Problemen met replicatielatentie in Azure Database for MySQL - Flexibele server oplossen
VAN TOEPASSING OP: Azure Database for MySQL - Enkele server Azure Database for MySQL - Flexibele server
Azure Database for MySQL - Enkele server Azure Database for MySQL - Flexibele server
Belangrijk
Azure Database for MySQL enkele server bevindt zich op het buitengebruikstellingspad. We raden u ten zeerste aan een upgrade uit te voeren naar een flexibele Azure Database for MySQL-server. Zie Wat gebeurt er met Azure Database for MySQL Enkele server voor meer informatie over migreren naar Azure Database for MySQL Flexibele server ?
Notitie
In dit artikel wordt verwezen naar een term die microsoft niet meer gebruikt. Zodra de term uit de software wordt verwijderd, verwijderen we deze uit dit artikel.
Met de functie leesreplica kunt u gegevens van een Azure Database for MySQL-server repliceren naar een alleen-lezen replicaserver. U kunt workloads uitschalen door lees- en rapportagequery's van de toepassing naar replicaservers te routeren. Deze installatie vermindert de druk op de bronserver en verbetert de algehele prestaties en latentie van de toepassing wanneer deze wordt geschaald.
Replica's worden asynchroon bijgewerkt met behulp van de systeemeigen binaire logboekbestandstechnologie (binlog) van de MySQL-engine. Zie voor meer informatie het overzicht van de replicatieconfiguratie op basis van de positie van het binlog-bestand van MySQL.
De replicatievertraging op de secundaire leesreplica's is afhankelijk van verschillende factoren. Deze factoren omvatten, maar zijn niet beperkt tot:
- Netwerklatentie.
- Transactievolume op de bronserver.
- Rekenlaag van de bronserver en secundaire leesreplicaserver.
- Query's die worden uitgevoerd op de bronserver en de secundaire server.
In dit artikel leert u hoe u problemen met replicatielatentie in Azure Database for MySQL oplost. U krijgt ook een beter beeld van enkele veelvoorkomende oorzaken van een verhoogde replicatielatentie op replicaservers.
Notitie
Dit artikel bevat verwijzingen naar de term slave, een term die Microsoft niet meer gebruikt. Zodra de term uit de software wordt verwijderd, verwijderen we deze uit dit artikel.
Replicatieconcepten
Wanneer een binair logboek is ingeschakeld, schrijft de bronserver vastgelegde transacties naar het binaire logboek. Het binaire logboek wordt gebruikt voor replicatie. Deze functie is standaard ingeschakeld voor alle nieuw ingerichte servers die ondersteuning bieden voor maximaal 16 TB opslagruimte. Op replicaservers worden twee threads uitgevoerd op elke replicaserver. De ene thread is de IO-thread en de andere is de SQL-thread:
- De IO-thread maakt verbinding met de bronserver en vraagt bijgewerkte binaire logboeken aan. Deze thread ontvangt de binaire logboekupdates. Deze updates worden opgeslagen op een replicaserver, in een lokaal logboek dat het relaylogboek wordt genoemd.
- De SQL-thread leest het relaylogboek en past vervolgens de gegevenswijzigingen toe op replicaservers.
Replicatielatentie bewaken
Azure Database for MySQL biedt de metrische waarde voor replicatievertraging in seconden in Azure Monitor. Deze metrische waarde is alleen beschikbaar op leesreplicaservers. Dit wordt berekend door de seconds_behind_master metrische gegevens die beschikbaar zijn in MySQL.
Als u de oorzaak van een verhoogde replicatielatentie wilt begrijpen, maakt u verbinding met de replicaserver met behulp van MySQL Workbench of Azure Cloud Shell. Voer vervolgens de volgende opdracht uit.
Notitie
Vervang in uw code de voorbeeldwaarden door de naam van de replicaserver en de gebruikersnaam van de beheerder. De gebruikersnaam van de beheerder vereist @\<servername> voor Azure Database for MySQL.
mysql --host=myreplicademoserver.mysql.database.azure.com --user=myadmin@mydemoserver -p
Zo ziet het proces eruit in de Cloud Shell-terminal:
Requesting a Cloud Shell.Succeeded.
