Gegevenswetenschap met een Windows-Data Science Virtual Machine
De Windows Data Science Virtual Machine (DSVM) is een krachtige ontwikkelomgeving voor gegevenswetenschap waar u gegevensverkennings- en modelleringstaken kunt uitvoeren. De omgeving is al gebouwd en gebundeld met verschillende populaire hulpprogramma's voor gegevensanalyse waarmee u eenvoudig aan de slag kunt met uw analyse voor on-premises, cloud- of hybride implementaties.
De DSVM werkt nauw samen met Azure-services. Het kan gegevens lezen en verwerken die al zijn opgeslagen in Azure, in Azure Synapse (voorheen SQL DW), Azure Data Lake, Azure Storage of Azure Cosmos DB. Het kan ook profiteren van andere analysehulpprogramma's, zoals Azure Machine Learning.
In dit artikel leert u hoe u uw DSVM kunt gebruiken om data science-taken uit te voeren en te communiceren met andere Azure-services. Hier volgen enkele dingen die u kunt doen op de DSVM:
Gebruik een Jupyter Notebook om te experimenteren met uw gegevens in een browser met behulp van Python 2, Python 3 en Microsoft R. (Microsoft R is een bedrijfsklare versie van R die is ontworpen voor prestaties.)
Verken gegevens en ontwikkel modellen lokaal op de DSVM met behulp van Microsoft Machine Learning Server en Python.
Beheer uw Azure-resources met behulp van de Azure Portal of PowerShell.
Breid uw opslagruimte uit en deel grootschalige gegevenssets/code met uw hele team door een Azure Files share te maken als een koppelbaar station op uw DSVM.
Deel code met uw team met behulp van GitHub. Open uw opslagplaats met behulp van de vooraf geïnstalleerde Git-clients: Git Bash en Git GUI.
Toegang tot Azure-gegevens- en analyseservices zoals Azure Blob Storage, Azure Cosmos DB, Azure Synapse (voorheen SQL DW) en Azure SQL Database.
Maak rapporten en een dashboard met behulp van het Power BI Desktop-exemplaar dat vooraf is geïnstalleerd op de DSVM en implementeer deze in de cloud.
Installeer extra hulpprogramma's op uw virtuele machine.
Notitie
Voor veel van de services voor gegevensopslag en analyse die in dit artikel worden vermeld, zijn extra gebruikskosten van toepassing. Zie de pagina met Azure-prijzen voor meer informatie.
Vereisten
- U hebt een Azure-abonnement nodig. U kunt zich registreren voor een gratis proefversie.
- Instructies voor het inrichten van een Data Science Virtual Machine op de Azure Portal zijn beschikbaar in Een virtuele machine maken.
Notitie
U wordt aangeraden de Azure Az PowerShell-module te gebruiken om te communiceren met Azure. Zie Azure PowerShell installeren om aan de slag te gaan. Raadpleeg Azure PowerShell migreren van AzureRM naar Az om te leren hoe u naar de Azure PowerShell-module migreert.
Jupyter-notebooks gebruiken
De Jupyter Notebook biedt een browsergebaseerde IDE voor het verkennen en modelleren van gegevens. U kunt Python 2, Python 3 of R gebruiken in een Jupyter Notebook.
Als u de Jupyter Notebook wilt starten, selecteert u het pictogram Jupyter Notebook in het Startmenu of op het bureaublad. In de DSVM-opdrachtprompt kunt u de opdracht jupyter notebook ook uitvoeren vanuit de map waar u bestaande notebooks hebt of waar u nieuwe notebooks wilt maken.
Nadat u Jupyter hebt gestart, gaat u naar de /notebooks map, bijvoorbeeld notebooks die vooraf zijn verpakt in de DSVM. U kunt nu:
- Selecteer het notebook om de code te zien.
- Voer elke cel uit door Shift+Enter te selecteren.
