Zelfstudie: Ontwerper - een regressiemodel zonder code trainen
Train een lineair regressiemodel dat autoprijzen voorspelt met behulp van de Azure Machine Learning-ontwerpfunctie. Deze zelfstudie is deel één van een serie van twee.
In deze zelfstudie wordt de Azure Machine Learning-ontwerpfunctie gebruikt voor meer informatie. Zie Wat is Azure Machine Learning-ontwerpfunctie?
Notitie
Designer ondersteunt twee typen onderdelen, klassieke vooraf samengestelde onderdelen (v1) en aangepaste onderdelen (v2). Deze twee typen onderdelen zijn NIET compatibel.
Klassieke vooraf samengestelde onderdelen bieden belangrijke vooraf gedefinieerde onderdelen voor gegevensverwerking en traditionele machine learning-taken, zoals regressie en classificatie. Dit type onderdeel wordt nog steeds ondersteund, maar er worden geen nieuwe onderdelen toegevoegd.
Met aangepaste onderdelen kunt u uw eigen code verpakken als onderdeel. Het biedt ondersteuning voor het delen van onderdelen in werkruimten en naadloze creatie in Studio-, CLI v2- en SDK v2-interfaces.
Voor nieuwe projecten raden we u ten zeerste aan aangepaste onderdelen te gebruiken, die compatibel is met AzureML V2 en nieuwe updates blijven ontvangen.
Dit artikel is van toepassing op klassieke vooraf samengestelde onderdelen en niet compatibel met CLI v2 en SDK v2.
In deel één van de zelfstudie leert u het volgende:
- Een nieuwe pipeline maken.
- Import data.
- Bereid gegevens voor.
- Een machine learning-model trainen.
- Een machine learning-model evalueren.
In deel twee van de zelfstudie implementeert u uw model als een realtime deductie-eindpunt om de prijs van een auto te voorspellen op basis van technische specificaties die u verzendt.
Notitie
Een voltooide versie van deze zelfstudie is als voorbeeldpijplijn beschikbaar.
Ga naar de ontwerpfunctie in uw werkruimte om deze te zoeken. Selecteer in de sectie Nieuwe pijplijn voorbeeld 1 - Regressie: Automobile Price Prediction(Basic).
Belangrijk
Als u grafische elementen die in dit document worden vermeld, zoals knoppen in Studio of Designer, niet ziet, hebt u mogelijk niet het juiste machtigingsniveau voor de werkruimte. Neem contact op met de beheerder van uw Azure-abonnement om te controleren of u het juiste toegangsniveau hebt gekregen. Zie Gebruikers en rollen beherenvoor meer informatie.
Een nieuwe pipeline maken
Met Azure Machine Learning-pijplijnen kunnen meerdere stappen voor machine learning en gegevensverwerking in één resource worden georganiseerd. Met pijplijnen kunt u complexe machine learning-workflows voor verschillende projecten en gebruikers organiseren, beheren en opnieuw gebruiken.
Als u een Azure Machine Learning-pijplijn wilt maken, hebt u een Azure Machine Learning-werkruimte nodig. In deze sectie leert u hoe u deze beide resources maakt.
Een nieuwe werkruimte maken
Als u de ontwerpfunctie wilt gebruiken, hebt u een Azure Machine Learning-werkruimte nodig. De werkruimte is de resource op het hoogste niveau voor Azure Machine Learning en biedt een gecentraliseerde werkplek met alle artefacten die u in Azure Machine Learning maakt. Zie Werkruimtebronnen maken voor instructies over het maken van een werkruimte.
Notitie
Als uw werkruimte gebruikmaakt van een virtueel netwerk, zijn er aanvullende configuratiestappen om de ontwerpfunctie te kunnen gebruiken. Zie Azure Machine Learning Studio gebruiken in een virtueel Azure-netwerk voor meer informatie
Maak de pijplijn
Notitie
Designer ondersteunt twee soorten onderdelen, klassieke vooraf samengestelde onderdelen en aangepaste onderdelen. Deze twee typen onderdelen zijn niet compatibel.
Klassieke vooraf gebouwde onderdelen bieden belangrijke vooraf gedefinieerde onderdelen voor gegevensverwerking en traditionele machine learning-taken, zoals regressie en classificatie. Dit type onderdeel wordt nog steeds ondersteund, maar er worden geen nieuwe onderdelen toegevoegd.
Met aangepaste onderdelen kunt u uw eigen code als onderdeel opgeven. Het biedt ondersteuning voor delen tussen werkruimten en naadloze creatie in Studio-, CLI- en SDK-interfaces.
Dit artikel is van toepassing op klassieke vooraf samengestelde onderdelen.
Meld u aan op ml.azure.com en selecteer de werkruimte waarmee u wilt werken.