Connecting terminal...
Welcome to Azure Cloud Shell
Type "az" to use Azure CLI
Type "help" to learn about Cloud Shell
user@Azure:~$mysql -h myreplicademoserver.mysql.database.azure.com -u myadmin@mydemoserver -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 64796
Server version: 5.6.42.0 Source distribution
Copyright (c) 2000, 2020, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql>
Voer in dezelfde Cloud Shell-terminal de volgende opdracht uit:
mysql> SHOW SLAVE STATUS;
Hier volgt een typische uitvoer:
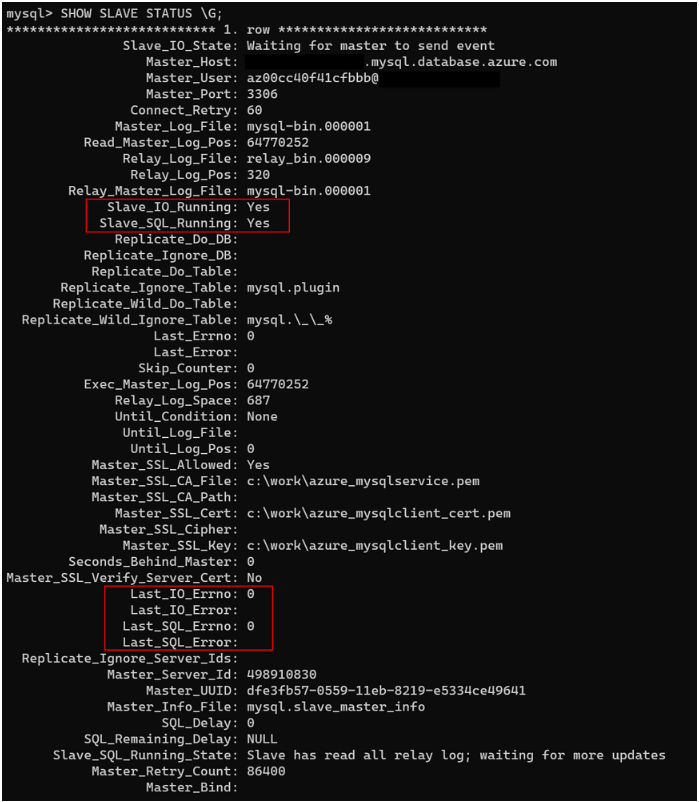
De uitvoer bevat talloze informatie. Normaal gesproken moet u zich alleen richten op de rijen die in de volgende tabel worden beschreven.
| Metrisch | Beschrijving |
|---|---|
| Slave_IO_State | Vertegenwoordigt de huidige status van de IO-thread. Normaal gesproken is de status 'Wachten op master om gebeurtenis te verzenden' als de bronserver (hoofdserver) wordt gesynchroniseerd. Een status zoals 'Verbinding maken naar master' geeft aan dat de replica de verbinding met de bronserver heeft verbroken. Controleer of de bronserver wordt uitgevoerd of controleer of een firewall de verbinding blokkeert. |
| Master_Log_File | Vertegenwoordigt het binaire logboekbestand waarnaar de bronserver schrijft. |
| Read_Master_Log_Pos | Geeft aan waar de bronserver in het binaire logboekbestand schrijft. |
| Relay_Master_Log_File | Vertegenwoordigt het binaire logboekbestand dat de replicaserver leest van de bronserver. |
| Slave_IO_Running | Geeft aan of de IO-thread wordt uitgevoerd. De waarde moet zijn Yes. Als de waarde is NO, wordt de replicatie waarschijnlijk verbroken. |
| Slave_SQL_Running | Geeft aan of de SQL-thread wordt uitgevoerd. De waarde moet zijn Yes. Als de waarde is NO, wordt de replicatie waarschijnlijk verbroken. |
| Exec_Master_Log_Pos | Geeft de positie van de Relay_Master_Log_File aan dat de replica wordt toegepast. Als er latentie is, moet deze positiereeks kleiner zijn dan Read_Master_Log_Pos. |
| Relay_Log_Space | Geeft de totale gecombineerde grootte van alle bestaande relaylogboekbestanden aan. U kunt de bovengrensgrootte controleren door een query uit te voeren SHOW GLOBAL VARIABLES zoals relay_log_space_limit. |
| Seconds_Behind_Master | Geeft de replicatielatentie in seconden weer. |
| Last_IO_Errno | Geeft de foutcode van de IO-thread weer, indien van toepassing. Zie de naslaginformatie over de mySQL-serverfout voor meer informatie over deze codes. |
| Last_IO_Error | Geeft het foutbericht van de IO-thread weer, indien van toepassing. |
| Last_SQL_Errno | Geeft de foutcode van de SQL-thread weer, indien van toepassing. Zie de naslaginformatie over de mySQL-serverfout voor meer informatie over deze codes. |
| Last_SQL_Error | Geeft het foutbericht van de SQL-thread weer, indien van toepassing. |
