R-scriptonderdeel uitvoeren
In dit artikel wordt beschreven hoe u het onderdeel R-script uitvoeren gebruikt om R-code uit te voeren in uw Azure Machine Learning Designer-pijplijn.
Met R kunt u taken uitvoeren die niet worden ondersteund door bestaande onderdelen, zoals:
- Aangepaste gegevenstransformaties maken
- Uw eigen metrische gegevens gebruiken om voorspellingen te evalueren
- Modellen bouwen met behulp van algoritmen die niet zijn geïmplementeerd als zelfstandige onderdelen in de ontwerpfunctie
Ondersteuning voor R-versies
Azure Machine Learning Designer maakt gebruik van de CRAN-distributie (Comprehensive R Archive Network) van R. De momenteel gebruikte versie is CRAN 3.5.1.
Ondersteunde R-pakketten
De R-omgeving is vooraf geïnstalleerd met meer dan 100 pakketten. Zie de sectie Vooraf geïnstalleerde R-pakketten voor een volledige lijst.
U kunt ook de volgende code toevoegen aan een R-scriptonderdeel uitvoeren om de geïnstalleerde pakketten weer te geven.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
dataframe1 <- data.frame(installed.packages())
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Notitie
Als uw pijplijn meerdere execute R Script-onderdelen bevat die pakketten nodig hebben die niet in de vooraf geïnstalleerde lijst staan, installeert u de pakketten in elk onderdeel.
R-pakketten installeren
Gebruik de install.packages() methode om extra R-pakketten te installeren. Pakketten worden geïnstalleerd voor elk R-scriptonderdeel uitvoeren. Ze worden niet gedeeld met andere onderdelen van Execute R Script.
Notitie
Het wordt NIET aanbevolen om het R-pakket te installeren vanuit de scriptbundel. Het wordt aanbevolen om pakketten rechtstreeks in de scripteditor te installeren.
Geef de CRAN-opslagplaats op wanneer u pakketten installeert, zoals install.packages("zoo",repos = "https://cloud.r-project.org").
Waarschuwing
Het excute R-scriptonderdeel biedt geen ondersteuning voor het installeren van pakketten waarvoor systeemeigen compilatie is vereist, zoals qdap een pakket waarvoor JAVA is vereist en drc een pakket waarvoor C++ is vereist. Dit komt doordat dit onderdeel wordt uitgevoerd in een vooraf geïnstalleerde omgeving met niet-beheerdersmachtigingen.
Installeer geen pakketten die vooraf zijn gebouwd op/voor Windows, omdat de ontwerponderdelen worden uitgevoerd op Ubuntu. Als u wilt controleren of een pakket vooraf is gebouwd in Windows, kunt u naar CRAN gaan en uw pakket doorzoeken, één binair bestand downloaden op basis van uw besturingssysteem en ingebouwd: deel in het DESCRIPTION-bestand controleren. Hier volgt een voorbeeld: 
In dit voorbeeld ziet u hoe u Zoo installeert:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
if(!require(zoo)) install.packages("zoo",repos = "https://cloud.r-project.org")
library(zoo)
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Notitie
Voordat u een pakket installeert, controleert u of het al bestaat, zodat u een installatie niet herhaalt. Herhaalde installaties kunnen ertoe leiden dat er een time-out optreedt voor webserviceaanvragen.
Toegang tot geregistreerde gegevensset
U kunt de volgende voorbeeldcode raadplegen voor toegang tot de geregistreerde gegevenssets in uw werkruimte:
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
run = get_current_run()
ws = run$experiment$workspace
dataset = azureml$core$dataset$Dataset$get_by_name(ws, "YOUR DATASET NAME")
dataframe2 <- dataset$to_pandas_dataframe()
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
R-script uitvoeren configureren
Het onderdeel R-script uitvoeren bevat voorbeeldcode als uitgangspunt.
