Batchvoorspellingen uitvoeren met de Azure Machine Learning-ontwerpfunctie
In dit artikel leert u hoe u de ontwerpfunctie gebruikt om een pijplijn voor batchvoorspelling te maken. Met batchvoorspelling kunt u continu grote gegevenssets op aanvraag scoren met behulp van een webservice die vanuit elke HTTP-bibliotheek kan worden geactiveerd.
In deze instructies leert u de volgende taken uit te voeren:
- Een batchdeductiepijplijn maken en publiceren
- Een pijplijneindpunt gebruiken
- Eindpuntversies beheren
Zie de bijbehorende zelfstudie over het scoren van pijplijnen voor meer informatie over het instellen van services voor batchscores met behulp van de SDK.
Vereisten
In deze procedure wordt ervan uitgegaan dat u al een trainingspijplijn hebt. Voor een begeleide inleiding tot de ontwerper, voltooit u deel één van de zelfstudie over ontwerpen.
Belangrijk
Als u grafische elementen die in dit document worden vermeld, zoals knoppen in Studio of Designer, niet ziet, hebt u mogelijk niet het juiste machtigingsniveau voor de werkruimte. Neem contact op met de beheerder van uw Azure-abonnement om te controleren of u het juiste toegangsniveau hebt gekregen. Zie Gebruikers en rollen beherenvoor meer informatie.
Een batchdeductiepijplijn maken
Uw trainingspijplijn moet ten minste één keer worden uitgevoerd om een deductiepijplijn te kunnen maken.
Ga naar het tabblad Designer in uw werkruimte.
Selecteer de trainingspijplijn waarmee het model wordt getraind dat u wilt gebruiken om voorspellingen te doen.
Verzend de pijplijn.
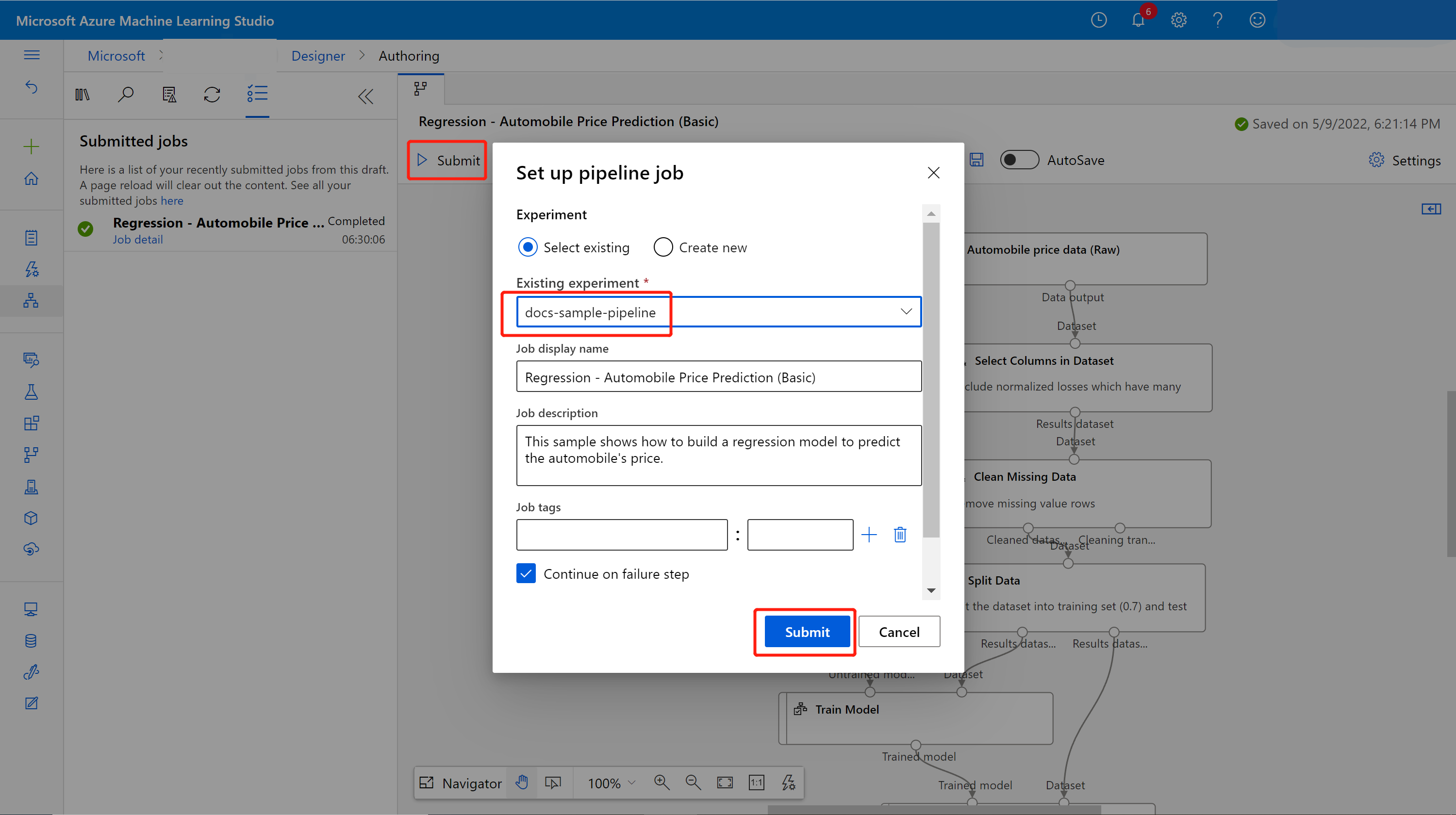

Links van het canvas ziet u een inzendingslijst. U kunt de koppeling taakdetails selecteren om naar de pagina met taakgegevens te gaan. Nadat de trainingspijplijntaak is voltooid, kunt u een batchdeductiepijplijn maken.

