Gegevensonderdeel normaliseren
In dit artikel wordt een onderdeel in de Azure Machine Learning-ontwerpfunctie beschreven.
Gebruik dit onderdeel om een gegevensset te transformeren via normalisatie.
Normalisatie is een techniek die vaak wordt toegepast als onderdeel van gegevensvoorbereiding voor machine learning. Het doel van normalisatie is om de waarden van numerieke kolommen in de gegevensset te wijzigen om een algemene schaal te gebruiken, zonder verschillen in de waardenbereiken te vervormen of informatie te verliezen. Normalisatie is ook vereist voor sommige algoritmen om de gegevens correct te modelleren.
Stel dat uw invoergegevensset één kolom bevat met waarden tussen 0 en 1 en een andere kolom met waarden tussen 10.000 en 100.000. Het grote verschil in de schaal van de getallen kan problemen veroorzaken wanneer u de waarden als functies probeert te combineren tijdens het modelleren.
Normalisatie voorkomt deze problemen door nieuwe waarden te maken die de algemene verdeling en verhoudingen in de brongegevens behouden, terwijl waarden binnen een schaal blijven die wordt toegepast op alle numerieke kolommen die in het model worden gebruikt.
Dit onderdeel biedt verschillende opties voor het transformeren van numerieke gegevens:
- U kunt alle waarden wijzigen in een schaal van 0-1 of de waarden transformeren door ze weer te geven als percentielrangen in plaats van absolute waarden.
- U kunt normalisatie toepassen op één kolom of op meerdere kolommen in dezelfde gegevensset.
- Als u de pijplijn wilt herhalen of dezelfde normalisatiestappen wilt toepassen op andere gegevens, kunt u de stappen opslaan als een normalisatietransformatie en toepassen op andere gegevenssets met hetzelfde schema.
Waarschuwing
Sommige algoritmen vereisen dat gegevens worden genormaliseerd voordat een model wordt getraind. Andere algoritmen voeren hun eigen gegevensschaal of normalisatie uit. Wanneer u een machine learning-algoritme kiest voor het bouwen van een voorspellend model, moet u daarom de gegevensvereisten van het algoritme controleren voordat u normalisatie toepast op de trainingsgegevens.
Gegevens normaliseren configureren
U kunt slechts één normalisatiemethode tegelijk toepassen met behulp van dit onderdeel. Daarom wordt dezelfde normalisatiemethode toegepast op alle kolommen die u selecteert. Als u verschillende normalisatiemethoden wilt gebruiken, gebruikt u een tweede instantie van Gegevens normaliseren.
Voeg het onderdeel Gegevens normaliseren toe aan uw pijplijn. U vindt het onderdeel In Azure Machine Learning, onder Gegevenstransformatie, in de categorie Schalen en verminderen .
Verbind een gegevensset die ten minste één kolom met alle getallen bevat.
Gebruik de kolomkiezer om de numerieke kolommen te kiezen die u wilt normaliseren. Als u geen afzonderlijke kolommen kiest, worden standaard alle numerieke kolommen in de invoer opgenomen en wordt hetzelfde normalisatieproces toegepast op alle geselecteerde kolommen.
Dit kan tot vreemde resultaten leiden als u numerieke kolommen opneemt die niet moeten worden genormaliseerd. Controleer de kolommen altijd zorgvuldig.
Als er geen numerieke kolommen worden gedetecteerd, controleert u de metagegevens van de kolom om te controleren of het gegevenstype van de kolom een ondersteund numeriek type is.
Tip
Als u ervoor wilt zorgen dat kolommen van een specifiek type als invoer worden opgegeven, gebruikt u het onderdeel Kolommen in gegevensset selecteren voordat u gegevens normaliseert.
0 gebruiken voor constante kolommen indien ingeschakeld: selecteer deze optie wanneer een numerieke kolom één onveranderlijke waarde bevat. Dit zorgt ervoor dat dergelijke kolommen niet worden gebruikt bij normalisatiebewerkingen.
Kies in de vervolgkeuzelijst Transformatiemethode één wiskundige functie die u wilt toepassen op alle geselecteerde kolommen.
Zscore: converteert alle waarden naar een z-score.
De waarden in de kolom worden getransformeerd met behulp van de volgende formule:
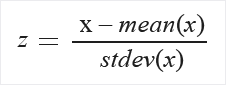
De gemiddelde en standaarddeviatie worden voor elke kolom afzonderlijk berekend. De standaarddeviatie van de populatie wordt gebruikt.
MinMax: met de min-max-normalizer wordt elke functie lineair aangepast aan het interval [0,1].
De schaalaanpassing naar het interval [0,1] wordt uitgevoerd door de waarden van elke functie te verplaatsen zodat de minimale waarde 0 is en vervolgens te delen door de nieuwe maximale waarde (het verschil tussen de oorspronkelijke maximum- en minimale waarden).
De waarden in de kolom worden getransformeerd met behulp van de volgende formule:

Logistiek: de waarden in de kolom worden getransformeerd met behulp van de volgende formule:

LogNormal: met deze optie worden alle waarden geconverteerd naar een logaritmische schaal.
De waarden in de kolom worden getransformeerd met behulp van de volgende formule:

Hier μ en σ de parameters van de verdeling, empirisch berekend op basis van de gegevens als schattingen van de maximale waarschijnlijkheid, voor elke kolom afzonderlijk.
TanH: Alle waarden worden geconverteerd naar een hyperbolische tangens.
De waarden in de kolom worden getransformeerd met behulp van de volgende formule:

Verzend de pijplijn of dubbelklik op het onderdeel Gegevens normaliseren en selecteer Geselecteerde uitvoeren.
Resultaten
Het onderdeel Normalize Data genereert twee uitvoerwaarden:
Als u de getransformeerde waarden wilt weergeven, klikt u met de rechtermuisknop op het onderdeel en selecteert u Visualiseren.
Standaard worden waarden op de plaats getransformeerd. Als u de getransformeerde waarden wilt vergelijken met de oorspronkelijke waarden, gebruikt u het onderdeel Kolommen toevoegen om de gegevenssets opnieuw te koppelen en de kolommen naast elkaar weer te geven.
Als u de transformatie wilt opslaan, zodat u dezelfde normalisatiemethode kunt toepassen op een andere gegevensset, selecteert u het onderdeel en selecteert u Gegevensset registreren op het tabblad Uitvoer in het rechterdeelvenster.
Vervolgens kunt u de opgeslagen transformaties laden vanuit de groep Transformaties van het linkernavigatiedeelvenster en deze toepassen op een gegevensset met hetzelfde schema met behulp van Transformatie toepassen.
Volgende stappen
Bekijk de set onderdelen die beschikbaar zijn voor Azure Machine Learning.