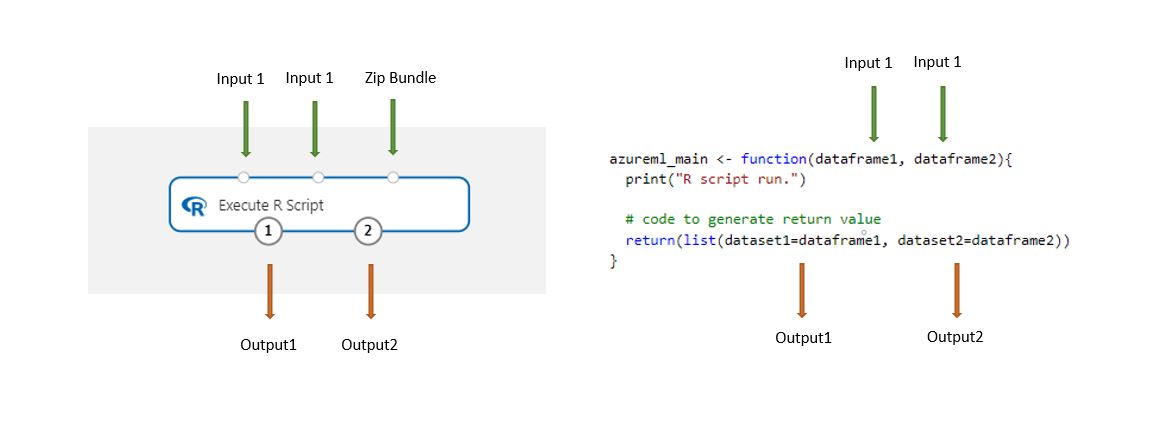
Gegevenssets die zijn opgeslagen in de ontwerpfunctie, worden automatisch geconverteerd naar een R-gegevensframe wanneer ze met dit onderdeel worden geladen.
Voeg het onderdeel R-script uitvoeren toe aan uw pijplijn.
Verbind alle invoer die het script nodig heeft. Invoer is optioneel en kan gegevens en aanvullende R-code bevatten.
Gegevensset1: verwijs naar de eerste invoer als
dataframe1. De invoergegevensset moet zijn opgemaakt als een CSV-, TSV- of ARFF-bestand. U kunt ook een Azure Machine Learning-gegevensset verbinden.Gegevensset2: verwijs naar de tweede invoer als
dataframe2. Deze gegevensset moet ook zijn opgemaakt als een CSV-, TSV- of ARFF-bestand of als een Azure Machine Learning-gegevensset.Scriptbundel: De derde invoer accepteert .zip bestanden. Een zip-bestand kan meerdere bestanden en meerdere bestandstypen bevatten.
Typ of plak een geldig R-script in het tekstvak R-script .
Notitie
Wees voorzichtig bij het schrijven van uw script. Zorg ervoor dat er geen syntaxisfouten zijn, zoals het gebruik van niet-opgegeven variabelen of niet-geimporteerde onderdelen of functies. Besteed extra aandacht aan de vooraf geïnstalleerde pakketlijst aan het einde van dit artikel. Als u pakketten wilt gebruiken die niet worden vermeld, installeert u deze in uw script. Een voorbeeld is
install.packages("zoo",repos = "https://cloud.r-project.org").Om u op weg te helpen, wordt het tekstvak R-script vooraf ingevuld met voorbeeldcode, die u kunt bewerken of vervangen.
# R version: 3.5.1 # The script MUST contain a function named azureml_main, # which is the entry point for this component. # Note that functions dependent on the X11 library, # such as "View," are not supported because the X11 library # is not preinstalled. # The entry point function MUST have two input arguments. # If the input port is not connected, the corresponding # dataframe argument will be null. # Param<dataframe1>: a R DataFrame # Param<dataframe2>: a R DataFrame azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # If a .zip file is connected to the third input port, it's # unzipped under "./Script Bundle". This directory is added # to sys.path. # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }De invoerpuntfunctie moet de invoerargumenten
Param<dataframe1>enParam<dataframe2>hebben, zelfs als deze argumenten niet worden gebruikt in de functie.Notitie
Naar de gegevens die worden doorgegeven aan het onderdeel Execute R Script wordt verwezen als
dataframe1endataframe2, wat verschilt van Azure Machine Learning Designer (de ontwerpfunctieverwijzing isdataset1,dataset2). Zorg ervoor dat in het script correct naar invoergegevens wordt verwezen.Notitie
Bestaande R-code moet mogelijk kleine wijzigingen hebben om in een ontwerppijplijn uit te voeren. Invoergegevens die u in CSV-indeling opgeeft, moeten bijvoorbeeld expliciet worden geconverteerd naar een gegevensset voordat u deze in uw code kunt gebruiken. Gegevens- en kolomtypen die in de R-taal worden gebruikt, verschillen in sommige opzichten ook van de gegevens- en kolomtypen die in de ontwerpfunctie worden gebruikt.
