Gegevens transformeren in Azure Machine Learning Designer
In dit artikel leert u hoe u gegevenssets kunt transformeren en opslaan in de Azure Machine Learning-ontwerpfunctie om uw eigen gegevens voor te bereiden op machine learning.
U gebruikt de binaire classificatiegegevensset voor volwassen volkstelling voor volwassenen om twee gegevenssets voor te bereiden: één gegevensset met gegevens over volwassen volkstelling van alleen de Verenigde Staten en een andere gegevensset met volkstellingsgegevens van niet-Amerikaanse volwassenen.
In dit artikel leert u het volgende:
- Een gegevensset transformeren om deze voor te bereiden op training.
- Exporteer de resulterende gegevenssets naar een gegevensarchief.
- Bekijk de resultaten.
Deze procedure is een vereiste voor het artikel over het opnieuw trainen van ontwerpmodellen . In dit artikel leert u hoe u de getransformeerde gegevenssets gebruikt om meerdere modellen te trainen, met pijplijnparameters.
Belangrijk
Als u geen grafische elementen ziet die in dit document worden vermeld, zoals knoppen in studio of ontwerper, hebt u mogelijk niet het juiste machtigingsniveau voor de werkruimte. Neem contact op met de beheerder van uw Azure-abonnement om te controleren of u het juiste toegangsniveau hebt gekregen. Ga naar Gebruikers en rollen beheren voor meer informatie.
Een gegevensset transformeren
In deze sectie leert u hoe u de voorbeeldgegevensset importeert en de gegevens splitst in amerikaanse en niet-AMERIKAANSE gegevenssets. Ga naar het importeren van gegevens voor meer informatie over het importeren van uw eigen gegevens in de ontwerpfunctie.
Gegevens importeren
Gebruik deze stappen om de voorbeeldgegevensset te importeren:
Meld u aan bij Azure Machine Learning-studio en selecteer de werkruimte die u wilt gebruiken
Ga naar de ontwerper. Selecteer Een nieuwe pijplijn maken met klassieke vooraf gemaakte onderdelen om een nieuwe pijplijn te maken
Vouw links van het pijplijncanvas op het tabblad Onderdeel het knooppunt Voorbeeldgegevens uit
Sleep de binaire classificatiegegevensset voor volwassen volkstelling en zet deze neer op het canvas
Selecteer met de rechtermuisknop het onderdeel Gegevensset voor volkstelling voor volwassenen en selecteer Voorbeeldgegevens
Gebruik het voorbeeldvenster voor gegevens om de gegevensset te verkennen. Noteer de kolomwaarden 'systeemeigen land'.
De gegevens splitsen
In deze sectie gebruikt u het onderdeel Split Data om rijen te identificeren en te splitsen die 'Verenigde Staten' bevatten in de kolom Systeemeigen land
Vouw links van het canvas op het onderdeeltabblad de sectie Gegevenstransformatie uit en zoek het onderdeel Split Data
Sleep het onderdeel Split Data naar het canvas en zet dat onderdeel onder het gegevenssetonderdeel
Verbinding maken het gegevenssetonderdeel naar de Split Data component
Selecteer het onderdeel Split Data om het deelvenster Split Data te openen
Rechts van het canvas in het pictogram Parameters stelt u de splitsmodus in op Reguliere expressie
Voer de reguliere expressie in:
\"native-country" United-StatesDe modus Reguliere expressie test één kolom voor een waarde. Ga naar de referentiepagina van het gerelateerde algoritmeonderdeel voor meer informatie over het onderdeel Split Data
Uw pijplijn moet er ongeveer als volgt uitzien:

De gegevenssets opslaan
Nu u uw pijplijn hebt ingesteld om de gegevens te splitsen, moet u opgeven waar de gegevenssets moeten worden bewaard. In dit voorbeeld gebruikt u het onderdeel Gegevens exporteren om uw gegevensset op te slaan in een gegevensarchief. Ga naar Verbinding maken naar Azure Storage-services voor meer informatie over gegevensarchieven.