| Slave_SQL_Running_State | Geeft de huidige SQL-threadstatus aan. In deze toestand System lock is normaal. Het is ook normaal om een status van Waiting for dependent transaction to commit. Deze status geeft aan dat de replica wacht op andere SQL-werkthreads om doorgevoerde transacties bij te werken. |
Als Slave_IO_Running is Yes en Slave_SQL_Running is Yes, wordt de replicatie prima uitgevoerd.
Controleer vervolgens Last_IO_Errno, Last_IO_Error, Last_SQL_Errno en Last_SQL_Error. In deze velden wordt het foutnummer en het foutbericht weergegeven van de meest recente fout waardoor de SQL-thread is gestopt. Een foutnummer en 0 een leeg bericht betekent dat er geen fout is. Onderzoek eventuele niet-nulfoutwaarden door de foutcode in de naslaginformatie over het mySQL-serverfoutbericht te controleren.
Veelvoorkomende scenario's voor hoge replicatielatentie
In de volgende secties worden scenario's besproken waarin hoge replicatielatentie gebruikelijk is.
Netwerklatentie of hoog CPU-verbruik op de bronserver
Als u de volgende waarden ziet, wordt de replicatielatentie waarschijnlijk veroorzaakt door een hoge netwerklatentie of een hoog CPU-verbruik op de bronserver.
Slave_IO_State: Waiting for master to send event
Master_Log_File: the binary file sequence is larger then Relay_Master_Log_File, e.g. mysql-bin.00020
Relay_Master_Log_File: the file sequence is smaller than Master_Log_File, e.g. mysql-bin.00010
In dit geval wordt de IO-thread uitgevoerd en wordt er gewacht op de bronserver. De bronserver heeft al naar binair logboekbestand nummer 20 geschreven. De replica heeft slechts het bestand nummer 10 ontvangen. De belangrijkste factoren voor hoge replicatielatentie in dit scenario zijn netwerksnelheid of hoog CPU-gebruik op de bronserver.
In Azure kan de netwerklatentie binnen een regio doorgaans milliseconden worden gemeten. In verschillende regio's varieert de latentie van milliseconden tot seconden.
In de meeste gevallen wordt de verbindingsvertraging tussen IO-threads en de bronserver veroorzaakt door een hoog CPU-gebruik op de bronserver. De IO-threads worden langzaam verwerkt. U kunt dit probleem detecteren met behulp van Azure Monitor om het CPU-gebruik en het aantal gelijktijdige verbindingen op de bronserver te controleren.
Als u geen hoog CPU-gebruik op de bronserver ziet, kan het probleem netwerklatentie zijn. Als de netwerklatentie plotseling abnormaal hoog is, controleert u de Azure-statuspagina op bekende problemen of storingen.
Zware bursts van transacties op de bronserver
Als u de volgende waarden ziet, veroorzaakt een zware burst van transacties op de bronserver waarschijnlijk de replicatielatentie.
Slave_IO_State: Waiting for the slave SQL thread to free enough relay log space
Master_Log_File: the binary file sequence is larger then Relay_Master_Log_File, e.g. mysql-bin.00020
Relay_Master_Log_File: the file sequence is smaller then Master_Log_File, e.g. mysql-bin.00010
De uitvoer laat zien dat de replica het binaire logboek achter de bronserver kan ophalen. De replica-IO-thread geeft echter aan dat de relaylogboekruimte al vol is.