Als uw script groter is dan 16 kB, gebruikt u de poort scriptbundel om fouten te voorkomen zoals CommandLine overschrijdt de limiet van 16597 tekens.
- Bundel het script en andere aangepaste resources in een zip-bestand.
- Upload het ZIP-bestand als een bestandsgegevensset naar de studio.
- Sleep het gegevenssetonderdeel vanuit de lijst Gegevenssets in het linkerdeelvenster van de ontwerppagina.
- Verbind het gegevenssetonderdeel met de poort scriptbundel van het onderdeel R Script uitvoeren .
Hieronder ziet u de voorbeeldcode om het script in de scriptbundel te gebruiken:
azureml_main <- function(dataframe1, dataframe2){ # Source the custom R script: my_script.R source("./Script Bundle/my_script.R") # Use the function that defined in my_script.R dataframe1 <- my_func(dataframe1) sample <- readLines("./Script Bundle/my_sample.txt") return (list(dataset1=dataframe1, dataset2=data.frame("Sample"=sample))) }Voer voor Willekeurig zaad een waarde in die u in de R-omgeving wilt gebruiken als de willekeurige seed-waarde. Deze parameter is gelijk aan het aanroepen
set.seed(value)in R-code.Verzend de pijplijn.
Resultaten
R-scriptonderdelen uitvoeren kunnen meerdere uitvoerwaarden retourneren, maar deze moeten worden opgegeven als R-gegevensframes. De ontwerpfunctie converteert gegevensframes automatisch naar gegevenssets voor compatibiliteit met andere onderdelen.
Standaardberichten en fouten van R worden geretourneerd naar het logboek van het onderdeel.
Als u resultaten wilt afdrukken in het R-script, vindt u de afgedrukte resultaten in 70_driver_log onder het tabblad Uitvoer en logboeken in het rechterdeelvenster van het onderdeel.
Voorbeeldscripts
Er zijn veel manieren om uw pijplijn uit te breiden met behulp van aangepaste R-scripts. Deze sectie bevat voorbeeldcode voor algemene taken.
Een R-script toevoegen als invoer
Het onderdeel Execute R Script ondersteunt willekeurige R-scriptbestanden als invoer. Als u ze wilt gebruiken, moet u ze uploaden naar uw werkruimte als onderdeel van het .zip-bestand.
Als u een .zip-bestand met R-code wilt uploaden naar uw werkruimte, gaat u naar de assetpagina Gegevenssets . Selecteer Gegevensset maken en selecteer vervolgens Van lokaal bestand en de optie Type bestandsgegevensset.
Controleer of het zip-bestand wordt weergegeven in Mijn gegevenssets onder de categorie Gegevenssets in de linkeronderdelenstructuur.
Verbind de gegevensset met de invoerpoort scriptbundel .
Alle bestanden in het .zip-bestand zijn beschikbaar tijdens de uitvoering van de pijplijn.
Als het scriptbundelbestand een mapstructuur bevat, blijft de structuur behouden. Maar u moet uw code wijzigen om de map ./Script Bundle toe te voegen aan het pad.
Gegevens verwerken
In het volgende voorbeeld ziet u hoe u invoergegevens kunt schalen en normaliseren:
# R version: 3.5.1
# The script MUST contain a function named azureml_main,
# which is the entry point for this component.
# Note that functions dependent on the X11 library,
# such as "View," are not supported because the X11 library
# is not preinstalled.
# The entry point function MUST have two input arguments.
# If the input port is not connected, the corresponding
# dataframe argument will be null.
# Param<dataframe1>: a R DataFrame
# Param<dataframe2>: a R DataFrame
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
# If a .zip file is connected to the third input port, it's
# unzipped under "./Script Bundle". This directory is added
# to sys.path.
series <- dataframe1$width
# Find the maximum and minimum values of the width column in dataframe1
max_v <- max(series)
min_v <- min(series)
# Calculate the scale and bias
scale <- max_v - min_v
bias <- min_v / dis
# Apply min-max normalizing
dataframe1$width <- dataframe1$width / scale - bias
dataframe2$width <- dataframe2$width / scale - bias
# Return datasets as a Named List
return(list(dataset1=dataframe1, dataset2=dataframe2))
}
Een .zip-bestand als invoer lezen
In dit voorbeeld ziet u hoe u een gegevensset in een .zip-bestand gebruikt als invoer voor het onderdeel R-script uitvoeren.
