Hyperparameter afstemmen van een model (v2)
VAN TOEPASSING OP: Azure CLI ml-extensie v2 (huidig)Python SDK azure-ai-ml v2 (huidig)
Azure CLI ml-extensie v2 (huidig)Python SDK azure-ai-ml v2 (huidig)
Automatiseer efficiënte afstemming van hyperparameters met behulp van Azure Machine Learning SDK v2 en CLI v2 via het type SweepJob.
- De parameterzoekruimte voor uw proefabonnement definiëren
- Geef het sampling-algoritme op voor uw sweep-taak
- De doelstelling opgeven om te optimaliseren
- Beleid voor vroegtijdige beëindiging opgeven voor slecht presterende taken
- Limieten voor de sweep-taak definiëren
- Een experiment starten met de gedefinieerde configuratie
- De trainingstaken visualiseren
- De beste configuratie voor uw model selecteren
Wat is hyperparameterafstemming?
Hyperparameters zijn aanpasbare parameters waarmee u het modeltrainingsproces kunt beheren. Met neurale netwerken bepaalt u bijvoorbeeld het aantal verborgen lagen en het aantal knooppunten in elke laag. Modelprestaties zijn sterk afhankelijk van hyperparameters.
Hyperparameter afstemmen, ook wel hyperparameteroptimalisatie genoemd, is het proces van het vinden van de configuratie van hyperparameters die resulteert in de beste prestaties. Het proces is doorgaans rekenkundig duur en handmatig.
Met Azure Machine Learning kunt u het afstemmen van hyperparameters automatiseren en parallel experimenten uitvoeren om hyperparameters efficiënt te optimaliseren.
De zoekruimte definiëren
Hyperparameters afstemmen door het bereik van waarden te verkennen dat voor elke hyperparameter is gedefinieerd.
Hyperparameters kunnen discreet of doorlopend zijn en hebben een verdeling van waarden die wordt beschreven door een parameterexpressie.
Discrete hyperparameters
Discrete hyperparameters worden opgegeven als een Choice onder discrete waarden. Choice kan zijn:
- een of meer door komma's gescheiden waarden
- een
rangeobject listwillekeurig object
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32, 64, 128]),
number_of_hidden_layers=Choice(values=range(1,5)),
)
In dit geval batch_size neemt een van de waarden [16, 32, 64, 128] een number_of_hidden_layers van de waarden [1, 2, 3, 4].
De volgende geavanceerde discrete hyperparameters kunnen ook worden opgegeven met behulp van een distributie:
QUniform(min_value, max_value, q)- Retourneert een waarde zoals round(Uniform(min_value, max_value) / q) * qQLogUniform(min_value, max_value, q)- Retourneert een waarde zoals round(exp(Uniform(min_value, max_value)) / q) * qQNormal(mu, sigma, q)- Geeft als resultaat een waarde zoals round(Normal(mu, sigma) / q) * qQLogNormal(mu, sigma, q)- Retourneert een waarde zoals round(exp(Normal(mu, sigma)) / q) * q
Continue hyperparameters
De continue hyperparameters worden opgegeven als een verdeling over een doorlopend bereik van waarden:
Uniform(min_value, max_value)- Geeft als resultaat een waarde die uniform is verdeeld tussen min_value en max_valueLogUniform(min_value, max_value)- Retourneert een waarde die is getekend volgens exp(Uniform(min_value, max_value)) zodat de logaritme van de geretourneerde waarde uniform wordt verdeeldNormal(mu, sigma)- Geeft als resultaat een reële waarde die normaal wordt verdeeld met gemiddelde mu en standaarddeviatie sigmaLogNormal(mu, sigma)- Geeft als resultaat een waarde die is getekend volgens exp(Normal(mu, sigma)) zodat de logaritme van de geretourneerde waarde normaal wordt verdeeld
Een voorbeeld van een parameterruimtedefinitie:
from azure.ai.ml.sweep import Normal, Uniform
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
)
Deze code definieert een zoekruimte met twee parameters: learning_rate en keep_probability. learning_rate heeft een normale verdeling met gemiddelde waarde 10 en een standaarddeviatie van 3. keep_probability heeft een uniforme verdeling met een minimumwaarde van 0,05 en een maximumwaarde van 0,1.
