Zelfstudie: Uw gegevens uploaden, openen en verkennen in Azure Machine Learning
VAN TOEPASSING OP: Python SDK azure-ai-ml v2 (actueel)
Python SDK azure-ai-ml v2 (actueel)
In deze zelfstudie leert u het volgende:
- Uw gegevens uploaden naar cloudopslag
- Een Azure Machine Learning-gegevensasset maken
- Toegang tot uw gegevens in een notebook voor interactieve ontwikkeling
- Nieuwe versies van gegevensassets maken
Het begin van een machine learning-project omvat doorgaans verkennende gegevensanalyse (EDA), gegevensvoorverwerking (reiniging, functie-engineering) en het bouwen van prototypen van Machine Learning-modellen om hypothesen te valideren. Deze prototypeprojectfase is zeer interactief. Het leent zich voor ontwikkeling in een IDE of een Jupyter-notebook, met een interactieve Python-console. In deze zelfstudie worden deze ideeën beschreven.
In deze video ziet u hoe u aan de slag gaat in Azure Machine Learning-studio, zodat u de stappen in de zelfstudie kunt volgen. In de video ziet u hoe u een notebook maakt, het notebook kloont, een rekenproces maakt en de gegevens downloadt die nodig zijn voor de zelfstudie. De stappen worden ook beschreven in de volgende secties.
Vereisten
-
Als u Azure Machine Learning wilt gebruiken, hebt u eerst een werkruimte nodig. Als u er nog geen hebt, voltooit u Resources maken die u nodig hebt om aan de slag te gaan met het maken van een werkruimte en meer informatie over het gebruik ervan.
-
Meld u aan bij de studio en selecteer uw werkruimte als deze nog niet is geopend.
-
Open of maak een notitieblok in uw werkruimte:
- Maak een nieuw notitieblok als u code wilt kopiëren/plakken in cellen.
- Of open zelfstudies/get-started-notebooks/explore-data.ipynb vanuit de sectie Voorbeelden van studio. Selecteer Vervolgens Klonen om het notitieblok toe te voegen aan uw bestanden. (Zie waar u voorbeelden kunt vinden.)
Uw kernel instellen
Maak op de bovenste balk boven het geopende notitieblok een rekenproces als u er nog geen hebt.

Als het rekenproces is gestopt, selecteert u Rekenproces starten en wacht u totdat het wordt uitgevoerd.

Zorg ervoor dat de kernel, die zich rechtsboven bevindt, is
Python 3.10 - SDK v2. Als dit niet het probleem is, gebruikt u de vervolgkeuzelijst om deze kernel te selecteren.
Als u een banner ziet met de melding dat u moet worden geverifieerd, selecteert u Verifiëren.



Belangrijk
De rest van deze zelfstudie bevat cellen van het zelfstudienotitieblok. Kopieer of plak deze in uw nieuwe notitieblok of ga nu naar het notitieblok als u het hebt gekloond.
De gegevens downloaden die in deze zelfstudie worden gebruikt
Voor gegevensopname verwerkt Azure Data Explorer onbewerkte gegevens in deze indelingen. In deze zelfstudie wordt gebruikgemaakt van dit voorbeeld van creditcardgegevens van creditcardclients. De stappen worden uitgevoerd in een Azure Machine Learning-resource. In die resource maken we een lokale map met de voorgestelde naam van gegevens rechtstreeks onder de map waar dit notebook zich bevindt.
Notitie
Deze zelfstudie is afhankelijk van gegevens die zijn geplaatst in een azure Machine Learning-resourcemaplocatie. Voor deze zelfstudie betekent 'lokaal' een maplocatie in die Azure Machine Learning-resource.
Selecteer Terminal openen onder de drie puntjes, zoals wordt weergegeven in deze afbeelding:
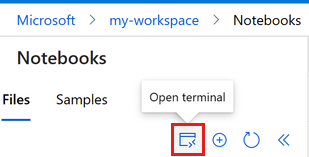
Het terminalvenster wordt geopend op een nieuw tabblad.