Selecteer Designer -> Klassiek vooraf samengesteld
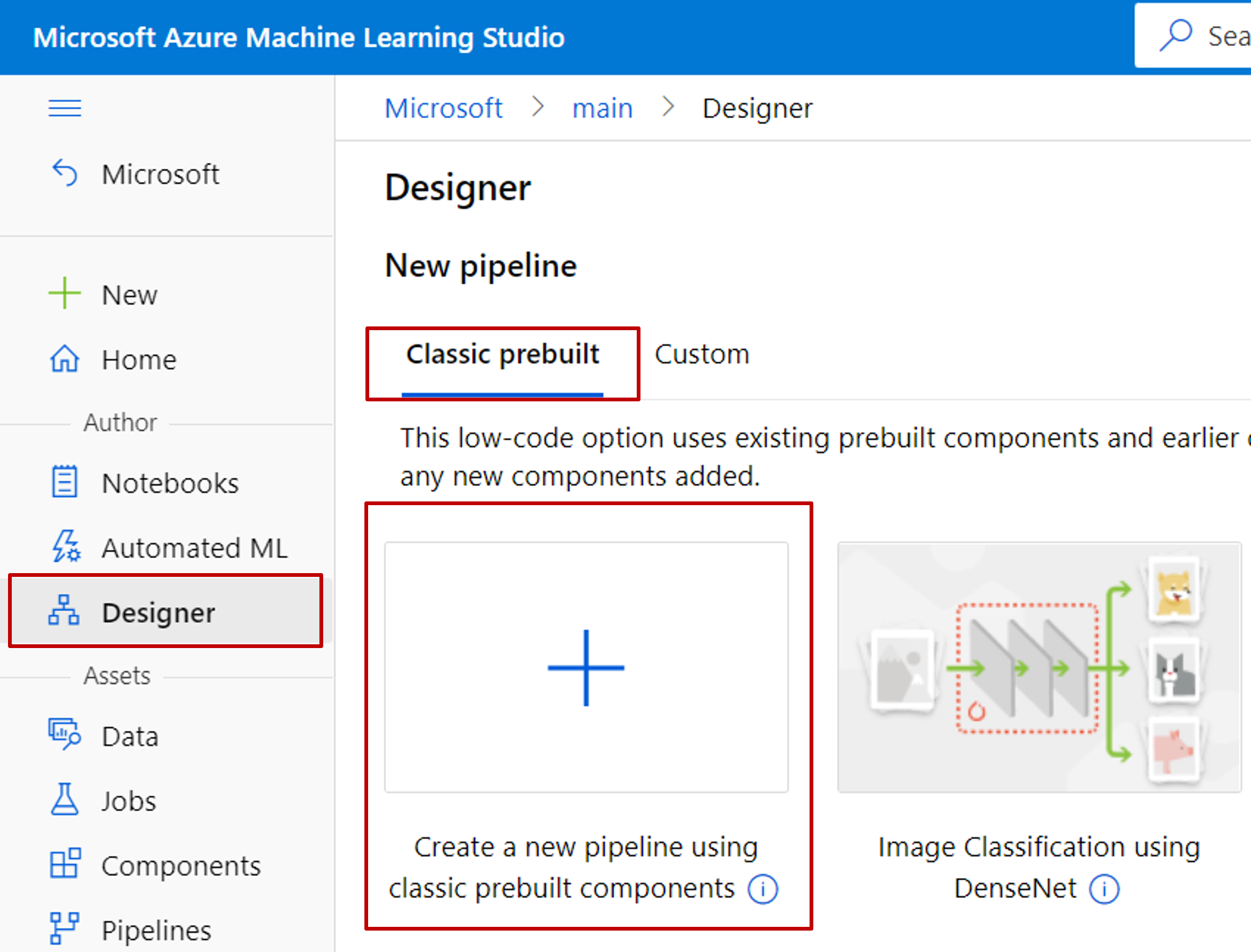
Selecteer Een nieuwe pijplijn maken met klassieke vooraf gemaakte onderdelen.
Klik op het potloodpictogram naast de automatisch gegenereerde naam van het pijplijnconcept en wijzig de naam ervan in Autoprijsvoorspelling. De naam hoeft niet uniek te zijn.
Gegevens importeren
Er zijn diverse voorbeeldgegevenssets meegeleverd in de ontwerpfunctie waarmee u kunt experimenteren. Voor deze zelfstudie gebruikt u Automobile price data (Raw).
Links van het pijplijncanvas bevindt zich een palet met gegevenssets en onderdelen. Selecteer Component ->Sample data.
Selecteer de gegevensset Automobile price data (Raw) en sleep deze naar het canvas.
De gegevens visualiseren
U kunt de gegevens visualiseren voor meer informatie over de gegevensset die u gebruikt.
Klik met de rechtermuisknop op de autoprijsgegevens (Raw) en selecteer Voorbeeldgegevens.
Selecteer de verschillende kolommen in het gegevensvenster om informatie over elke kolom weer te geven.
