Een indexeerfunctie maken in Azure AI Search
Gebruik een indexeerfunctie om het importeren en indexeren van gegevens in Azure AI Search te automatiseren. Een indexeerfunctie is een benoemd object in een zoekservice die verbinding maakt met een externe Azure-gegevensbron, gegevens leest en doorgeeft aan een zoekmachine voor indexering. Het gebruik van indexeerfuncties vermindert de hoeveelheid en complexiteit van de code die u moet schrijven aanzienlijk als u een ondersteunde gegevensbron gebruikt.
Indexeerfuncties ondersteunen twee werkstromen:
Indexering op basis van tekst, tekenreeksen en metagegevens extraheren uit tekstuele inhoud voor zoekscenario's voor volledige tekst.
Indexering op basis van vaardigheden, met behulp van ingebouwde of aangepaste vaardigheden die geïntegreerde machine learning toevoegen voor analyse over afbeeldingen en grote niet-gedifferentieerde inhoud, het extraheren of uitstellen van tekst en structuur. Indexering op basis van vaardigheden maakt zoeken mogelijk via inhoud die anders niet eenvoudig doorzoekbaar is voor volledige tekst. Zie AI-verrijking in Azure AI Search voor meer informatie.
Dit artikel is gericht op de basisstappen voor het maken van een indexeerfunctie. Afhankelijk van de gegevensbron en uw werkstroom is er mogelijk meer configuratie nodig.
Vereisten
Een ondersteunde gegevensbron die de inhoud bevat die u wilt opnemen.
Een indexeerfunctiegegevensbron waarmee een verbinding met externe gegevens wordt ingesteld.
Een zoekindex die binnenkomende gegevens kan accepteren.
De maximale limieten voor uw servicelaag overschrijden. Met de gratis laag kunnen drie objecten van elk type en 1-3 minuten indexeerfunctie worden verwerkt, of 3-10 als er een vaardighedenset is.
Indexeerpatronen
Wanneer u een indexeerfunctie maakt, is de definitie een van twee patronen: op tekst gebaseerde indexering of AI-verrijking met vaardigheden. De patronen zijn hetzelfde, behalve dat indexering op basis van vaardigheden meer definities heeft.
Indexeerfunctievoorbeeld voor indexering op basis van tekst
Indexering op basis van tekst voor zoeken in volledige tekst is de primaire use-case voor indexeerfuncties en voor deze werkstroom ziet een indexeerfunctie eruit zoals in dit voorbeeld.
{
"name": (required) String that uniquely identifies the indexer,
"description": (optional),
"dataSourceName": (required) String indicating which existing data source to use,
"targetIndexName": (required) String indicating which existing index to use,
"parameters": {
"batchSize": null,
"maxFailedItems": 0,
"maxFailedItemsPerBatch": 0,
"base64EncodeKeys": false,
"configuration": {}
},
"fieldMappings": (optional) unless field discrepancies need resolution,
"disabled": null,
"schedule": null,
"encryptionKey": null
}
Indexeerfuncties hebben de volgende vereisten:
- Een
"name"eigenschap die de indexeerfunctie uniek identificeert in de indexeerfunctieverzameling. - Een
"dataSourceName"eigenschap die verwijst naar een gegevensbronobject. Hiermee geeft u een verbinding met externe gegevens op. - Een
"targetIndexName"eigenschap die verwijst naar de doelzoekindex.
Andere parameters zijn optioneel en wijzigen uitvoeringstijdgedrag, zoals het aantal fouten dat moet worden geaccepteerd voordat de hele taak mislukt. Vereiste parameters worden opgegeven in alle indexeerfuncties en worden beschreven in de REST API-verwijzing.
Gegevensbronspecifieke indexeerfuncties voor blobs, SQL en Azure Cosmos DB bieden extra "configuration" parameters voor bronspecifiek gedrag. Als de bron bijvoorbeeld Blob Storage is, kunt u een parameter instellen die filtert op bestandsextensies: "parameters" : { "configuration" : { "indexedFileNameExtensions" : ".pdf,.docx" } }. Als de bron Azure SQL is, kunt u een time-outparameter voor query's instellen.
Veldtoewijzingen worden gebruikt om bron-naar-doelvelden expliciet toe te wijzen als er verschillen zijn op naam of type tussen een veld in de gegevensbron en een veld in de zoekindex.
Standaard wordt een indexeerfunctie onmiddellijk uitgevoerd wanneer u deze in de zoekservice maakt. Als u niet wilt dat de indexeerfunctie wordt uitgevoerd, stelt "disabled" u deze in op true bij het maken van de indexeerfunctie.
