Een ontwikkelomgeving instellen met Azure Databricks en AutoML in Azure Machine Learning
Meer informatie over het configureren van een ontwikkelomgeving in Azure Machine Learning die gebruikmaakt van Azure Databricks en geautomatiseerde ML.
Azure Databricks is ideaal voor het uitvoeren van grootschalige intensieve machine learning-werkstromen op het schaalbare Apache Spark-platform in de Azure-cloud. Het biedt een op notebook gebaseerde omgeving met een op CPU of GPU gebaseerd rekencluster.
Zie Python-ontwikkelomgeving instellen voor informatie over andere machine learning-ontwikkelomgevingen.
Vereiste
Azure Machine Learning-werkruimte. Als u een werkruimte wilt maken, gebruikt u de stappen in het artikel Werkruimteresources maken .
Azure Databricks met Azure Machine Learning en AutoML
Azure Databricks is geïntegreerd met Azure Machine Learning en de Bijbehorende AutoML-mogelijkheden.
U kunt Azure Databricks gebruiken:
- Een model trainen met Behulp van Spark MLlib en het model implementeren in ACI/AKS.
- Met geautomatiseerde machine learning-mogelijkheden met behulp van een Azure Machine Learning SDK.
- Als rekendoel van een Azure Machine Learning-pijplijn.
Een Databricks-cluster instellen
Maak een Databricks-cluster. Sommige instellingen zijn alleen van toepassing als u de SDK voor geautomatiseerde machine learning op Databricks installeert.
Het duurt enkele minuten om het cluster te maken.
Gebruik deze instellingen:
| Instelling | Van toepassing op | Waarde |
|---|---|---|
| Clusternaam | altijd | yourclustername |
| Databricks Runtime-versie | altijd | 9.1 LTS |
| Python-versie | altijd | 3 |
| Werkroltype (bepaalt het maximumaantal gelijktijdige iteraties) |
Geautomatiseerde machine learning Alleen |
Voorkeur voor geoptimaliseerde VM's met geheugen |
| Werknemers | altijd | 2 of hoger |
| Automatisch schalen inschakelen | Geautomatiseerde machine learning Alleen |
Uitschakelen |
Wacht totdat het cluster wordt uitgevoerd voordat u verdergaat.
De Azure Machine Learning SDK toevoegen aan Databricks
Zodra het cluster wordt uitgevoerd, maakt u een bibliotheek om het juiste Azure Machine Learning SDK-pakket aan uw cluster te koppelen.
Als u geautomatiseerde ML wilt gebruiken, gaat u naar De Azure Machine Learning SDK toevoegen met AutoML.
Klik met de rechtermuisknop op de huidige werkruimtemap waarin u de bibliotheek wilt opslaan. Selecteer Bibliotheek maken>.
Tip
Als u een oude SDK-versie hebt, schakelt u deze uit de geïnstalleerde clusterbibliotheken en gaat u naar de prullenbak. Installeer de nieuwe SDK-versie en start het cluster opnieuw op. Als er een probleem is na het opnieuw opstarten, koppelt u het cluster los en koppelt u het opnieuw.
Kies de volgende optie (er worden geen andere SDK-installaties ondersteund)
Extra's voor SDK-pakketten Bron PyPi-naam Voor Databricks Python Egg of PyPI uploaden azureml-sdk[databricks] Waarschuwing
Er kunnen geen andere SDK-extra's worden geïnstalleerd. Kies alleen de optie [
databricks].- Selecteer niet Automatisch koppelen aan alle clusters.
- Selecteer Koppelen naast de naam van uw cluster.
Controleer op fouten totdat de status wordt gewijzigd in Gekoppeld. Dit kan enkele minuten duren. Als deze stap mislukt:
Probeer het cluster opnieuw op te starten door:
- Selecteer Clusters in het linkerdeelvenster.
- Selecteer in de tabel de naam van uw cluster.
- Selecteer op het tabblad Bibliotheken de optie Opnieuw opstarten.
Een geslaagde installatie ziet er als volgt uit:
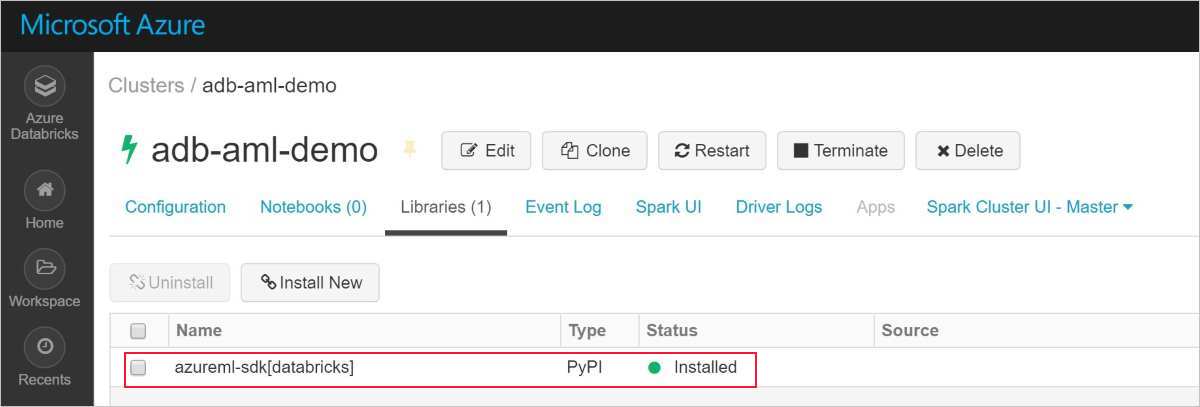
De Azure Machine Learning SDK met AutoML toevoegen aan Databricks
Als het cluster is gemaakt met Databricks Runtime 7.3 LTS (niet ML), voert u de volgende opdracht uit in de eerste cel van uw notebook om de Azure Machine Learning SDK te installeren.