- Voer het hele notebook uit door Celuitvoering> te selecteren.
- Maak een nieuw notitieblok door het Jupyter-pictogram (linkerbovenhoek) te selecteren, rechts de knop Nieuw te selecteren en vervolgens de notebooktaal (ook wel kernels genoemd) te kiezen.
Notitie
Momenteel worden Python 2.7, Python 3.6, R, Julia en PySpark-kernels in Jupyter ondersteund. De R-kernel ondersteunt programmeren in zowel opensource R als Microsoft R.
Wanneer u zich in het notebook bevindt, kunt u uw gegevens verkennen, het model bouwen en het model testen met behulp van de bibliotheken van uw keuze.
Gegevens verkennen en modellen ontwikkelen met Microsoft Machine Learning Server
Notitie
Ondersteuning voor Machine Learning Server Standalone eindigt op 1 juli 2021. We verwijderen deze na 30 juni uit de DSVM-installatiekopieën. Bestaande implementaties blijven toegang hebben tot de software, maar vanwege de einddatum van de ondersteuning is er na 1 juli 2021 geen ondersteuning meer voor de software.
U kunt talen zoals R en Python gebruiken om uw gegevensanalyse rechtstreeks op de DSVM uit te voeren.
Voor R kunt u R Tools voor Visual Studio gebruiken. Microsoft heeft naast de opensource CRAN R extra bibliotheken beschikbaar gesteld om schaalbare analyses mogelijk te maken en gegevens te analyseren die groter zijn dan de geheugengrootte die is toegestaan in parallelle gesegmenteerde analyse.
Voor Python kunt u een IDE zoals Visual Studio Community Edition gebruiken, waarop de extensie Python Tools for Visual Studio (PTVS) vooraf is geïnstalleerd. Standaard wordt alleen Python 3.6, de Conda-hoofdomgeving, geconfigureerd op PTVS. Voer de volgende stappen uit om Anaconda Python 2.7 in te schakelen:
- Maak aangepaste omgevingen voor elke versie door naar Hulpprogramma's>Python Tools>Python-omgevingen te gaan en vervolgens + Aangepast te selecteren in Visual Studio Community Edition.
- Geef een beschrijving en stel het pad naar het omgevingsvoorvoegsel in als c:\anaconda\envs\python2 voor Anaconda Python 2.7.
- Selecteer Automatisch detecteren>Toepassen om de omgeving op te slaan.
Zie de documentatie over PTVS voor meer informatie over het maken van Python-omgevingen.
U bent nu klaar om een nieuw Python-project te maken. Ga naar Bestand>Nieuw>project>Python en selecteer het type Python-toepassing dat u bouwt. U kunt de Python-omgeving voor het huidige project instellen op de gewenste versie (Python 2.7 of 3.6) door met de rechtermuisknop op Python-omgevingen te klikken en vervolgens Python-omgevingen toevoegen/verwijderen te selecteren. Meer informatie over het werken met PTVS vindt u in de productdocumentatie.
Azure-resources beheren
Met de DSVM kunt u niet alleen uw analyseoplossing lokaal op de virtuele machine bouwen. Hiermee hebt u ook toegang tot services op het Azure-cloudplatform. Azure biedt verschillende services voor berekeningen, opslag, gegevensanalyse en andere services die u kunt beheren en openen vanuit uw DSVM.
Voor het beheren van uw Azure-abonnement en cloudresources hebt u twee opties:
Gebruik uw browser en ga naar de Azure Portal.
Gebruik PowerShell-scripts. Voer Azure PowerShell uit via een snelkoppeling op het bureaublad of vanuit het startmenu. Zie de documentatie voor Microsoft Azure PowerShell voor meer informatie.
