Een model implementeren als een online-eindpunt
VAN TOEPASSING OP: Python SDK azure-ai-ml v2 (actueel)
Python SDK azure-ai-ml v2 (actueel)
Leer hoe u een model implementeert op een online-eindpunt met behulp van Azure Machine Learning Python SDK v2.
In deze zelfstudie implementeert en gebruikt u een model waarmee de kans wordt voorspeld dat een klant standaard een creditcardbetaling gebruikt.
De stappen die u uitvoert, zijn:
- Uw model registreren
- Een eindpunt en een eerste implementatie maken
- Een proefversie implementeren
- Testgegevens handmatig verzenden naar de implementatie
- Details van de implementatie ophalen
- Een tweede implementatie maken
- De tweede implementatie handmatig schalen
- Toewijzing van productieverkeer tussen beide implementaties bijwerken
- Details van de tweede implementatie ophalen
- De nieuwe implementatie implementeren en de eerste implementatie verwijderen
In deze video ziet u hoe u aan de slag gaat in Azure Machine Learning-studio, zodat u de stappen in de zelfstudie kunt volgen. In de video ziet u hoe u een notebook maakt, een rekenproces maakt en het notebook kloont. De stappen worden ook beschreven in de volgende secties.
Vereisten
-
Als u Azure Machine Learning wilt gebruiken, hebt u eerst een werkruimte nodig. Als u er nog geen hebt, voltooit u Resources maken die u nodig hebt om aan de slag te gaan met het maken van een werkruimte en meer informatie over het gebruik ervan.
-
Meld u aan bij de studio en selecteer uw werkruimte als deze nog niet is geopend.
-
Open of maak een notitieblok in uw werkruimte:
- Maak een nieuw notitieblok als u code wilt kopiëren/plakken in cellen.
- Of open zelfstudies/get-started-notebooks/deploy-model.ipynb vanuit de sectie Samples van de studio. Selecteer Vervolgens Klonen om het notitieblok toe te voegen aan uw bestanden. (Zie waar u voorbeelden kunt vinden.)
Bekijk uw VM-quotum en zorg ervoor dat er voldoende quota beschikbaar zijn om online implementaties te maken. In deze zelfstudie hebt u ten minste 8 kernen van
STANDARD_DS3_v2en 12 kernen vanSTANDARD_F4s_v2nodig. Zie Resourcequota beheren om het quotumgebruik van uw VM weer te geven en quotumverhogingen aan te vragen.
Uw kernel instellen
Maak op de bovenste balk boven het geopende notitieblok een rekenproces als u er nog geen hebt.

Als het rekenproces is gestopt, selecteert u Rekenproces starten en wacht u totdat het wordt uitgevoerd.

Zorg ervoor dat de kernel, die zich rechtsboven bevindt, is
Python 3.10 - SDK v2. Als dit niet het probleem is, gebruikt u de vervolgkeuzelijst om deze kernel te selecteren.
Als u een banner ziet met de melding dat u moet worden geverifieerd, selecteert u Verifiëren.



Belangrijk
De rest van deze zelfstudie bevat cellen van het zelfstudienotitieblok. Kopieer of plak deze in uw nieuwe notitieblok of ga nu naar het notitieblok als u het hebt gekloond.
Notitie
- Serverloze Spark Compute is niet
Python 3.10 - SDK v2standaard geïnstalleerd. We raden gebruikers aan een rekenproces te maken en deze te selecteren voordat ze verdergaan met de zelfstudie.
Greep maken voor werkruimte
Voordat u in de code duikt, hebt u een manier nodig om naar uw werkruimte te verwijzen. Maak ml_client een ingang voor de werkruimte en gebruik de ml_client werkruimte om resources en taken te beheren.
Voer in de volgende cel uw abonnements-id, resourcegroepnaam en werkruimtenaam in. Deze waarden zoeken:
- Selecteer in de rechterbovenhoek Azure Machine Learning-studio werkbalk de naam van uw werkruimte.