Vouw links van het canvas in het onderdeelpalet de sectie Gegevensinvoer en Uitvoer uit en zoek het onderdeel Gegevens exporteren
Sleep en zet twee exportgegevensonderdelen onder het onderdeel Split Data
Verbinding maken elke uitvoerpoort van de Het onderdeel Gegevens splitsen naar een ander onderdeel Gegevens exporteren
Uw pijplijn moet er als volgt uitzien:

Selecteer het onderdeel Gegevens exporteren dat is verbonden met de meest linkse poort van het onderdeel Split Data om het deelvenster Gegevens exporteren te openen
Voor het onderdeel Split Data is de uitvoerpoortvolgorde belangrijk. De eerste uitvoerpoort bevat de rijen waarin de reguliere expressie waar is. In dit geval bevat de eerste poort rijen voor inkomsten op basis van de VS en de tweede poort rijen voor niet-Amerikaanse inkomsten
Stel in het detailvenster van het onderdeel rechts van het canvas de volgende opties in:
Gegevensarchieftype: Azure Blob Storage
Gegevensarchief: Selecteer een bestaand gegevensarchief of selecteer 'Nieuw gegevensarchief' om een nieuw gegevensarchief te maken
Pad:
/data/us-incomeBestandsindeling: CSV
Notitie
In dit artikel wordt ervan uitgegaan dat u toegang hebt tot een gegevensarchief dat is geregistreerd bij de huidige Azure Machine Learning-werkruimte. Ga naar Verbinding maken naar Azure Storage-services voor installatie-instructies voor gegevensopslag
U kunt een gegevensarchief maken als u er nog geen hebt. In dit artikel worden de gegevenssets bijvoorbeeld opgeslagen in het standaard-blobopslagaccount dat is gekoppeld aan de werkruimte. De gegevenssets worden opgeslagen in de
azuremlcontainer, in een nieuwe map met de naamdataSelecteer het onderdeel Gegevens exporteren dat is verbonden met de meest rechtse poort van het onderdeel Split Data om het deelvenster Gegevens exporteren te openen
Stel rechts van het canvas in het detailvenster van het onderdeel de volgende opties in:
Gegevensarchieftype: Azure Blob Storage
Gegevensarchief: Selecteer het eerdere gegevensarchief
Pad:
/data/non-us-incomeBestandsindeling: CSV
Controleer of het onderdeel Gegevens exporteren is verbonden met de linkerpoort van de splitsgegevens het pad heeft
/data/us-incomeControleer of het onderdeel Gegevens exporteren dat is verbonden met de juiste poort het pad heeft
/data/non-us-incomeUw pijplijn en instellingen moeten er als volgt uitzien:

De taak verzenden
Nu u uw pijplijn hebt ingesteld om de gegevens te splitsen en te exporteren, dient u een pijplijntaak in.
Selecteer Configureren en verzenden boven aan het canvas
Selecteer de optie Nieuwe maken in het deelvenster Basisbeginselen van de pijplijntaak instellen om een experiment te maken
Experimenten groeperen gerelateerde pijplijntaken logisch. Als u deze pijplijn in de toekomst uitvoert, moet u hetzelfde experiment gebruiken voor logboekregistratie en tracering
Geef een beschrijvende experimentnaam op, bijvoorbeeld 'split-census-data'
Selecteer Beoordelen en verzenden en selecteer vervolgens Verzenden
Resultaten weergeven
Nadat de pijplijn is uitgevoerd, kunt u naar uw Azure Portal-blobopslag navigeren om uw resultaten weer te geven. U kunt ook de tussenliggende resultaten van het onderdeel Split Data bekijken om te controleren of uw gegevens correct zijn gesplitst.