Opslag uitbreiden met behulp van gedeelde bestandssystemen
Gegevenswetenschappers kunnen grote gegevenssets, code of andere resources binnen het team delen. De DSVM heeft ongeveer 45 GB aan ruimte beschikbaar. Als u uw opslag wilt uitbreiden, kunt u Azure Files gebruiken en deze koppelen aan een of meer DSVM-exemplaren of deze openen via een REST API. U kunt ook de Azure Portal gebruiken of Azure PowerShell gebruiken om extra toegewezen gegevensschijven toe te voegen.
Notitie
De maximale ruimte op de Azure Files share is 5 TB. De maximale grootte voor elk bestand is 1 TB.
U kunt dit script in Azure PowerShell gebruiken om een Azure Files share te maken:
# Authenticate to Azure.
Connect-AzAccount
# Select your subscription
Get-AzSubscription –SubscriptionName "<your subscription name>" | Select-AzSubscription
# Create a new resource group.
New-AzResourceGroup -Name <dsvmdatarg>
# Create a new storage account. You can reuse existing storage account if you want.
New-AzStorageAccount -Name <mydatadisk> -ResourceGroupName <dsvmdatarg> -Location "<Azure Data Center Name For eg. South Central US>" -Type "Standard_LRS"
# Set your current working storage account
Set-AzCurrentStorageAccount –ResourceGroupName "<dsvmdatarg>" –StorageAccountName <mydatadisk>
# Create an Azure Files share
$s = New-AzStorageShare <<teamsharename>>
# Create a directory under the file share. You can give it any name
New-AzStorageDirectory -Share $s -Path <directory name>
# List the share to confirm that everything worked
Get-AzStorageFile -Share $s
Nu u een Azure Files share hebt gemaakt, kunt u deze koppelen aan elke virtuele machine in Azure. U wordt aangeraden de virtuele machine in hetzelfde Azure-datacenter te plaatsen als het opslagaccount, om latentie en kosten voor gegevensoverdracht te voorkomen. Dit zijn de Azure PowerShell opdrachten om het station te koppelen aan de DSVM:
# Get the storage key of the storage account that has the Azure Files share from the Azure portal. Store it securely on the VM to avoid being prompted in the next command.
cmdkey /add:<<mydatadisk>>.file.core.windows.net /user:<<mydatadisk>> /pass:<storage key>
# Mount the Azure Files share as drive Z on the VM. You can choose another drive letter if you want.
net use z: \\<mydatadisk>.file.core.windows.net\<<teamsharename>>
Nu hebt u toegang tot dit station, net zoals elk normaal station op de VM.
Code delen in GitHub
GitHub is een codeopslagplaats waar u codevoorbeelden en -bronnen voor verschillende hulpprogramma's kunt vinden met behulp van technologieën die worden gedeeld door de ontwikkelaarscommunity. Het maakt gebruik van Git als de technologie voor het bijhouden en opslaan van versies van de codebestanden. GitHub is ook een platform waar u uw eigen opslagplaats kunt maken om de gedeelde code en documentatie van uw team op te slaan, versiebeheer te implementeren en te bepalen wie toegang heeft om code te bekijken en bij te dragen.
Ga naar de Help-pagina's van GitHub voor meer informatie over het gebruik van Git. U kunt GitHub gebruiken als een van de manieren om samen te werken met uw team, code te gebruiken die is ontwikkeld door de community en code terug te dragen aan de community.
De DSVM wordt geleverd met clienthulpprogramma's op de opdrachtregel en in de GUI voor toegang tot de GitHub-opslagplaats. Het opdrachtregelprogramma dat met Git en GitHub werkt, heet Git Bash. Visual Studio wordt geïnstalleerd op de DSVM en heeft de Git-extensies. U vindt pictogrammen voor deze hulpprogramma's in het Startmenu en op het bureaublad.