Elke auto wordt weergegeven als een rij. De variabelen die aan elke auto zijn gekoppeld, worden weergegeven als kolommen. Er zijn 205 rijen en 26 kolommen in deze gegevensset.
Gegevens voorbereiden
Voor gegevenssets moet u doorgaans enige verwerking vooraf uitvoeren voordat u de analyse kunt uitvoeren. U hebt wellicht al gezien dat er een aantal waarden ontbreekt toen u de gegevensset inspecteerde. Deze ontbrekende waarden moeten worden opgeschoond, zodat de gegevens correct kunnen worden geanalyseerd.
Een kolom verwijderen
Wanneer u een model traint, moet u iets doen aan de ontbrekende gegevens. In deze gegevensset ontbreken veel waarden in de kolom normalized-losses , dus sluit u die kolom helemaal uit van het model.
Klik in het palet met gegevenssets en onderdelen links van het canvas op Component en zoek naar het onderdeel Kolommen selecteren in gegevensset .
Sleep het onderdeel Kolommen selecteren in gegevensset naar het canvas. Verwijder het onderdeel onder het gegevenssetonderdeel.
Verbinding maken de Gegevensset automobile price data (Raw) to the Select Columns in Dataset component. Sleep vanaf de uitvoerpoort van de gegevensset, de kleine cirkel onder aan de gegevensset op het canvas, naar de invoerpoort van Select Columns in Dataset. Dit is de kleine cirkel boven aan het onderdeel.
Tip
U maakt een gegevensstroom via uw pijplijn wanneer u de uitvoerpoort van het ene onderdeel verbindt met een invoerpoort van een ander onderdeel.
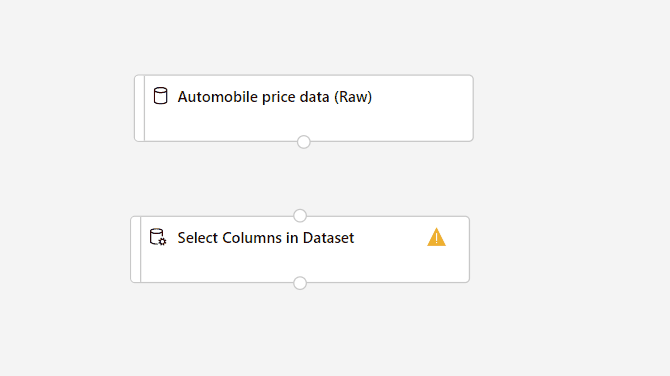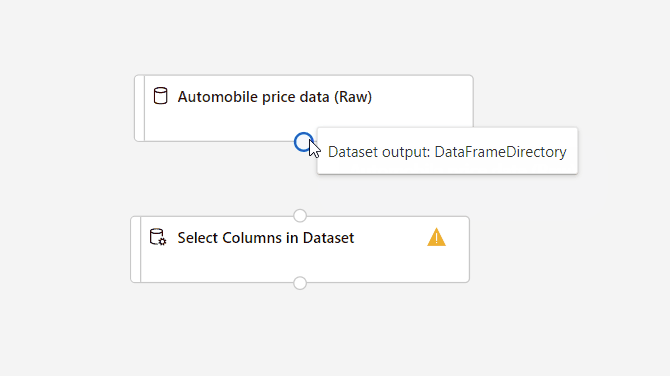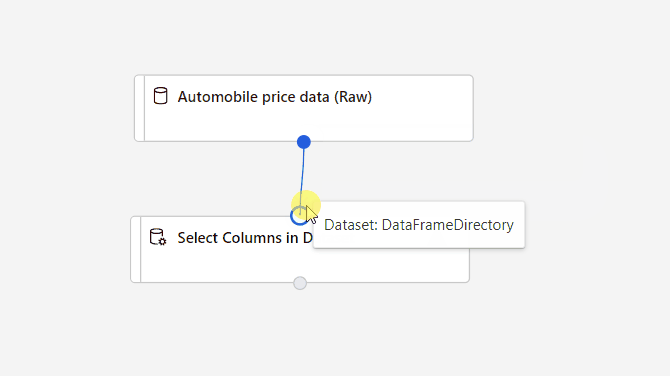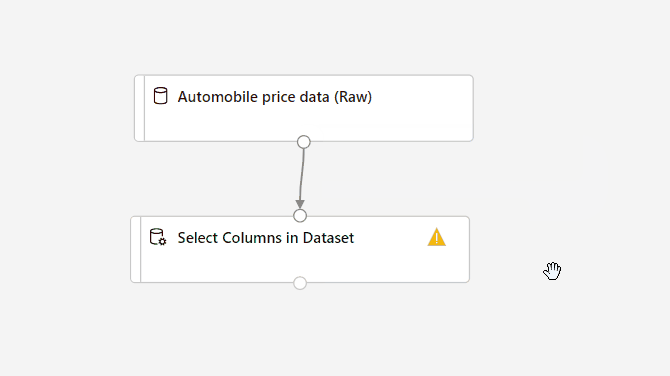
Selecteer het onderdeel Kolommen selecteren in gegevensset .