- Kopieer de waarde voor werkruimte, resourcegroep en abonnements-id naar de code.
- U moet één waarde kopiëren, het gebied sluiten en plakken en vervolgens terugkomen voor de volgende waarde.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Notitie
Het maken maakt MLClient geen verbinding met de werkruimte. De initialisatie van de client is lui en wacht tot de eerste keer dat deze een aanroep moet doen (dit gebeurt in de volgende codecel).
Het model registreren
Als u de eerdere trainingszelfstudie al hebt voltooid, traint u een model, hebt u een MLflow-model geregistreerd als onderdeel van het trainingsscript en kunt u doorgaan naar de volgende sectie.
Als u de trainingszelfstudie niet hebt voltooid, moet u het model registreren. Het registreren van uw model voordat de implementatie wordt aanbevolen.
De volgende code geeft de inline op path (waar bestanden moeten worden geüpload). Als u de map zelfstudies hebt gekloond, voert u de volgende code als zodanig uit. Anders downloadt u de bestanden en metagegevens voor het model om de bestanden te implementeren en uit te pakken. Werk het pad bij naar de locatie van de uitgepakte bestanden op uw lokale computer.
De SDK uploadt automatisch de bestanden en registreert het model.
Zie Uw model registreren als een asset in Machine Learning met behulp van de SDK voor meer informatie over het registreren van uw model als asset.
# Import the necessary libraries
from azure.ai.ml.entities import Model
from azure.ai.ml.constants import AssetTypes
# Provide the model details, including the
# path to the model files, if you've stored them locally.
mlflow_model = Model(
path="./deploy/credit_defaults_model/",
type=AssetTypes.MLFLOW_MODEL,
name="credit_defaults_model",
description="MLflow Model created from local files.",
)
# Register the model
ml_client.models.create_or_update(mlflow_model)
Controleer of het model is geregistreerd
U kunt de pagina Modellen in Azure Machine Learning-studio controleren om de nieuwste versie van het geregistreerde model te identificeren.
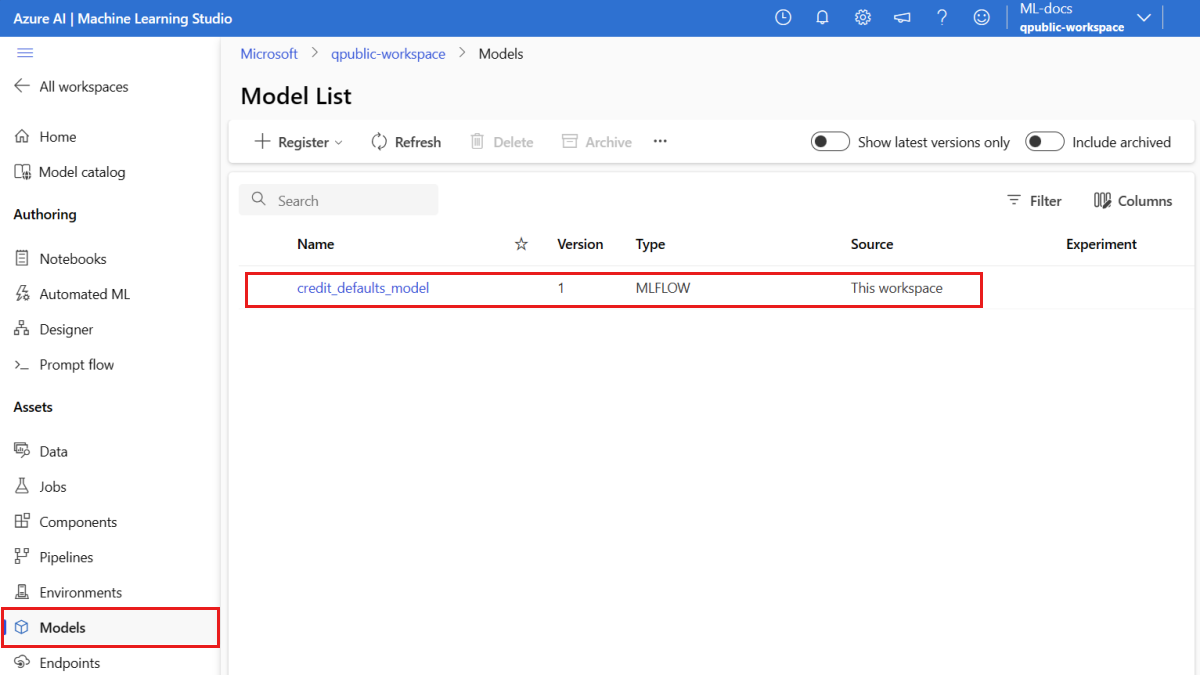
U kunt ook met de volgende code het meest recente versienummer ophalen dat u kunt gebruiken.
