Productiegegevens verzamelen van modellen die zijn geïmplementeerd voor realtime deductie
VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
In dit artikel leert u hoe u Azure Machine Learning-gegevensverzamelaar gebruikt om productiedeductiegegevens te verzamelen van een model dat is geïmplementeerd in een online-eindpunt van Azure Machine Learning of een online-eindpunt van Kubernetes.
U kunt gegevensverzameling inschakelen voor nieuwe of bestaande online-eindpuntimplementaties. Azure Machine Learning-gegevensverzamelaar registreert deductiegegevens in Azure Blob Storage. Gegevens die worden verzameld met de Python SDK, worden automatisch geregistreerd als een gegevensasset in uw Azure Machine Learning-werkruimte. Deze gegevensasset kan worden gebruikt voor modelbewaking.
Als u geïnteresseerd bent in het verzamelen van productiedeductiegegevens voor een MLflow-model dat is geïmplementeerd op een realtime-eindpunt, raadpleegt u Gegevensverzameling voor MLflow-modellen.
Vereisten
Voordat u de stappen in dit artikel volgt, moet u ervoor zorgen dat u over de volgende vereisten beschikt:
De Azure CLI en de
mlextensie voor de Azure CLI. Zie De CLI (v2) installeren, instellen en gebruiken voor meer informatie.Belangrijk
In de CLI-voorbeelden in dit artikel wordt ervan uitgegaan dat u de Bash-shell (of compatibele) shell gebruikt. Bijvoorbeeld vanuit een Linux-systeem of Windows-subsysteem voor Linux.
Een Azure Machine Learning-werkruimte. Als u er nog geen hebt, gebruikt u de stappen in de installatie, het instellen en gebruiken van de CLI (v2) om er een te maken.
- Op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC) wordt gebruikt om toegang te verlenen tot bewerkingen in Azure Machine Learning. Als u de stappen in dit artikel wilt uitvoeren, moet aan uw gebruikersaccount de rol eigenaar of inzender voor de Azure Machine Learning-werkruimte zijn toegewezen, of een aangepaste rol die toestaat
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Zie Toegang tot een Azure Machine Learning-werkruimte beheren voor meer informatie.
Een geregistreerd model hebben dat u kunt gebruiken voor implementatie. Als u geen geregistreerd model hebt, raadpleegt u Uw model registreren als een asset in Machine Learning.
Maak een online-eindpunt voor Azure Machine Learning. Als u geen bestaand online-eindpunt hebt, raadpleegt u Een machine learning-model implementeren en beoordelen met behulp van een online-eindpunt.
Aangepaste logboekregistratie uitvoeren voor modelbewaking
Met gegevensverzameling met aangepaste logboekregistratie kunt u pandas DataFrames rechtstreeks vanuit uw scorescript vastleggen vóór, tijdens en na eventuele gegevenstransformaties. Met aangepaste logboekregistratie worden tabelgegevens in realtime geregistreerd bij uw werkruimte-blobopslag of een aangepaste blobopslagcontainer. Uw modelmonitors kunnen de gegevens uit de opslag gebruiken.
Uw scorescript bijwerken met aangepaste logboekregistratiecode
Voeg om te beginnen aangepaste logboekregistratiecode toe aan uw scorescript (score.py). Voor aangepaste logboekregistratie hebt u het azureml-ai-monitoring pakket nodig. Zie de uitgebreide PyPI-pagina voor de gegevensverzamelaar-SDK voor meer informatie over dit pakket.