Selecteer op de detailpagina van de taak, boven het canvas, de vervolgkeuzelijst Deductiepijplijn maken. Selecteer Batch-deductiepijplijn.
Notitie
Momenteel werkt het automatisch genereren van deductiepijplijn alleen voor trainingspijplijnen die uitsluitend zijn gebouwd door ingebouwde onderdelen van de ontwerpfunctie.

Er wordt een concept voor een batchdeductiepijplijn voor u gemaakt. Het concept van de batchdeductiepijplijn maakt gebruik van het getrainde model als MD-knooppunt en transformatie als TD-knooppunt van de trainingspijplijntaak.
U kunt dit concept van deductiepijplijn ook wijzigen om uw invoergegevens voor batchdeductie beter te verwerken.



Een pijplijnparameter toevoegen
Als u voorspellingen wilt maken voor nieuwe gegevens, kunt u handmatig een andere gegevensset verbinden in deze conceptweergave van de pijplijn of een parameter maken voor uw gegevensset. Met parameters kunt u het gedrag van het batchdeductieproces tijdens runtime wijzigen.
In deze sectie maakt u een gegevenssetparameter om een andere gegevensset op te geven waarop voorspellingen moeten worden gemaakt.
Selecteer het gegevenssetonderdeel.
Rechts van het canvas wordt een deelvenster weergegeven. Selecteer onder in het deelvenster Instellen als pijplijnparameter.
Voer een naam in voor de parameter of accepteer de standaardwaarde.