Voor de CLI kunt u het YAML-schema van de sweep-taak gebruiken om de zoekruimte in uw YAML te definiëren:
search_space:
conv_size:
type: choice
values: [2, 5, 7]
dropout_rate:
type: uniform
min_value: 0.1
max_value: 0.2
Een steekproef nemen van de hyperparameterruimte
Geef de parametersamplingsmethode op die moet worden gebruikt voor de hyperparameterruimte. Azure Machine Learning ondersteunt de volgende methoden:
- Willekeurige steekproeven
- Rastersampling
- Bayesiaanse steekproeven
Willekeurige steekproeven
Willekeurige steekproeven ondersteunen discrete en continue hyperparameters. Het ondersteunt vroegtijdige beëindiging van slecht presterende taken. Sommige gebruikers voeren een eerste zoekopdracht uit met willekeurige steekproeven en verfijnen vervolgens de zoekruimte om de resultaten te verbeteren.
Bij willekeurige steekproeven worden hyperparameterwaarden willekeurig geselecteerd uit de gedefinieerde zoekruimte. Nadat u de opdrachttaak hebt gemaakt, kunt u de parameter sweep gebruiken om het sampling-algoritme te definiëren.
from azure.ai.ml.sweep import Normal, Uniform, RandomParameterSampling
command_job_for_sweep = command_job(
learning_rate=Normal(mu=10, sigma=3),
keep_probability=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "random",
...
)
Sobol
Sobol is een type willekeurige steekproeven dat wordt ondersteund door het opruimen van taaktypen. U kunt sobol gebruiken om uw resultaten te reproduceren met behulp van seed en de verdeling van de zoekruimte gelijkmatiger te bedekken.
Als u sobol wilt gebruiken, gebruikt u de klasse RandomParameterSampling om de seed en regel toe te voegen, zoals wordt weergegeven in het onderstaande voorbeeld.
from azure.ai.ml.sweep import RandomParameterSampling
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = RandomParameterSampling(seed=123, rule="sobol"),
...
)
Rastersampling
Rastersampling ondersteunt discrete hyperparameters. Gebruik rastersampling als u kunt budgetteren om uitgebreid te zoeken in de zoekruimte. Ondersteunt vroegtijdige beëindiging van taken met lage prestaties.
Rastersampling voert een eenvoudige rasterzoekopdracht uit op alle mogelijke waarden. Rastersampling kan alleen worden gebruikt met choice hyperparameters. De volgende ruimte bevat bijvoorbeeld zes voorbeelden:
from azure.ai.ml.sweep import Choice
command_job_for_sweep = command_job(
batch_size=Choice(values=[16, 32]),
number_of_hidden_layers=Choice(values=[1,2,3]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "grid",
...
)
Bayesiaanse steekproeven
Bayesiaanse steekproeven zijn gebaseerd op het Bayesian-optimalisatie-algoritme. Er worden voorbeelden gekozen op basis van hoe eerdere voorbeelden dat deden, zodat nieuwe voorbeelden de primaire metrische gegevens verbeteren.
Bayesiaanse sampling wordt aanbevolen als u voldoende budget hebt om de hyperparameterruimte te verkennen. Voor de beste resultaten raden we een maximum aantal taken aan dat groter is dan of gelijk is aan 20 keer het aantal hyperparameters dat wordt afgestemd.
Het aantal gelijktijdige taken heeft invloed op de effectiviteit van het afstemmingsproces. Een kleiner aantal gelijktijdige taken kan leiden tot een betere convergentie van steekproeven, omdat door een kleinere mate van parallelle uitvoering het aantal taken dat profiteert van eerder voltooide taken toeneemt.
Bayesian sampling ondersteunt choicealleen distributies , uniformen quniform over de zoekruimte.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
...
)
Het doel van de sweep opgeven
Definieer het doel van uw sweep-taak door het primaire metrische gegevens en doel op te geven dat hyperparameterafstemming moet worden geoptimaliseerd. Elke trainingstaak wordt geëvalueerd voor de primaire metrische waarde. Het beleid voor vroegtijdige beëindiging maakt gebruik van de primaire metrische gegevens om taken met lage prestaties te identificeren.
primary_metric: de naam van de primaire metrische waarde moet exact overeenkomen met de naam van de metrische gegevens die zijn vastgelegd door het trainingsscriptgoal: dit kan ofMaximizeMinimizezijn en bepaalt of de primaire metrische waarde wordt gemaximaliseerd of geminimaliseerd bij het evalueren van de taken.
from azure.ai.ml.sweep import Uniform, Choice
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.05, max_value=0.1),
batch_size=Choice(values=[16, 32, 64, 128]),
)
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm = "bayesian",
primary_metric="accuracy",
goal="Maximize",
)
In dit voorbeeld wordt de nauwkeurigheid gemaximaliseerd.