Importeer het
azureml-ai-monitoringpakket door de volgende regel toe te voegen aan het begin van het scorescript:from azureml.ai.monitoring import CollectorDeclareer uw gegevensverzamelingsvariabelen (maximaal vijf daarvan) in uw
init()functie:Notitie
Als u de namen
model_inputsenmodel_outputsvoor uwCollectorobjecten gebruikt, herkent het bewakingssysteem van het model automatisch de automatisch geregistreerde gegevensassets om een naadlozere modelbewakingservaring te bieden.global inputs_collector, outputs_collector inputs_collector = Collector(name='model_inputs') outputs_collector = Collector(name='model_outputs')Azure Machine Learning genereert standaard een uitzondering als er een fout optreedt tijdens het verzamelen van gegevens. U kunt eventueel de
on_errorparameter gebruiken om een functie op te geven die moet worden uitgevoerd als er een logboekfout optreedt. Met behulp van deon_errorparameter in de volgende code registreert Azure Machine Learning bijvoorbeeld de fout in plaats van een uitzondering te genereren:inputs_collector = Collector(name='model_inputs', on_error=lambda e: logging.info("ex:{}".format(e)))Gebruik de
collect()functie in uwrun()functie om DataFrames vóór en na het scoren te registreren. Decontextwaarde wordt geretourneerd van de eerste aanroep naarcollect()en bevat informatie om de modelinvoer en modeluitvoer later te correleren.context = inputs_collector.collect(data) result = model.predict(data) outputs_collector.collect(result, context)Notitie
Momenteel registreert de
collect()API alleen pandas DataFrames. Als de gegevens zich niet in een DataFrame bevinden wanneer ze worden doorgegeven aancollect(), worden deze niet geregistreerd bij de opslag en wordt er een fout gerapporteerd.
De volgende code is een voorbeeld van een volledig scorescript (score.py) dat gebruikmaakt van de aangepaste Python SDK voor logboekregistratie.
import pandas as pd
import json
from azureml.ai.monitoring import Collector
def init():
global inputs_collector, outputs_collector, inputs_outputs_collector
# instantiate collectors with appropriate names, make sure align with deployment spec
inputs_collector = Collector(name='model_inputs')
outputs_collector = Collector(name='model_outputs')
def run(data):
# json data: { "data" : { "col1": [1,2,3], "col2": [2,3,4] } }
pdf_data = preprocess(json.loads(data))
# tabular data: { "col1": [1,2,3], "col2": [2,3,4] }
input_df = pd.DataFrame(pdf_data)
# collect inputs data, store correlation_context
context = inputs_collector.collect(input_df)
# perform scoring with pandas Dataframe, return value is also pandas Dataframe
output_df = predict(input_df)
# collect outputs data, pass in correlation_context so inputs and outputs data can be correlated later
outputs_collector.collect(output_df, context)
return output_df.to_dict()
def preprocess(json_data):
# preprocess the payload to ensure it can be converted to pandas DataFrame
return json_data["data"]
def predict(input_df):
# process input and return with outputs
...
return output_df
Uw scorescript bijwerken om aangepaste unieke id's te registreren
Naast het rechtstreeks vastleggen van pandas DataFrames binnen uw scorescript, kunt u gegevens vastleggen met unieke id's van uw keuze. Deze id's kunnen afkomstig zijn van uw toepassing, een extern systeem of u kunt deze genereren. Als u geen aangepaste id opgeeft, zoals beschreven in deze sectie, wordt er automatisch een unieke correlationid gegevensverzamelaar gegenereerd om u te helpen de invoer en uitvoer van uw model later te correleren. Als u een aangepaste id opgeeft, bevat het correlationid veld in de vastgelegde gegevens de waarde van de opgegeven aangepaste id.
Voer eerst de stappen in de vorige sectie uit en importeer het
azureml.ai.monitoring.contextpakket door de volgende regel toe te voegen aan uw scorescript:from azureml.ai.monitoring.context import BasicCorrelationContextMaak in uw scorescript een instantie van een
BasicCorrelationContextobject en geef hetidobject door dat u wilt registreren voor die rij. We raden u aan dat ditideen unieke id van uw systeem is, zodat u elke geregistreerde rij uniek kunt identificeren vanuit uw Blob Storage. Geef dit object door aan uwcollect()API-aanroep als parameter:# create a context with a custom unique id artificial_context = BasicCorrelationContext(id='test') # collect inputs data, store correlation_context context = inputs_collector.collect(input_df, artificial_context)Zorg ervoor dat u de context doorgeeft aan uw
outputs_collectorgegevens, zodat de invoer en uitvoer van uw model dezelfde unieke id hebben die met hen is geregistreerd en ze later eenvoudig kunnen worden gecorreleerd:# collect outputs data, pass in context so inputs and outputs data can be correlated later outputs_collector.collect(output_df, context)
De volgende code is een voorbeeld van een volledig scorescript (score.py) waarmee aangepaste unieke id's worden vastgelegd.