- Maak het gegevensbestand in CSV-indeling en geef het de naammydatafile.csv.
- Maak een .zip-bestand en voeg het CSV-bestand toe aan het archief.
- Upload het zip-bestand naar uw Azure Machine Learning-werkruimte.
- Verbind de resulterende gegevensset met de ScriptBundle-invoer van het onderdeel Execute R Script .
- Gebruik de volgende code om de CSV-gegevens uit het zip-bestand te lezen.
azureml_main <- function(dataframe1, dataframe2){
print("R script run.")
mydataset<-read.csv("./Script Bundle/mydatafile.csv",encoding="UTF-8");
# Return datasets as a Named List
return(list(dataset1=mydataset, dataset2=dataframe2))
}
Rijen repliceren
In dit voorbeeld ziet u hoe u positieve records in een gegevensset repliceert om het voorbeeld te verdelen:
azureml_main <- function(dataframe1, dataframe2){
data.set <- dataframe1[dataframe1[,1]==-1,]
# positions of the positive samples
pos <- dataframe1[dataframe1[,1]==1,]
# replicate the positive samples to balance the sample
for (i in 1:20) data.set <- rbind(data.set,pos)
row.names(data.set) <- NULL
# Return datasets as a Named List
return(list(dataset1=data.set, dataset2=dataframe2))
}
R-objecten doorgeven tussen onderdelen van R-script uitvoeren
U kunt R-objecten doorgeven tussen exemplaren van het onderdeel R-script uitvoeren met behulp van het interne serialisatiemechanisme. In dit voorbeeld wordt ervan uitgegaan dat u het R-object met de naam A wilt verplaatsen tussen twee execute R Script-onderdelen.
Voeg het eerste onderdeel Execute R Script toe aan uw pijplijn. Voer vervolgens de volgende code in het tekstvak R-script in om een geserialiseerd object
Ate maken als een kolom in de uitvoergegevenstabel van het onderdeel:azureml_main <- function(dataframe1, dataframe2){ print("R script run.") # some codes generated A serialized <- as.integer(serialize(A,NULL)) data.set <- data.frame(serialized,stringsAsFactors=FALSE) return(list(dataset1=data.set, dataset2=dataframe2)) }De expliciete conversie naar het type geheel getal wordt uitgevoerd omdat de serialisatiefunctie gegevens uitvoert in de R-indeling
Raw, die de ontwerper niet ondersteunt.Voeg een tweede exemplaar van het onderdeel Execute R Script toe en verbind dit met de uitvoerpoort van het vorige onderdeel.
Typ de volgende code in het tekstvak R-script om het object
Auit de tabel met invoergegevens te extraheren.azureml_main <- function(dataframe1, dataframe2){ print("R script run.") A <- unserialize(as.raw(dataframe1$serialized)) # Return datasets as a Named List return(list(dataset1=dataframe1, dataset2=dataframe2)) }
Vooraf geïnstalleerde R-pakketten
De volgende vooraf geïnstalleerde R-pakketten zijn momenteel beschikbaar:
| Pakket | Versie |
|---|---|
| Askpass | 1.1 |
| assertthat | 0.2.1 |
| backports | 1.1.4 |
| base | 3.5.1 |