Klik op het pijlpictogram onder Instellingen rechts van het canvas om het detailvenster van het onderdeel te openen. U kunt ook dubbelklikken op het onderdeel Kolommen selecteren in gegevensset om het detailvenster te openen.
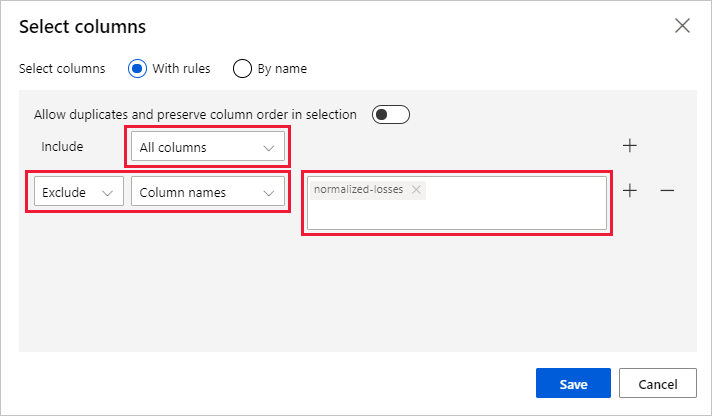
Selecteer Kolom bewerken rechts van het deelvenster.
Vouw de vervolgkeuzelijst Kolomnamen naast Invoegen uit en selecteer Alle kolommen.
Selecteer de + om een nieuwe regel toe te voegen.
Bij de vervolgkeuzemenu's selecteert u Uitsluiten en Kolomnamen.
Voer normalized-losses in het tekstvak in.
Rechtsonder selecteert u Opslaan om de kolomselector te sluiten.
Vouw in het deelvenster Details van het onderdeel Gegevensset selecteren de gegevens van het knooppunt uit.
Selecteer het tekstvak Opmerking en voer genormaliseerde verliezen uitsluiten in.
Opmerkingen worden op de grafiek weergegeven om uw pijplijn te helpen organiseren.
Ontbrekende gegevens opschonen
Er ontbreken nog steeds waarden in uw gegevensset nadat u de kolom normalized-losses hebt verwijderd. U kunt de resterende ontbrekende gegevens verwijderen met behulp van het onderdeel Ontbrekende gegevens opschonen.
Tip
Het opschonen van de ontbrekende waarden uit invoergegevens is een vereiste voor het gebruik van de meeste onderdelen in de ontwerpfunctie.
Klik in het palet met gegevenssets en onderdelen links van het canvas op Component en zoek naar het onderdeel Ontbrekende gegevens opschonen.
Sleep het onderdeel Ontbrekende gegevens opschonen naar het pijplijncanvas. Verbinding maken naar de Selecteer kolommen in het onderdeel Gegevensset.
Selecteer het onderdeel Ontbrekende gegevens opschonen.
Klik op het pijlpictogram onder Instellingen rechts van het canvas om het detailvenster van het onderdeel te openen. U kunt ook dubbelklikken op het onderdeel Ontbrekende gegevens opschonen om het detailvenster te openen.
Selecteer Kolom bewerken rechts van het deelvenster.
In het venster Kolommen die moeten worden gewist dat wordt weergegeven, vouwt u het vervolgkeuzemenu naast Invoegen uit. Selecteer Alle kolommen
Selecteer Opslaan
Selecteer in het detailvenster Ontbrekende gegevens opschonen onder De modus Opschonen de optie Hele rij verwijderen.
Vouw in het detailvenster Ontbrekende gegevens opschonen de knooppuntgegevens uit.
Selecteer het tekstvak Opmerking en voer ontbrekende waarderijen verwijderen in.
Uw pijplijn ziet er als volgt uit:
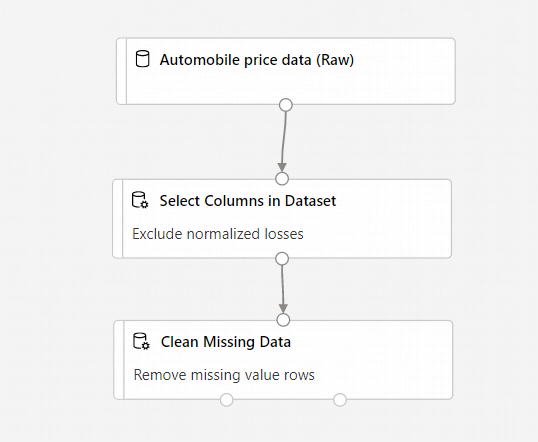
Een Machine Learning-model trainen
Nu u de onderdelen hebt om de gegevens te verwerken, kunt u de trainingsonderdelen instellen.