Zorg ervoor dat u
cdzich in dezelfde map bevindt waar dit notitieblok zich bevindt. Als het notitieblok zich bijvoorbeeld in een map bevindt met de naam get-started-notebooks:cd get-started-notebooks # modify this to the path where your notebook is locatedVoer deze opdrachten in het terminalvenster in om de gegevens naar uw rekeninstantie te kopiëren:
mkdir data cd data # the sub-folder where you'll store the data wget https://azuremlexamples.blob.core.windows.net/datasets/credit_card/default_of_credit_card_clients.csvU kunt nu het terminalvenster sluiten.
Meer informatie over deze gegevens vindt u in de UCI Machine Learning-opslagplaats.
Greep maken voor werkruimte
Voordat we in de code duiken, hebt u een manier nodig om naar uw werkruimte te verwijzen. U maakt ml_client een ingang voor de werkruimte. Vervolgens gebruikt ml_client u om resources en taken te beheren.
Voer in de volgende cel uw abonnements-id, resourcegroepnaam en werkruimtenaam in. Deze waarden zoeken:
- Selecteer in de rechterbovenhoek Azure Machine Learning-studio werkbalk de naam van uw werkruimte.
- Kopieer de waarde voor werkruimte, resourcegroep en abonnements-id in de code.
- U moet één waarde kopiëren, het gebied sluiten en plakken en vervolgens terugkomen voor de volgende waarde.
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# authenticate
credential = DefaultAzureCredential()
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)
Notitie
Het maken van MLClient maakt geen verbinding met de werkruimte. De initialisatie van de client is lui. Het wacht op de eerste keer dat de client een aanroep moet doen (dit gebeurt in de volgende codecel).
Gegevens uploaden naar cloudopslag
Azure Machine Learning maakt gebruik van Uniform Resource Identifiers (URI's), die verwijzen naar opslaglocaties in de cloud. Met een URI hebt u eenvoudig toegang tot gegevens in notebooks en taken. Gegevens-URI-indelingen lijken op de web-URL's die u in uw webbrowser gebruikt voor toegang tot webpagina's. Voorbeeld:
- Toegang tot gegevens van openbare https-server:
https://<account_name>.blob.core.windows.net/<container_name>/<folder>/<file> - Toegang tot gegevens van Azure Data Lake Gen 2:
abfss://<file_system>@<account_name>.dfs.core.windows.net/<folder>/<file>
Een Azure Machine Learning-gegevensasset is vergelijkbaar met bladwijzers van webbrowsers (favorieten). In plaats van lange opslagpaden (URI's) te onthouden die verwijzen naar uw meest gebruikte gegevens, kunt u een gegevensasset maken en die asset vervolgens openen met een beschrijvende naam.
Het maken van gegevensassets maakt ook een verwijzing naar de locatie van de gegevensbron, samen met een kopie van de metagegevens. Omdat de gegevens zich op de bestaande locatie bevinden, worden er geen extra opslagkosten in rekening gebracht en loopt u geen risico op gegevensbronintegriteit. U kunt gegevensassets maken op basis van Azure Machine Learning-gegevensarchieven, Azure Storage, openbare URL's en lokale bestanden.
Tip
Voor kleinere gegevensuploads werkt het maken van azure Machine Learning-gegevensassets goed voor het uploaden van gegevens van lokale machineresources naar cloudopslag. Deze aanpak voorkomt dat extra hulpprogramma's of hulpprogramma's nodig zijn. Voor een grotere gegevensupload is echter mogelijk een speciaal hulpprogramma of hulpprogramma vereist, bijvoorbeeld azcopy. Het opdrachtregelprogramma azcopy verplaatst gegevens naar en van Azure Storage. Meer informatie over azcopy vindt u hier.
In de volgende notebookcel wordt de gegevensasset gemaakt. Het codevoorbeeld uploadt het onbewerkte gegevensbestand naar de aangewezen cloudopslagresource.