Metrische logboekgegevens voor het afstemmen van hyperparameters
Het trainingsscript voor uw model moet de primaire metrische gegevens registreren tijdens het trainen van het model met dezelfde bijbehorende metrische naam, zodat de SweepJob er toegang toe heeft voor het afstemmen van de hyperparameter.
Registreer de primaire metrische gegevens in uw trainingsscript met het volgende voorbeeldfragment:
import mlflow
mlflow.log_metric("accuracy", float(val_accuracy))
Het trainingsscript berekent de val_accuracy en registreert deze als de primaire metrische waarde 'nauwkeurigheid'. Telkens wanneer de metrische waarde wordt geregistreerd, wordt deze ontvangen door de hyperparameter-afstemmingsservice. Het is aan u om de frequentie van de rapportage te bepalen.
Zie Logboekregistratie in Azure Machine Learning-trainingstaken inschakelen voor meer informatie over het vastleggen van waarden voor trainingstaken.
Beleid voor vroegtijdige beëindiging opgeven
Automatisch slecht presterende taken beëindigen met een beleid voor vroegtijdige beëindiging. Vroegtijdige beëindiging verbetert de rekenefficiëntie.
U kunt de volgende parameters configureren die bepalen wanneer een beleid wordt toegepast:
evaluation_interval: de frequentie van het toepassen van het beleid. Telkens wanneer het trainingsscript registreert, wordt de primaire metrische waarde als één interval geteld. Eenevaluation_intervalvan 1 past het beleid toe telkens wanneer het trainingsscript de primaire metrische gegevens rapporteert. Eenevaluation_intervalvan 2 past het beleid elke andere keer toe. Als dit niet is opgegeven,evaluation_intervalis standaard ingesteld op 0.delay_evaluation: vertraagt de eerste beleidsevaluatie met een opgegeven aantal intervallen. Dit is een optionele parameter die voortijdige beëindiging van trainingstaken voorkomt door toe te staan dat alle configuraties gedurende een minimum aantal intervallen worden uitgevoerd. Indien opgegeven, wordt het beleid toegepast op elk veelvoud van evaluation_interval dat groter is dan of gelijk is aan delay_evaluation. Als dit niet is opgegeven,delay_evaluationis standaard ingesteld op 0.
Azure Machine Learning ondersteunt het volgende beleid voor vroegtijdige beëindiging:
Bandit-beleid
Bandit-beleid is gebaseerd op de margefactor/margehoeveelheid en evaluatie-interval. Bandit-beleid beëindigt een taak wanneer de primaire metrische waarde zich niet binnen de opgegeven margefactor/margehoeveelheid van de meest geslaagde taak bevindt.
Geef de volgende configuratieparameters op:
slack_factorofslack_amount: de toegestane marge met betrekking tot de best presterende trainingstaak.slack_factorgeeft de toegestane marge op als een verhouding.slack_amounthiermee geeft u de toegestane marge op als een absoluut bedrag in plaats van een verhouding.Overweeg bijvoorbeeld een Bandit-beleid dat is toegepast met interval 10. Stel dat de best presterende taak met interval 10 een primaire metrische waarde 0,8 is met het doel om het primaire metrische gegeven te maximaliseren. Als het beleid een
slack_factorvan 0,2 opgeeft, worden alle trainingstaken waarvan de beste metrische waarde op interval 10 kleiner is dan 0,66 (0,8/(1+slack_factor)) beëindigd.evaluation_interval: (optioneel) de frequentie voor het toepassen van het beleiddelay_evaluation: (optioneel) vertraagt de eerste beleidsevaluatie met een opgegeven aantal intervallen
from azure.ai.ml.sweep import BanditPolicy
sweep_job.early_termination = BanditPolicy(slack_factor = 0.1, delay_evaluation = 5, evaluation_interval = 1)
In dit voorbeeld wordt het beleid voor vroegtijdige beëindiging toegepast op elk interval wanneer metrische gegevens worden gerapporteerd, te beginnen bij evaluatie-interval 5. Alle taken waarvan de beste metrische gegevens kleiner zijn dan (1/(1+0.1) of 91% van de best presterende taken, worden beëindigd.