registered_model_name = "credit_defaults_model"
# Let's pick the latest version of the model
latest_model_version = max(
[int(m.version) for m in ml_client.models.list(name=registered_model_name)]
)
print(latest_model_version)
Nu u een geregistreerd model hebt, kunt u een eindpunt en implementatie maken. In de volgende sectie wordt kort aandacht besteed aan enkele belangrijke informatie over deze onderwerpen.
Eindpunten en implementaties
Nadat u een machine learning-model hebt getraind, moet u het implementeren zodat anderen het kunnen gebruiken voor deductie. Voor dit doel kunt u met Azure Machine Learning eindpunten maken en er implementaties aan toevoegen.
Een eindpunt is in deze context een HTTPS-pad dat een interface biedt voor clients om aanvragen (invoergegevens) naar een getraind model te verzenden en de deductieresultaten (scoren) van het model te ontvangen. Een eindpunt biedt:
- Verificatie met verificatie op basis van sleutel of token
- BEËINDIGING VAN TLS(SSL)
- Een stabiele score-URI (endpoint-name.region.inference.ml.azure.com)
Een implementatie is een set resources die vereist is voor het hosten van het model dat de werkelijke deductie uitvoert.
Eén eindpunt kan meerdere implementaties bevatten. Eindpunten en implementaties zijn onafhankelijke Azure Resource Manager-resources die worden weergegeven in Azure Portal.
Met Azure Machine Learning kunt u online-eindpunten implementeren voor realtime deductie op clientgegevens en batcheindpunten voor deductie van grote hoeveelheden gegevens gedurende een bepaalde periode.
In deze zelfstudie doorloopt u de stappen voor het implementeren van een beheerd online-eindpunt. Beheerde online-eindpunten werken met krachtige CPU- en GPU-machines in Azure op een schaalbare, volledig beheerde manier die u vrij maakt van de overhead van het instellen en beheren van de onderliggende implementatie-infrastructuur.
Een online-eindpunt maken
Nu u een geregistreerd model hebt, is het tijd om uw online-eindpunt te maken. De eindpuntnaam moet uniek zijn in de hele Azure-regio. Voor deze zelfstudie maakt u een unieke naam met een universeel unieke id UUID. Zie eindpuntlimieten voor meer informatie over de naamgevingsregels voor eindpunten.
import uuid
# Create a unique name for the endpoint
online_endpoint_name = "credit-endpoint-" + str(uuid.uuid4())[:8]
Definieer eerst het eindpunt met behulp van de ManagedOnlineEndpoint klasse.
Tip
auth_mode: Gebruikenkeyvoor verificatie op basis van sleutels. Gebruikenaml_tokenvoor verificatie op basis van tokens op basis van Azure Machine Learning. Akeyverloopt niet, maaraml_tokenverloopt wel. Zie Clients verifiëren voor online-eindpunten voor meer informatie over verificatie.U kunt eventueel een beschrijving en tags toevoegen aan uw eindpunt.
from azure.ai.ml.entities import ManagedOnlineEndpoint
# define an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="this is an online endpoint",
auth_mode="key",
tags={
"training_dataset": "credit_defaults",
},
)
Maak met behulp van het MLClient eerder gemaakte eindpunt in de werkruimte. Met deze opdracht wordt het maken van het eindpunt gestart en wordt een bevestigingsantwoord geretourneerd terwijl het maken van het eindpunt wordt voortgezet.