import pandas as pd
import json
from azureml.ai.monitoring import Collector
from azureml.ai.monitoring.context import BasicCorrelationContext
def init():
global inputs_collector, outputs_collector, inputs_outputs_collector
# instantiate collectors with appropriate names, make sure align with deployment spec
inputs_collector = Collector(name='model_inputs')
outputs_collector = Collector(name='model_outputs')
def run(data):
# json data: { "data" : { "col1": [1,2,3], "col2": [2,3,4] } }
pdf_data = preprocess(json.loads(data))
# tabular data: { "col1": [1,2,3], "col2": [2,3,4] }
input_df = pd.DataFrame(pdf_data)
# create a context with a custom unique id
artificial_context = BasicCorrelationContext(id='test')
# collect inputs data, store correlation_context
context = inputs_collector.collect(input_df, artificial_context)
# perform scoring with pandas Dataframe, return value is also pandas Dataframe
output_df = predict(input_df)
# collect outputs data, pass in context so inputs and outputs data can be correlated later
outputs_collector.collect(output_df, context)
return output_df.to_dict()
def preprocess(json_data):
# preprocess the payload to ensure it can be converted to pandas DataFrame
return json_data["data"]
def predict(input_df):
# process input and return with outputs
...
return output_df
Gegevens verzamelen voor modelprestaties bewaken
Als u de verzamelde gegevens wilt gebruiken voor modelprestatiebewaking, is het belangrijk dat elke geregistreerde rij een unieke correlationid rij heeft die kan worden gebruikt om de gegevens te correleren met gegevens over de grondwaar, wanneer dergelijke gegevens beschikbaar komen. De gegevensverzamelaar zal automatisch een unieke genereren correlationid voor elke geregistreerde rij en deze automatisch gegenereerde id opnemen in het correlationid veld in het JSON-object. Zie Verzamelde gegevens opslaan in blobopslag voor meer informatie over het JSON-schema.
Als u uw eigen unieke id wilt gebruiken voor logboekregistratie met uw productiegegevens, raden we u aan deze id als een afzonderlijke kolom in uw Pandas DataFrame te registreren, omdat de gegevensverzamelaar aanvragen die zich dicht bij elkaar bevinden, batches uitvoert. Door de logboekregistratie van de correlationid kolom als een afzonderlijke kolom, is deze direct beschikbaar voor integratie met grondwaargegevens.
Uw afhankelijkheden bijwerken
Voordat u uw implementatie kunt maken met het bijgewerkte scorescript, moet u uw omgeving maken met de basisinstallatiekopieën mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04 en de juiste conda-afhankelijkheden. Daarna kunt u de omgeving bouwen met behulp van de specificatie in de volgende YAML.
channels:
- conda-forge
dependencies:
- python=3.8
- pip=22.3.1
- pip:
- azureml-defaults==1.38.0
- azureml-ai-monitoring~=0.1.0b1
name: model-env
Uw YAML-implementatie bijwerken
Vervolgens maakt u de YAML voor de implementatie. Als u de YAML-implementatie wilt maken, neemt u het kenmerk op en schakelt u het data_collector verzamelen van gegevens in voor de Collector objecten en model_inputsmodel_outputs, die u eerder hebt geïnstantieerd via de Python SDK voor aangepaste logboekregistratie:
data_collector:
collections:
model_inputs:
enabled: 'True'
model_outputs:
enabled: 'True'
De volgende code is een voorbeeld van een uitgebreide YAML-implementatie voor een beheerde online-eindpuntimplementatie. Werk de YAML-implementatie bij volgens uw scenario. Zie Voorbeelden van azure-modelgegevensverzamelaars voor meer voorbeelden over het opmaken van uw YAML voor implementatie voor deductiegegevenslogboeken.
