Een aangepaste container gebruiken om een model te implementeren op een online-eindpunt
VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Meer informatie over het gebruik van een aangepaste container voor het implementeren van een model naar een online-eindpunt in Azure Machine Learning.
Aangepaste containerimplementaties kunnen andere webservers gebruiken dan de standaard Python Flask-server die wordt gebruikt door Azure Machine Learning. Gebruikers van deze implementaties kunnen nog steeds profiteren van de ingebouwde bewaking, schaalaanpassing, waarschuwingen en verificatie van Azure Machine Learning.
De volgende tabel bevat verschillende implementatievoorbeelden die gebruikmaken van aangepaste containers zoals TensorFlow Serving, TorchServe, Triton Inference Server, Plumber R package en Azure Machine Learning Inference Minimal image.
| Opmerking | Script (CLI) | Beschrijving |
|---|---|---|
| minimaal/multimodel | deploy-custom-container-minimal-multimodel | Implementeer meerdere modellen in één implementatie door de minimale installatiekopie van Azure Machine Learning Uit te breiden. |
| minimaal/enkel model | deploy-custom-container-minimal-single-model | Implementeer één model door de minimale installatiekopie van Azure Machine Learning-deductie uit te breiden. |
| mlflow/multideployment-scikit | deploy-custom-container-mlflow-multideployment-scikit | Implementeer twee MLFlow-modellen met verschillende Python-vereisten voor twee afzonderlijke implementaties achter één eindpunt met behulp van de minimale installatiekopie van Azure Machine Learning. |
| r/multimodel-loodgieter | deploy-custom-container-r-multimodel-plumber | Drie regressiemodellen implementeren op één eindpunt met behulp van het Plumber R-pakket |
| tfserving/half-plus-two | deploy-custom-container-tfserving-half-plus-two | Implementeer een Half Plus Two-model met behulp van een aangepaste TensorFlow Serving-container met behulp van het standaardmodelregistratieproces. |
| tfserving/half-plus-two-integrated | deploy-custom-container-tfserving-half-plus-two-integrated | Implementeer een Half Plus Two-model met behulp van een aangepaste TensorFlow Serving-container met het model dat is geïntegreerd in de installatiekopieën. |
| torchserve/densenet | deploy-custom-container-torchserve-densenet | Implementeer één model met behulp van een aangepaste TorchServe-container. |
| torchserve/huggingface-textgen | deploy-custom-container-torchserve-huggingface-textgen | Implementeer Hugging Face-modellen naar een online-eindpunt en volg samen met het voorbeeld van Hugging Face Transformers TorchServe. |
| triton/single-model | deploy-custom-container-triton-single-model | Een Triton-model implementeren met behulp van een aangepaste container |
Dit artikel is gericht op het bedienen van een TensorFlow-model met TensorFlow (TF) Serving.
Waarschuwing
Microsoft kan mogelijk niet helpen bij het oplossen van problemen die worden veroorzaakt door een aangepaste installatiekopieën. Als u problemen ondervindt, wordt u mogelijk gevraagd om de standaardafbeelding te gebruiken of een van de afbeeldingen die Microsoft biedt om te zien of het probleem specifiek is voor uw afbeelding.
Vereisten
Voordat u de stappen in dit artikel volgt, moet u ervoor zorgen dat u over de volgende vereisten beschikt:
Een Azure Machine Learning-werkruimte. Als u er nog geen hebt, gebruikt u de stappen in de quickstart: artikel Werkruimtebronnen maken om er een te maken.
De Azure CLI en de
mlextensie of de Azure Machine Learning Python SDK v2:Zie De CLI (v2) installeren, instellen en gebruiken om de Azure CLI en extensie te installeren.
Belangrijk
In de CLI-voorbeelden in dit artikel wordt ervan uitgegaan dat u de Bash-shell (of compatibele) shell gebruikt. Bijvoorbeeld vanuit een Linux-systeem of Windows-subsysteem voor Linux.
Gebruik de volgende opdracht om de Python SDK v2 te installeren:
pip install azure-ai-ml azure-identityGebruik de volgende opdracht om een bestaande installatie van de SDK bij te werken naar de nieuwste versie:
pip install --upgrade azure-ai-ml azure-identityZie De Python SDK v2 voor Azure Machine Learning installeren voor meer informatie.
U of de service-principal die u gebruikt, moet inzendertoegang hebben tot de Azure-resourcegroep die uw werkruimte bevat. U hebt een dergelijke resourcegroep als u uw werkruimte hebt geconfigureerd met behulp van het quickstart-artikel.
Als u lokaal wilt implementeren, moet de Docker-engine lokaal worden uitgevoerd. Deze stap wordt ten zeerste aanbevolen. Dit helpt u bij het opsporen van problemen.
Broncode downloaden
Als u deze zelfstudie wilt volgen, kloont u de broncode van GitHub.
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
Omgevingsvariabelen initialiseren
Omgevingsvariabelen definiëren:
BASE_PATH=endpoints/online/custom-container/tfserving/half-plus-two
AML_MODEL_NAME=tfserving-mounted
MODEL_NAME=half_plus_two
MODEL_BASE_PATH=/var/azureml-app/azureml-models/$AML_MODEL_NAME/1
Een TensorFlow-model downloaden
Download en pak een model uit dat een invoer door twee deelt en voegt 2 toe aan het resultaat:
wget https://aka.ms/half_plus_two-model -O $BASE_PATH/half_plus_two.tar.gz
tar -xvf $BASE_PATH/half_plus_two.tar.gz -C $BASE_PATH
Een TF Serving-installatiekopieën lokaal uitvoeren om te testen of deze werkt
Gebruik docker om uw installatiekopieën lokaal uit te voeren om te testen:
docker run --rm -d -v $PWD/$BASE_PATH:$MODEL_BASE_PATH -p 8501:8501 \
-e MODEL_BASE_PATH=$MODEL_BASE_PATH -e MODEL_NAME=$MODEL_NAME \
--name="tfserving-test" docker.io/tensorflow/serving:latest
sleep 10
Controleer of u liveness- en scoreaanvragen naar de afbeelding kunt verzenden
Controleer eerst of de container actief is, wat betekent dat het proces in de container nog steeds wordt uitgevoerd. U krijgt een 200 (OK)-antwoord.