Notitie
Verwacht dat het maken van het eindpunt ongeveer 2 minuten duurt.
# create the online endpoint
# expect the endpoint to take approximately 2 minutes.
endpoint = ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Zodra u het eindpunt hebt gemaakt, kunt u het als volgt ophalen:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpoint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)
Informatie over online implementaties
De belangrijkste aspecten van een implementatie zijn:
name- Naam van de implementatie.endpoint_name- Naam van het eindpunt dat de implementatie bevat.model- Het model dat moet worden gebruikt voor de implementatie. Deze waarde kan een verwijzing zijn naar een bestaand versiemodel in de werkruimte of een inline modelspecificatie.environment- De omgeving die moet worden gebruikt voor de implementatie (of om het model uit te voeren). Deze waarde kan een verwijzing zijn naar een bestaande versieomgeving in de werkruimte of een inline-omgevingsspecificatie. De omgeving kan een Docker-installatiekopieën zijn met Conda-afhankelijkheden of een Dockerfile.code_configuration- de configuratie voor de broncode en het scorescript.path- Pad naar de broncodemap voor het scoren van het model.scoring_script- Relatief pad naar het scorebestand in de broncodemap. Met dit script wordt het model uitgevoerd op een bepaalde invoeraanvraag. Zie Het scorescript in het artikel 'Een ML-model implementeren met een online-eindpunt' voor een voorbeeld van een scorescript.
instance_type- De VM-grootte die moet worden gebruikt voor de implementatie. Zie de lijst met beheerde online-eindpunten voor SKU's voor de lijst met ondersteunde grootten.instance_count- Het aantal exemplaren dat moet worden gebruikt voor de implementatie.
Implementatie met behulp van een MLflow-model
Azure Machine Learning biedt ondersteuning voor implementatie zonder code van een model dat is gemaakt en geregistreerd met MLflow. Dit betekent dat u geen scorescript of een omgeving hoeft op te geven tijdens de implementatie van het model, omdat het scorescript en de omgeving automatisch worden gegenereerd bij het trainen van een MLflow-model. Als u echter een aangepast model gebruikt, moet u tijdens de implementatie de omgeving en het scorescript opgeven.
Belangrijk
Als u modellen doorgaans implementeert met behulp van scorescripts en aangepaste omgevingen en dezelfde functionaliteit wilt bereiken met behulp van MLflow-modellen, raden we u aan richtlijnen te lezen voor het implementeren van MLflow-modellen.
Het model implementeren op het eindpunt
Begin met het maken van één implementatie die 100% van het binnenkomende verkeer verwerkt. Kies een willekeurige kleurnaam (blauw) voor de implementatie. Gebruik ManagedOnlineDeployment de klasse om de implementatie voor het eindpunt te maken.
Notitie
U hoeft geen omgeving of scorescript op te geven omdat het model dat moet worden geïmplementeerd, een MLflow-model is.
from azure.ai.ml.entities import ManagedOnlineDeployment
# Choose the latest version of the registered model for deployment
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
blue_deployment = ManagedOnlineDeployment(
name="blue",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_DS3_v2",
instance_count=1,
)
Maak nu de implementatie in de werkruimte met behulp van de MLClient eerder gemaakte implementatie. Met deze opdracht wordt het maken van de implementatie gestart en wordt een bevestigingsantwoord geretourneerd terwijl het maken van de implementatie wordt voortgezet.