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my_endpoint
model: azureml:iris_mlflow_model@latest
environment:
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: model/conda.yaml
code_configuration:
code: scripts
scoring_script: score.py
instance_type: Standard_F2s_v2
instance_count: 1
data_collector:
collections:
model_inputs:
enabled: 'True'
model_outputs:
enabled: 'True'
Desgewenst kunt u de volgende extra parameters voor uw data_collector:
data_collector.rolling_rate: de snelheid voor het partitioneren van de gegevens in de opslag. Kies uit de waarden:Minute,Hour,Day,MonthofYear.data_collector.sampling_rate: Het percentage dat wordt weergegeven als een decimaal percentage, van de gegevens die moeten worden verzameld. Een waarde van bijvoorbeeld het verzamelen van1.0100% van de gegevens.data_collector.collections.<collection_name>.data.name: De naam van de gegevensasset die moet worden geregistreerd bij de verzamelde gegevens.data_collector.collections.<collection_name>.data.path: het volledige Azure Machine Learning-gegevensarchiefpad waarin de verzamelde gegevens moeten worden geregistreerd als een gegevensasset.data_collector.collections.<collection_name>.data.version: De versie van de gegevensasset die moet worden geregistreerd bij de verzamelde gegevens in blobopslag.
Gegevens verzamelen in een aangepaste blobopslagcontainer
U kunt de gegevensverzamelaar gebruiken om uw productiedeductiegegevens te verzamelen naar een aangepaste blobopslagcontainer door de volgende stappen uit te voeren:
Verbinding maken de opslagcontainer naar een Azure Machine Learning-gegevensarchief. Zie Gegevensarchieven maken voor meer informatie over het verbinden van de opslagcontainer met het Azure Machine Learning-gegevensarchief.
Controleer of uw Azure Machine Learning-eindpunt over de benodigde machtigingen beschikt om naar het doel van het gegevensarchief te schrijven.
De gegevensverzamelaar ondersteunt zowel door het systeem toegewezen beheerde identiteiten (SAMIs's) als door de gebruiker toegewezen beheerde identiteiten (UAMI's). Voeg de identiteit toe aan uw eindpunt. Wijs de
Storage Blob Data Contributorrol toe aan deze identiteit met de Blob Storage-container die moet worden gebruikt als de gegevensbestemming. Zie Azure-rollen toewijzen aan een beheerde identiteit voor meer informatie over het gebruik van beheerde identiteiten in Azure.Werk de YAML-implementatie bij zodat deze de
dataeigenschap in elke verzameling bevat.- De vereiste parameter,
data.namegeeft de naam van de gegevensasset die moet worden geregistreerd bij de verzamelde gegevens. - De vereiste parameter,
data.pathgeeft het volledig gevormde Azure Machine Learning-gegevensarchiefpad op, dat is verbonden met uw Azure Blob Storage-container. - De optionele parameter,
data.versiongeeft de versie van de gegevensasset op (standaard ingesteld op 1).
In de volgende YAML-configuratie ziet u een voorbeeld van het opnemen van de
dataeigenschap binnen elke verzameling.data_collector: collections: model_inputs: enabled: 'True' data: name: my_model_inputs_data_asset path: azureml://datastores/workspaceblobstore/paths/modelDataCollector/my_endpoint/blue/model_inputs version: 1 model_outputs: enabled: 'True' data: name: my_model_outputs_data_asset path: azureml://datastores/workspaceblobstore/paths/modelDataCollector/my_endpoint/blue/model_outputs version: 1Notitie
U kunt de
data.pathparameter ook gebruiken om te verwijzen naar gegevensarchieven in verschillende Azure-abonnementen door een pad op te geven dat de indeling volgt:azureml://subscriptions/<sub_id>/resourcegroups/<rg_name>/workspaces/<ws_name>/datastores/<datastore_name>/paths/<path>- De vereiste parameter,
Uw implementatie maken met gegevensverzameling
Implementeer het model waarvoor aangepaste logboekregistratie is ingeschakeld:
$ az ml online-deployment create -f deployment.YAML
Zie het YAML-schema voor online-implementatie van Azure Arc (v2) met CLI (v2) voor meer informatie over het opmaken van uw YAML-implementatie voor gegevensverzameling met Kubernetes online-eindpunten voor Kubernetes.
Zie HET YAML-schema voor beheerde online-implementatie van CLI (v2) voor meer informatie over het opmaken van uw implementatie-YAML voor het verzamelen van gegevens met beheerde online-eindpunten.