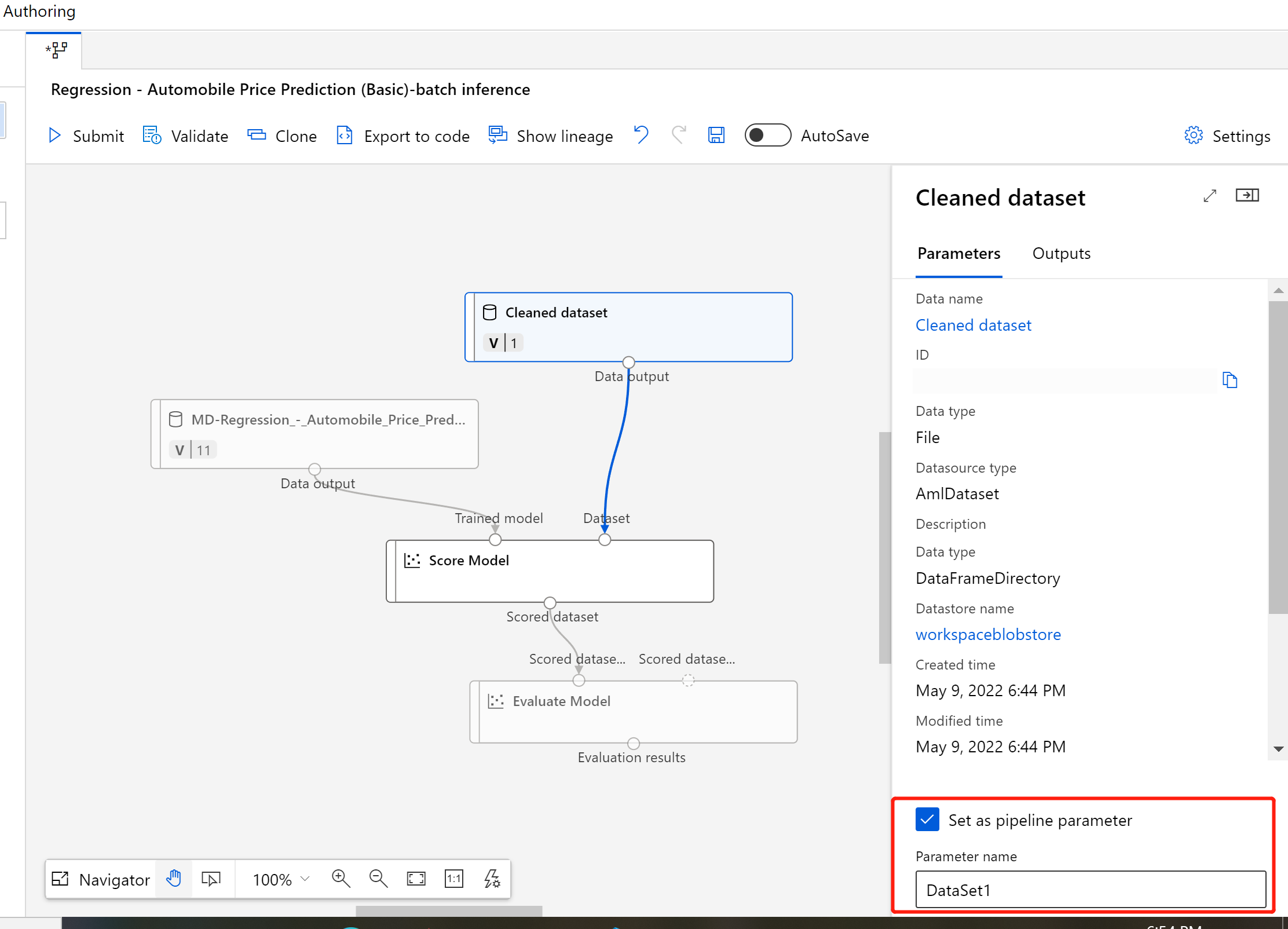
Verzend de batchdeductiepijplijn en ga naar de pagina met taakgegevens door de taakkoppeling in het linkerdeelvenster te selecteren.

De batchdeductiepijplijn publiceren
U bent nu klaar om de deductiepijplijn te implementeren. Hiermee wordt de pijplijn geïmplementeerd en beschikbaar gemaakt voor gebruik door anderen.
Selecteer de knop Publiceren.
Vouw in het dialoogvenster dat wordt weergegeven de vervolgkeuzelijst voor PipelineEndpoint uit en selecteer New PipelineEndpoint.
Geef een eindpuntnaam en optionele beschrijving op.
Onderaan het dialoogvenster ziet u de parameter die u hebt geconfigureerd met een standaardwaarde van de gegevensset-id die tijdens de training is gebruikt.
Selecteer Publiceren.

Een eindpunt gebruiken
Nu hebt u een gepubliceerde pijplijn met een gegevenssetparameter. De pijplijn gebruikt het getrainde model dat is gemaakt in de trainingspijplijn om de gegevensset die u opgeeft als parameter te scoren.
Een pijplijntaak verzenden
In deze sectie stelt u een handmatige pijplijntaak in en wijzigt u de pijplijnparameter om nieuwe gegevens te scoren.
Nadat de implementatie is voltooid, gaat u naar de sectie Eindpunten .
Selecteer Pijplijneindpunten.
Selecteer de naam van het eindpunt dat u hebt gemaakt.
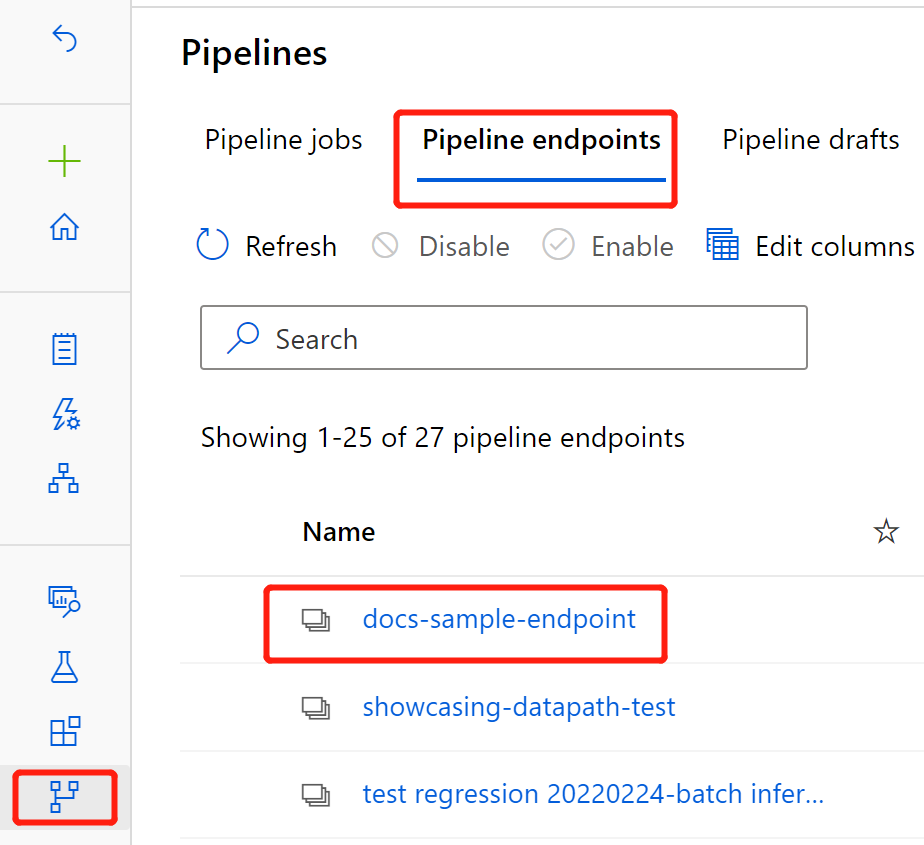
Selecteer Gepubliceerde pijplijnen.