Beleid voor mediaan stoppen
Mediaan stoppen is een beleid voor vroegtijdige beëindiging op basis van actieve gemiddelden van primaire metrische gegevens die door de taken worden gerapporteerd. Dit beleid berekent lopende gemiddelden voor alle trainingstaken en stopt taken waarvan de primaire metrische waarde slechter is dan de mediaan van de gemiddelden.
Voor dit beleid worden de volgende configuratieparameters gebruikt:
evaluation_interval: de frequentie voor het toepassen van het beleid (optionele parameter).delay_evaluation: vertraagt de eerste beleidsevaluatie voor een opgegeven aantal intervallen (optionele parameter).
from azure.ai.ml.sweep import MedianStoppingPolicy
sweep_job.early_termination = MedianStoppingPolicy(delay_evaluation = 5, evaluation_interval = 1)
In dit voorbeeld wordt het beleid voor vroegtijdige beëindiging toegepast op elk interval vanaf evaluatie-interval 5. Een taak wordt gestopt bij interval 5 als de beste primaire metrische waarde slechter is dan de mediaan van de lopende gemiddelden over intervallen van 1:5 voor alle trainingstaken.
Selectiebeleid voor afkapping
Met afkappingsselectie wordt een percentage van de taken met de laagste prestaties bij elk evaluatie-interval geannuleerd. taken worden vergeleken met behulp van het primaire metrische gegeven.
Voor dit beleid worden de volgende configuratieparameters gebruikt:
truncation_percentage: het percentage taken dat het minst presteert dat moet worden beëindigd bij elk evaluatie-interval. Een geheel getal tussen 1 en 99.evaluation_interval: (optioneel) de frequentie voor het toepassen van het beleiddelay_evaluation: (optioneel) vertraagt de eerste beleidsevaluatie met een opgegeven aantal intervallenexclude_finished_jobs: geeft aan of voltooide taken moeten worden uitgesloten bij het toepassen van het beleid
from azure.ai.ml.sweep import TruncationSelectionPolicy
sweep_job.early_termination = TruncationSelectionPolicy(evaluation_interval=1, truncation_percentage=20, delay_evaluation=5, exclude_finished_jobs=true)
In dit voorbeeld wordt het beleid voor vroegtijdige beëindiging toegepast op elk interval vanaf evaluatie-interval 5. Een taak eindigt bij interval 5 als de prestaties met interval 5 de laagste 20% van de prestaties van alle taken zijn met interval 5 en worden voltooide taken uitgesloten bij het toepassen van het beleid.
Geen beëindigingsbeleid (standaard)
Als er geen beleid is opgegeven, kan de hyperparameter-afstemmingsservice alle trainingstaken uitvoeren tot voltooiing.
sweep_job.early_termination = None
Een beleid voor vroegtijdige beëindiging kiezen
- Voor een conservatief beleid dat besparingen biedt zonder veelbelovende banen te beëindigen, kunt u een mediaan stoppen-beleid met
evaluation_interval1 endelay_evaluation5 overwegen. Dit zijn conservatieve instellingen die ongeveer 25%-35% besparingen kunnen bieden zonder verlies op primaire metrische gegevens (op basis van onze evaluatiegegevens). - Voor meer agressieve besparingen gebruikt u Bandit-beleid met een kleinere toegestane marge of afkappingsselectiebeleid met een groter afkappingspercentage.
Limieten instellen voor uw sweep-taak
Beheer uw resourcebudget door limieten in te stellen voor uw sweep-taak.
max_total_trials: Maximum aantal proeftaken. Moet een geheel getal tussen 1 en 1000 zijn.max_concurrent_trials: (optioneel) Maximum aantal proeftaken dat gelijktijdig kan worden uitgevoerd. Als dit niet is opgegeven, max_total_trials aantal taken parallel worden gestart. Indien opgegeven, moet een geheel getal tussen 1 en 1000 zijn.timeout: De maximale tijd in seconden dat de volledige sweep-taak mag worden uitgevoerd. Zodra deze limiet is bereikt, annuleert het systeem de sweep-taak, inclusief alle proefversies.trial_timeout: De maximale tijd in seconden die elke proeftaak mag worden uitgevoerd. Zodra deze limiet is bereikt, annuleert het systeem de proefversie.