Logboekregistratie van nettolading uitvoeren
Naast aangepaste logboekregistratie met de opgegeven Python SDK kunt u gegevens van http-nettoladingen van aanvragen en antwoorden rechtstreeks verzamelen zonder dat u uw scorescript (score.py) hoeft te verbeteren.
Als u logboekregistratie van nettoladingen wilt inschakelen, gebruikt u in uw YAML-implementatie de namen
requestenresponse:$schema: http://azureml/sdk-2-0/OnlineDeployment.json endpoint_name: my_endpoint name: blue model: azureml:my-model-m1:1 environment: azureml:env-m1:1 data_collector: collections: request: enabled: 'True' response: enabled: 'True'Implementeer het model waarvoor logboekregistratie van nettolading is ingeschakeld:
$ az ml online-deployment create -f deployment.YAML
Bij logboekregistratie van nettoladingen zijn de verzamelde gegevens niet gegarandeerd in tabelvorm. Als u verzamelde nettoladinggegevens wilt gebruiken met modelbewaking, moet u daarom een voorverwerkingsonderdeel opgeven om de gegevens in tabelvorm te maken. Als u geïnteresseerd bent in een naadloze modelbewakingservaring, raden we u aan de Python SDK voor aangepaste logboekregistratie te gebruiken.
Wanneer uw implementatie wordt gebruikt, stromen de verzamelde gegevens naar uw werkruimte-blobopslag. De volgende JSON-code is een voorbeeld van een VERZAMELDE HTTP-aanvraag:
{"specversion":"1.0",
"id":"19790b87-a63c-4295-9a67-febb2d8fbce0",
"source":"/subscriptions/d511f82f-71ba-49a4-8233-d7be8a3650f4/resourceGroups/mire2etesting/providers/Microsoft.MachineLearningServices/workspaces/mirmasterenvws/onlineEndpoints/localdev-endpoint/deployments/localdev",
"type":"azureml.inference.request",
"datacontenttype":"application/json",
"time":"2022-05-25T08:59:48Z",
"data":{"data": [ [1,2,3,4,5,6,7,8,9,10], [10,9,8,7,6,5,4,3,2,1]]},
"path":"/score",
"method":"POST",
"contentrange":"bytes 0-59/*",
"correlationid":"f6e806c9-1a9a-446b-baa2-901373162105","xrequestid":"f6e806c9-1a9a-446b-baa2-901373162105"}
En de volgende JSON-code is een ander voorbeeld van een HTTP-antwoord dat wordt verzameld:
{"specversion":"1.0",
"id":"bbd80e51-8855-455f-a719-970023f41e7d",
"source":"/subscriptions/d511f82f-71ba-49a4-8233-d7be8a3650f4/resourceGroups/mire2etesting/providers/Microsoft.MachineLearningServices/workspaces/mirmasterenvws/onlineEndpoints/localdev-endpoint/deployments/localdev",
"type":"azureml.inference.response",
"datacontenttype":"application/json",
"time":"2022-05-25T08:59:48Z",
"data":[11055.977245525679, 4503.079536107787],
"contentrange":"bytes 0-38/39",
"correlationid":"f6e806c9-1a9a-446b-baa2-901373162105","xrequestid":"f6e806c9-1a9a-446b-baa2-901373162105"}
Verzamelde gegevens opslaan in blobopslag
Met gegevensverzameling kunt u productiedeductiegegevens vastleggen naar een blobopslagbestemming van uw keuze. De instellingen voor de gegevensbestemming kunnen op het collection_name niveau worden geconfigureerd.
Uitvoer/indeling van Blob Storage:
De verzamelde gegevens worden standaard opgeslagen op het volgende pad in uw werkruimte-blobopslag:
azureml://datastores/workspaceblobstore/paths/modelDataCollector.Het laatste pad in de blob wordt toegevoegd aan
{endpoint_name}/{deployment_name}/{collection_name}/{yyyy}/{MM}/{dd}/{HH}/{instance_id}.jsonl.Elke regel in het bestand is een JSON-object dat één deductieaanvraag/-antwoord vertegenwoordigt die is vastgelegd.