In dit scherm ziet u alle gepubliceerde pijplijnen die onder dit eindpunt zijn gepubliceerd.
Selecteer de pijplijn die u hebt gepubliceerd.
Op de pagina met pijplijndetails ziet u een gedetailleerde taakgeschiedenis en connection string informatie voor uw pijplijn.
Selecteer Verzenden om een handmatige uitvoering van de pijplijn te maken.
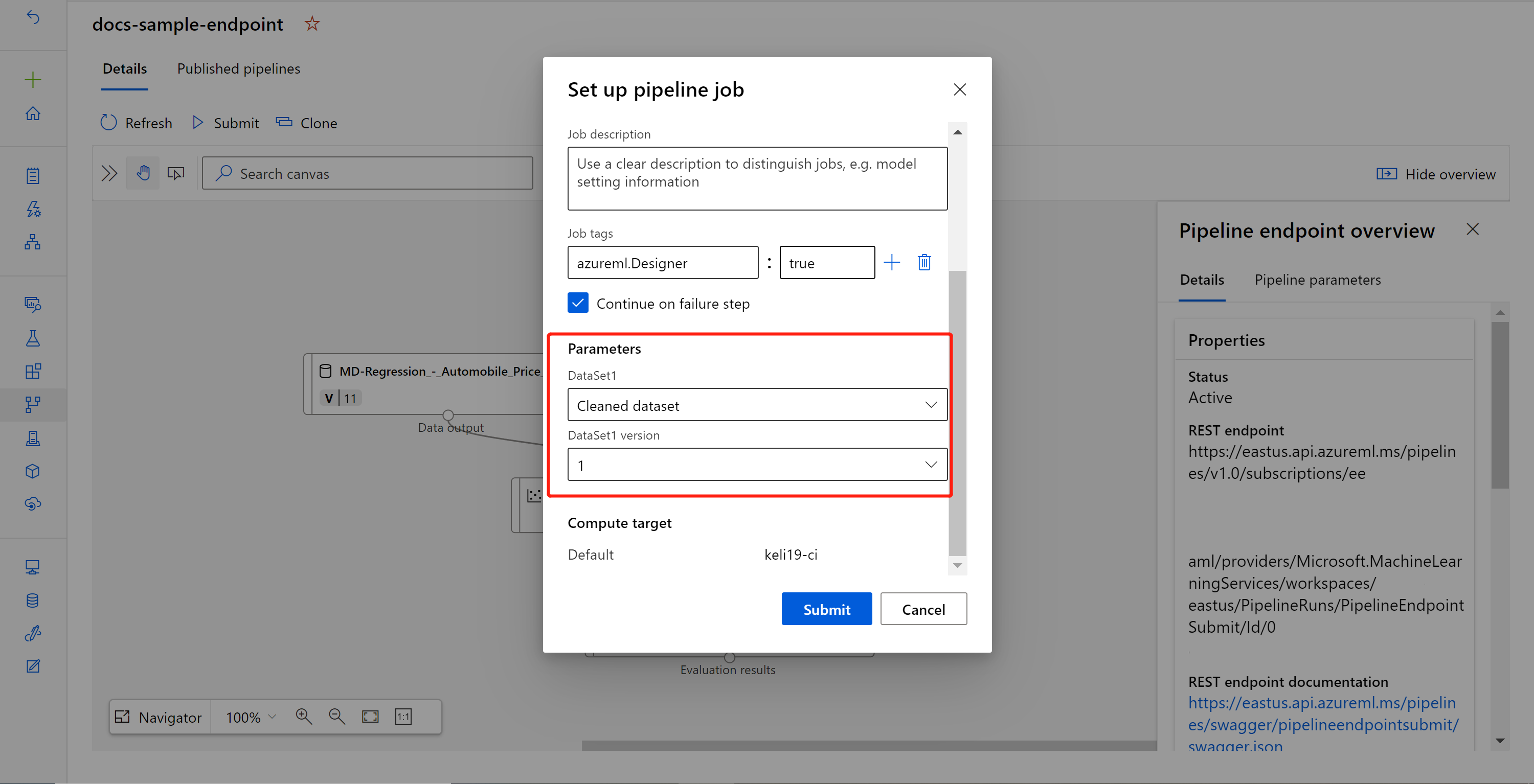
Wijzig de parameter om een andere gegevensset te gebruiken.