U kunt ook een schema opgeven of een versleutelingssleutel instellen voor aanvullende versleuteling van de definitie van de indexeerfunctie.
Indexeerfunctievoorbeeld voor indexering op basis van vaardigheden
Indexeerfuncties stimuleren ook AI-verrijking. Alle bovenstaande eigenschappen en parameters voor toepassing, maar de volgende extra eigenschappen zijn specifiek voor AI-verrijking: "skillSetName", "cache", . "outputFieldMappings"
{
"name": (required) String that uniquely identifies the indexer,
"dataSourceName": (required) String, provides raw content that will be enriched,
"targetIndexName": (required) String, name of an existing index,
"skillsetName" : (required for AI enrichment) String, name of an existing skillset,
"cache": {
"storageConnectionString" : (required if you enable the cache) Connection string to a blob container,
"enableReprocessing": true
},
"parameters": { },
"fieldMappings": (optional) Maps fields in the underlying data source to fields in an index,
"outputFieldMappings" : (required) Maps skill outputs to fields in an index,
}
AI-verrijking is een eigen onderwerpgebied en valt buiten het bereik van dit artikel. Begin voor meer informatie met AI-verrijking, vaardighedensets in Azure AI Search, maak een vaardighedenset, uitvoervelden voor kaartverrijking en schakel caching in voor AI-verrijking.
Externe gegevens voorbereiden
Indexeerfuncties werken met gegevenssets. Wanneer u een indexeerfunctie uitvoert, wordt er verbinding gemaakt met uw gegevensbron, worden de gegevens opgehaald uit de container of map, eventueel geserialiseerd in JSON voordat deze wordt doorgegeven aan de zoekmachine voor indexering. In deze sectie worden de vereisten beschreven voor binnenkomende gegevens voor indexering op basis van tekst.
| Brongegevens | Opdrachten |
|---|---|
| JSON-documenten | Zorg ervoor dat de structuur of vorm van binnenkomende gegevens overeenkomt met het schema van uw zoekindex. De meeste zoekindexen zijn redelijk vlak, waarbij de verzameling velden bestaat uit velden op hetzelfde niveau. Hiërarchische of geneste structuren zijn echter mogelijk via complexe velden en verzamelingen. |
| Relationeel | Geef deze op als een afgevlakte rijset, waarbij elke rij een volledig of gedeeltelijk zoekdocument in de index wordt. Als u relationele gegevens in een rijset wilt afvlakken, moet u een SQL-weergave maken of een query maken die bovenliggende en onderliggende records in dezelfde rij retourneert. De ingebouwde voorbeeldgegevensset hotels is bijvoorbeeld een SQL-database met 50 records (één voor elk hotel), gekoppeld aan ruimterecords in een gerelateerde tabel. Met de query waarmee de collectieve gegevens in een rijset worden platgemaakt, worden alle kamergegevens in JSON-documenten in elke hotelrecord ingesloten. De informatie over de ingesloten ruimte wordt gegenereerd door een query die gebruikmaakt van een FOR JSON AUTO-component . Meer informatie over deze techniek vindt u in het definiëren van een query die ingesloten JSON retourneert. Dit is slechts één voorbeeld; u kunt andere benaderingen vinden die hetzelfde resultaat opleveren. |
| Bestanden | Een indexeerfunctie maakt doorgaans één zoekdocument voor elk bestand, waarbij het zoekdocument bestaat uit velden voor inhoud en metagegevens. Afhankelijk van het bestandstype kan de indexeerfunctie soms één bestand parseren in meerdere zoekdocumenten. In een CSV-bestand kan elke rij bijvoorbeeld een zelfstandig zoekdocument worden. |
Houd er rekening mee dat u alleen doorzoekbare en filterbare gegevens hoeft op te halen:
- Doorzoekbare gegevens zijn tekst.
- Filterbare gegevens zijn alfanumeriek.
Azure AI Search kan in geen enkele indeling zoeken op binaire gegevens, hoewel het tekstbeschrijvingen van afbeeldingsbestanden (zie AI-verrijking) kan extraheren en afleiden om doorzoekbare inhoud te maken. Op dezelfde manier kan grote tekst worden opgesplitst en geanalyseerd door modellen in natuurlijke taal om structuur of relevante informatie te vinden, waardoor nieuwe inhoud wordt gegenereerd die u aan een zoekdocument kunt toevoegen.
Aangezien indexeerfuncties geen gegevensproblemen oplossen, zijn er mogelijk andere vormen van gegevensopschoning of manipulatie nodig. Raadpleeg de productdocumentatie van uw Azure-databaseproduct voor meer informatie.
Een gegevensbron voorbereiden
Indexeerfuncties vereisen een gegevensbron die het type, de container en de verbinding aangeeft.