Telkens wanneer u een gegevensasset maakt, hebt u er een unieke versie voor nodig. Als de versie al bestaat, krijgt u een foutmelding. In deze code gebruiken we de 'initial' voor de eerste keer dat de gegevens worden gelezen. Als die versie al bestaat, gaan we het maken ervan overslaan.
U kunt ook de versieparameter weglaten en er wordt een versienummer voor u gegenereerd, te beginnen met 1 en vervolgens te verhogen.
In deze zelfstudie gebruiken we de naam 'initial' als de eerste versie. In de zelfstudie Machine Learning-pijplijnen voor productie maken wordt ook gebruikgemaakt van deze versie van de gegevens, dus hier gebruiken we een waarde die u in die zelfstudie opnieuw ziet.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
# update the 'my_path' variable to match the location of where you downloaded the data on your
# local filesystem
my_path = "./data/default_of_credit_card_clients.csv"
# set the version number of the data asset
v1 = "initial"
my_data = Data(
name="credit-card",
version=v1,
description="Credit card data",
path=my_path,
type=AssetTypes.URI_FILE,
)
## create data asset if it doesn't already exist:
try:
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(
f"Data asset already exists. Name: {my_data.name}, version: {my_data.version}"
)
except:
ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
U kunt de geüploade gegevens zien door gegevens aan de linkerkant te selecteren. U ziet dat de gegevens worden geüpload en er een gegevensasset wordt gemaakt:
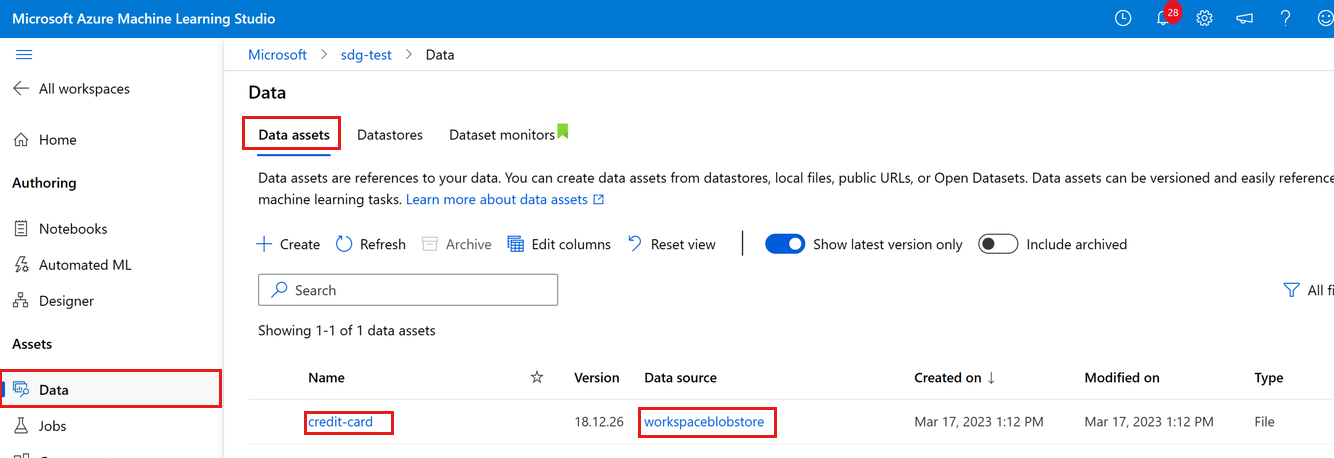
Deze gegevens hebben de naam creditcard en op het tabblad Gegevensassets kunnen we deze zien in de kolom Naam . Deze gegevens die zijn geüpload naar het standaardgegevensarchief van uw werkruimte met de naam workspaceblobstore, te zien in de kolom Gegevensbron .