Als u code wilt downloaden uit een GitHub-opslagplaats, gebruikt u de git clone opdracht . Als u bijvoorbeeld de data science-opslagplaats wilt downloaden die door Microsoft is gepubliceerd in de huidige map, kunt u de volgende opdracht uitvoeren in Git Bash:
git clone https://github.com/Azure/DataScienceVM.git
In Visual Studio kunt u dezelfde kloonbewerking uitvoeren. In de volgende schermopname ziet u hoe u toegang hebt tot Git- en GitHub-hulpprogramma's in Visual Studio:

Meer informatie over het gebruik van Git om te werken met uw GitHub-opslagplaats vindt u in resources die beschikbaar zijn op github.com. Het cheatsheet is een handige referentie.
Toegang tot Azure-gegevens- en analyseservices
Azure Blob Storage
Azure Blob Storage is een betrouwbare, voordelige cloudopslagservice voor grote en kleine gegevens. In deze sectie wordt beschreven hoe u gegevens naar blobopslag kunt verplaatsen en toegang kunt krijgen tot gegevens die zijn opgeslagen in een Azure-blob.
Vereisten
Maak uw Azure Blob Storage-account op basis van de Azure Portal.
Controleer of het azcopy-opdrachtregelprogramma vooraf is geïnstalleerd:
C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy.exe. De map die azcopy.exe bevat, bevindt zich al in uw PATH-omgevingsvariabele, zodat u kunt voorkomen dat u het volledige opdrachtpad typt wanneer u dit hulpprogramma uitvoert. Zie de AzCopy-documentatie voor meer informatie over het hulpprogramma AzCopy.Start het hulpprogramma Azure Storage Explorer. U kunt het downloaden van de Storage Explorer webpagina.
Gegevens verplaatsen van een VM naar een Azure-blob: AzCopy
Als u gegevens wilt verplaatsen tussen uw lokale bestanden en Blob-opslag, kunt u AzCopy gebruiken op de opdrachtregel of in PowerShell:
AzCopy /Source:C:\myfolder /Dest:https://<mystorageaccount>.blob.core.windows.net/<mycontainer> /DestKey:<storage account key> /Pattern:abc.txt
Vervang C:\myfolder door het pad waar uw bestand is opgeslagen, mystorageaccount door de naam van uw Blob Storage-account, mycontainer door de naam van de container en de opslagaccountsleutel door uw blobopslagtoegangssleutel. U vindt de referenties van uw opslagaccount in de Azure Portal.
Voer de AzCopy-opdracht uit in PowerShell of vanaf een opdrachtprompt. Hier volgt een voorbeeld van het gebruik van de AzCopy-opdracht:
# Copy *.sql from a local machine to an Azure blob
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Source:"c:\Aaqs\Data Science Scripts" /Dest:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /DestKey:[ENTER STORAGE KEY] /S /Pattern:*.sql
# Copy back all files from an Azure blob container to a local machine
"C:\Program Files (x86)\Microsoft SDKs\Azure\AzCopy\azcopy" /Dest:"c:\Aaqs\Data Science Scripts\temp" /Source:https://[ENTER STORAGE ACCOUNT].blob.core.windows.net/[ENTER CONTAINER] /SourceKey:[ENTER STORAGE KEY] /S
Nadat u de AzCopy-opdracht hebt uitgevoerd om naar een Azure-blob te kopiëren, wordt uw bestand weergegeven in Azure Storage Explorer.