Selecteer Verzenden om de pijplijn uit te voeren.

Het REST-eindpunt gebruiken
Informatie over het gebruik van pijplijneindpunten en gepubliceerde pijplijnen vindt u in de sectie Eindpunten .
U vindt het REST-eindpunt van een pijplijneindpunt in het deelvenster Taakoverzicht. Door het eindpunt aan te roepen, gebruikt u de standaard gepubliceerde pijplijn.
U kunt ook een gepubliceerde pijplijn gebruiken op de pagina Gepubliceerde pijplijnen . Selecteer een gepubliceerde pijplijn en u vindt het REST-eindpunt ervan in het deelvenster Overzicht van gepubliceerde pijplijn rechts van de grafiek.
Als u een REST-aanroep wilt doen, hebt u een OAuth 2.0-verificatieheader van het type Bearer nodig. Zie de volgende zelfstudiesectie voor meer informatie over het instellen van verificatie voor uw werkruimte en het maken van een geparameteriseerde REST-aanroep.
Versiebeheereindpunten
De ontwerpfunctie wijst een versie toe aan elke volgende pijplijn die u naar een eindpunt publiceert. U kunt de pijplijnversie opgeven die u wilt uitvoeren als een parameter in uw REST-aanroep. Als u geen versienummer opgeeft, gebruikt de ontwerper de standaardpijplijn.
Wanneer u een pijplijn publiceert, kunt u ervoor kiezen om deze als nieuwe standaardpijplijn voor dat eindpunt te maken.
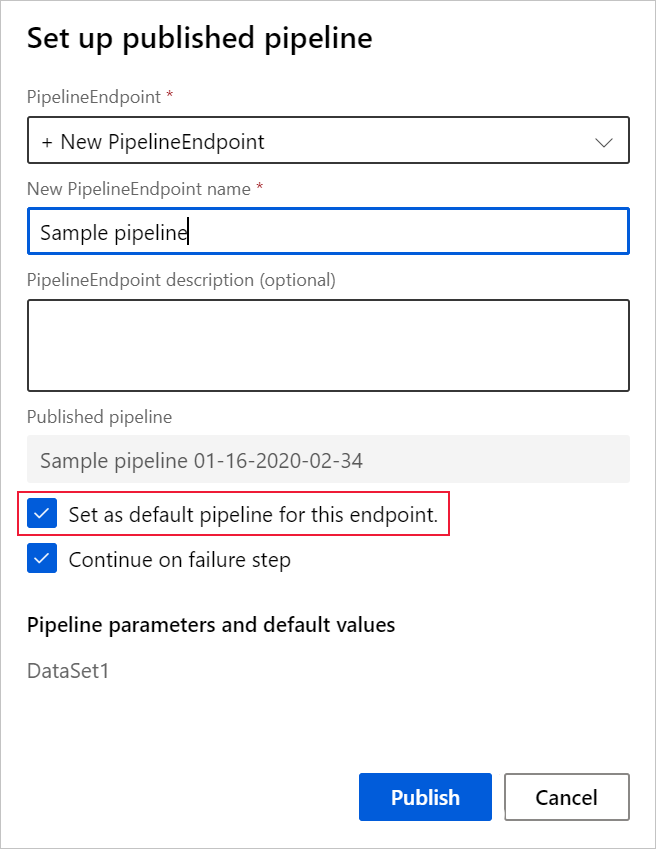
U kunt ook een nieuwe standaardpijplijn instellen op het tabblad Gepubliceerde pijplijnen van uw eindpunt.
