Interactieve gegevens Wrangling met Apache Spark in Azure Machine Learning
Gegevens wrangling wordt een van de belangrijkste stappen in machine learning-projecten. De Integratie van Azure Machine Learning met Azure Synapse Analytics biedt toegang tot een Apache Spark-pool, ondersteund door Azure Synapse, voor interactieve gegevens die gebruikmaken van Azure Machine Learning Notebooks.
In dit artikel leert u hoe u gegevens wrangling uitvoert met behulp van
- Serverloze Spark-rekenkracht
- Gekoppelde Synapse Spark-pool
Vereisten
- Een Azure-abonnement; Als u geen Azure-abonnement hebt, maakt u een gratis account voordat u begint.
- Een Azure Machine Learning-werkruimte. Zie Werkruimtebronnen maken.
- Een Azure Data Lake Storage -opslagaccount (ADLS) Gen 2. Zie Een Azure Data Lake Storage-opslagaccount (ADLS) Gen 2 maken.
- (Optioneel): Een Azure Key Vault. Zie Een Azure Key Vault maken.
- (Optioneel): een service-principal. Zie Een service-principal maken.
- (Optioneel): Een gekoppelde Synapse Spark-pool in de Azure Machine Learning-werkruimte.
Voordat u begint met het wrangling-taken van uw gegevens, leert u meer over het proces voor het opslaan van geheimen
- Toegangssleutel voor Azure Blob Storage-account
- SAS-token (Shared Access Signature)
- Informatie over azure Data Lake Storage (ADLS) Gen 2-service-principal
in Azure Key Vault. U moet ook weten hoe u roltoewijzingen kunt afhandelen in de Azure-opslagaccounts. In de volgende secties worden deze concepten besproken. Vervolgens verkennen we de details van interactieve gegevens die worden gebruikt met behulp van de Spark-pools in Azure Machine Learning Notebooks.
Tip
Zie Roltoewijzingen toevoegen in Azure-opslagaccounts voor meer informatie over de configuratie van roltoewijzing van azure-opslagaccounts of als u toegang hebt tot gegevens in uw opslagaccounts met behulp van passthrough voor gebruikersidentiteit.
Interactieve gegevens Wrangling met Apache Spark
Azure Machine Learning biedt serverloze Spark-rekenkracht en gekoppelde Synapse Spark-pool voor interactieve gegevens met Apache Spark in Azure Machine Learning Notebooks. Voor serverloze Spark-rekenkracht is het maken van resources in de Azure Synapse-werkruimte niet vereist. In plaats daarvan wordt een volledig beheerde serverloze Spark-berekening direct beschikbaar in de Azure Machine Learning Notebooks. Het gebruik van een serverloze Spark-berekening is de eenvoudigste manier om toegang te krijgen tot een Spark-cluster in Azure Machine Learning.
Serverloze Spark-rekenkracht in Azure Machine Learning Notebooks
Een serverloze Spark-berekening is standaard beschikbaar in Azure Machine Learning Notebooks. Als u toegang wilt krijgen tot spark in een notebook, selecteert u Serverloze Spark onder Serverloze Spark van Azure Machine Learning in het menu Compute-selectie .
De gebruikersinterface van notebooks biedt ook opties voor spark-sessieconfiguratie, voor serverloze Spark-berekeningen. Een Spark-sessie configureren:
- Selecteer Sessie configureren boven aan het scherm.
- Selecteer de Apache Spark-versie in de vervolgkeuzelijst.
Belangrijk
Azure Synapse Runtime voor Apache Spark: aankondigingen
- Azure Synapse Runtime voor Apache Spark 3.2:
- EOLA Aankondigingsdatum: 8 juli 2023
- Einddatum van ondersteuning: 8 juli 2024. Na deze datum wordt de runtime uitgeschakeld.
- Voor continue ondersteuning en optimale prestaties raden we u aan om te migreren naar Apache Spark 3.3.
- Azure Synapse Runtime voor Apache Spark 3.2:
- Selecteer Exemplaartype in de vervolgkeuzelijst. De volgende exemplaartypen worden momenteel ondersteund:
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
- Voer een time-outwaarde voor een Spark-sessie in minuten in.
- Selecteren of uitvoerders dynamisch moeten worden toegewezen
- Selecteer het aantal uitvoerders voor de Spark-sessie.
- Selecteer De grootte van de uitvoerder in de vervolgkeuzelijst.
- Selecteer De grootte van het stuurprogramma in de vervolgkeuzelijst.