Gegevens verplaatsen van een VM naar een Azure-blob: Azure Storage Explorer
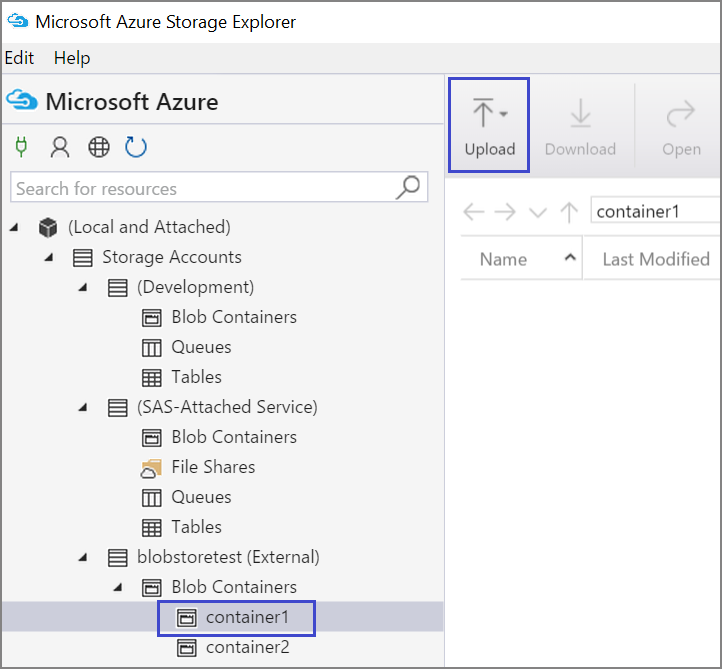
U kunt ook gegevens uit het lokale bestand in uw VM uploaden met behulp van Azure Storage Explorer:
- Als u gegevens wilt uploaden naar een container, selecteert u de doelcontainer en selecteert u de knop Uploaden.
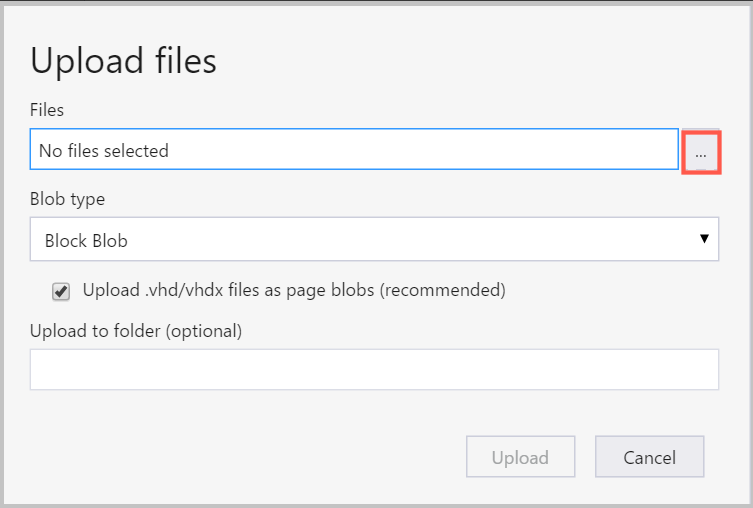
- Selecteer het beletselteken (...) rechts van het vak Bestanden , selecteer een of meer bestanden die u wilt uploaden vanuit het bestandssysteem en selecteer Uploaden om te beginnen met het uploaden van de bestanden.
Gegevens lezen uit een Azure-blob: Python ODBC
U kunt de BlobService-bibliotheek gebruiken om gegevens rechtstreeks uit een blob in een Jupyter Notebook of in een Python-programma te lezen.