Het onderdeel Split Data selecteren
Selecteer in het detailvenster van het onderdeel rechts van het canvas het tabblad Uitvoer en logboeken
Selecteer de vervolgkeuzelijst Gegevensuitvoer weergeven
Selecteer het pictogram
 Visualiseren naast resultatengegevensset1
Visualiseren naast resultatengegevensset1Controleer of de kolom 'native-country' alleen de waarde 'Verenigde Staten' bevat
Selecteer het pictogram
Visualiseren naast resultatengegevensset2Controleer of de kolom systeemeigen land niet de waarde 'Verenigde Staten' bevat
Resources opschonen
Sla deze sectie over om door te gaan met deel twee van deze modellen opnieuw trainen met azure Machine Learning Designer .
Belangrijk
U kunt de resources die u hebt gemaakt, gebruiken als vereisten voor andere Azure Machine Learning-zelfstudies en artikelen met procedures.
Alles verwijderen
Als u niets wilt gebruiken dat u hebt gemaakt, kunt u de hele resourcegroep verwijderen zodat er geen kosten voor in rekening worden gebracht.
Selecteer in Azure Portal, aan de linkerkant in het venster, de optie Resourcegroepen.
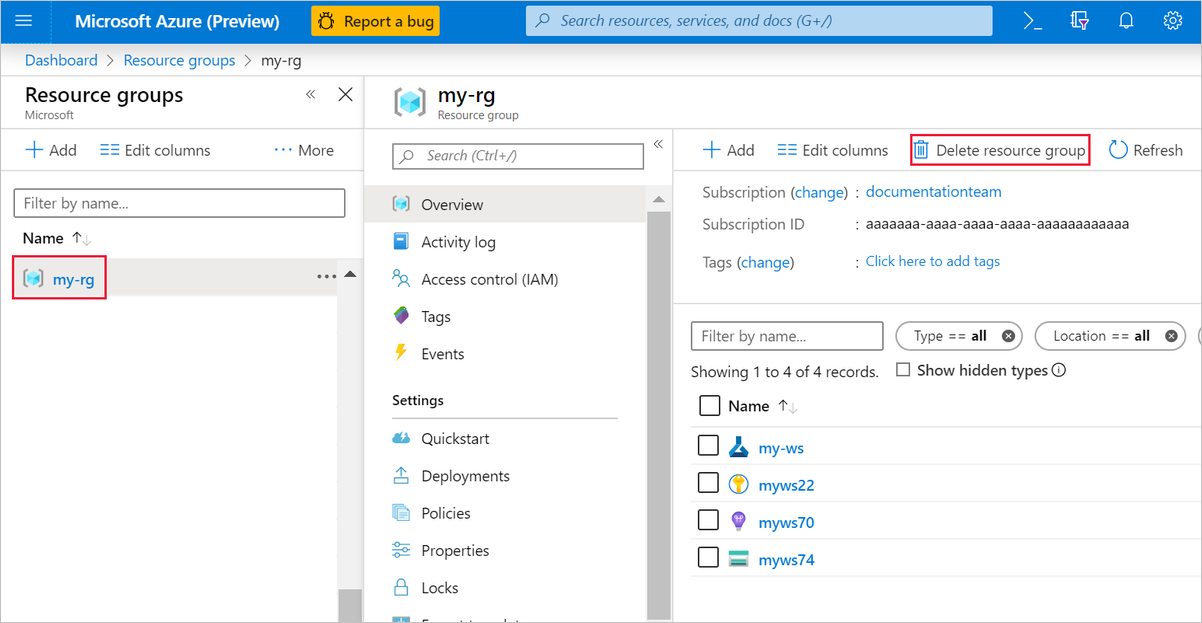
Selecteer de resourcegroep die u hebt gemaakt in de lijst.
Selecteer Resourcegroep verwijderen.
Als u de resource groep verwijdert, worden ook alle resources verwijderd die u in de ontwerpfunctie hebt gemaakt.