# create the online deployment
blue_deployment = ml_client.online_deployments.begin_create_or_update(
blue_deployment
).result()
# blue deployment takes 100% traffic
# expect the deployment to take approximately 8 to 10 minutes.
endpoint.traffic = {"blue": 100}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
De status van het eindpunt controleren
U kunt de status van het eindpunt controleren om te zien of het model zonder fouten is geïmplementeerd:
# return an object that contains metadata for the endpoint
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
# print a selection of the endpoint's metadata
print(
f"Name: {endpoint.name}\nStatus: {endpoint.provisioning_state}\nDescription: {endpoint.description}"
)
# existing traffic details
print(endpoint.traffic)
# Get the scoring URI
print(endpoint.scoring_uri)
Het eindpunt testen met voorbeeldgegevens
Nu het model is geïmplementeerd op het eindpunt, kunt u er deductie mee uitvoeren. Begin met het maken van een voorbeeldaanvraagbestand dat volgt op het ontwerp dat wordt verwacht in de uitvoeringsmethode die is gevonden in het scorescript.
import os
# Create a directory to store the sample request file.
deploy_dir = "./deploy"
os.makedirs(deploy_dir, exist_ok=True)
Maak nu het bestand in de implementatiemap. In de volgende codecel wordt IPython magic gebruikt om het bestand naar de map te schrijven die u zojuist hebt gemaakt.
%%writefile {deploy_dir}/sample-request.json
{
"input_data": {
"columns": [0,1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22],
"index": [0, 1],
"data": [
[20000,2,2,1,24,2,2,-1,-1,-2,-2,3913,3102,689,0,0,0,0,689,0,0,0,0],
[10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8, 7, 6, 5, 4, 3, 2, 1, 10, 9, 8]
]
}
}
Haal met behulp van de MLClient eerder gemaakte ingang een ingang op naar het eindpunt. U kunt het eindpunt aanroepen met behulp van de invoke opdracht met de volgende parameters:
endpoint_name- Naam van het eindpuntrequest_file- Bestand met aanvraaggegevensdeployment_name- Naam van de specifieke implementatie die moet worden getest in een eindpunt
Test de blauwe implementatie met de voorbeeldgegevens.
# test the blue deployment with the sample data
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name="blue",
request_file="./deploy/sample-request.json",
)
Logboeken van de implementatie ophalen
Controleer de logboeken om te zien of het eindpunt/de implementatie is aangeroepen. Als u fouten ondervindt, raadpleegt u De implementatie van online-eindpunten oplossen.
logs = ml_client.online_deployments.get_logs(
name="blue", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Een tweede implementatie maken
Implementeer het model als een tweede implementatie met de naam green. In de praktijk kunt u verschillende implementaties maken en de prestaties ervan vergelijken. Deze implementaties kunnen een andere versie van hetzelfde model, een ander model of een krachtiger rekenproces gebruiken.
In dit voorbeeld implementeert u dezelfde modelversie met behulp van een krachtiger rekenproces dat de prestaties mogelijk kan verbeteren.
# pick the model to deploy. Here you use the latest version of the registered model
model = ml_client.models.get(name=registered_model_name, version=latest_model_version)
# define an online deployment using a more powerful instance type
# if you run into an out of quota error, change the instance_type to a comparable VM that is available.\
# Learn more on https://azure.microsoft.com/en-us/pricing/details/machine-learning/.
green_deployment = ManagedOnlineDeployment(
name="green",
endpoint_name=online_endpoint_name,
model=model,
instance_type="Standard_F4s_v2",
instance_count=1,
)
# create the online deployment
# expect the deployment to take approximately 8 to 10 minutes
green_deployment = ml_client.online_deployments.begin_create_or_update(
green_deployment
).result()
Implementatie schalen om meer verkeer te verwerken
Met behulp van het MLClient eerder gemaakte bestand kunt u een ingang krijgen voor de green implementatie. Vervolgens kunt u deze schalen door de instance_countschaal te verhogen of te verlagen.