Importeer eerst de vereiste pakketten:
import pandas as pd
from pandas import Series, DataFrame
import numpy as np
import matplotlib.pyplot as plt
from time import time
import pyodbc
import os
from azure.storage.blob import BlobService
import tables
import time
import zipfile
import random
Sluit vervolgens de referenties van uw Blob Storage-account aan en lees gegevens uit de blob:
CONTAINERNAME = 'xxx'
STORAGEACCOUNTNAME = 'xxxx'
STORAGEACCOUNTKEY = 'xxxxxxxxxxxxxxxx'
BLOBNAME = 'nyctaxidataset/nyctaxitrip/trip_data_1.csv'
localfilename = 'trip_data_1.csv'
LOCALDIRECTORY = os.getcwd()
LOCALFILE = os.path.join(LOCALDIRECTORY, localfilename)
#download from blob
t1 = time.time()
blob_service = BlobService(account_name=STORAGEACCOUNTNAME,account_key=STORAGEACCOUNTKEY)
blob_service.get_blob_to_path(CONTAINERNAME,BLOBNAME,LOCALFILE)
t2 = time.time()
print(("It takes %s seconds to download "+BLOBNAME) % (t2 - t1))
#unzip downloaded files if needed
#with zipfile.ZipFile(ZIPPEDLOCALFILE, "r") as z:
# z.extractall(LOCALDIRECTORY)
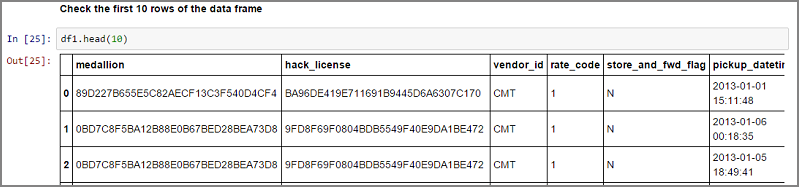
df1 = pd.read_csv(LOCALFILE, header=0)
df1.columns = ['medallion','hack_license','vendor_id','rate_code','store_and_fwd_flag','pickup_datetime','dropoff_datetime','passenger_count','trip_time_in_secs','trip_distance','pickup_longitude','pickup_latitude','dropoff_longitude','dropoff_latitude']
print 'the size of the data is: %d rows and %d columns' % df1.shape
De gegevens worden gelezen als een gegevensframe:
Azure Synapse Analytics en databases
Azure Synapse Analytics is een elastisch datawarehouse als een service met een hoogwaardige SQL Server ervaring.
U kunt Azure Synapse Analytics inrichten door de instructies in dit artikel te volgen. Nadat u Azure Synapse Analytics hebt ingericht, kunt u dit scenario gebruiken om gegevens te uploaden, verkennen en modelleren met behulp van gegevens in Azure Synapse Analytics.
Azure Cosmos DB
Azure Cosmos DB is een NoSQL-database in de cloud. U kunt het gebruiken om te werken met documenten zoals JSON en om de documenten op te slaan en er query's op uit te voeren.
Gebruik de volgende vereiste stappen voor toegang tot Azure Cosmos DB vanuit de DSVM:
De Azure Cosmos DB Python SDK is al geïnstalleerd op de DSVM. Als u deze wilt bijwerken, voert u uit
pip install pydocumentdb --upgradevanaf een opdrachtprompt.Maak een Azure Cosmos DB-account en -database op basis van de Azure Portal.
Download het Azure Cosmos DB-hulpprogramma voor gegevensmigratie vanuit het Microsoft Downloadcentrum en pak het uit naar een map van uw keuze.
Importeer JSON-gegevens (vulkaangegevens) die zijn opgeslagen in een openbare blob in Azure Cosmos DB met de volgende opdrachtparameters naar het migratiehulpprogramma. (Gebruik dtui.exe uit de map waarin u het Hulpprogramma voor gegevensmigratie van Azure Cosmos DB hebt geïnstalleerd.) Voer de bron- en doellocatie in met de volgende parameters:
/s:JsonFile /s.Files:https://data.humdata.org/dataset/a60ac839-920d-435a-bf7d-25855602699d/resource/7234d067-2d74-449a-9c61-22ae6d98d928/download/volcano.json /t:DocumentDBBulk /t.ConnectionString:AccountEndpoint=https://[DocDBAccountName].documents.azure.com:443/;AccountKey=[[KEY];Database=volcano /t.Collection:volcano1
Nadat u de gegevens hebt geïmporteerd, kunt u naar Jupyter gaan en het notitieblok met de naam DocumentDBSample openen. Het bevat Python-code om toegang te krijgen tot Azure Cosmos DB en eenvoudige query's uit te voeren. Ga naar de documentatiepagina van de service voor meer informatie over Azure Cosmos DB.