Notitie
collection_name verwijst naar de naam van de gegevensverzameling (bijvoorbeeld model_inputs of model_outputs).
instance_id is een unieke id die de groepering van gegevens identificeert die is geregistreerd.
De verzamelde gegevens volgen het volgende JSON-schema. De verzamelde gegevens zijn beschikbaar via de data sleutel en er worden aanvullende metagegevens opgegeven.
{"specversion":"1.0",
"id":"725aa8af-0834-415c-aaf5-c76d0c08f694",
"source":"/subscriptions/636d700c-4412-48fa-84be-452ac03d34a1/resourceGroups/mire2etesting/providers/Microsoft.MachineLearningServices/workspaces/mirmasterws/onlineEndpoints/localdev-endpoint/deployments/localdev",
"type":"azureml.inference.inputs",
"datacontenttype":"application/json",
"time":"2022-12-01T08:51:30Z",
"data":[{"label":"DRUG","pattern":"aspirin"},{"label":"DRUG","pattern":"trazodone"},{"label":"DRUG","pattern":"citalopram"}],
"correlationid":"3711655d-b04c-4aa2-a6c4-6a90cbfcb73f","xrequestid":"3711655d-b04c-4aa2-a6c4-6a90cbfcb73f",
"modelversion":"default",
"collectdatatype":"pandas.core.frame.DataFrame",
"agent":"monitoring-sdk/0.1.2",
"contentrange":"bytes 0-116/117"}
Tip
Regeleinden worden alleen weergegeven voor leesbaarheid. In de verzamelde JSONL-bestanden zijn er geen regeleinden.
Grote nettoladingen opslaan
Als de nettolading van uw gegevens groter is dan 4 MB, is er een gebeurtenis in het {instance_id}.jsonl bestand in het {endpoint_name}/{deployment_name}/request/.../{instance_id}.jsonl pad dat verwijst naar een onbewerkt bestandspad, dat het volgende pad moet hebben: blob_url/{blob_container}/{blob_path}/{endpoint_name}/{deployment_name}/{rolled_time}/{instance_id}.jsonl De verzamelde gegevens bestaan op dit pad.
Binaire gegevens opslaan
Met verzamelde binaire gegevens tonen we het onbewerkte bestand rechtstreeks, met instance_id als bestandsnaam. Binaire gegevens worden in dezelfde map geplaatst als het pad van de aanvraagbrongroep, op basis van de rolling_rate. In het volgende voorbeeld wordt het pad in het gegevensveld weergegeven. De indeling is json en regeleinden worden alleen weergegeven voor leesbaarheid:
{
"specversion":"1.0",
"id":"ba993308-f630-4fe2-833f-481b2e4d169a",
"source":"/subscriptions//resourceGroups//providers/Microsoft.MachineLearningServices/workspaces/ws/onlineEndpoints/ep/deployments/dp",
"type":"azureml.inference.request",
"datacontenttype":"text/plain",
"time":"2022-02-28T08:41:07Z",
"data":"https://masterws0373607518.blob.core.windows.net/modeldata/mdc/%5Byear%5D%5Bmonth%5D%5Bday%5D-%5Bhour%5D_%5Bminute%5D/ba993308-f630-4fe2-833f-481b2e4d169a",
"path":"/score?size=1",
"method":"POST",
"contentrange":"bytes 0-80770/80771",
"datainblob":"true"
}
Batchverwerking van gegevensverzamelaar
Als aanvragen binnen korte tijdsintervallen van elkaar worden verzonden, worden deze door de gegevensverzamelaar samengevoegd in hetzelfde JSON-object. Als u bijvoorbeeld een script uitvoert om voorbeeldgegevens naar uw eindpunt te verzenden en de implementatie gegevensverzameling heeft ingeschakeld, kunnen sommige aanvragen worden samengevoegd, afhankelijk van het tijdsinterval tussen de aanvragen. Als u gegevensverzameling gebruikt met Azure Machine Learning-modelbewaking, verwerkt de modelbewakingsservice elke aanvraag onafhankelijk. Als u echter verwacht dat elke geregistreerde rij met gegevens een eigen unieke correlationidrij heeft, kunt u de correlationid kolom opnemen als een kolom in het Pandas DataFrame dat u bij de gegevensverzamelaar aanmeldt. Zie Gegevens verzamelen voor modelprestaties voor meer informatie over hoe u uw unieke correlationid als kolom in het Pandas DataFrame kunt opnemen.