Een Azure Machine Learning-gegevensarchief is een verwijzing naar een bestaand opslagaccount in Azure. Een gegevensarchief biedt de volgende voordelen:
- Een veelgebruikte en gebruiksvriendelijke API om te communiceren met verschillende opslagtypen (Blob/Files/Azure Data Lake Storage) en verificatiemethoden.
- Een eenvoudigere manier om nuttige gegevensarchieven te ontdekken wanneer u als team werkt.
- In uw scripts kunt u verbindingsgegevens verbergen voor gegevenstoegang op basis van referenties (service-principal/SAS/sleutel).
Toegang tot uw gegevens in een notebook
Pandas biedt rechtstreeks ondersteuning voor URI's. In dit voorbeeld ziet u hoe u een CSV-bestand leest uit een Azure Machine Learning-gegevensarchief:
import pandas as pd
df = pd.read_csv("azureml://subscriptions/<subid>/resourcegroups/<rgname>/workspaces/<workspace_name>/datastores/<datastore_name>/paths/<folder>/<filename>.csv")
Zoals eerder vermeld, kan het echter moeilijk worden om deze URI's te onthouden. Daarnaast moet u handmatig alle <subtekenreekswaarden> in de opdracht pd.read_csv vervangen door de werkelijke waarden voor uw resources.
U wilt gegevensassets maken voor veelgebruikte gegevens. Dit is een eenvoudigere manier om toegang te krijgen tot het CSV-bestand in Pandas:
Belangrijk
Voer in een notebookcel deze code uit om de azureml-fsspec Python-bibliotheek in uw Jupyter-kernel te installeren:
%pip install -U azureml-fsspec
import pandas as pd
# get a handle of the data asset and print the URI
data_asset = ml_client.data.get(name="credit-card", version=v1)
print(f"Data asset URI: {data_asset.path}")
# read into pandas - note that you will see 2 headers in your data frame - that is ok, for now
df = pd.read_csv(data_asset.path)
df.head()
Lees Access-gegevens uit Azure-cloudopslag tijdens interactieve ontwikkeling voor meer informatie over gegevenstoegang in een notebook.
Een nieuwe versie van de gegevensasset maken
U hebt misschien gemerkt dat de gegevens een beetje licht moeten worden opgeschoond, zodat deze geschikt zijn voor het trainen van een machine learning-model. Het heeft:
- twee headers
- een client-id-kolom; we zouden deze functie niet gebruiken in Machine Learning
- spaties in de naam van de antwoordvariabele
In vergelijking met de CSV-indeling wordt de Parquet-bestandsindeling ook een betere manier om deze gegevens op te slaan. Parquet biedt compressie en onderhoudt het schema. Gebruik daarom het volgende om de gegevens op te schonen en op te slaan in Parquet:
# read in data again, this time using the 2nd row as the header
df = pd.read_csv(data_asset.path, header=1)
# rename column
df.rename(columns={"default payment next month": "default"}, inplace=True)
# remove ID column
df.drop("ID", axis=1, inplace=True)
# write file to filesystem
df.to_parquet("./data/cleaned-credit-card.parquet")
In deze tabel ziet u de structuur van de gegevens in het oorspronkelijke default_of_credit_card_clients.csv bestand. CSV-bestand dat in een eerdere stap is gedownload. De geüploade gegevens bevatten 23 verklarende variabelen en 1 antwoordvariabele, zoals hier wordt weergegeven:
| Kolomnaam(en) | Type variabele | Beschrijving |
|---|---|---|
| X1 | Verklarende | Bedrag van het opgegeven tegoed (NT-dollar): het omvat zowel het individuele consumentenkrediet als het gezinskrediet (aanvullend). |
| X2 | Verklarende | Geslacht (1 = mannelijk; 2 = vrouw). |
| X3 | Verklarende | Onderwijs (1 = graduate school; 2 = universiteit; 3 = middelbare school; 4 = anderen). |
| X4 | Verklarende | Burgerlijke staat (1 = getrouwd; 2 = single; 3 = anderen). |
| X5 | Verklarende | Leeftijd (jaren). |
| X6-X11 | Verklarende | Geschiedenis van eerdere betaling. We hebben de afgelopen maandelijkse betalingsrecords bijgehouden (van april tot september 2005). -1 = naar behoren betalen; 1 = betalingsvertraging voor één maand; 2 = betalingsvertraging voor twee maanden; . . .; 8 = betalingsvertraging voor acht maanden; 9 = betalingsvertraging voor negen maanden en hoger. |
| X12-17 | Verklarende | Bedrag van factuuroverzicht (NT dollar) van april tot september 2005. |
| X18-23 | Verklarende | Bedrag van eerdere betaling (NT dollar) van april tot september 2005. |
| J | Respons | Standaardbetaling (Ja = 1, Nee = 0) |
Maak vervolgens een nieuwe versie van de gegevensasset (de gegevens worden automatisch geüpload naar cloudopslag). Voor deze versie voegen we een tijdwaarde toe, zodat telkens wanneer deze code wordt uitgevoerd, een ander versienummer wordt gemaakt.