Power BI-rapporten en -dashboards gebruiken
U kunt het Volcano JSON-bestand uit het voorgaande Azure Cosmos DB-voorbeeld visualiseren in Power BI Desktop om visueel inzicht te krijgen in de gegevens. Gedetailleerde stappen vindt u in het Power BI-artikel. Dit zijn de stappen op hoog niveau:
- Open Power BI Desktop en selecteer Gegevens ophalen. Geef de URL op als:
https://cahandson.blob.core.windows.net/samples/volcano.json. - Als het goed is, ziet u de JSON-records die zijn geïmporteerd als een lijst. Converteer de lijst naar een tabel zodat Power BI ermee kan werken.
- Vouw de kolommen uit door het pictogram uitvouwen (pijl) te selecteren.
- U ziet dat de locatie een recordveld is. Vouw de record uit en selecteer alleen de coördinaten. Coördinaat is een lijstkolom.
- Voeg een nieuwe kolom toe om de kolom met lijstcoördinaat te converteren naar een door komma's gescheiden LatLong-kolom . Voeg de twee elementen in het coördinatenlijstveld samen met behulp van de formule
Text.From([coordinates]{1})&","&Text.From([coordinates]{0}). - Converteer de kolom Hoogte naar een decimaal getal en selecteer de knoppen Sluiten en Toepassen .
In plaats van de voorgaande stappen te gebruiken, kunt u de volgende code plakken. De stappen die worden gebruikt in de Geavanceerde editor in Power BI om de gegevenstransformaties in een querytaal te schrijven, worden in scripts beschreven.
let
Source = Json.Document(Web.Contents("https://cahandson.blob.core.windows.net/samples/volcano.json")),
#"Converted to Table" = Table.FromList(Source, Splitter.SplitByNothing(), null, null, ExtraValues.Error),
#"Expanded Column1" = Table.ExpandRecordColumn(#"Converted to Table", "Column1", {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}, {"Volcano Name", "Country", "Region", "Location", "Elevation", "Type", "Status", "Last Known Eruption", "id"}),
#"Expanded Location" = Table.ExpandRecordColumn(#"Expanded Column1", "Location", {"coordinates"}, {"coordinates"}),
#"Added Custom" = Table.AddColumn(#"Expanded Location", "LatLong", each Text.From([coordinates]{1})&","&Text.From([coordinates]{0})),
#"Changed Type" = Table.TransformColumnTypes(#"Added Custom",{{"Elevation", type number}})
in
#"Changed Type"
U hebt nu de gegevens in uw Power BI-gegevensmodel. Uw Power BI Desktop-exemplaar moet er als volgt uitzien:
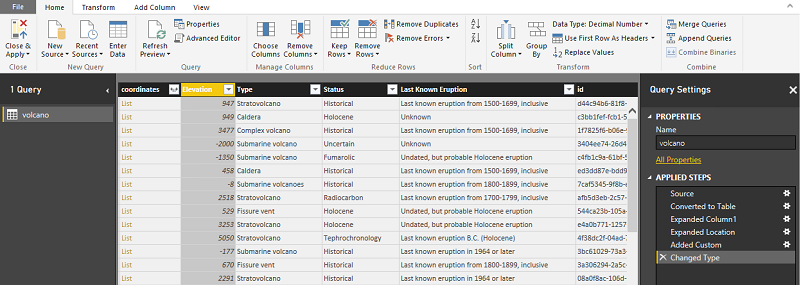
U kunt beginnen met het maken van rapporten en visualisaties met behulp van het gegevensmodel. U kunt de stappen in dit Power BI-artikel volgen om een rapport te maken.
De DSVM dynamisch schalen
U kunt de DSVM omhoog en omlaag schalen om te voldoen aan de behoeften van uw project. Als u de VM niet 's avonds of in het weekend hoeft te gebruiken, kunt u de VM afsluiten vanaf de Azure Portal.