De netwerksnelheid veroorzaakt de vertraging niet. De replica probeert in te halen. Maar de bijgewerkte binaire logboekgrootte overschrijdt de bovengrens van de relaylogboekruimte.
U kunt dit probleem oplossen door het logboek voor langzame query's op de bronserver in te schakelen. Gebruik logboeken voor trage query's om langlopende transacties op de bronserver te identificeren. Stem vervolgens de geïdentificeerde query's af om de latentie op de server te verminderen.
Replicatielatentie van dit type wordt meestal veroorzaakt door de gegevensbelasting op de bronserver. Wanneer bronservers wekelijks of maandelijks gegevens laden, is replicatielatentie helaas onvermijdelijk. De replicaservers halen uiteindelijk op nadat de gegevensbelasting op de bronserver is voltooid.
Traagheid op de replicaserver
Als u de volgende waarden bekijkt, kan het probleem zich op de replicaserver bevinden.
Slave_IO_State: Waiting for master to send event
Master_Log_File: The binary log file sequence equals to Relay_Master_Log_File, e.g. mysql-bin.000191
Read_Master_Log_Pos: The position of master server written to the above file is larger than Relay_Log_Pos, e.g. 103978138
Relay_Master_Log_File: mysql-bin.000191
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
Exec_Master_Log_Pos: The position of slave reads from master binary log file is smaller than Read_Master_Log_Pos, e.g. 13468882
Seconds_Behind_Master: There is latency and the value here is greater than 0
In dit scenario ziet u in de uitvoer dat zowel de IO-thread als de SQL-thread goed worden uitgevoerd. De replica leest hetzelfde binaire logboekbestand dat de bronserver schrijft. Sommige latentie op de replicaserver weerspiegelt echter dezelfde transactie van de bronserver.
In de volgende secties worden veelvoorkomende oorzaken van dit soort latentie beschreven.
Geen primaire sleutel of unieke sleutel in een tabel
Azure Database for MySQL maakt gebruik van replicatie op basis van rijen. De bronserver schrijft gebeurtenissen naar het binaire logboek en registreert wijzigingen in afzonderlijke tabelrijen. De SQL-thread repliceert deze wijzigingen vervolgens naar de bijbehorende tabelrijen op de replicaserver. Wanneer een tabel geen primaire sleutel of unieke sleutel heeft, scant de SQL-thread alle rijen in de doeltabel om de wijzigingen toe te passen. Deze scan kan replicatievertraging veroorzaken.
In MySQL is de primaire sleutel een gekoppelde index die zorgt voor snelle queryprestaties, omdat deze geen NULL-waarden kan bevatten. Als u de InnoDB-opslagengine gebruikt, worden de tabelgegevens fysiek georganiseerd om ultrasnelle zoekopdrachten en sorteringen uit te voeren op basis van de primaire sleutel.
U wordt aangeraden een primaire sleutel toe te voegen aan tabellen in de bronserver voordat u de replicaserver maakt. Voeg primaire sleutels toe op de bronserver en maak vervolgens leesreplica's opnieuw om de replicatielatentie te verbeteren.
Gebruik de volgende query om erachter te komen welke tabellen een primaire sleutel op de bronserver missen:
select tab.table_schema as database_name, tab.table_name
from information_schema.tables tab left join
information_schema.table_constraints tco
on tab.table_schema = tco.table_schema
and tab.table_name = tco.table_name
and tco.constraint_type = 'PRIMARY KEY'
where tco.constraint_type is null
and tab.table_schema not in('mysql', 'information_schema', 'performance_schema', 'sys')
and tab.table_type = 'BASE TABLE'
order by tab.table_schema, tab.table_name;
Langlopende query's op de replicaserver
De workload op de replicaserver kan ervoor zorgen dat de SQL-thread achterloopt op de IO-thread. Langlopende query's op de replicaserver zijn een van de veelvoorkomende oorzaken van hoge replicatielatentie. U kunt dit probleem oplossen door het logboek voor trage query's op de replicaserver in te schakelen.