curl -v http://localhost:8501/v1/models/$MODEL_NAME
Controleer vervolgens of u voorspellingen kunt krijgen over niet-gelabelde gegevens:
curl --header "Content-Type: application/json" \
--request POST \
--data @$BASE_PATH/sample_request.json \
http://localhost:8501/v1/models/$MODEL_NAME:predict
De afbeelding stoppen
Nu u lokaal hebt getest, stopt u de installatiekopieën:
docker stop tfserving-test
Uw online-eindpunt implementeren in Azure
Implementeer vervolgens uw online-eindpunt in Azure.
Een YAML-bestand maken voor uw eindpunt en implementatie
U kunt uw cloudimplementatie configureren met BEHULP van YAML. Bekijk de YAML-voorbeeld voor dit voorbeeld:
tfserving-endpoint.yml
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: tfserving-endpoint
auth_mode: aml_token
tfserving-deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: {{MODEL_VERSION}}
path: ./half_plus_two
environment_variables:
MODEL_BASE_PATH: /var/azureml-app/azureml-models/tfserving-mounted/{{MODEL_VERSION}}
MODEL_NAME: half_plus_two
environment:
#name: tfserving
#version: 1
image: docker.io/tensorflow/serving:latest
inference_config:
liveness_route:
port: 8501
path: /v1/models/half_plus_two
readiness_route:
port: 8501
path: /v1/models/half_plus_two
scoring_route:
port: 8501
path: /v1/models/half_plus_two:predict
instance_type: Standard_DS3_v2
instance_count: 1
Er zijn enkele belangrijke concepten die u kunt zien in deze YAML-/Python-parameter:
Gereedheidsroute versus livenessroute
Een HTTP-server definieert paden voor zowel liveness als gereedheid. Er wordt een livenessroute gebruikt om te controleren of de server wordt uitgevoerd. Er wordt een gereedheidsroute gebruikt om te controleren of de server gereed is voor werk. In machine learning-deductie kan een server 200 OK reageren op een liveness-aanvraag voordat een model wordt geladen. De server kan 200 OK reageren op een gereedheidsaanvraag pas nadat het model in het geheugen is geladen.
Zie de Kubernetes-documentatie voor meer informatie over liveness- en gereedheidstests.
U ziet dat deze implementatie hetzelfde pad gebruikt voor zowel liveness als gereedheid, omdat TF-server alleen een livenessroute definieert.
Het gekoppelde model zoeken
Wanneer u een model implementeert als een online-eindpunt, koppelt Azure Machine Learning uw model aan uw eindpunt. Met model koppelen kunt u nieuwe versies van het model implementeren zonder dat u een nieuwe Docker-installatiekopieën hoeft te maken. Standaard bevindt een model dat is geregistreerd met de naam foo en versie 1 zich op het volgende pad in uw geïmplementeerde container: /var/azureml-app/azureml-models/foo/1
Als u bijvoorbeeld een mapstructuur hebt van /azureml-examples/cli/endpoints/online/custom-container op uw lokale computer, waarbij het model de naam half_plus_two heeft:

En tfserving-deployment.yml bevat:
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
Vervolgens bevindt uw model zich onder /var/azureml-app/azureml-models/tfserving-deployment/1 in uw implementatie:

U kunt desgewenst uw model_mount_path. Hiermee kunt u het pad wijzigen waar het model is gekoppeld.
Belangrijk
Het model_mount_path moet een geldig absoluut pad in Linux zijn (het besturingssysteem van de containerinstallatiekopieën).
U kunt bijvoorbeeld de parameter in uw tfserving-deployment.yml hebbenmodel_mount_path:
name: tfserving-deployment
endpoint_name: tfserving-endpoint
model:
name: tfserving-mounted
version: 1
path: ./half_plus_two
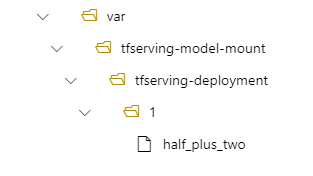
model_mount_path: /var/tfserving-model-mount
.....
Vervolgens bevindt uw model zich in /var/tfserving-model-mount/tfserving-deployment/1 in uw implementatie. Houd er rekening mee dat het niet meer onder azureml-app/azureml-models valt, maar onder het koppelpad dat u hebt opgegeven:
Uw eindpunt en implementatie maken
Nu u begrijpt hoe de YAML is samengesteld, maakt u uw eindpunt.
az ml online-endpoint create --name tfserving-endpoint -f endpoints/online/custom-container/tfserving-endpoint.yml
Het maken van een implementatie kan enkele minuten duren.
az ml online-deployment create --name tfserving-deployment -f endpoints/online/custom-container/tfserving-deployment.yml --all-traffic
Het eindpunt aanroepen
Zodra de implementatie is voltooid, controleert u of u een scoreaanvraag kunt indienen bij het geïmplementeerde eindpunt.
RESPONSE=$(az ml online-endpoint invoke -n $ENDPOINT_NAME --request-file $BASE_PATH/sample_request.json)
Het eindpunt verwijderen
Nu u uw eindpunt hebt beoordeeld, kunt u het volgende verwijderen:
az ml online-endpoint delete --name tfserving-endpoint