Notitie
Er worden rekenkosten in rekening gebracht als u alleen de afsluitknop voor het besturingssysteem op de VM gebruikt. In plaats daarvan moet u de toewijzing van uw DSVM ongedaan maken met behulp van de Azure Portal of Cloud Shell.
Mogelijk moet u een grootschalige analyse uitvoeren en meer CPU, geheugen of schijfcapaciteit nodig hebben. Als dat het geval is, kunt u een keuze maken uit VM-grootten in termen van CPU-kernen, GPU-exemplaren voor deep learning, geheugencapaciteit en schijftypen (inclusief SSD-schijven) die voldoen aan uw reken- en budgettaire behoeften. De volledige lijst met VM's, samen met de rekenprijzen per uur, is beschikbaar op de pagina Met prijzen voor Azure Virtual Machines.
Meer hulpprogramma's toevoegen
Hulpprogramma's die vooraf zijn ingebouwd in de DSVM, kunnen voldoen aan veel algemene behoeften voor gegevensanalyse. Dit bespaart u tijd omdat u uw omgevingen niet een voor een hoeft te installeren en configureren. Het bespaart u ook geld, omdat u alleen betaalt voor resources die u gebruikt.
U kunt andere Azure-gegevens- en analyseservices gebruiken die in dit artikel zijn geprofileerd om uw analyseomgeving te verbeteren. In sommige gevallen hebt u mogelijk extra hulpprogramma's nodig, waaronder enkele eigen partnerhulpprogramma's. U hebt volledige beheerderstoegang op de virtuele machine om nieuwe hulpprogramma's te installeren die u nodig hebt. U kunt ook extra pakketten in Python en R installeren die niet vooraf zijn geïnstalleerd. Voor Python kunt u of pipgebruikenconda. Voor R kunt u gebruiken install.packages() in de R-console, of de IDE gebruiken en Pakketten>installeren pakketten selecteren.
Deep learning
Naast de voorbeelden op basis van een framework kunt u een reeks uitgebreide scenario's krijgen die zijn gevalideerd op de DSVM. Deze walkthroughs helpen u snel aan de slag te gaan met de ontwikkeling van deep learning-toepassingen in domeinen zoals afbeeldingen en tekst/taalbegrip.
Neurale netwerken uitvoeren in verschillende frameworks: in dit scenario ziet u hoe u code migreert van het ene framework naar het andere. Het laat ook zien hoe u modellen en runtimeprestaties in verschillende frameworks kunt vergelijken.
Een handleiding voor het bouwen van een end-to-end-oplossing voor het detecteren van producten in afbeeldingen: Afbeeldingsdetectie is een techniek waarmee objecten in afbeeldingen kunnen worden gevonden en geclassificeerd. Deze technologie heeft het potentieel om enorme beloningen te brengen in veel zakelijke domeinen in de praktijk. Retailers kunnen deze techniek bijvoorbeeld gebruiken om te bepalen welk product een klant uit het schap heeft opgehaald. Deze informatie helpt winkels weer bij het beheren van de productvoorraad.
Deep learning voor audio: in deze zelfstudie ziet u hoe u een deep learning-model traint voor de detectie van audiogebeurtenissen op de gegevensset met stedelijke geluiden. Het biedt ook een overzicht van hoe u met audiogegevens kunt werken.
Classificatie van tekstdocumenten: In dit scenario ziet u hoe u twee neurale netwerkarchitecturen bouwt en traint: Hierarchical Attention Network en LSTM-netwerk (Long Short Term Memory). Deze neurale netwerken gebruiken de Keras-API voor deep learning om tekstdocumenten te classificeren.
Samenvatting
In dit artikel worden enkele dingen beschreven die u kunt doen op de Microsoft Data Science Virtual Machine. Er zijn nog veel meer dingen die u kunt doen om van de DSVM een effectieve analyseomgeving te maken.