Trage query's kunnen het resourceverbruik verhogen of de server vertragen, zodat de replica de bronserver niet kan inhalen. In dit scenario kunt u de trage query's afstemmen. Snellere query's verhinderen de blokkering van de SQL-thread en verbeteren de replicatielatentie aanzienlijk.
DDL-query's op de bronserver
Op de bronserver kan een DDL-opdracht ALTER TABLE (Data Definition Language) lang duren. Terwijl de DDL-opdracht wordt uitgevoerd, worden mogelijk duizenden andere query's parallel uitgevoerd op de bronserver.
Wanneer de DDL wordt gerepliceerd om databaseconsistentie te garanderen, voert de MySQL-engine de DDL uit in één replicatiethread. Tijdens deze taak worden alle andere gerepliceerde query's geblokkeerd en moeten ze wachten totdat de DDL-bewerking is voltooid op de replicaserver. Zelfs online DDL-bewerkingen veroorzaken deze vertraging. DDL-bewerkingen verhogen de replicatielatentie.
Als u het logboek voor trage query's op de bronserver hebt ingeschakeld, kunt u dit latentieprobleem detecteren door te controleren op een DDL-opdracht die op de bronserver is uitgevoerd. Door indexen te verwijderen, te hernoemen en te maken, kunt u het INPLACE-algoritme voor de ALTER TABLE gebruiken. Mogelijk moet u de tabelgegevens kopiëren en de tabel opnieuw opbouwen.
Normaal gesproken wordt gelijktijdige DML ondersteund voor het INPLACE-algoritme. Maar u kunt kort een exclusieve metagegevensvergrendeling op de tabel nemen wanneer u de bewerking voorbereidt en uitvoert. Voor de INSTRUCTIE CREATE INDEX kunt u dus de componenten ALGORITHM en LOCK gebruiken om de methode voor het kopiëren van tabellen en het gelijktijdigheidsniveau voor lezen en schrijven te beïnvloeden. U kunt DML-bewerkingen nog steeds voorkomen door een FULLTEXT-index of SPATIAL-index toe te voegen.
In het volgende voorbeeld wordt een index gemaakt met behulp van ALGORITME- en LOCK-componenten.
ALTER TABLE table_name ADD INDEX index_name (column), ALGORITHM=INPLACE, LOCK=NONE;
Helaas kunt u voor een DDL-instructie waarvoor een vergrendeling is vereist, de replicatielatentie niet voorkomen. Als u de mogelijke effecten wilt verminderen, voert u deze soorten DDL-bewerkingen uit tijdens daluren, bijvoorbeeld 's nachts.
Gedowngradeerde replicaserver
Leesreplica's in Azure Database for MySQL gebruiken dezelfde serverconfiguratie als de bronserver. U kunt de configuratie van de replicaserver wijzigen nadat deze is gemaakt.
Als de replicaserver is gedowngraded, kan de workload meer resources verbruiken, wat op zijn beurt kan leiden tot replicatielatentie. Als u dit probleem wilt detecteren, gebruikt u Azure Monitor om het CPU- en geheugenverbruik van de replicaserver te controleren.
In dit scenario raden we u aan om de configuratie van de replicaserver gelijk te houden aan of groter dan de waarden van de bronserver. Met deze configuratie kan de replica de bronserver bijhouden.
Replicatielatentie verbeteren door de bronserverparameters af te stemmen
In Azure Database for MySQL is replicatie standaard geoptimaliseerd voor uitvoering met parallelle threads op replica's. Wanneer workloads met hoge gelijktijdigheid op de bronserver ertoe leiden dat de replicaserver achtervalt, kunt u de replicatielatentie verbeteren door de parameter binlog_group_commit_sync_delay op de bronserver te configureren.
De binlog_group_commit_sync_delay parameter bepaalt hoeveel microseconden de binaire logboekdoorvoering wacht voordat het binaire logboekbestand wordt gesynchroniseerd. Het voordeel van deze parameter is dat in plaats van onmiddellijk elke vastgelegde transactie toe te passen, de bronserver de binaire logboekupdates bulksgewijs verzendt. Deze vertraging vermindert IO op de replica en helpt de prestaties te verbeteren.