In de volgende code verhoogt u het VM-exemplaar handmatig. Het is echter ook mogelijk om online-eindpunten automatisch te schalen. Automatisch schalen wordt uitgevoerd met de juiste hoeveelheid resources om de belasting van uw toepassing te verwerken. Beheerde online-eindpunten bieden ondersteuning voor automatisch schalen via integratie met de functie voor automatische schaalaanpassing van Azure Monitor. Zie Online-eindpunten voor automatisch schalen als u automatische schaalaanpassing wilt configureren.
# update definition of the deployment
green_deployment.instance_count = 2
# update the deployment
# expect the deployment to take approximately 8 to 10 minutes
ml_client.online_deployments.begin_create_or_update(green_deployment).result()
Verkeerstoewijzing voor implementaties bijwerken
U kunt productieverkeer splitsen tussen implementaties. Misschien wilt u eerst de green implementatie testen met voorbeeldgegevens, net zoals u dat hebt gedaan voor de blue implementatie. Zodra u uw groene implementatie hebt getest, wijst u er een klein percentage verkeer aan toe.
endpoint.traffic = {"blue": 80, "green": 20}
ml_client.online_endpoints.begin_create_or_update(endpoint).result()
Test de verkeerstoewijzing door het eindpunt meerdere keren aan te roepen:
# You can invoke the endpoint several times
for i in range(30):
ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./deploy/sample-request.json",
)
Geef logboeken van de green implementatie weer om te controleren of er binnenkomende aanvragen zijn en of het model is beoordeeld.
logs = ml_client.online_deployments.get_logs(
name="green", endpoint_name=online_endpoint_name, lines=50
)
print(logs)
Metrische gegevens weergeven met Behulp van Azure Monitor
U kunt verschillende metrische gegevens (aanvraagnummers, aanvraaglatentie, netwerkbytes, CPU/GPU/Schijf-/geheugengebruik en meer) bekijken voor een online-eindpunt en de implementaties ervan door koppelingen te volgen op de pagina Details van het eindpunt in de studio. Als u een van deze koppelingen volgt, gaat u naar de exacte pagina met metrische gegevens in Azure Portal voor het eindpunt of de implementatie.

Als u de metrische gegevens voor het online-eindpunt opent, kunt u de pagina instellen om metrische gegevens weer te geven, zoals de gemiddelde latentie van de aanvraag, zoals wordt weergegeven in de volgende afbeelding.

Zie Online-eindpunten bewaken voor meer informatie over het weergeven van metrische online eindpunten.
Al het verkeer verzenden naar de nieuwe implementatie
Zodra u volledig tevreden bent met uw green implementatie, schakelt u al het verkeer naar de implementatie over.
endpoint.traffic = {"blue": 0, "green": 100}
ml_client.begin_create_or_update(endpoint).result()
De oude implementatie verwijderen
Verwijder de oude (blauwe) implementatie:
ml_client.online_deployments.begin_delete(
name="blue", endpoint_name=online_endpoint_name
).result()
Resources opschonen
Als u het eindpunt en de implementatie niet gaat gebruiken nadat u deze zelfstudie hebt voltooid, moet u deze verwijderen.
Notitie
Verwacht dat de volledige verwijdering ongeveer 20 minuten duurt.
ml_client.online_endpoints.begin_delete(name=online_endpoint_name).result()
Alles verwijderen
Gebruik deze stappen om uw Azure Machine Learning-werkruimte en alle rekenresources te verwijderen.
Belangrijk
De resources die u hebt gemaakt, kunnen worden gebruikt als de vereisten voor andere Azure Machine Learning-zelfstudies en artikelen met procedures.
Als u niet van plan bent om een van de resources te gebruiken die u hebt gemaakt, verwijdert u deze zodat er geen kosten in rekening worden gebracht:
Selecteer Resourcegroepen links in Azure Portal.
Selecteer de resourcegroep die u hebt gemaakt uit de lijst.
Selecteer Resourcegroep verwijderen.