Notitie
Als zowel max_total_trials als time-out zijn opgegeven, wordt het hyperparameterafstemmingsexperiment beëindigd wanneer de eerste van deze twee drempelwaarden wordt bereikt.
Notitie
Het aantal gelijktijdige proeftaken is afhankelijk van de resources die beschikbaar zijn in het opgegeven rekendoel. Zorg ervoor dat het rekendoel de beschikbare resources heeft voor de gewenste gelijktijdigheid.
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=4, timeout=1200)
Met deze code configureert u het hyperparameter-afstemmingsexperiment om maximaal 20 totale proeftaken te gebruiken, waarbij vier proeftaken tegelijk worden uitgevoerd met een time-out van 1200 seconden voor de volledige sweep-taak.
Experiment voor het afstemmen van hyperparameters configureren
Geef het volgende op om uw experiment voor hyperparameterafstemming te configureren:
- De gedefinieerde zoekruimte voor hyperparameters
- Uw sampling-algoritme
- Uw beleid voor vroegtijdige beëindiging
- Uw doelstelling
- Bronlimieten
- CommandJob of CommandComponent
- SweepJob
SweepJob kan een hyperparameter-sweep uitvoeren op het opdracht- of opdrachtonderdeel.
Notitie
Het rekendoel dat in wordt gebruikt, sweep_job moet voldoende resources hebben om te voldoen aan uw gelijktijdigheidsniveau. Zie Rekendoelen voor meer informatie over rekendoelen.
Configureer uw hyperparameter-afstemmingsexperiment:
from azure.ai.ml import MLClient
from azure.ai.ml import command, Input
from azure.ai.ml.sweep import Choice, Uniform, MedianStoppingPolicy
from azure.identity import DefaultAzureCredential
# Create your base command job
command_job = command(
code="./src",
command="python main.py --iris-csv ${{inputs.iris_csv}} --learning-rate ${{inputs.learning_rate}} --boosting ${{inputs.boosting}}",
environment="AzureML-lightgbm-3.2-ubuntu18.04-py37-cpu@latest",
inputs={
"iris_csv": Input(
type="uri_file",
path="https://azuremlexamples.blob.core.windows.net/datasets/iris.csv",
),
"learning_rate": 0.9,
"boosting": "gbdt",
},
compute="cpu-cluster",
)
# Override your inputs with parameter expressions
command_job_for_sweep = command_job(
learning_rate=Uniform(min_value=0.01, max_value=0.9),
boosting=Choice(values=["gbdt", "dart"]),
)
# Call sweep() on your command job to sweep over your parameter expressions
sweep_job = command_job_for_sweep.sweep(
compute="cpu-cluster",
sampling_algorithm="random",
primary_metric="test-multi_logloss",
goal="Minimize",
)
# Specify your experiment details
sweep_job.display_name = "lightgbm-iris-sweep-example"
sweep_job.experiment_name = "lightgbm-iris-sweep-example"
sweep_job.description = "Run a hyperparameter sweep job for LightGBM on Iris dataset."
# Define the limits for this sweep
sweep_job.set_limits(max_total_trials=20, max_concurrent_trials=10, timeout=7200)
# Set early stopping on this one
sweep_job.early_termination = MedianStoppingPolicy(
delay_evaluation=5, evaluation_interval=2
)
De command_job wordt aangeroepen als een functie, zodat we de parameterexpressies kunnen toepassen op de sweep-invoer. De sweep functie wordt vervolgens geconfigureerd met trial, sampling-algorithm, objective, limitsen compute. Het bovenstaande codefragment is afkomstig uit het voorbeeldnotebook Hyperparameter sweep uitvoeren op een opdracht of CommandComponent. In dit voorbeeld worden de learning_rate parameters en boosting afgestemd. Het vroegtijdig stoppen van taken wordt bepaald door een MedianStoppingPolicy, waarmee een taak wordt gestopt waarvan de primaire metrische waarde slechter is dan de mediaan van de gemiddelden voor alle trainingstaken. ( zie Naslaginformatie over de klasse MedianStoppingPolicy).
Raadpleeg dit codevoorbeeld om te zien hoe de parameterwaarden worden ontvangen, geparseerd en doorgegeven aan het trainingsscript dat moet worden afgestemd
Belangrijk
Met elke hyperparameter-sweeptaak wordt de training opnieuw gestart, inclusief het opnieuw bouwen van het model en alle gegevensladers. U kunt deze kosten minimaliseren door een Azure Machine Learning-pijplijn of handmatig proces te gebruiken om zoveel mogelijk gegevensvoorbereiding uit te voeren voorafgaand aan uw trainingstaken.