Omdat u de prijs wilt voorspellen, wat een getal is, gebruikt u een regressiealgoritme. In dit voorbeeld gebruikt u een lineair regressiemodel.
De gegevens splitsen
Het splitsen van gegevens is een algemene taak bij machine learning. U splitst uw gegevens op in twee afzonderlijke gegevenssets. De ene gegevensset traint het model en de andere gegevensset test hoe goed het model presteert.
Klik in het palet met gegevenssets en onderdelen links van het canvas op Component en zoek naar het onderdeel Split Data .
Sleep het onderdeel Split Data naar het pijplijncanvas.
Verbinding maken de linkerpoort van de Schoon het onderdeel Ontbrekende gegevens op in het onderdeel Split Data.
Belangrijk
Zorg ervoor dat de linkeruitvoerpoort van Clean Missing Data verbinding maakt met Split Data. De linkerpoort bevat de opgeschoonde gegevens. De rechterpoort bevat de genegeerde gegevens.
Selecteer het onderdeel Split Data .
Klik op het pijlpictogram onder Instellingen rechts van het canvas om het detailvenster van het onderdeel te openen. U kunt ook dubbelklikken op het onderdeel Split Data om het detailvenster te openen.
Stel in het deelvenster Gegevens splitsen het deel van de rijen in de eerste uitvoergegevensset in op 0,7.
Met deze optie wordt 70% van de gegevens gebruikt om het model te trainen en 30% om het model te testen. De gegevensset van 70% is toegankelijk via de linkeruitvoerpoort. De resterende gegevens zijn beschikbaar via de juiste uitvoerpoort.
Vouw in het deelvenster Gegevens splitsen de gegevens van het knooppunt uit.
Selecteer het tekstvak Opmerking en voer de gegevensset splitsen in trainingsset (0.7) en testset (0.3) in.
Het model trainen
Train het model door hiervoor een gegevensset te gebruiken waarin de prijs een van de elementen is. Het algoritme bouwt een model waarmee de relatie tussen de functies en de prijs wordt uitgelegd, zoals dat uit de trainingsgegevens blijkt.
Klik in het palet met gegevenssets en onderdelen links van het canvas op Component en zoek naar het component Linear Regression .
Sleep het component Linear Regression naar het pijplijncanvas.
Klik in het palet met gegevenssets en onderdelen links van het canvas op Component en zoek naar het onderdeel Model trainen .
Sleep het onderdeel Train Model naar het pijplijncanvas.
Verbinding maken de uitvoer van de Lineair regressieonderdeel aan de linkerkant van het onderdeel Train Model.
Verbinding maken de uitvoer van de trainingsgegevens (linkerpoort) van de Split Data component to the right input of the Train Model component.
Belangrijk
Zorg ervoor dat de linkeruitvoerpoort van Split Data verbinding maakt met Train Model. De linkerpoort bevat de trainingsset. De rechterpoort bevat de testset.
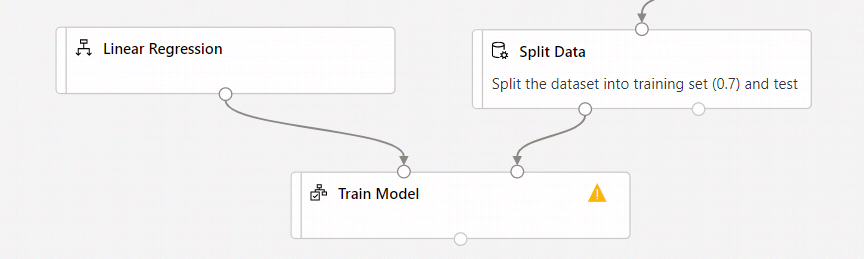
Selecteer het onderdeel Train Model .
Klik op het pijlpictogram onder Instellingen rechts van het canvas om het detailvenster van het onderdeel te openen. U kunt ook dubbelklikken op het onderdeel Model trainen om het detailvenster te openen.
Selecteer Kolom bewerken rechts van het deelvenster.
Vouw in het venster Labelkolom dat wordt weergegeven de vervolgkeuzelijst uit en selecteer Kolomnamen.
In het tekstvak voert u price in om de waarde op te geven die door uw model gaat worden voorspeld.
Belangrijk
Zorg ervoor dat u de kolomnaam exact opgeeft. Gebruik geen hoofdletters in het woord price.