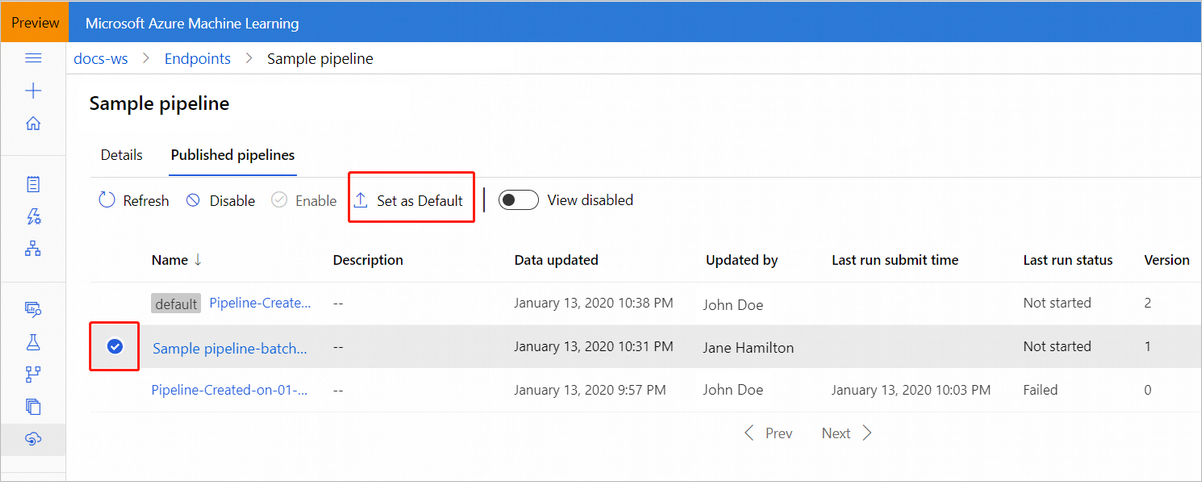
Pijplijneindpunt bijwerken
Als u enkele wijzigingen aanbrengt in uw trainingspijplijn, kunt u het zojuist getrainde model bijwerken naar het pijplijneindpunt.
Nadat de aangepaste trainingspijplijn is voltooid, gaat u naar de pagina met taakgegevens.
Klik met de rechtermuisknop op Het onderdeel Model trainen en selecteer Gegevens registreren
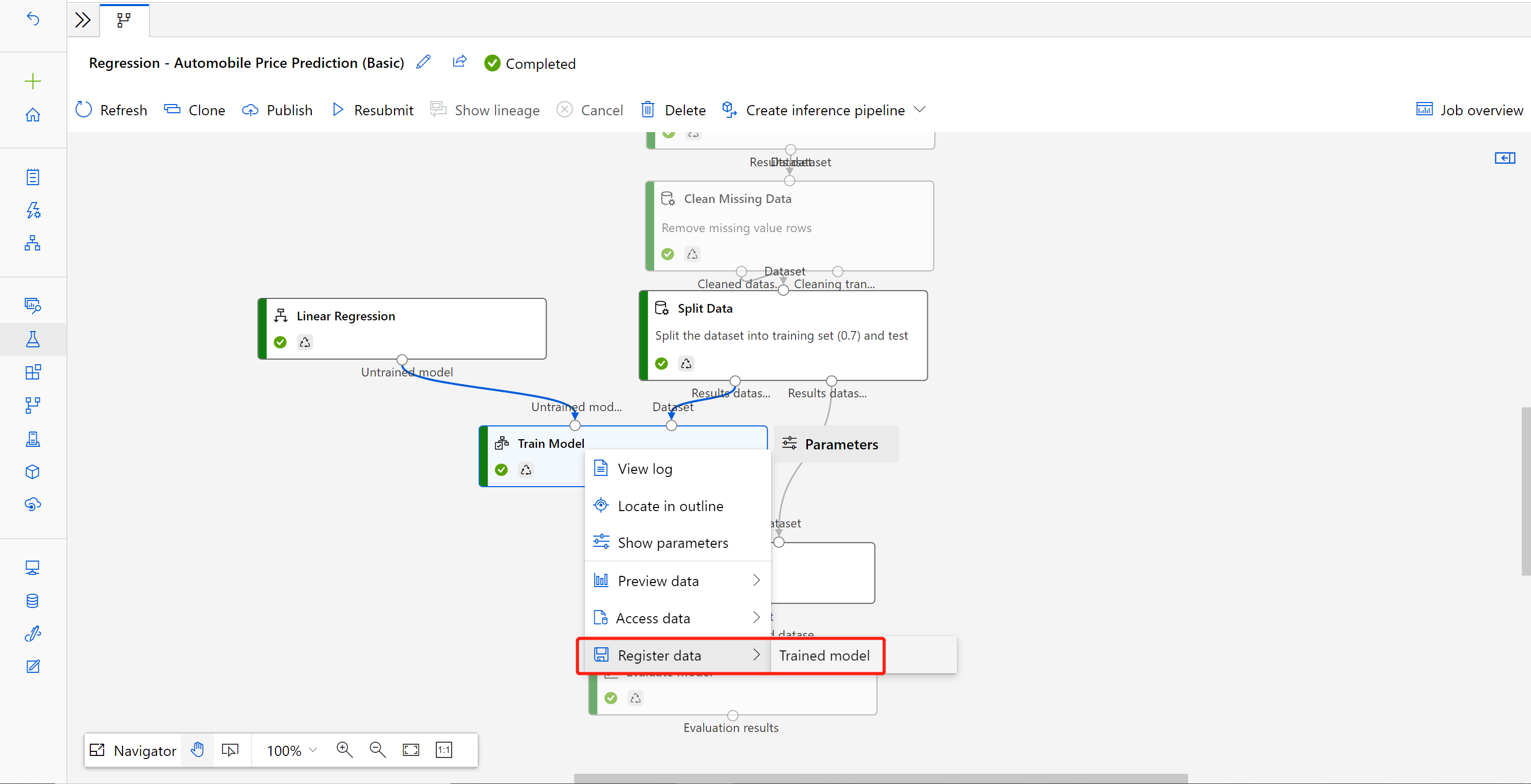
Voer de naam in en selecteer Bestandstype .
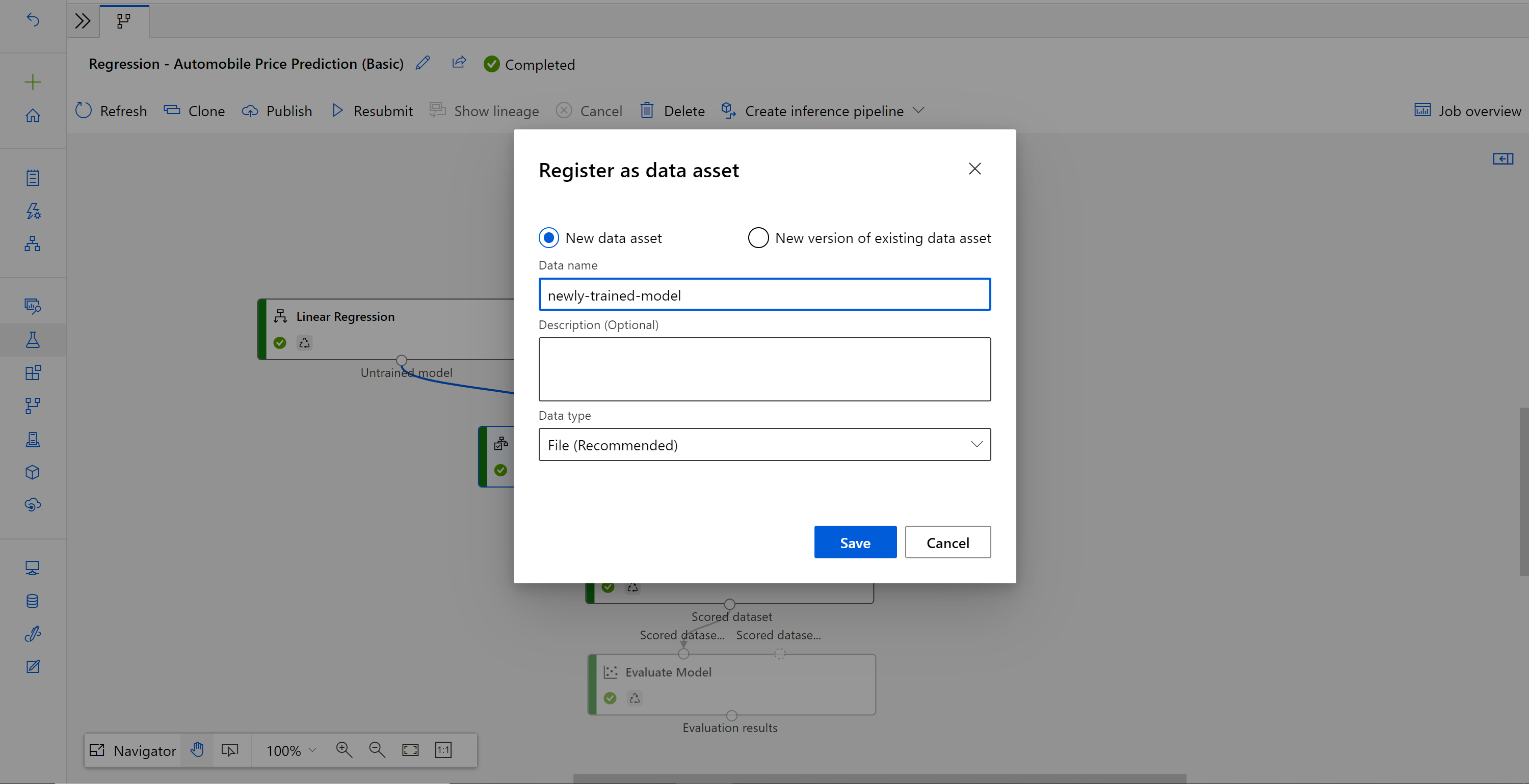
Zoek het vorige concept van de batchdeductiepijplijn of u kunt de gepubliceerde pijplijn klonen in een nieuw concept.