Hier volgt een voorbeeld van twee geregistreerde aanvragen die samen worden gebatcheerd:
{"specversion":"1.0",
"id":"720b8867-54a2-4876-80eb-1fd6a8975770",
"source":"/subscriptions/79a1ba0c-35bb-436b-bff2-3074d5ff1f89/resourceGroups/rg-bozhlinmomoignite/providers/Microsoft.MachineLearningServices/workspaces/momo-demo-ws/onlineEndpoints/credit-default-mdc-testing-4/deployments/main2",
"type":"azureml.inference.model_inputs",
"datacontenttype":"application/json",
"time":"2024-03-05T18:16:25Z",
"data":[{"LIMIT_BAL":502970,"AGE":54,"BILL_AMT1":308068,"BILL_AMT2":381402,"BILL_AMT3":442625,"BILL_AMT4":320399,"BILL_AMT5":322616,"BILL_AMT6":397534,"PAY_AMT1":17987,"PAY_AMT2":78764,"PAY_AMT3":26067,"PAY_AMT4":24102,"PAY_AMT5":-1155,"PAY_AMT6":2154,"SEX":2,"EDUCATION":2,"MARRIAGE":2,"PAY_0":0,"PAY_2":0,"PAY_3":0,"PAY_4":0,"PAY_5":0,"PAY_6":0},{"LIMIT_BAL":293458,"AGE":35,"BILL_AMT1":74131,"BILL_AMT2":-71014,"BILL_AMT3":59284,"BILL_AMT4":98926,"BILL_AMT5":110,"BILL_AMT6":1033,"PAY_AMT1":-3926,"PAY_AMT2":-12729,"PAY_AMT3":17405,"PAY_AMT4":25110,"PAY_AMT5":7051,"PAY_AMT6":1623,"SEX":1,"EDUCATION":3,"MARRIAGE":2,"PAY_0":-2,"PAY_2":-2,"PAY_3":-2,"PAY_4":-2,"PAY_5":-1,"PAY_6":-1}],
"contentrange":"bytes 0-6794/6795",
"correlationid":"test",
"xrequestid":"test",
"modelversion":"default",
"collectdatatype":"pandas.core.frame.DataFrame",
"agent":"azureml-ai-monitoring/0.1.0b4"}
De gegevens weergeven in de gebruikersinterface van Studio
De verzamelde gegevens in Blob Storage weergeven vanuit de gebruikersinterface van studio:
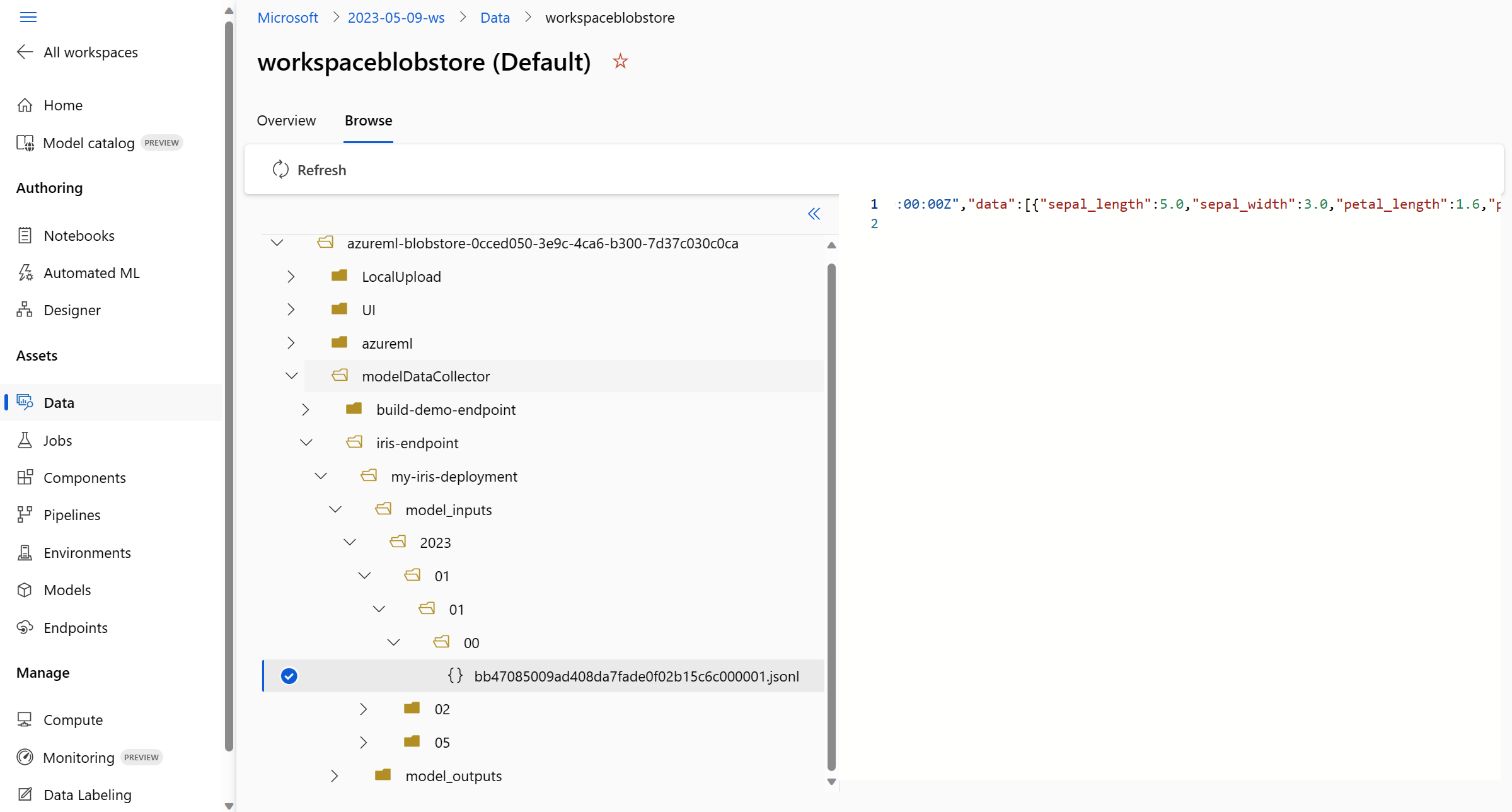
