Architectuur van toegewezen SQL-pool (voorheen SQL DW) in Azure Synapse Analytics
Azure Synapse Analytics is een analyseservice die zakelijke datawarehousing en big data-analyses combineert. Het biedt u de vrijheid om gegevens op uw voorwaarden op te vragen.
Notitie
Bekijk deze video waarin de verbeteringen voor gegevensverplaatsing worden uitgelegd voor meer informatie over Azure Synapse Analytics.
Synapse SQL-architectuuronderdelen
Toegewezen SQL-pool (voorheen SQL DW) maakt gebruik van een uitschaalarchitectuur om rekenkundige verwerking van gegevens over meerdere knooppunten te distribueren. De schaaleenheid is een abstractie van rekenkracht die een datawarehouse-eenheid wordt genoemd. De berekening staat los van de opslag, waarmee u de rekenkracht onafhankelijk van de gegevens in uw systeem kunt schalen.
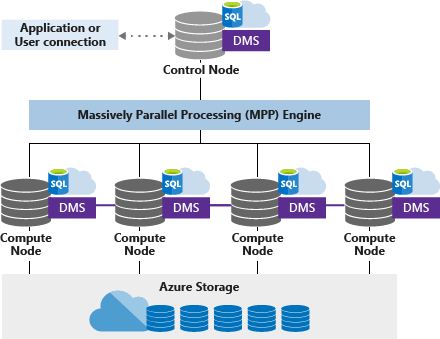
Toegewezen SQL-pool (voorheen SQL DW) maakt gebruik van een architectuur op basis van knooppunten. Toepassingen maken verbinding met T-SQL-opdrachten en geven deze uit aan een besturingsknooppunt. Het beheerknooppunt fungeert als host voor de gedistribueerde query-engine, waarmee query's voor parallelle verwerking worden geoptimaliseerd en vervolgens bewerkingen worden doorgegeven aan rekenknooppunten om hun werk parallel uit te voeren.
De rekenknooppunten slaan alle gebruikersgegevens op in Azure Storage en voeren de parallelle query's uit. De DMS (Data Movement Service) is een interne service op systeemniveau die de gegevens naar de knooppunten verplaatst om tegelijkertijd query's te kunnen uitvoeren en nauwkeurige resultaten te retourneren.
Met losgekoppelde opslag en rekenkracht kunt u het volgende doen wanneer u een toegewezen SQL-pool (voorheen SQL DW) gebruikt:
- Rekenkracht onafhankelijk van grootte, ongeacht uw opslagbehoeften.
- Rekenkracht vergroten of verkleinen, binnen een toegewezen SQL-pool (voorheen SQL DW), zonder gegevens te verplaatsen.
- De rekencapaciteit onderbreekt terwijl gegevens intact blijven, zodat u alleen betaalt voor opslag.
- De rekencapaciteit hervatten tijdens werktijden.
Azure Storage
Toegewezen SQL-pool SQL (voorheen SQL DW) maakt gebruik van Azure Storage om uw gebruikersgegevens veilig te houden. Omdat uw gegevens worden opgeslagen en beheerd door Azure Storage, worden er afzonderlijke kosten in rekening gebracht voor uw opslagverbruik. De gegevens worden in distributies geshard om de prestaties van het systeem te optimaliseren. Bij het definiëren van de tabel kunt u kiezen welk sharding-patroon u wilt gebruiken om de gegevens te distribueren. Deze shardingpatronen worden ondersteund:
- Hash
- Round Robin
- Repliceren
Beheerknooppunt
Het beheerknooppunt is het brein van de architectuur. Het is de front-end met interactie met alle toepassingen en verbindingen. De gedistribueerde query-engine wordt uitgevoerd op het besturingsknooppunt om parallelle query's te optimaliseren en te coördineren. Wanneer u een T-SQL-query verzendt, transformeert het besturingsknooppunt deze in query's die parallel op elke distributie worden uitgevoerd.
Rekenknooppunten
De rekenknooppunten leveren de rekenkracht. Distributies worden toegewezen aan rekenknooppunten voor verwerking. Naarmate u voor meer rekenresources betaalt, worden distributies opnieuw toegewezen aan beschikbare rekenknooppunten. Het aantal rekenknooppunten varieert van 1 tot 60 en wordt bepaald door het serviceniveau voor Synapse SQL.
Elk rekenknooppunt heeft een knooppunt-id die zichtbaar is in systeemweergaven. U kunt de id van het rekenknooppunt zien door te zoeken naar de kolom node_id in systeemweergaven waarvan de namen beginnen met sys.pdw_nodes. Zie Synapse SQL-systeemweergaven voor een lijst met deze systeemweergaven.