from azure.ai.ml.entities import Data
from azure.ai.ml.constants import AssetTypes
import time
# Next, create a new *version* of the data asset (the data is automatically uploaded to cloud storage):
v2 = "cleaned" + time.strftime("%Y.%m.%d.%H%M%S", time.gmtime())
my_path = "./data/cleaned-credit-card.parquet"
# Define the data asset, and use tags to make it clear the asset can be used in training
my_data = Data(
name="credit-card",
version=v2,
description="Default of credit card clients data.",
tags={"training_data": "true", "format": "parquet"},
path=my_path,
type=AssetTypes.URI_FILE,
)
## create the data asset
my_data = ml_client.data.create_or_update(my_data)
print(f"Data asset created. Name: {my_data.name}, version: {my_data.version}")
Het opgeschoonde Parquet-bestand is de meest recente versiegegevensbron. Deze code toont eerst de resultatenset van de CSV-versie en vervolgens de Parquet-versie:
import pandas as pd
# get a handle of the data asset and print the URI
data_asset_v1 = ml_client.data.get(name="credit-card", version=v1)
data_asset_v2 = ml_client.data.get(name="credit-card", version=v2)
# print the v1 data
print(f"V1 Data asset URI: {data_asset_v1.path}")
v1df = pd.read_csv(data_asset_v1.path)
print(v1df.head(5))
# print the v2 data
print(
"_____________________________________________________________________________________________________________\n"
)
print(f"V2 Data asset URI: {data_asset_v2.path}")
v2df = pd.read_parquet(data_asset_v2.path)
print(v2df.head(5))
Resources opschonen
Als u van plan bent om nu door te gaan naar andere zelfstudies, gaat u verder met volgende stappen.
Rekenproces stoppen
Als u deze nu niet gaat gebruiken, stopt u het rekenproces:
- Selecteer Compute in het linkernavigatiegebied in de studio.
- Selecteer op de bovenste tabbladen Rekeninstanties
- Selecteer het rekenproces in de lijst.
- Selecteer Stoppen op de bovenste werkbalk.
Alle resources verwijderen
Belangrijk
De resources die u hebt gemaakt, kunnen worden gebruikt als de vereisten voor andere Azure Machine Learning-zelfstudies en artikelen met procedures.
Als u niet van plan bent om een van de resources te gebruiken die u hebt gemaakt, verwijdert u deze zodat er geen kosten in rekening worden gebracht:
Selecteer Resourcegroepen links in Azure Portal.
Selecteer de resourcegroep die u hebt gemaakt uit de lijst.
Selecteer Resourcegroep verwijderen.