%pip install --upgrade --force-reinstall -r https://aka.ms/automl_linux_requirements.txt
AutoML-configuratie-instellingen
Voeg bij het gebruik van Azure Databricks in de AutoML-configuratie de volgende parameters toe:
max_concurrent_iterationsis gebaseerd op het aantal werkknooppunten in uw cluster.spark_context=scis gebaseerd op de standaard spark-context.
ML-notebooks die werken met Azure Databricks
Probeer het eens:
Hoewel er veel voorbeeldnotebooks beschikbaar zijn, werken alleen deze voorbeeldnotebooks met Azure Databricks.
Importeer deze voorbeelden rechtstreeks vanuit uw werkruimte. Zie hieronder:
Meer informatie over het maken van een pijplijn met Databricks als trainingsberekening.
Problemen oplossen
Databricks annuleert een geautomatiseerde machine learning-uitvoering: als u geautomatiseerde machine learning-mogelijkheden in Azure Databricks gebruikt, moet u uw Azure Databricks-cluster opnieuw starten om een uitvoering te annuleren en een nieuw experiment te starten.
Databricks >10-iteraties voor geautomatiseerde machine learning: als u meer dan tien iteraties hebt in de instellingen voor geautomatiseerde machine learning, stelt u in
show_outputFalseop wanneer u de uitvoering verzendt.Databricks-widget voor de Azure Machine Learning SDK en geautomatiseerde machine learning: de Azure Machine Learning SDK-widget wordt niet ondersteund in een Databricks-notebook omdat de notebooks geen HTML-widgets kunnen parseren. U kunt de widget in de portal weergeven met behulp van deze Python-code in uw Azure Databricks-notebookcel:
displayHTML("<a href={} target='_blank'>Azure Portal: {}</a>".format(local_run.get_portal_url(), local_run.id))Fout bij het installeren van pakketten
Azure Machine Learning SDK-installatie mislukt in Azure Databricks wanneer er meer pakketten worden geïnstalleerd. Sommige pakketten, zoals
psutil, kunnen conflicten veroorzaken. Om installatiefouten te voorkomen, installeert u pakketten door de bibliotheekversie te blokkeren. Dit probleem heeft te maken met Databricks en niet met de Azure Machine Learning SDK. Mogelijk ondervindt u dit probleem ook bij andere bibliotheken. Voorbeeld:psutil cryptography==1.5 pyopenssl==16.0.0 ipython==2.2.0U kunt ook init-scripts gebruiken als u steeds installatieproblemen ondervindt met Python-bibliotheken. Deze aanpak wordt niet officieel ondersteund. Zie Init-scripts met clusterbereik voor meer informatie.
Importfout: kan de naam
Timedeltaniet importeren uitpandas._libs.tslibs: als u deze fout ziet wanneer u geautomatiseerde machine learning gebruikt, voert u de volgende twee regels uit in uw notebook:%sh rm -rf /databricks/python/lib/python3.7/site-packages/pandas-0.23.4.dist-info /databricks/python/lib/python3.7/site-packages/pandas %sh /databricks/python/bin/pip install pandas==0.23.4Importfout: er is geen module met de naam pandas.core.indexes: als u deze fout ziet wanneer u geautomatiseerde machine learning gebruikt:
Voer deze opdracht uit om twee pakketten te installeren in uw Azure Databricks-cluster:
scikit-learn==0.19.1 pandas==0.22.0Koppel het cluster los en koppel het vervolgens opnieuw aan uw notebook.
Als het probleem niet wordt opgelost met deze stappen, start u het cluster opnieuw op.
FailToSendFeather: Als u een
FailToSendFeatherfout ziet bij het lezen van gegevens in een Azure Databricks-cluster, raadpleegt u de volgende oplossingen:- Upgrade
azureml-sdk[automl]pakket naar de nieuwste versie. - Voeg
azureml-dataprepversie 1.1.8 of hoger toe. - Voeg
pyarrowversie 0.11 of hoger toe.
- Upgrade
Volgende stappen
- Een model trainen en implementeren in Azure Machine Learning met de MNIST-gegevensset.
- Zie de naslaginformatie over de Azure Machine Learning SDK voor Python.