Data Movement Service
Data Movement Service (DMS) is de technologie voor gegevenstransport die de gegevensverplaatsing tussen de rekenknooppunten coördineert. Voor sommige query's is gegevensverplaatsing vereist om ervoor te zorgen dat de parallelle query's nauwkeurige resultaten retourneren. Wanneer gegevensverplaatsing is vereist, zorgt DMS ervoor dat de juiste gegevens naar de juiste locatie worden opgehaald.
Distributies
Een distributie is de basiseenheid voor opslag en verwerking van parallelle query's die op gedistribueerde gegevens worden uitgevoerd. Wanneer Synapse SQL een query uitvoert, wordt het werk onderverdeeld in 60 kleinere query's die parallel worden uitgevoerd.
Elk van de 60 kleinere query's wordt uitgevoerd op een van de gegevensdistributies. Elk rekenknooppunt beheert een of meer van de 60 distributies. Een toegewezen SQL-pool (voorheen SQL DW) met maximale rekenresources heeft één distributie per rekenknooppunt. Een toegewezen SQL-pool (voorheen SQL DW) met minimale rekenresources heeft alle distributies op één rekenknooppunt.
Notitie
Zie de Azure Synapse SQL Distribution Advisor voor aanbevelingen over de beste distributiestrategie voor tabellen die u kunt gebruiken op basis van uw workloads.
Met hash gedistribueerde tabellen
Een met hash gedistribueerde tabel kan de hoogste queryprestaties leveren voor samenvoegingen en aggregaties in grotere tabellen.
Als u gegevens in een gedistribueerde hashtabel wilt sharden, wordt een hash-functie gebruikt om elke rij deterministisch toe te wijzen aan één distributie. In de tabeldefinitie wordt een van de kolommen ingesteld als de distributiekolom. De hashfunctie maakt gebruik van de waarden in de distributiekolom om elke rij toe te wijzen aan een distributie.
In het volgende diagram ziet u hoe een volledige (niet-gedistribueerde tabel) wordt opgeslagen als een door hash gedistribueerde tabel.

- Elke rij behoort tot één distributie.
- Een deterministisch hash-algoritme wijst elke rij toe aan één distributie.
- Het aantal tabelrijen per distributie varieert, zoals wordt weergegeven door de verschillende grootten van tabellen.
Er zijn prestatieoverwegingen voor de selectie van een distributiekolom, zoals uniekheid, scheeftrekken van gegevens en de typen query's die op het systeem worden uitgevoerd.
Met round robin gedistribueerde tabellen
Een round robin-tabel is de eenvoudigste tabel voor het maken en leveren van snelle prestaties wanneer deze wordt gebruikt als faseringstabel voor laden.
Een met round robin gedistribueerde tabel distribueert de gegevens gelijkmatig in de tabel, maar zonder verdere optimalisatie. Een distributie wordt eerst willekeurig gekozen en vervolgens worden buffers van rijen opeenvolgend toegewezen aan distributies. In een round robin-tabel kunnen gegevens snel worden geladen. De prestaties van query's van met hash gedistribueerde tabellen zijn echter vaak beter. Joins voor round robin-tabellen vereisen het opnieuw opvragen van gegevens, wat extra tijd kost.
Gerepliceerde tabellen
Een gerepliceerde tabel biedt de snelste prestaties van query's voor kleine tabellen.
Een tabel die wordt gerepliceerd, slaat een volledige kopie van de tabel op elk rekenknooppunt in de cache op. Hierdoor hoeven de gegevens niet te worden overgedragen tussen rekenknooppunten voor een samenvoeging of aggregatie. Gerepliceerde tabellen zijn het meest geschikt als het gaat om kleine tabellen. Extra opslag is vereist en er is extra overhead die wordt gemaakt bij het schrijven van gegevens, waardoor grote tabellen onpraktisch zijn.
In het onderstaande diagram ziet u een gerepliceerde tabel die in de cache is opgeslagen in de eerste distributie op elk rekenknooppunt.

Volgende stappen
Nu u iets weet over Azure Synapse, leert u hoe u snel een toegewezen SQL-pool (voorheen SQL DW) maakt en voorbeeldgegevens laadt. Als u niet bekend bent met Azure, kan de Azure-woordenlijst handig zijn bij het opzoeken van nieuwe terminologie. Of bekijk enkele van deze andere Azure Synapse-resources.