Zorg ervoor dat u een ondersteund gegevensbrontype gebruikt.
Maak een gegevensbrondefinitie . De volgende lijst is een aantal van de meest gebruikte gegevensbronnen:
Als de gegevensbron een database is, zoals Azure SQL of Cosmos DB, schakelt u wijzigingen bijhouden in. Azure Storage heeft ingebouwde wijzigingen bijhouden via de
LastModifiedeigenschap op elke blob, elk bestand en elke tabel. In de bovenstaande koppelingen voor de verschillende gegevensbronnen wordt uitgelegd welke methoden voor het bijhouden van wijzigingen worden ondersteund door indexeerfuncties.
Een index voorbereiden
Indexeerfuncties vereisen ook een zoekindex. Zoals u weet, geven indexeerfuncties gegevens door aan de zoekmachine voor indexering. Net zoals indexeerfuncties eigenschappen hebben die het gedrag van de uitvoering bepalen, heeft een indexschema eigenschappen die van invloed zijn op de manier waarop tekenreeksen worden geïndexeerd (alleen tekenreeksen worden geanalyseerd en tokenized).
Begin met een zoekindex maken.
Stel de veldenverzameling en veldkenmerken in.
Velden zijn de enige receptoren van externe inhoud. Afhankelijk van hoe de velden worden toegeschreven in het schema, worden de waarden voor elk veld geanalyseerd, tokenized of opgeslagen als verbatimtekenreeksen voor filters, fuzzy zoekopdrachten en typeaheadquery's.
Indexeerfuncties kunnen bronvelden automatisch toewijzen aan doelindexvelden wanneer de namen en typen gelijkwaardig zijn. Als een veld niet impliciet kan worden toegewezen, moet u er rekening mee houden dat u een expliciete veldtoewijzing kunt definiëren waarmee de indexeerfunctie wordt geïnformeerd hoe de inhoud moet worden gerouteerd.
Controleer de analysetoewijzingen voor elk veld. Analyzers kunnen tekenreeksen transformeren. Daarom kunnen geïndexeerde tekenreeksen afwijken van wat u hebt doorgegeven. U kunt de effecten van analyseanalyses evalueren met behulp van Analyze Text (REST). Zie Analyzers voor tekstverwerking voor meer informatie over analyse.
Tijdens het indexeren controleert een indexeerfunctie alleen veldnamen en -typen. Er is geen validatiestap die ervoor zorgt dat binnenkomende inhoud juist is voor het bijbehorende zoekveld in de index.
Een indexeerfunctie maken
Wanneer u klaar bent om een indexeerfunctie te maken voor een externe zoekservice, hebt u een zoekclient nodig. Een zoekclient kan Azure Portal, een REST-client of code zijn waarmee een indexeerclient wordt geïnstitueert. We raden de Azure-portal of REST API's aan voor vroege ontwikkeling en proof-of-concept-tests.
Meld u aan bij het Azure-portaal.
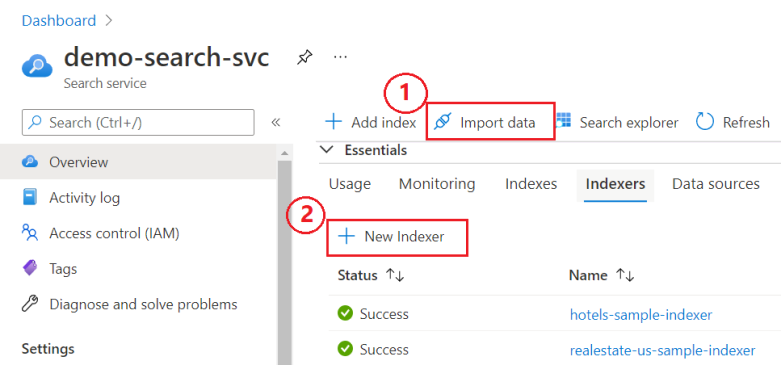
Kies op de pagina Overzicht van de zoekservice uit twee opties:
Wizard Gegevens importeren. De wizard is uniek omdat alle vereiste elementen worden gemaakt. Voor andere benaderingen is een vooraf gedefinieerde gegevensbron en index vereist.
Nieuwe indexeerfunctie, een visuele editor voor het opgeven van een indexeerfunctiedefinitie.
In de volgende schermopname ziet u waar u deze functies kunt vinden in de portal.
De indexeerfunctie uitvoeren
Standaard wordt een indexeerfunctie onmiddellijk uitgevoerd wanneer u deze in de zoekservice maakt. U kunt dit gedrag overschrijven door in te stellen "disabled" op true in de definitie van de indexeerfunctie. De uitvoering van de indexeerfunctie is het moment waarop u erachter komt of er problemen zijn met verbindingen, veldtoewijzingen of vaardighedensetconstructie.