- Als u een Conda-bestand wilt gebruiken om een Spark-sessie te configureren, schakelt u het selectievakje Conda-bestand uploaden in. Selecteer Vervolgens Bladeren en kies het Conda-bestand met de gewenste Spark-sessieconfiguratie.
- Voeg eigenschappen van configuratie-instellingen , invoerwaarden toe in de tekstvakken Eigenschap en Waarde en selecteer Toevoegen.
- Selecteer Toepassen.
- Selecteer Sessie stoppen in het pop-upvenster Nieuwe sessie configureren.
De wijzigingen in de sessieconfiguratie blijven behouden en worden beschikbaar voor een andere notebooksessie die is gestart met het serverloze Spark-rekenproces.
Tip
Als u Conda-pakketten op sessieniveau gebruikt, kunt u de koude begintijd van de Spark-sessie verbeteren als u de configuratievariabele spark.hadoop.aml.enable_cache instelt op waar. Een sessie koud starten met Conda-pakketten op sessieniveau duurt doorgaans 10 tot 15 minuten wanneer de sessie voor het eerst wordt gestart. De volgende sessie koud begint echter met de configuratievariabele die is ingesteld op waar, duurt doorgaans drie tot vijf minuten.
Gegevens importeren en wrangle uit Azure Data Lake Storage (ADLS) Gen 2
U kunt gegevens die zijn opgeslagen in Azure Data Lake Storage (ADLS) Gen 2-opslagaccounts abfss:// met gegevens-URI's, openen en wrangleen volgens een van de twee mechanismen voor gegevenstoegang:
- Passthrough voor gebruikersidentiteit
- Gegevenstoegang op basis van service-principal
Tip
Voor gegevens die worden gebruikt met een serverloze Spark-berekening en passthrough voor gebruikersidentiteit voor toegang tot gegevens in een Azure Data Lake Storage -opslagaccount (ADLS) Gen 2, is het kleinste aantal configuratiestappen vereist.
Interactieve gegevens starten met de passthrough van de gebruikersidentiteit:
Controleer of de gebruikersidentiteit roltoewijzingen Inzender en Opslagblobgegevens heeft in het Azure Data Lake Storage -opslagaccount (ADLS) Gen 2.
Als u de serverloze Spark-berekening wilt gebruiken, selecteert u Serverloze Spark Compute onder Serverloze Spark van Azure Machine Learning in het menu Compute-selectie .
Als u een gekoppelde Synapse Spark-pool wilt gebruiken, selecteert u een gekoppelde Synapse Spark-pool onder Synapse Spark-pools in het menu Compute-selectie .
Dit Titanic-codevoorbeeld toont het gebruik van een gegevens-URI in indeling
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>metpyspark.pandasenpyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled", index_col="PassengerId", )Notitie
In dit Python-codevoorbeeld wordt gebruikgemaakt van
pyspark.pandas. Alleen de Spark Runtime-versie 3.2 of hoger ondersteunt dit.
Gegevens wrangleen op basis van toegang via een service-principal:
Controleer of de service-principal roltoewijzingen Inzender en Opslagblobgegevens heeft in het Azure Data Lake Storage-opslagaccount (ADLS) Gen 2.
Maak Azure Key Vault-geheimen voor de tenant-id, client-id en clientgeheimwaarden voor de service-principal.
Selecteer Serverloze Spark-berekening onder Serverloze Spark van Azure Machine Learning in het menu Compute-selectie of selecteer een gekoppelde Synapse Spark-pool onder Synapse Spark-pools in het menu Compute-selectie .
Als u de tenant-id, client-id en clientgeheim van de service-principal in de configuratie wilt instellen en het volgende codevoorbeeld wilt uitvoeren.
De
get_secret()aanroep van de code is afhankelijk van de naam van de Azure Key Vault en de namen van de Azure Key Vault-geheimen die zijn gemaakt voor de tenant-id van de service-principal, client-id en clientgeheim. Stel deze bijbehorende eigenschapsnaam/-waarden in de configuratie in:- Eigenschap Client-id:
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Eigenschap clientgeheim:
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Eigenschap Tenant-id:
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Tenant-id-waarde:
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary # Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>") # Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set( "fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_id, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_secret, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", )- Eigenschap Client-id:
Importeer en wrangle gegevens met behulp van gegevens-URI in indeling
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>, zoals wordt weergegeven in het codevoorbeeld, met behulp van de Titanic-gegevens.
Gegevens importeren en wrangle uit Azure Blob Storage
U hebt toegang tot Azure Blob Storage-gegevens met de toegangssleutel van het opslagaccount of een SAS-token (Shared Access Signature). U moet deze referenties opslaan in Azure Key Vault als geheim en deze instellen als eigenschappen in de sessieconfiguratie.