Experiment voor het afstemmen van hyperparameters verzenden
Nadat u de configuratie voor het afstemmen van de hyperparameter hebt gedefinieerd, verzendt u de taak:
# submit the sweep
returned_sweep_job = ml_client.create_or_update(sweep_job)
# get a URL for the status of the job
returned_sweep_job.services["Studio"].endpoint
Afstemmingstaken voor hyperparameters visualiseren
U kunt al uw hyperparameterafstemmingstaken visualiseren in de Azure Machine Learning-studio. Zie Taakrecords weergeven in de studio voor meer informatie over het weergeven van een experiment in de portal.
Grafiek met metrische gegevens: deze visualisatie houdt de metrische gegevens bij die zijn vastgelegd voor elke onderliggende hyperdrive-taak gedurende de duur van het afstemmen van de hyperparameter. Elke regel vertegenwoordigt een onderliggende taak en elk punt meet de primaire metrische waarde op die herhaling van runtime.

Parallelcoördinaatdiagram: deze visualisatie toont de correlatie tussen primaire metrische prestaties en afzonderlijke hyperparameterwaarden. De grafiek is interactief via het verplaatsen van assen (klikken en slepen met het aslabel) en door waarden over één as te markeren (klik en sleep verticaal langs één as om een bereik met gewenste waarden te markeren). Het parallelle coördinatendiagram bevat een as op het meest rechtse gedeelte van de grafiek waarmee de beste metrische waarde wordt uitgezet die overeenkomt met de hyperparameters die voor dat taakexemplaar zijn ingesteld. Deze as wordt geleverd om de legenda van de grafiekovergang op een beter leesbare manier op de gegevens te projecteert.
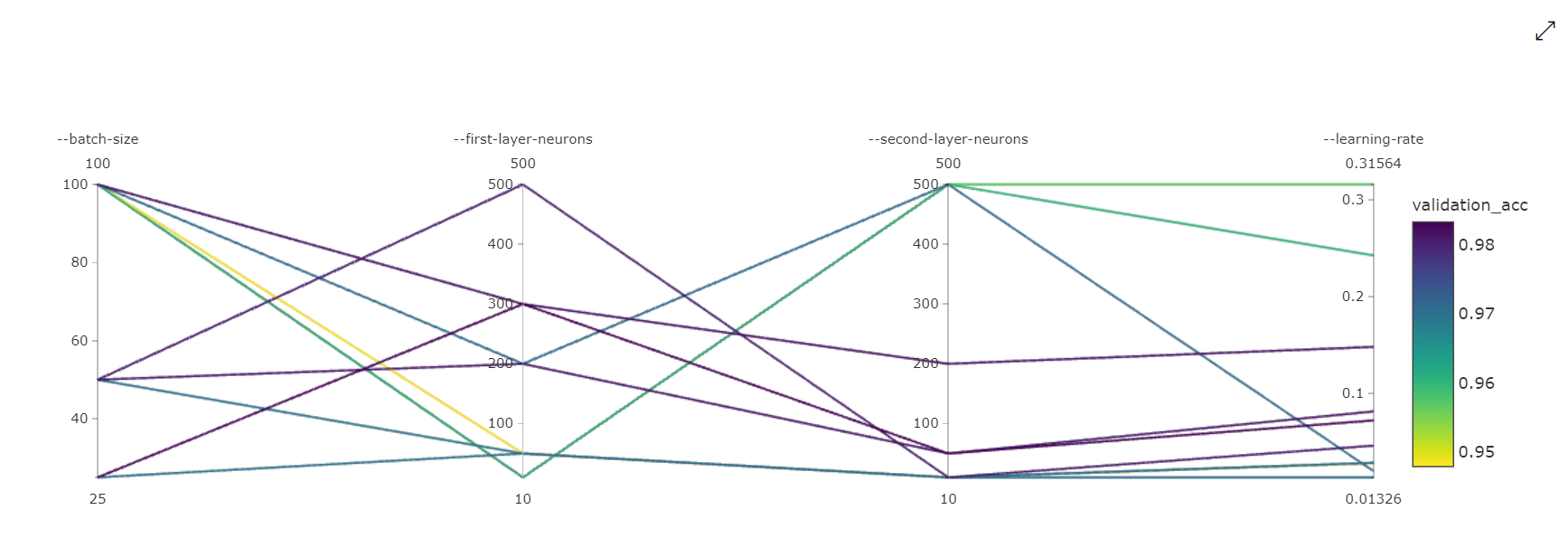
2-dimensionale spreidingsdiagram: deze visualisatie toont de correlatie tussen twee afzonderlijke hyperparameters, samen met de bijbehorende primaire metrische waarde.
