. De documentatie bevat portalvoorbeelden, API-verwijzingen en stapsgewijze zelfstudies met codevoorbeelden. De Azure Batch-voorbeeldtoepassingen zijn ook vrij beschikbaar op GitHub.
Hieronder vindt u enkele snelle zelfstudies om u te helpen bij het bouwen van een eenvoudige toepassing om batch-rekentaken te maken en uit te voeren. Opties voor het bouwen van de toepassing zijn als volgt:
- Batch .NET API
- Batch SDK voor Python
- Batch SDK voor Node.js
- Batchbeheer met PowerShell
- Batchbeheer met de Azure CLI
Overweeg een proof-of-concept-initiatief te starten. Wat is uw benadering voor gegevensopname in Azure? Gebruikt u een hybride netwerk of uploadt u gegevens via een SDK- of REST-interface? Als u een hybride netwerk overweegt, kunt u overwegen om een testfase uit te voeren om dit in te stellen.
Evalueer de grootte van uw Batch-rekentaken en selecteer vervolgens de juiste schaaloplossing. Formules voor automatisch schalen maken complexe planningsscenario's mogelijk, terwijl eenvoudigere scenario's mogelijk zijn met behulp van Azure Portal.
Onderdelen
Azure Batch biedt mogelijkheden voor het uitvoeren van grootschalige parallelle verwerkingstaken in de cloud.
Microsoft Entra ID is een multitenant, cloudgebaseerde directory en identiteitsbeheerservice die kerndirectoryservices, toepassingstoegangsbeheer en identiteitsbeveiliging combineert in één oplossing.
Formules voor automatisch schalen zijn scripts die worden geüpload naar de batchverwerkingsplanner voor fijnmazige controle over het gedrag van Batch-schaalaanpassing.
Logboekregistratie van Diagnostische gegevens in Batch is een functie van Azure Batch waarmee u een gedetailleerd logboek kunt maken van uw Batch-uitvoeringen en de gegenereerde gebeurtenissen. Logboeken worden opgeslagen in Azure Storage.
Batch Explorer is een zelfstandige toepassing voor Batch-bewaking en -beheer die beschikbaar is voor Windows, macOS en Linux.
ExpressRoute is een hybride netwerkoplossing met hoge snelheid en betrouwbaarheid voor het toevoegen van on-premises en Azure-netwerken.
Azure VPN Gateway is een hybride netwerkoplossing die gebruikmaakt van internet voor het toevoegen van on-premises netwerken en Azure-netwerken.
Conclusie
Dit document biedt een overzicht van technische oplossingen en overwegingen bij het gebruik van Azure Batch voor computing op het risicoraster voor het bankwezen. In het artikel is veel besproken van de definitie van Azure Batch tot netwerkopties en zelfs kostenoverwegingen.
Medewerkers
Dit artikel wordt onderhouden door Microsoft. De tekst is oorspronkelijk geschreven door de volgende Inzenders.
Belangrijkste auteurs:
- David Starr | Principal Solutions Architect
Volgende stappen
Bij het evalueren van Azure Batch voor risicorastercomputing is deze pagina een goede resource om aan de slag te gaan. Het biedt voorbeeldhandleidingen voor parallelle bestandsverwerking, die inherent zijn aan risicorastercomputing. Zelfstudies worden aangeboden met behulp van Azure Portal, Azure CLI, .NET en Python.
Productdocumentatie: