Veilige implementatie van nieuwe implementaties uitvoeren voor realtime deductie
VAN TOEPASSING OP: Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)Python SDK azure-ai-ml v2 (current)
In dit artikel leert u hoe u een nieuwe versie van een machine learning-model in productie implementeert zonder onderbrekingen te veroorzaken. U gebruikt een blauwgroene implementatiestrategie (ook wel een veilige implementatiestrategie genoemd) om een nieuwe versie van een webservice in productie te introduceren. Met deze strategie kunt u uw nieuwe versie van de webservice implementeren voor een kleine subset van gebruikers of aanvragen voordat u deze volledig uitrolt.
In dit artikel wordt ervan uitgegaan dat u online-eindpunten gebruikt, dat wil gezegd eindpunten die worden gebruikt voor onlinedeductie (realtime). Er zijn twee soorten online-eindpunten: beheerde online-eindpunten en Kubernetes-online-eindpunten. Zie Wat zijn Azure Machine Learning-eindpunten voor meer informatie over eindpunten en de verschillen tussen beheerde online-eindpunten en Kubernetes Online-eindpunten.
In het hoofdvoorbeeld in dit artikel worden beheerde online-eindpunten gebruikt voor implementatie. Als u in plaats daarvan Kubernetes-eindpunten wilt gebruiken, raadpleegt u de notities in dit document die inline zijn met de discussie over beheerde online-eindpunten.
In dit artikel leert u:
- Een online-eindpunt definiëren met een implementatie met de naam 'blauw' voor versie 1 van een model
- De blauwe implementatie schalen zodat er meer aanvragen kunnen worden verwerkt
- Implementeer versie 2 van het model (de 'groene' implementatie genoemd) naar het eindpunt, maar verzend de implementatie geen live verkeer
- De groene implementatie geïsoleerd testen
- Een percentage liveverkeer naar de groene implementatie spiegelen om dit te valideren
- Een klein percentage liveverkeer verzenden naar de groene implementatie
- Al het liveverkeer verzenden naar de groene implementatie
- De nu ongebruikte v1 blauwe implementatie verwijderen
Vereisten
Voordat u de stappen in dit artikel volgt, moet u ervoor zorgen dat u over de volgende vereisten beschikt:
De Azure CLI en de
mlextensie voor de Azure CLI. Zie De CLI (v2) installeren, instellen en gebruiken voor meer informatie.Belangrijk
In de CLI-voorbeelden in dit artikel wordt ervan uitgegaan dat u de Bash-shell (of compatibele) shell gebruikt. Bijvoorbeeld vanuit een Linux-systeem of Windows-subsysteem voor Linux.
Een Azure Machine Learning-werkruimte. Als u er nog geen hebt, gebruikt u de stappen in de installatie, het instellen en gebruiken van de CLI (v2) om er een te maken.
Op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC) wordt gebruikt om toegang te verlenen tot bewerkingen in Azure Machine Learning. Als u de stappen in dit artikel wilt uitvoeren, moet aan uw gebruikersaccount de rol eigenaar of inzender voor de Azure Machine Learning-werkruimte zijn toegewezen, of een aangepaste rol die toestaat
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Zie Toegang tot een Azure Machine Learning-werkruimte beheren voor meer informatie.(Optioneel) Als u lokaal wilt implementeren, moet u Docker Engine installeren op uw lokale computer. We raden deze optie ten zeerste aan , dus het is eenvoudiger om problemen op te sporen.
Uw systeem voorbereiden
Omgevingsvariabelen instellen
Als u de standaardinstellingen voor de Azure CLI nog niet hebt ingesteld, slaat u de standaardinstellingen op. Voer deze code uit om te voorkomen dat de waarden voor uw abonnement, werkruimte en resourcegroep meerdere keren worden doorgegeven:
az account set --subscription <subscription id>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
De opslagplaats met voorbeelden klonen
Als u dit artikel wilt volgen, kloont u eerst de opslagplaats met voorbeelden (azureml-examples). Ga vervolgens naar de map van cli/ de opslagplaats:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
cd cli
Tip
Gebruik --depth 1 dit om alleen de meest recente doorvoering naar de opslagplaats te klonen. Dit vermindert de tijd om de bewerking te voltooien.
De opdrachten in deze zelfstudie bevinden zich in het bestand deploy-safe-rollout-online-endpoints.sh in de cli map en de YAML-configuratiebestanden bevinden zich in de endpoints/online/managed/sample/ submap.
Notitie
De YAML-configuratiebestanden voor Online Kubernetes-eindpunten bevinden zich in de endpoints/online/kubernetes/ submap.
Het eindpunt en de implementatie definiëren
Online-eindpunten worden gebruikt voor online (realtime)-deductie. Online-eindpunten bevatten implementaties die gereed zijn om gegevens van clients te ontvangen en antwoorden in realtime terug te sturen.
Een eindpunt definiëren
De volgende tabel bevat belangrijke kenmerken die moeten worden opgegeven wanneer u een eindpunt definieert.
| Kenmerk | Beschrijving |
|---|---|
| Naam | Vereist. Naam van het eindpunt. Deze moet uniek zijn in de Azure-regio. Zie eindpuntlimieten voor meer informatie over de naamgevingsregels. |
| Verificatiemodus | De verificatiemethode voor het eindpunt. Kies tussen verificatie key op basis van sleutels en verificatie aml_tokenop basis van een Azure Machine Learning-token. Een sleutel verloopt niet, maar een token verloopt wel. Zie Verifiëren bij een online-eindpunt voor meer informatie over verificatie. |
| Beschrijving | Beschrijving van het eindpunt. |
| Tags | Woordenlijst met tags voor het eindpunt. |
| Verkeer | Regels voor het routeren van verkeer tussen implementaties. Vertegenwoordig het verkeer als een woordenlijst van sleutel-waardeparen, waarbij de sleutel de implementatienaam en waarde vertegenwoordigt het percentage verkeer naar die implementatie. U kunt het verkeer alleen instellen wanneer de implementaties onder een eindpunt zijn gemaakt. U kunt ook het verkeer voor een online-eindpunt bijwerken nadat de implementaties zijn gemaakt. Zie Een klein percentage liveverkeer toewijzen aan de nieuwe implementatie voor meer informatie over het gebruik van gespiegeld verkeer. |
| Verkeer spiegelen | Percentage liveverkeer dat moet worden gespiegeld aan een implementatie. Zie De implementatie testen met gespiegeld verkeer voor meer informatie over het gebruik van gespiegeld verkeer. |
Als u een volledige lijst met kenmerken wilt zien die u kunt opgeven wanneer u een eindpunt maakt, raadpleegt u CLI (v2) ONLINE YAML-schema of SDK (v2) ManagedOnlineEndpoint Class.
Een implementatie definiëren
Een implementatie is een set resources die vereist is voor het hosten van het model dat de werkelijke deductie uitvoert. In de volgende tabel worden de belangrijkste kenmerken beschreven die moeten worden opgegeven wanneer u een implementatie definieert.
| Kenmerk | Beschrijving |
|---|---|
| Naam | Vereist. Naam van de implementatie. |
| Naam Eeindpunt | Vereist. De naam van het eindpunt voor het maken van de implementatie onder. |
| Model | Het model dat moet worden gebruikt voor de implementatie. Deze waarde kan een verwijzing zijn naar een bestaand versiemodel in de werkruimte of een inline modelspecificatie. In het voorbeeld hebben we een scikit-learn-model dat regressie uitvoert. |
| Codepad | Het pad naar de map in de lokale ontwikkelomgeving die alle Python-broncode bevat voor het scoren van het model. U kunt geneste mappen en pakketten gebruiken. |
| Scorescript | Python-code waarmee het model wordt uitgevoerd op een bepaalde invoeraanvraag. Deze waarde kan het relatieve pad naar het scorebestand in de broncodemap zijn. Het scorescript ontvangt gegevens die zijn verzonden naar een geïmplementeerde webservice en geeft deze door aan het model. Het script voert vervolgens het model uit en retourneert de reactie op de client. Het scorescript is specifiek voor uw model en moet inzicht hebben in de gegevens die het model als invoer verwacht en als uitvoer retourneert. In dit voorbeeld hebben we een score.py-bestand . Deze Python-code moet een init() functie en een run() functie hebben. De init() functie wordt aangeroepen nadat het model is gemaakt of bijgewerkt (u kunt deze bijvoorbeeld gebruiken om het model in het geheugen op te cachen). De run() functie wordt aangeroepen bij elke aanroep van het eindpunt om de werkelijke score en voorspelling uit te voeren. |
| Omgeving | Vereist. De omgeving voor het hosten van het model en de code. Deze waarde kan een verwijzing zijn naar een bestaande versieomgeving in de werkruimte of een inline-omgevingsspecificatie. De omgeving kan een Docker-installatiekopieën zijn met Conda-afhankelijkheden, een Dockerfile of een geregistreerde omgeving. |
| Type instantie | Vereist. De VM-grootte die moet worden gebruikt voor de implementatie. Zie de lijst met beheerde online-eindpunten voor SKU's voor de lijst met ondersteunde grootten. |
| Aantal exemplaren | Vereist. Het aantal exemplaren dat moet worden gebruikt voor de implementatie. Baseer de waarde op de workload die u verwacht. Voor hoge beschikbaarheid raden we u aan om de waarde ten minste 3in te stellen op . We reserveren een extra 20% voor het uitvoeren van upgrades. Zie limieten voor online-eindpunten voor meer informatie. |
Als u een volledige lijst met kenmerken wilt zien die u kunt opgeven wanneer u een implementatie maakt, raadpleegt u HET YAML-schema of SDK (v2) ManagedOnlineDeployment Class (CLI (v2) ManagedOnlineDeployment.
Online-eindpunt maken
Stel eerst de naam van het eindpunt in en configureer deze. In dit artikel gebruikt u het eindpunten/online/managed/sample/endpoint.yml-bestand om het eindpunt te configureren. In het volgende fragment wordt de inhoud van het bestand weergegeven:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
De verwijzing voor de YAML-indeling van het eindpunt wordt beschreven in de volgende tabel. Zie de YAML-referentie voor het online-eindpunt voor meer informatie over het opgeven van deze kenmerken. Zie limieten voor online-eindpunten voor informatie over limieten met betrekking tot beheerde online-eindpunten.
| Toets | Beschrijving |
|---|---|
$schema |
(Optioneel) Het YAML-schema. Als u alle beschikbare opties in het YAML-bestand wilt zien, kunt u het schema bekijken in het voorgaande codefragment in een browser. |
name |
De naam van het eindpunt. |
auth_mode |
Gebruiken key voor verificatie op basis van sleutels. Gebruiken aml_token voor verificatie op basis van tokens op basis van Azure Machine Learning. Gebruik de az ml online-endpoint get-credentials opdracht om het meest recente token op te halen. |
Een online-eindpunt maken:
Stel de naam van uw eindpunt in:
Voer voor Unix deze opdracht uit (vervang door
YOUR_ENDPOINT_NAMEeen unieke naam):export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"Belangrijk
Eindpuntnamen moeten uniek zijn binnen een Azure-regio. In de Azure-regio
westus2kan er bijvoorbeeld slechts één eindpunt met de naammy-endpointzijn.Maak het eindpunt in de cloud:
Voer de volgende code uit om het
endpoint.ymlbestand te gebruiken om het eindpunt te configureren:az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
De 'blauwe' implementatie maken
In dit artikel gebruikt u het bestand endpoints/online/managed/sample/blue-deployment.yml om de belangrijkste aspecten van de implementatie te configureren. In het volgende fragment wordt de inhoud van het bestand weergegeven:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
Als u een implementatie wilt maken met de naam blue van uw eindpunt, voert u de volgende opdracht uit om het bestand te gebruiken om het blue-deployment.yml te configureren
az ml online-deployment create --name blue --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml --all-traffic
Belangrijk
De --all-traffic vlag in de az ml online-deployment create vlag wijst 100% van het eindpuntverkeer toe aan de zojuist gemaakte blauwe implementatie.
In het blue-deployment.yaml bestand geven we inline op path waar bestanden moeten worden geüpload. De CLI uploadt automatisch de bestanden en registreert het model en de omgeving. Als best practice voor productie moet u het model en de omgeving registreren en de geregistreerde naam en versie afzonderlijk opgeven in de YAML. Gebruik het formulier model: azureml:my-model:1 of environment: azureml:my-env:1.
Voor registratie kunt u de YAML-definities van model en environment in afzonderlijke YAML-bestanden extraheren en de opdrachten az ml model create en az ml environment creategebruiken. Voor meer informatie over deze opdrachten voert u de opdracht uit az ml model create -h en az ml environment create -h.
Zie Uw model registreren als een asset in Machine Learning met behulp van de CLI voor meer informatie over het registreren van uw model als een asset. Zie Azure Machine Learning-omgevingen beheren met de CLI & SDK (v2) voor meer informatie over het maken van een omgeving.





Uw bestaande implementatie bevestigen
Een manier om uw bestaande implementatie te bevestigen, is door uw eindpunt aan te roepen, zodat het uw model kan beoordelen voor een bepaalde invoeraanvraag. Wanneer u uw eindpunt aanroept via de CLI of Python SDK, kunt u ervoor kiezen om de naam op te geven van de implementatie die het binnenkomende verkeer ontvangt.
Notitie
In tegenstelling tot de CLI of Python SDK moet u Azure Machine Learning-studio een implementatie opgeven wanneer u een eindpunt aanroept.
Eindpunt aanroepen met implementatienaam
Als u het eindpunt aanroept met de naam van de implementatie die verkeer ontvangt, stuurt Azure Machine Learning het verkeer van het eindpunt rechtstreeks naar de opgegeven implementatie en retourneert de uitvoer. U kunt de --deployment-name optie voor CLI v2 of deployment_name de optie voor SDK v2 gebruiken om de implementatie op te geven.
Eindpunt aanroepen zonder implementatie op te geven
Als u het eindpunt aanroept zonder de implementatie op te geven die verkeer ontvangt, stuurt Azure Machine Learning het binnenkomende verkeer van het eindpunt naar de implementatie(s) in het eindpunt op basis van de instellingen voor verkeerbeheer.
Instellingen voor verkeersbeheer wijzen opgegeven percentages van binnenkomend verkeer toe aan elke implementatie in het eindpunt. Als uw verkeersregels bijvoorbeeld aangeven dat een bepaalde implementatie in uw eindpunt 40% van de tijd binnenkomend verkeer ontvangt, routeert Azure Machine Learning 40% van het verkeer van het eindpunt naar die implementatie.
U kunt de status van uw bestaande eindpunt en implementatie bekijken door het volgende uit te voeren:
az ml online-endpoint show --name $ENDPOINT_NAME
az ml online-deployment show --name blue --endpoint $ENDPOINT_NAME
U ziet nu het eindpunt dat is geïdentificeerd door $ENDPOINT_NAME en een implementatie met de naam blue.
Het eindpunt testen met voorbeeldgegevens
Het eindpunt kan worden aangeroepen met behulp van de invoke opdracht. We verzenden een voorbeeldaanvraag met behulp van een json-bestand .
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json


Uw bestaande implementatie schalen om meer verkeer te verwerken
In de implementatie die wordt beschreven in Implementeren en scoren van een machine learning-model met een online-eindpunt, stelt u de instance_count waarde 1 in het yaml-bestand voor de implementatie in. U kunt uitschalen met behulp van de update opdracht:
az ml online-deployment update --name blue --endpoint-name $ENDPOINT_NAME --set instance_count=2
Notitie
U ziet dat we --set in de bovenstaande opdracht de implementatieconfiguratie overschrijven. U kunt het yaml-bestand ook bijwerken en doorgeven als invoer aan de update opdracht met behulp van de --file invoer.

Een nieuw model implementeren, maar het verkeer nog niet verzenden
Maak een nieuwe implementatie met de naam green:
az ml online-deployment create --name green --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/green-deployment.yml
Omdat er geen verkeer expliciet aan ons is greentoegewezen, is er geen verkeer toegewezen. U kunt controleren of u dit kunt doen met behulp van de opdracht:
az ml online-endpoint show -n $ENDPOINT_NAME --query traffic
De nieuwe implementatie testen
Hoewel green 0% van het verkeer is toegewezen, kunt u het rechtstreeks aanroepen door de --deployment naam op te geven:
az ml online-endpoint invoke --name $ENDPOINT_NAME --deployment-name green --request-file endpoints/online/model-2/sample-request.json
Als u een REST-client wilt gebruiken om de implementatie rechtstreeks aan te roepen zonder verkeersregels te doorlopen, stelt u de volgende HTTP-header in: azureml-model-deployment: <deployment-name> Het onderstaande codefragment gebruikt curl om de implementatie rechtstreeks aan te roepen. Het codefragment moet werken in Unix-/WSL-omgevingen:
# get the scoring uri
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
# use curl to invoke the endpoint
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --header "azureml-model-deployment: green" --data @endpoints/online/model-2/sample-request.json


De implementatie testen met gespiegeld verkeer
Zodra u uw green implementatie hebt getest, kunt u een percentage van het liveverkeer naar de implementatie spiegelen (of kopiëren). Bij verkeerspiegeling (ook wel schaduwen genoemd) worden de resultaten die naar clients worden geretourneerd, niet gewijzigd. Aanvragen stromen nog steeds 100% naar de blue implementatie. Het gespiegelde percentage van het verkeer wordt gekopieerd en verzonden naar de green implementatie, zodat u metrische gegevens en logboekregistratie kunt verzamelen zonder dat dit van invloed is op uw clients. Spiegelen is handig als u een nieuwe implementatie wilt valideren zonder dat dit van invloed is op clients. U kunt spiegeling bijvoorbeeld gebruiken om te controleren of de latentie binnen acceptabele grenzen valt of om te controleren of er geen HTTP-fouten zijn. Het testen van de nieuwe implementatie met verkeerspiegeling/schaduwen wordt ook wel schaduwtests genoemd. De implementatie die het gespiegelde verkeer ontvangt (in dit geval de green implementatie) kan ook de schaduwimplementatie worden genoemd.
Spiegeling heeft de volgende beperkingen:
- Spiegeling wordt ondersteund voor de CLI (v2) (versie 2.4.0 of hoger) en Python SDK (v2) (versie 1.0.0 of hoger). Als u een oudere versie van CLI/SDK gebruikt om een eindpunt bij te werken, verliest u de instelling voor spiegelverkeer.
- Spiegeling wordt momenteel niet ondersteund voor Online-eindpunten van Kubernetes.
- U kunt verkeer spiegelen naar slechts één implementatie in een eindpunt.
- Het maximale percentage verkeer dat u kunt spiegelen is 50%. Deze limiet is om het effect op het quotum voor eindpuntbandbreedte (standaard 5 MBPS) te verminderen. Uw eindpuntbandbreedte wordt beperkt als u het toegewezen quotum overschrijdt. Zie Beheerde online-eindpunten bewaken voor informatie over het bewaken van bandbreedtebeperking.
Let ook op het volgende gedrag:
- Een implementatie kan worden geconfigureerd om alleen live verkeer of gespiegeld verkeer te ontvangen, niet beide.
- Wanneer u een eindpunt aanroept, kunt u de naam van alle implementaties ( zelfs een schaduwimplementatie) opgeven om de voorspelling te retourneren.