Interactieve gegevens wrangling starten:
Selecteer Notitieblokken in het linkerdeelvenster Azure Machine Learning-studio.
Selecteer Serverloze Spark-berekening onder Serverloze Spark van Azure Machine Learning in het menu Compute-selectie of selecteer een gekoppelde Synapse Spark-pool onder Synapse Spark-pools in het menu Compute-selectie .
De toegangssleutel van het opslagaccount of een SAS-token (Shared Access Signature) configureren voor gegevenstoegang in Azure Machine Learning Notebooks:
Stel voor de toegangssleutel de eigenschap
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netin zoals wordt weergegeven in dit codefragment:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key )Stel voor het SAS-token de eigenschap
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netin zoals wordt weergegeven in dit codefragment:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", sas_token, )Notitie
Voor
get_secret()de aanroepen in de bovenstaande codefragmenten is de naam van de Azure Key Vault vereist en de namen van de geheimen die zijn gemaakt voor de toegangssleutel of het SAS-token van het Azure Blob Storage-account
Voer de gegevens wrangling-code uit in hetzelfde notebook. Maak de gegevens-URI op als , vergelijkbaar met
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>wat in dit codefragment wordt weergegeven:import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled", index_col="PassengerId", )Notitie
In dit Python-codevoorbeeld wordt gebruikgemaakt van
pyspark.pandas. Alleen de Spark Runtime-versie 3.2 of hoger ondersteunt dit.
Gegevens importeren en wrangle uit Azure Machine Learning-gegevensarchief
Als u toegang wilt krijgen tot gegevens uit Azure Machine Learning DataStore, definieert u een pad naar gegevens in het gegevensarchief met een URI-indelingazureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA>. Gegevens uit een Azure Machine Learning-gegevensarchief in een Notebooks-sessie interactief weergeven:
Selecteer Serverloze Spark-berekening onder Serverloze Spark van Azure Machine Learning in het menu Compute-selectie of selecteer een gekoppelde Synapse Spark-pool onder Synapse Spark-pools in het menu Compute-selectie .
In dit codevoorbeeld ziet u hoe u Gegevens uit een Azure Machine Learning-gegevensarchief kunt lezen en wrangle uit een Azure Machine Learning-gegevensarchief, met behulp van
azureml://de URIpyspark.pandasvoor gegevensopslag enpyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "azureml://datastores/workspaceblobstore/paths/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "azureml://datastores/workspaceblobstore/paths/data/wrangled", index_col="PassengerId", )Notitie
In dit Python-codevoorbeeld wordt gebruikgemaakt van
pyspark.pandas. Alleen de Spark Runtime-versie 3.2 of hoger ondersteunt dit.
De Azure Machine Learning-gegevensarchieven hebben toegang tot gegevens met behulp van azure-opslagaccountreferenties
- toegangssleutel
- SAS-token
- service-principal
of geef referentiesloze gegevenstoegang op. Afhankelijk van het gegevensarchieftype en het onderliggende azure-opslagaccounttype, selecteert u een geschikt verificatiemechanisme om gegevenstoegang te garanderen. Deze tabel bevat een overzicht van de verificatiemechanismen voor toegang tot gegevens in de Azure Machine Learning-gegevensarchieven:
| Storage account type | Gegevenstoegang met minder referenties | Mechanisme voor gegevenstoegang | Roltoewijzingen |
|---|---|---|---|
| Azure Blob | Nee | Toegangssleutel of SAS-token | Er zijn geen roltoewijzingen nodig |
| Azure Blob | Ja | Passthrough voor gebruikersidentiteit* | Gebruikersidentiteit moet de juiste roltoewijzingen hebben in het Azure Blob Storage-account |
| Azure Data Lake Storage (ADLS) Gen 2 | Nee | Service-principal | Service-principal moet de juiste roltoewijzingen hebben in het Azure Data Lake Storage -opslagaccount (ADLS) Gen 2 |
| Azure Data Lake Storage (ADLS) Gen 2 | Ja | Passthrough voor gebruikersidentiteit | Gebruikersidentiteit moet de juiste roltoewijzingen hebben in het Azure Data Lake Storage -opslagaccount (ADLS) Gen 2 |
* Passthrough voor gebruikersidentiteiten werkt voor gegevensarchieven zonder referenties die verwijzen naar Azure Blob Storage-accounts, alleen als voorlopig verwijderen niet is ingeschakeld.
Toegang tot gegevens op de standaardbestandsshare
De standaardbestandsshare is gekoppeld aan serverloze Spark-rekenkracht en gekoppelde Synapse Spark-pools.