Afzonderlijke assets verwijderen
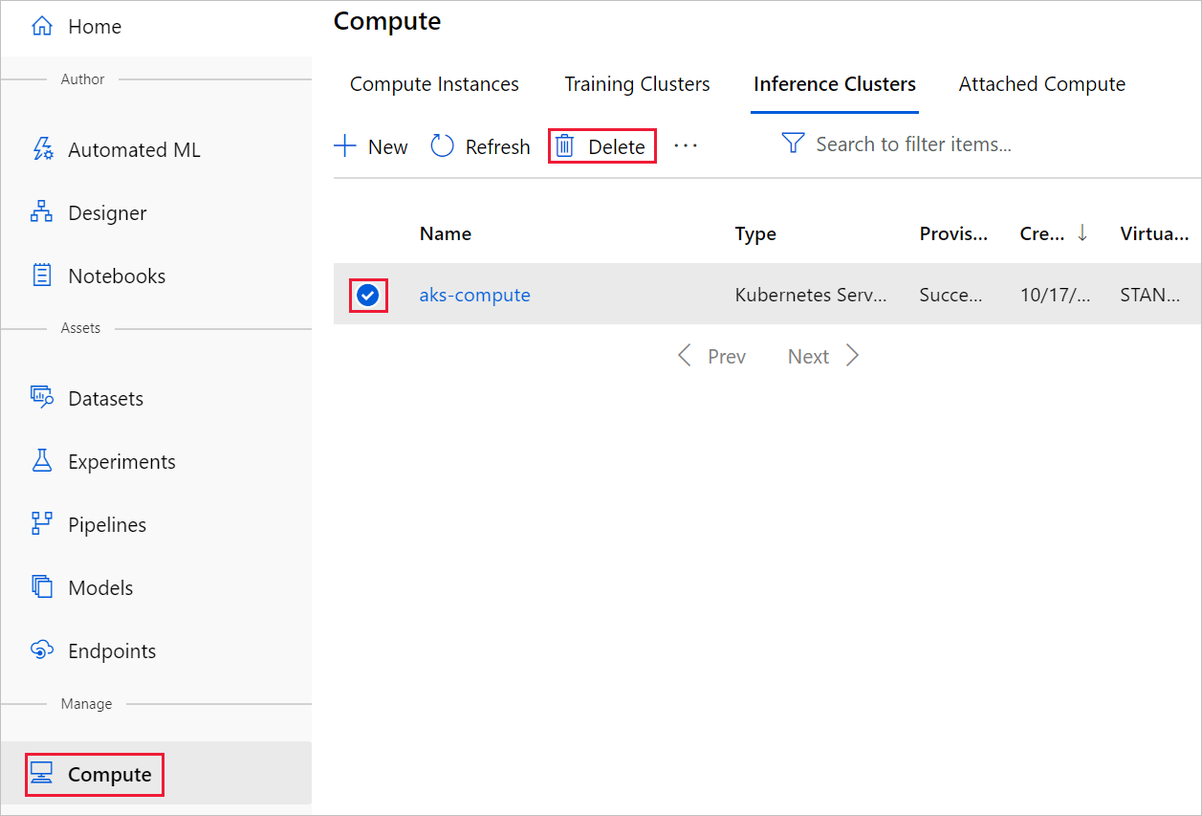
In de ontwerpfunctie waar u uw experiment hebt gemaakt, verwijdert u afzonderlijke assets door ze te selecteren en vervolgens de knop Verwijderen te selecteren.
Het rekendoel dat u hier hebt gemaakt, wordt, wanneer het niet wordt gebruikt, automatisch geschaald naar nul knooppunten. Deze actie wordt uitgevoerd om de kosten te minimaliseren. Als u het rekendoel wilt verwijderen, voert u de volgende stappen uit:
U kunt de registratie van gegevenssets vanuit uw werkruimte opheffen door alle gegevenssets te selecteren en Registratie opheffen te selecteren.