- Wanneer u een eindpunt aanroept met de naam van de implementatie die binnenkomend verkeer ontvangt, spiegelt Azure Machine Learning geen verkeer naar de schaduwimplementatie. Azure Machine Learning spiegelt verkeer naar de schaduwimplementatie van verkeer dat naar het eindpunt wordt verzonden wanneer u geen implementatie opgeeft.
Nu gaan we de groene implementatie zo instellen dat 10% van het gespiegelde verkeer wordt ontvangen. Clients ontvangen nog steeds alleen voorspellingen van de blauwe implementatie.
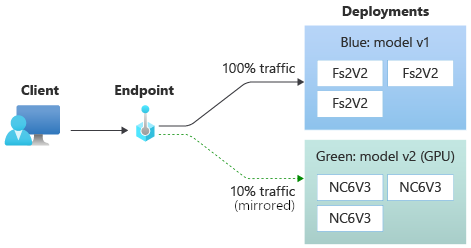
Met de volgende opdracht wordt 10% van het verkeer naar de green implementatie gespiegeld:
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=10"
U kunt spiegelverkeer testen door het eindpunt meerdere keren aan te roepen zonder een implementatie op te geven om het binnenkomende verkeer te ontvangen:
for i in {1..20} ; do
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
done
U kunt controleren of het specifieke percentage van het verkeer naar de green implementatie is verzonden door de logboeken van de implementatie te bekijken:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Na het testen kunt u het gespiegelde verkeer instellen op nul om spiegeling uit te schakelen:
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=0"



Een klein percentage liveverkeer toewijzen aan de nieuwe implementatie
Zodra u uw green implementatie hebt getest, wijst u er een klein percentage verkeer aan toe:
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=90 green=10"
Tip
Het totale verkeerspercentage moet worden opgeteld tot 0% (om verkeer uit te schakelen) of 100% (om verkeer in te schakelen).
green Uw implementatie ontvangt nu 10% van al het live verkeer. Clients ontvangen voorspellingen van zowel de bluegreen als de implementaties.
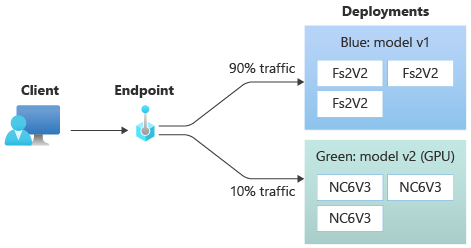
Al het verkeer naar uw nieuwe implementatie verzenden
Zodra u volledig tevreden bent met uw green implementatie, schakelt u al het verkeer naar de implementatie over.
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=0 green=100"
De oude implementatie verwijderen
Gebruik de volgende stappen om een afzonderlijke implementatie te verwijderen uit een beheerd online-eindpunt. Het verwijderen van een afzonderlijke implementatie heeft gevolgen voor de andere implementaties in het beheerde online-eindpunt:
az ml online-deployment delete --name blue --endpoint $ENDPOINT_NAME --yes --no-wait
Het eindpunt en de implementatie verwijderen
Als u het eindpunt en de implementatie niet gaat gebruiken, moet u deze verwijderen. Door het eindpunt te verwijderen, verwijdert u ook alle onderliggende implementaties.
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Gerelateerde inhoud
- Voorbeelden van online-eindpunten verkennen
- Modellen implementeren met REST
- Netwerkisolatie gebruiken met beheerde online-eindpunten
- Toegang tot Azure-resources met een online-eindpunt en beheerde identiteit
- Beheerde online-eindpunten bewaken
- Quota voor resources beheren en verhogen met Azure Machine Learning
- Kosten weergeven voor een online-eindpunt dat door Azure Machine Learning wordt beheerd
- SKU-lijst met beheerde online-eindpunten
- Problemen met de implementatie en score van online-eindpunten oplossen
- YamL-referentie voor online-eindpunt