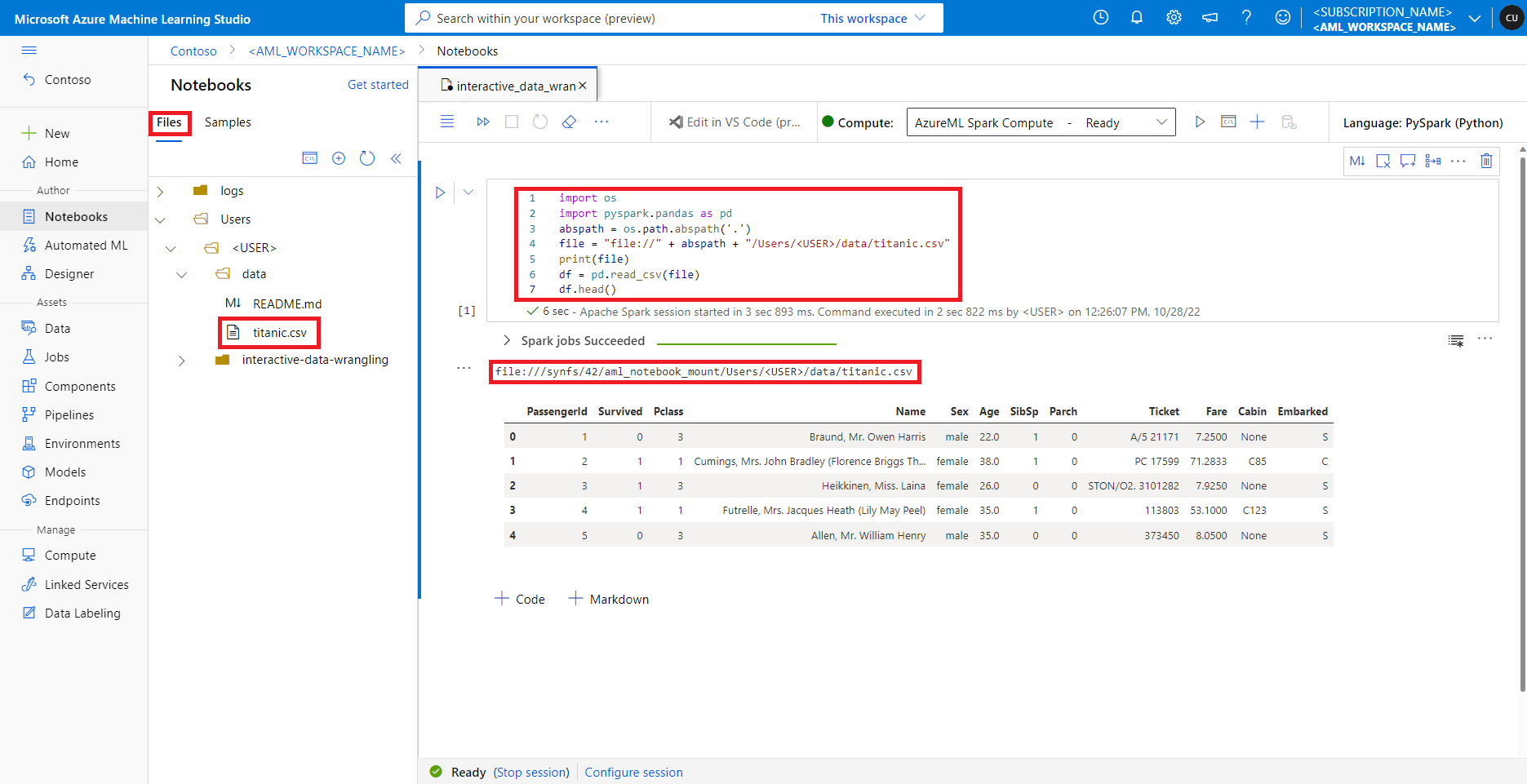
In Azure Machine Learning-studio worden bestanden in de standaardbestandsshare weergegeven in de mapstructuur op het tabblad Bestanden. Notitieblokcode heeft rechtstreeks toegang tot bestanden die zijn opgeslagen in deze bestandsshare met file:// protocol, samen met het absolute pad van het bestand, zonder meer configuraties. Dit codefragment laat zien hoe u toegang hebt tot een bestand dat is opgeslagen op de standaardbestandsshare:
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
abspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(
inputCols=["Age"],
outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
Notitie
In dit Python-codevoorbeeld wordt gebruikgemaakt van pyspark.pandas. Alleen de Spark Runtime-versie 3.2 of hoger ondersteunt dit.