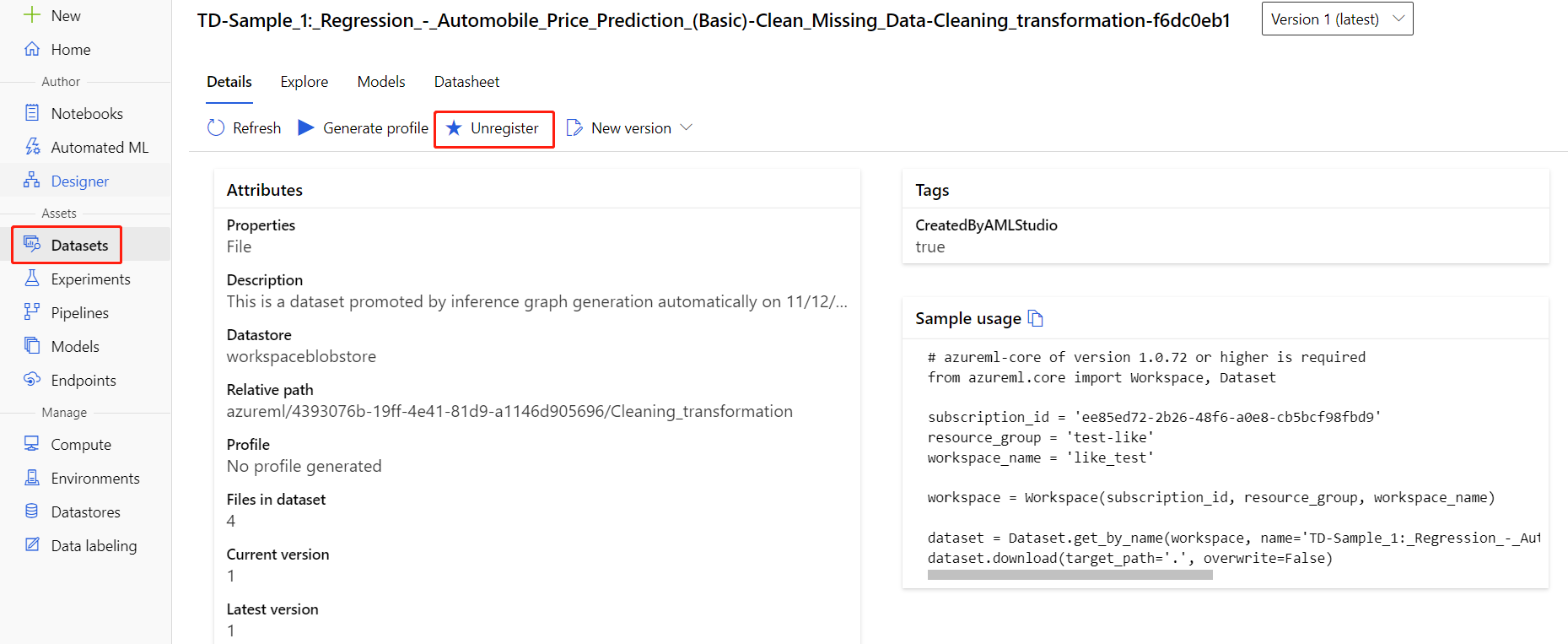
Als u een gegevensset wilt verwijderen, gaat u naar het opslagaccount via Azure Portal of Azure Storage Explorer en verwijdert u de assets handmatig.
Volgende stappen
In dit artikel hebt u geleerd hoe u een gegevensset transformeert en opslaat in een geregistreerd gegevensarchief.
Ga door naar het volgende deel van deze reeks met modellen opnieuw trainen met Azure Machine Learning Designer om uw getransformeerde gegevenssets en pijplijnparameters te gebruiken om machine learning-modellen te trainen.