Er zijn verschillende manieren om een indexeerfunctie uit te voeren:
Uitvoeren bij het maken of bijwerken van de indexeerfunctie (standaard).
Voer op aanvraag uit wanneer er geen wijzigingen in de definitie zijn of voorafgaan aan het opnieuw instellen voor volledige indexering. Zie Indexeerfuncties uitvoeren of opnieuw instellen voor meer informatie.
Plan de verwerking van de indexeerfunctie om de uitvoering met regelmatige tussenpozen aan te roepen.
Geplande uitvoering wordt meestal geïmplementeerd wanneer u incrementele indexering nodig hebt, zodat u de meest recente wijzigingen kunt ophalen. Als zodanig heeft de planning een afhankelijkheid van wijzigingsdetectie.
Indexeerfuncties zijn een van de weinige subsystemen die uitgaande aanroepen naar andere Azure-resources maken. In termen van Azure-rollen hebben indexeerfuncties geen afzonderlijke identiteiten: een verbinding van de zoekmachine naar een andere Azure-resource wordt gemaakt met behulp van de door het systeem of door de gebruiker toegewezen beheerde identiteit van een zoekservice. Als de indexeerfunctie verbinding maakt met een Azure-resource in een virtueel netwerk, moet u een gedeelde privékoppeling voor die verbinding maken. Zie de beveiliging in Azure AI Search voor meer informatie over beveiligde verbindingen.
Resultaten controleren
Controleer de status van de indexeerfunctie om te controleren op de status. Geslaagde uitvoering kan nog steeds waarschuwingen en meldingen bevatten. Zorg ervoor dat u zowel geslaagde als mislukte statusmeldingen controleert voor meer informatie over de taak.
Voer voor inhoudsverificatie query's uit op de ingevulde index die volledige documenten of geselecteerde velden retourneert.
Wijzigingsdetectie en interne status
Als uw gegevensbron wijzigingsdetectie ondersteunt, kan een indexeerfunctie onderliggende wijzigingen in de gegevens detecteren en alleen de nieuwe of bijgewerkte documenten op elke indexeerfunctie uitvoeren, waardoor ongewijzigde inhoud ongewijzigd blijft. Als de uitvoeringsgeschiedenis van de indexeerfunctie aangeeft dat een uitvoering is geslaagd met 0/0 verwerkte documenten, betekent dit dat de indexeerfunctie geen nieuwe of gewijzigde rijen of blobs in de onderliggende gegevensbron heeft gevonden.
Wijzigingsdetectielogica is ingebouwd in de gegevensplatformen. Hoe een indexeerfunctie wijzigingsdetectie ondersteunt, verschilt per gegevensbron:
Azure Storage heeft ingebouwde wijzigingsdetectie, wat betekent dat een indexeerfunctie nieuwe en bijgewerkte documenten automatisch kan herkennen. Blob Storage, Azure Table Storage en Azure Data Lake Storage Gen2 stempelen elke blob of rijupdate met een datum en tijd. Een indexeerfunctie gebruikt deze informatie automatisch om te bepalen welke documenten moeten worden bijgewerkt in de index. Zie Detectie verwijderen met indexeerfuncties voor Azure Storage in Azure AI Search voor meer informatie over verwijderingsdetectie.
Clouddatabasetechnologieën bieden optionele functies voor wijzigingsdetectie in hun platformen. Voor deze gegevensbronnen is wijzigingsdetectie niet automatisch. U moet opgeven in de definitie van de gegevensbron welk beleid wordt gebruikt:
Indexeerfuncties houden het laatste document bij dat door de gegevensbron is verwerkt via een interne hoge watermarkering. De markering wordt nooit weergegeven in de API, maar intern houdt de indexeerfunctie bij waar deze is gestopt. Wanneer het indexeren hervat, ofwel via een geplande uitvoering of een aanroep op aanvraag, verwijst de indexeerfunctie naar het hoogwaterteken, zodat deze kan worden opgehaald waar het was gebleven.
Als u de hoge watermarkering moet wissen om volledig opnieuw te indexeren, kunt u De indexeerfunctie opnieuw instellen gebruiken. Voor selectiever opnieuw indexeren gebruikt u Vaardigheden opnieuw instellen of Documenten opnieuw instellen. Via de reset-API's kunt u de interne status wissen en ook de cache leegmaken als u incrementele verrijking hebt ingeschakeld. Zie Indexeerfuncties, vaardigheden en documenten uitvoeren of opnieuw instellen voor meer achtergrond en vergelijking van elke optie voor opnieuw instellen.