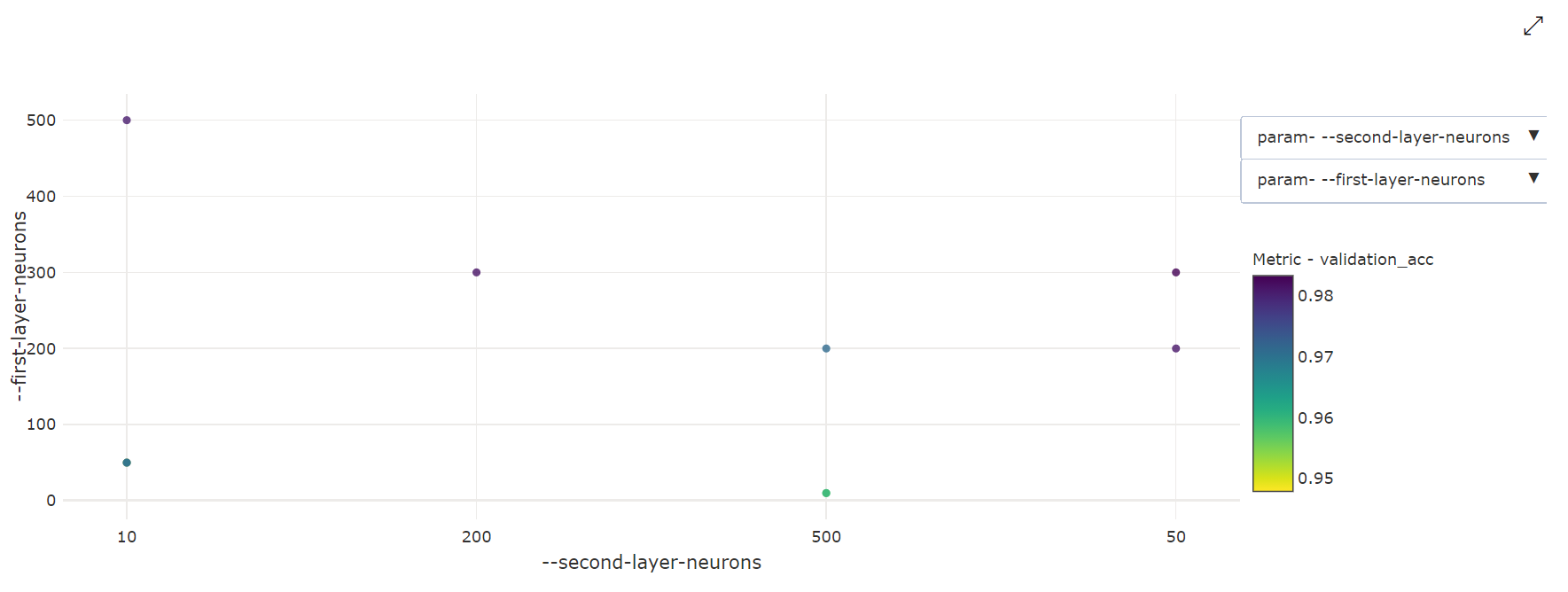
3-dimensionale spreidingsdiagram: Deze visualisatie is hetzelfde als 2D, maar biedt drie hyperparameterdimensies van correlatie met de primaire metrische waarde. U kunt ook klikken en slepen om de grafiek te heroriënteren om verschillende correlaties in 3D-ruimte weer te geven.

De beste proeftaak vinden
Zodra alle afstemmingstaken voor hyperparameters zijn voltooid, haalt u de beste proefuitvoer op:
# Download best trial model output
ml_client.jobs.download(returned_sweep_job.name, output_name="model")
U kunt de CLI gebruiken om alle standaard- en benoemde uitvoer van de beste proeftaak en logboeken van de sweep-taak te downloaden.
az ml job download --name <sweep-job> --all
Optioneel, om alleen de beste proefuitvoer te downloaden
az ml job download --name <sweep-job> --output-name model