Het kan handig zijn om de parameter binlog_group_commit_sync_delay in te stellen op 1000 of zo. Controleer vervolgens de replicatielatentie. Stel deze parameter voorzichtig in en gebruik deze alleen voor workloads met hoge gelijktijdigheid.
Belangrijk
In de replicaserver wordt binlog_group_commit_sync_delay parameter aanbevolen als 0. Dit wordt aanbevolen omdat in tegenstelling tot de bronserver de replicaserver geen hoge gelijktijdigheid heeft en de waarde voor binlog_group_commit_sync_delay op de replicaserver per ongeluk kan toenemen.
Voor workloads met lage gelijktijdigheid die veel singleton-transacties bevatten, kan de instelling binlog_group_commit_sync_delay latentie verhogen. Latentie kan toenemen omdat de IO-thread wacht op bulkupdates voor binaire logboeken, zelfs als er slechts een paar transacties worden doorgevoerd.
Geavanceerde opties voor probleemoplossing
Als het gebruik van de opdracht status van de show slave onvoldoende informatie biedt om problemen met de replicatielatentie op te lossen, kunt u deze aanvullende opties bekijken voor informatie over welke processen actief of wachtend zijn.
De threads-tabel weergeven
In performance_schema.threads de tabel wordt de processtatus weergegeven. Een proces met de status Wachten op lock_type-vergrendeling geeft aan dat er een vergrendeling is op een van de tabellen, waardoor de replicatiethread de tabel niet kan bijwerken.
SELECT name, processlist_state, processlist_time FROM performance_schema.threads WHERE name LIKE '%slave%';
Zie Algemene threadstatussen voor meer informatie.
De replication_connection_status tabel weergeven
In de tabel performance_schema.replication_connection_status ziet u de huidige status van de I/O-replicatiethread waarmee de verbinding van de replica met de bron wordt verwerkt en deze vaker wordt gewijzigd. De tabel bevat waarden die variëren tijdens de verbinding.
SELECT * FROM performance_schema.replication_connection_status;
De replication_applier_status_by_worker tabel weergeven
In performance_schema.replication_applier_status_by_worker de tabel ziet u de status van de werkrolthreads, de laatst geziene transactie, samen met het laatste foutnummer en het laatste foutbericht, waarmee u het probleem met de transactie kunt vinden en de hoofdoorzaak kunt identificeren.
U kunt de onderstaande opdrachten uitvoeren in de replicatie van gegevens om fouten of transacties over te slaan:
az_replication_skip_counter
of
az_replication_skip_gtid_transaction
SELECT * FROM performance_schema.replication_applier_status_by_worker;
De INSTRUCTIE SHOW RELAYLOG EVENTS weergeven
De show relaylog events instructie toont de gebeurtenissen in het relaylogboek van een replica.
· Voor replicatie op basis van GITD (leesreplica) toont de instructie GTID-transactie- en binlog-bestand en de positie ervan, kunt u mysqlbinlog gebruiken om inhoud en instructies op te halen die worden uitgevoerd. · Voor de positiereplicatie van de binlog van MySQL (gebruikt voor replicatie van gegevens), worden instructies weergegeven die worden uitgevoerd, zodat u weet welke tabeltransacties worden uitgevoerd
Controleer de uitvoer van de InnoDB Standard Monitor en Vergrendelingsmonitor
U kunt ook proberen de innoDB Standard Monitor- en vergrendelingsmonitoruitvoer te controleren om vergrendelingen en impasses op te lossen en replicatievertraging te minimaliseren. De vergrendelingsmonitor is hetzelfde als de standaardmonitor, behalve dat deze aanvullende vergrendelingsgegevens bevat. Als u deze aanvullende vergrendelings- en impassegegevens wilt weergeven, voert u de opdracht show engine innodb status\G uit.
Volgende stappen
Bekijk het overzicht van de replicatie van binlog van MySQL.