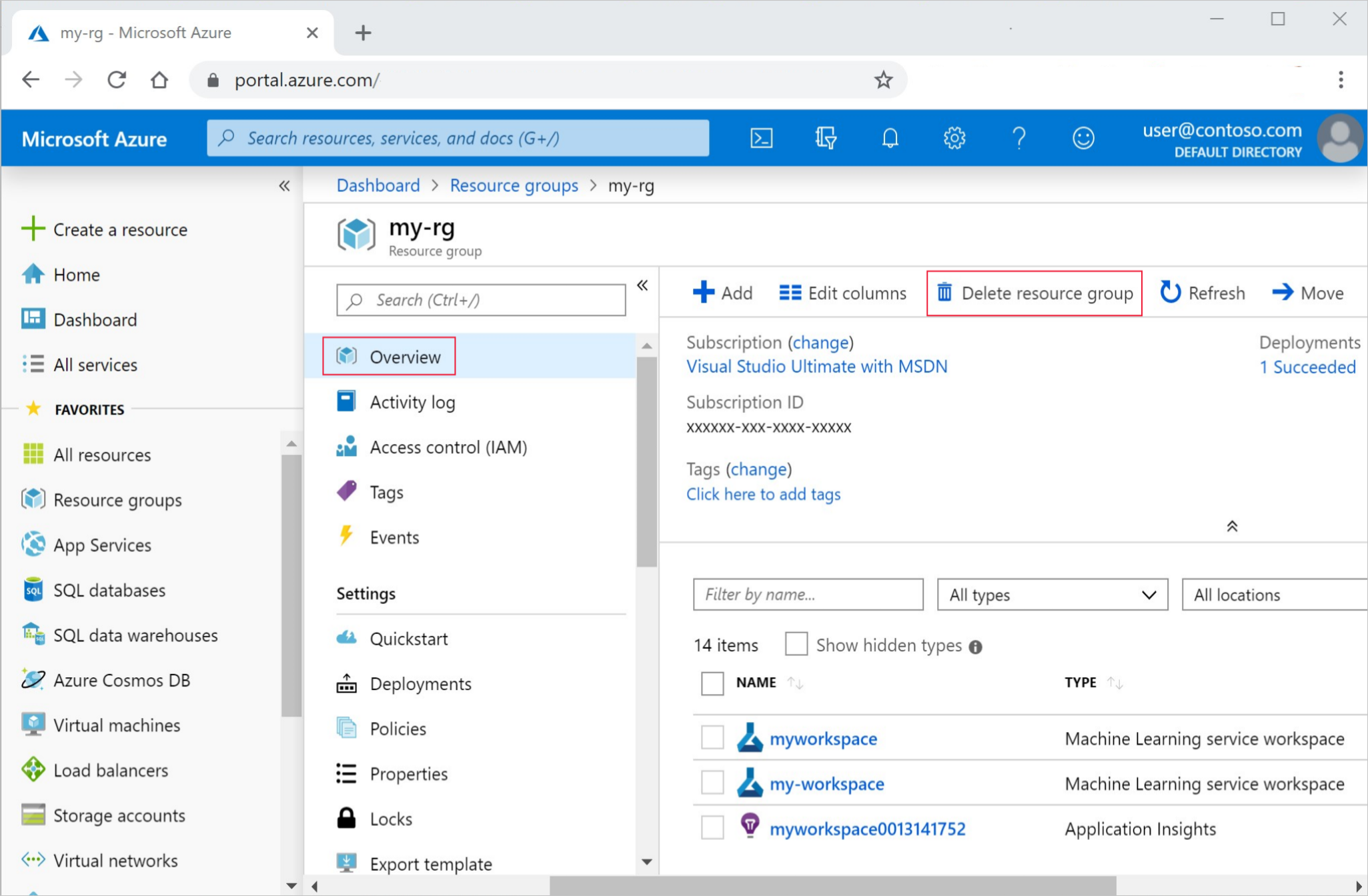
Voer de naam van de resourcegroup in. Selecteer daarna Verwijderen.
Volgende stappen
Lees Gegevensassets maken voor meer informatie over gegevensassets .
Lees Gegevensarchieven maken voor meer informatie over gegevensarchieven.
Ga verder met zelfstudies om te leren hoe u een trainingsscript ontwikkelt.