Uw pijplijn ziet er als volgt uit:
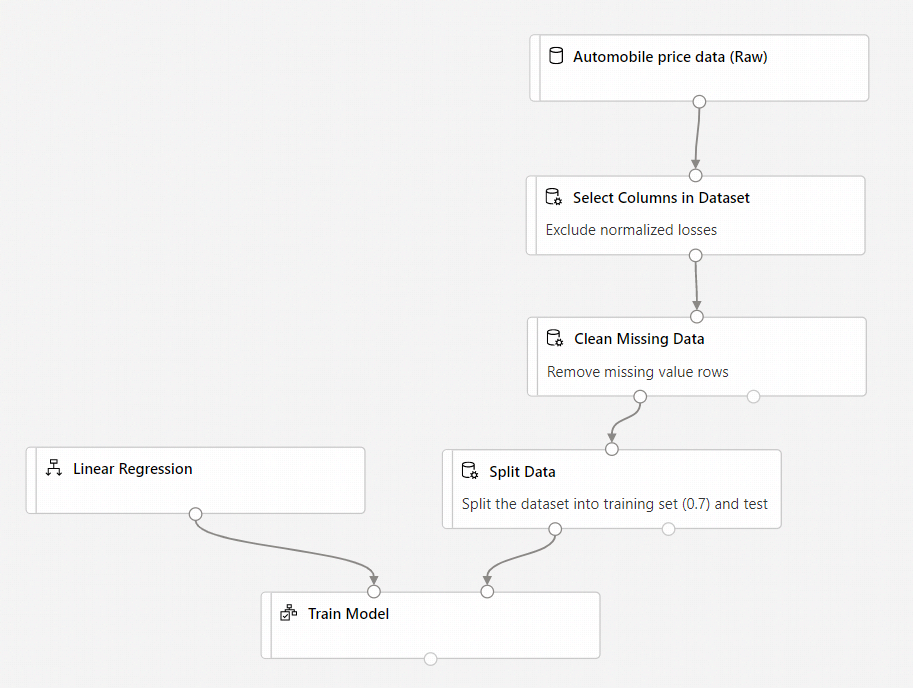
Het onderdeel Score Model toevoegen
Nadat u uw model hebt getraind aan de hand van 70% van de gegevens, kunt u dit gebruiken om de overige 30% van een score te voorzien, om te zien hoe goed uw model werkt.
Klik in het palet met gegevenssets en onderdelen links van het canvas op Component en zoek naar het onderdeel Score Model .
Sleep het onderdeel Score Model naar het pijplijncanvas.
Verbinding maken de uitvoer van de Train modelonderdeel naar de linkerinvoerpoort van Score Model. Verbinding maken de uitvoer van de testgegevens (rechterpoort) van de Split Data component to the right input port of Score Model.
Het onderdeel Evaluate Model toevoegen
Gebruik het onderdeel Evaluate Model om te evalueren hoe goed uw model de testgegevensset heeft beoordeeld.
Klik in het palet met gegevenssets en onderdelen links van het canvas op Component en zoek naar het onderdeel Evaluate Model .
Sleep het onderdeel Evaluate Model naar het pijplijncanvas.
Verbinding maken de uitvoer van de Score Model component aan de linkerkant van Evaluate Model.
De uiteindelijke pijplijn ziet er als volgt uit:
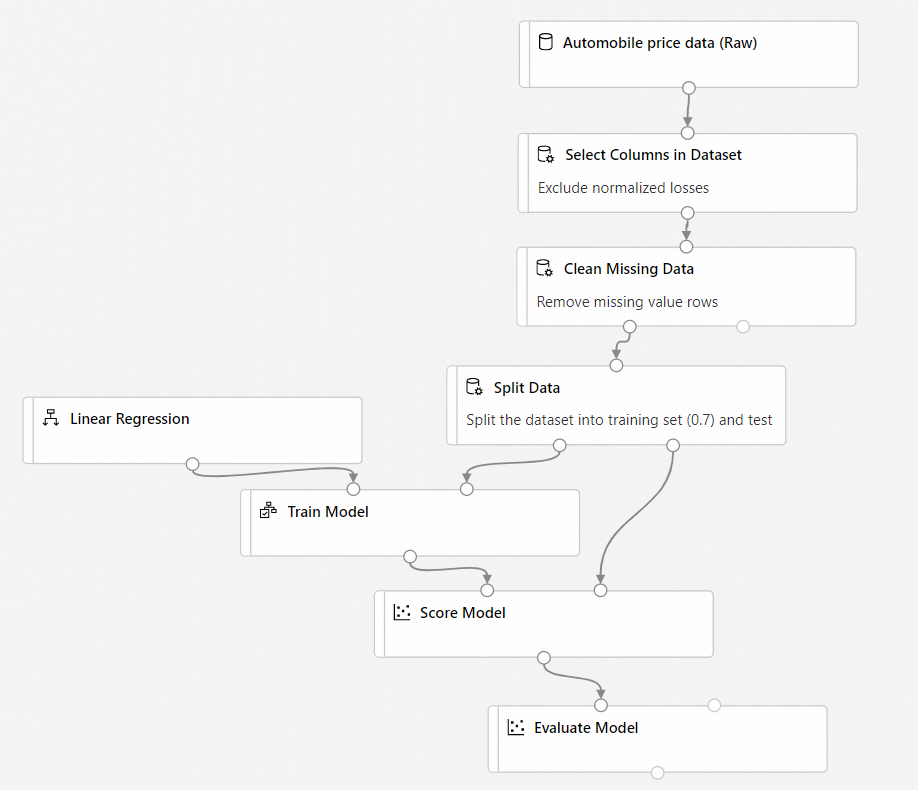
Pijplijn verzenden
Selecteer Configureren en verzenden in de rechterbovenhoek om de pijplijn te verzenden.