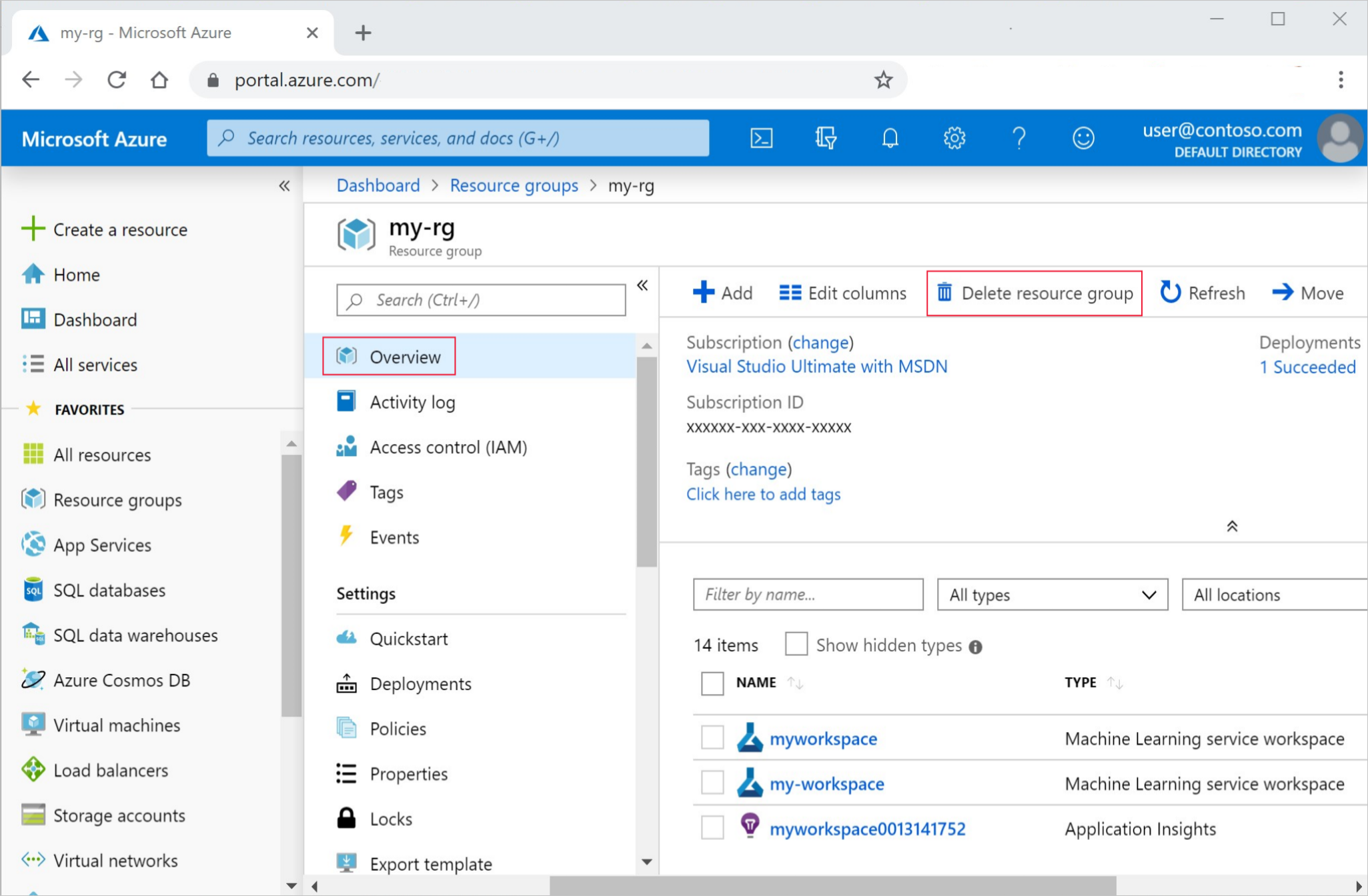
Voer de naam van de resourcegroup in. Selecteer daarna Verwijderen.