Ga naar het tabblad Gegevens in uw Azure Machine Learning-werkruimte:

Navigeer naar Gegevensarchieven en selecteer uw workspaceblobstore (standaard):a1>

Gebruik het menu Bladeren om de verzamelde productiegegevens weer te geven:



Gegevens verzamelen voor MLflow-modellen
Als u een MLflow-model implementeert in een online-eindpunt van Azure Machine Learning, kunt u het verzamelen van productiedeductiegegevens inschakelen met één wisselknop in de gebruikersinterface van studio. Als het verzamelen van gegevens is ingeschakeld, wordt in Azure Machine Learning automatisch uw scorescript met aangepaste logboekregistratiecode gebruikt om ervoor te zorgen dat de productiegegevens worden vastgelegd in uw werkruimte-blobopslag. Uw modelmonitoren kunnen vervolgens de gegevens gebruiken om de prestaties van uw MLflow-model in productie te bewaken.
Tijdens het configureren van de implementatie van uw model kunt u het verzamelen van productiegegevens inschakelen. Selecteer Ingeschakeld voor gegevensverzameling op het tabblad Implementatie.
Nadat u het verzamelen van gegevens hebt ingeschakeld, worden productiedeductiegegevens vastgelegd in de Blob Storage van uw Azure Machine Learning-werkruimte en worden er twee gegevensassets gemaakt met namen <endpoint_name>-<deployment_name>-model_inputs en <endpoint_name>-<deployment_name>-model_outputs. Deze gegevensassets worden in realtime bijgewerkt wanneer u uw implementatie in productie gebruikt. Uw modelmonitoren kunnen vervolgens de gegevensassets gebruiken om de prestaties van uw model in productie te bewaken.