Vervolgens ziet u een stapsgewijze wizard en volgt u de wizard om de pijplijntaak te verzenden.


In de basisstap kunt u het experiment, de weergavenaam van de taak, de taakbeschrijving, enzovoort configureren.
In de stap Invoer en uitvoer kunt u waarde toewijzen aan de invoer-/uitvoerwaarden die worden gepromoveerd tot pijplijnniveau. In dit voorbeeld is deze leeg omdat er geen invoer/uitvoer naar het pijplijnniveau is gepromoot.
In runtime-instellingen kunt u het standaardgegevensarchief en de standaard rekenkracht voor de pijplijn configureren. Het is de standaardgegevensopslag/compute voor alle onderdelen in de pijplijn. Als u echter expliciet een ander reken- of gegevensarchief instelt voor een onderdeel, respecteert het systeem de instelling op onderdeelniveau. Anders wordt de standaardwaarde gebruikt.
De stap Beoordelen en verzenden is de laatste stap om alle instellingen te controleren voordat u verzendt. De wizard onthoudt uw laatste configuratie als u de pijplijn ooit verzendt.
Nadat u de pijplijntaak hebt verzonden, ziet u bovenaan een bericht met een koppeling naar de taakdetails. U kunt deze koppeling selecteren om de taakdetails te bekijken.

Gescoorde labels weergeven
Op de pagina met taakdetails kunt u de status, resultaten en logboeken van de pijplijntaak controleren.
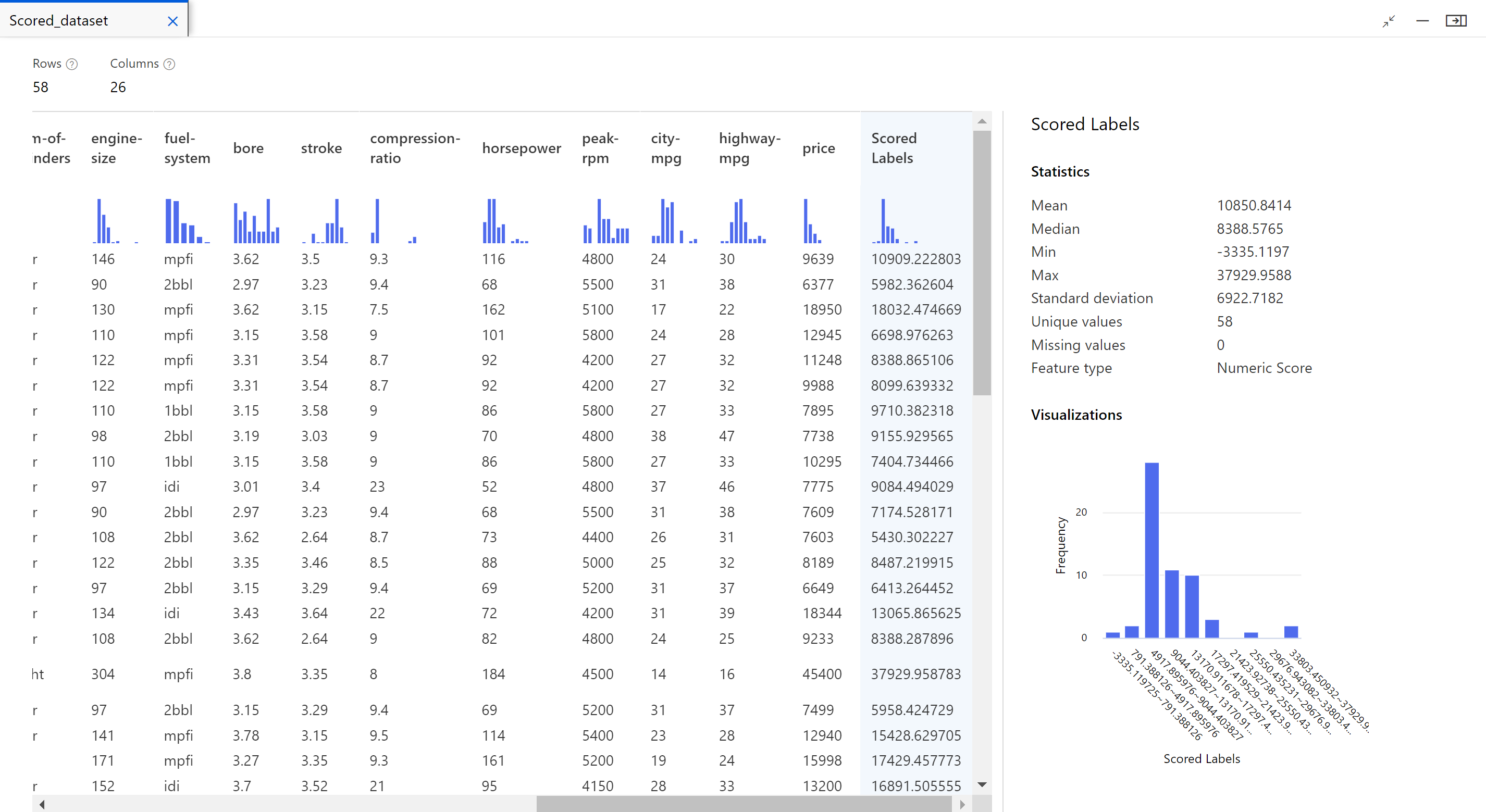
Nadat de taak is voltooid, kunt u de resultaten van de pijplijntaak bekijken. Kijk eerst naar de voorspellingen die door het regressiemodel zijn gegenereerd.