| base64enc | 0.1-3 |
| BH | 1.69.0-1 |
| bindr | 0.1.1 |
| bindrcpp | 0.2.2 |
| bitops | 1.0-6 |
| boot | 1.3-22 |
| broom | 0.5.2 |
| callr | 3.2.0 |
| dakje | 6.0-84 |
| caTools | 1.17.1.2 |
| cellranger | 1.1.0 |
| klasse | 7.3-15 |
| cli | 1.1.0 |
| clipr | 0.6.0 |
| cluster | 2.0.7-1 |
| codetools | 0.2-16 |
| colorspace | 1.4-1 |
| compiler | 3.5.1 |
| crayon | 1.3.4 |
| curl | 3,3 |
| data.table | 1.12.2 |
| gegevenssets | 3.5.1 |
| DBI | 1.0.0 |
| dbplyr | 1.4.1 |
| digest | 0.6.19 |
| dplyr | 0.7.6 |
| e1071 | 1.7-2 |
| evaluate | 0,14 |
| fansi | 0.4.0 |
| forcats | 0.3.0 |
| foreach | 1.4.4 |
| foreign | 0.8-71 |
| Fs | 1.3.1 |
| gdata | 2.18.0 |
| Generics | 0.0.2 |
| ggplot2 | 3.2.0 |
| glmnet | 2.0-18 |
| glue | 1.3.1 |
| gower | 0.2.1 |
| gplots | 3.0.1.1 |
| afbeeldingen | 3.5.1 |
| grDevices | 3.5.1 |
| grid | 3.5.1 |
| gtable | 0.3.0 |
| gtools | 3.8.1 |
| haven | 2.1.0 |
| highr | 0,8 |
| hms | 0.4.2 |
| htmltools | 0.3.6 |
| httr | 1.4.0 |
| ipred | 0.9-9 |
| iterators | 1.0.10 |
| jsonlite | 1.6 |
| KernSmooth | 2.23-15 |
| knitr | 1,23 |
| labeling | 0.3 |
| lattice | 0.20-38 |
| lava | 1.6.5 |
| lazyeval | 0.2.2 |
| lubridate | 1.7.4 |
| magrittr | 1.5 |
| markdown | 1 |
| MASS | 7.3-51.4 |
| Matrix | 1.2-17 |
| methods | 3.5.1 |
| mgcv | 1.8-28 |
| mime | 0,7 |
| ModelMetrics | 1.2.2 |
| modelr | 0.1.4 |
| munsell | 0.5.0 |
| nlme | 3.1-140 |
| nnet | 7.3-12 |
| numDeriv | 2016.8-1.1 |
| openssl | 1.4 |
| parallel | 3.5.1 |
| pillar | 1.4.1 |
| pkgconfig | 2.0.2 |
| plogr | 0.2.0 |
| plyr | 1.8.4 |
| prettyunits | 1.0.2 |
| processx | 3.3.1 |
| prodlim | 2018.04.18 |
| progress | 1.2.2 |
| ps | 1.3.0 |
| purrr | 0.3.2 |
| quadprog | 1.5-7 |
| quantmod | 0.4-15 |
| R6 | 2.4.0 |
| randomForest | 4.6-14 |
| RColorBrewer | 1.1-2 |
| Rcpp | 1.0.1 |
| RcppRoll | 0.3.0 |
| readr | 1.3.1 |
| readxl | 1.3.1 |
| recipes | 0.1.5 |
| rematch | 1.0.1 |
| reprex | 0.3.0 |
| reshape2 | 1.4.3 |
| reticulate | 1.12 |
| rlang | 0.4.0 |
| rmarkdown | 1.13 |
| ROCR | 1.0-7 |
| rpart | 4.1-15 |
| rstudioapi | 0,1 |
| rvest | 0.3.4 |
| scales | 1.0.0 |
| selectr | 0.4-1 |
| spatial | 7.3-11 |
| splines | 3.5.1 |
| SQUAREM | 2017.10-1 |
| stats | 3.5.1 |
| stats4 | 3.5.1 |
| stringi | 1.4.3 |
| stringr | 1.3.1 |
| survival | 2.44-1.1 |
| sys | 3,2 |
| tcltk | 3.5.1 |
| tibble | 2.1.3 |
| tidyr | 0.8.3 |
| tidyselect | 0.2.5 |
| tidyverse | 1.2.1 |
| timeDate | 3043.102 |
| tinytex | 0.13 |
| tools | 3.5.1 |
| tseries | 0.10-47 |
| TTR | 0.23-4 |
| utf8 | 1.1.4 |
| utils | 3.5.1 |
| vctrs | 0.1.0 |
| viridisLite | 0.3.0 |
| whisker | 0.3-2 |
| withr | 2.1.2 |
| xfun | 0,8 |
| xml2 | 1.2.0 |
| xts | 0.11-2 |
| yaml | 2.2.0 |
| zeallot | 0.1.0 |
| zoo | 1.8-6 |
Volgende stappen
Bekijk de set onderdelen die beschikbaar zijn voor Azure Machine Learning.