Vervang het MD-knooppunt in het concept van de deductiepijplijn door de geregistreerde gegevens in de bovenstaande stap.
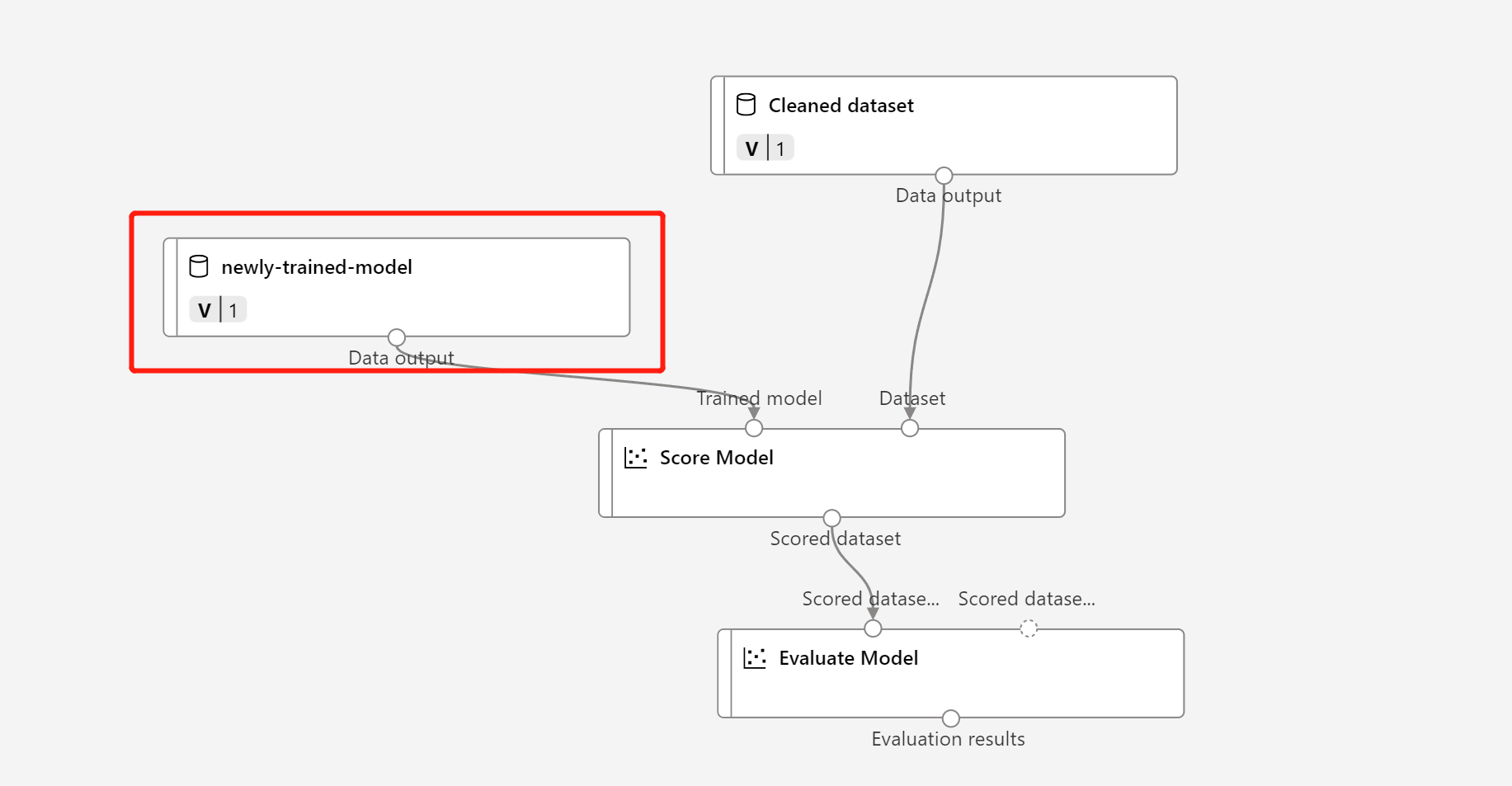
Het bijwerken van gegevenstransformatieknooppunt TD- is hetzelfde als het getrainde model.
Vervolgens kunt u de deductiepijplijn met het bijgewerkte model en de bijgewerkte transformatie verzenden en opnieuw publiceren.


Volgende stappen
- Volg de zelfstudie over ontwerpen om een regressiemodel te trainen en implementeren.
- Zie het artikel Pijplijnen implementeren voor informatie over het publiceren en uitvoeren van een gepubliceerde pijplijn met behulp van de SDK v1.