Klik met de rechtermuisknop op het onderdeel Score Model en selecteer Voorbeeldgegevensset> scored om de uitvoer ervan weer te geven.
Hier ziet u de voorspelde prijzen en de daadwerkelijke prijzen van de testgegevens.
Modellen evalueren
Gebruik Evaluate Model om te zien hoe goed het getrainde model heeft gepresteerd met de testgegevensset.
- Klik met de rechtermuisknop op het onderdeel Model evalueren en selecteer Voorbeeld van de resultaten van de evaluatie van gegevens>om de uitvoer ervan weer te geven.
De volgende statistieken worden weergegeven voor uw model:
- Gemiddelde absolute fout (MAE): het gemiddelde van absolute fouten. Een fout is het verschil tussen de voorspelde waarde en de daadwerkelijke waarde.
- Root Mean Squared Error (RMSE): de wortel uit het gemiddelde aan gekwadrateerde fouten voor de voorspellingen op basis van de testgegevensset.
- Relative Absolute Error: het gemiddelde aan absolute fouten ten opzichte van het absolute verschil tussen de werkelijke waarden en het gemiddelde van alle werkelijke waarden.
- Relative Squared Error: het gemiddelde aan gekwadrateerde fouten ten opzichte van het gekwadrateerde verschil tussen de werkelijke waarden en het gemiddelde van alle werkelijke waarden.
- De bepalingscoëfficiënt: ook wel bekend als de R-kwadratische waarde, geeft deze statistische meetwaarde aan hoe goed een model past bij de gegevens.
Voor elk van de foutstatistieken geldt: hoe kleiner hoe beter. Een lagere waarde geeft aan dat de voorspellingen dichter bij de daadwerkelijke waarden liggen. Hoe dichter de determinatiecoëfficiënt bij één (1,0) ligt, hoe beter de voorspellingen.
Resources opschonen
Sla deze sectie over als u door wilt gaan met deel 2 van de zelfstudie Modellen implementeren.
Belangrijk
U kunt de resources die u hebt gemaakt, gebruiken als vereisten voor andere Azure Machine Learning-zelfstudies en artikelen met procedures.
Alles verwijderen
Als u niets wilt gebruiken dat u hebt gemaakt, kunt u de hele resourcegroep verwijderen zodat er geen kosten voor in rekening worden gebracht.
Selecteer in Azure Portal, aan de linkerkant in het venster, de optie Resourcegroepen.
Selecteer de resourcegroep die u hebt gemaakt in de lijst.
Selecteer Resourcegroep verwijderen.
Als u de resource groep verwijdert, worden ook alle resources verwijderd die u in de ontwerpfunctie hebt gemaakt.
Afzonderlijke assets verwijderen
In de ontwerpfunctie waar u uw experiment hebt gemaakt, verwijdert u afzonderlijke assets door ze te selecteren en vervolgens de knop Verwijderen te selecteren.
Het rekendoel dat u hier hebt gemaakt, wordt, wanneer het niet wordt gebruikt, automatisch geschaald naar nul knooppunten. Deze actie wordt uitgevoerd om de kosten te minimaliseren. Als u het rekendoel wilt verwijderen, voert u de volgende stappen uit:
U kunt de registratie van gegevenssets vanuit uw werkruimte opheffen door alle gegevenssets te selecteren en Registratie opheffen te selecteren.
Als u een gegevensset wilt verwijderen, gaat u naar het opslagaccount via Azure Portal of Azure Storage Explorer en verwijdert u de assets handmatig.
Volgende stappen
In deel 2 leert u hoe u uw model kunt implementeren als een realtime-eindpunt.