Prestaties afstemmen met geordende en geclusterde columnstore-index
Van toepassing op: toegewezen SQL-pools van Azure Synapse Analytics, SQL Server 2022 (16.x) en hoger
Wanneer gebruikers een query uitvoeren op een columnstore-tabel in een toegewezen SQL-pool, controleert het optimalisatieprogramma de minimum- en maximumwaarden die zijn opgeslagen in elk segment. Segmenten die buiten de grenzen van het querypredicaat vallen, worden niet gelezen van schijf naar geheugen. Een query kan sneller worden voltooid als het aantal segmenten dat moet worden gelezen en de totale grootte klein is.
Geordende versus niet-geordende geclusterde columnstore-index
Standaard maakt een intern onderdeel (opbouwfunctie voor indexen) voor elke tabel die is gemaakt zonder een indexoptie een niet-geordende geclusterde columnstore-index (CCI). Gegevens in elke kolom worden gecomprimeerd in een afzonderlijk CCI-rijgroepsegment. Er zijn metagegevens voor het waardebereik van elk segment, zodat segmenten die zich buiten de grenzen van het querypredicaat bevinden, niet van de schijf worden gelezen tijdens het uitvoeren van de query. CCI biedt het hoogste niveau van gegevenscompressie en vermindert de grootte van segmenten om te lezen, zodat query's sneller kunnen worden uitgevoerd. Omdat de opbouwfunctie voor indexen echter geen gegevens sorteert voordat ze in segmenten worden gecomprimeerd, kunnen er segmenten met overlappende waardebereiken optreden, waardoor query's meer segmenten van schijf lezen en langer duren om te voltooien.
Geclusterde columnstore-indexen door efficiënte segmentverwijdering in te schakelen, wat resulteert in veel snellere prestaties door grote hoeveelheden geordende gegevens over te slaan die niet overeenkomen met het querypredicaat. Bij het maken van een geordende CCI sorteert de toegewezen SQL-poolengine de bestaande gegevens in het geheugen op volgordesleutel(s) voordat de opbouwfunctie voor indexen deze in indexsegmenten comprimeert. Met gesorteerde gegevens wordt de overlapping van segmenten verminderd, waardoor query's een efficiëntere segmentuitschakeling en dus snellere prestaties hebben omdat het aantal segmenten dat van de schijf moet worden gelezen, kleiner is. Als alle gegevens in één keer in het geheugen kunnen worden gesorteerd, kan overlappende segmenten worden vermeden. Vanwege grote tabellen in datawarehouses gebeurt dit scenario niet vaak.
Als u de segmentbereiken voor een kolom wilt controleren, voert u de volgende opdracht uit met de tabelnaam en kolomnaam:
SELECT o.name, pnp.index_id,
cls.row_count, pnp.data_compression_desc,
pnp.pdw_node_id, pnp.distribution_id, cls.segment_id,
cls.column_id,
cls.min_data_id, cls.max_data_id,
cls.max_data_id-cls.min_data_id as difference
FROM sys.pdw_nodes_partitions AS pnp
JOIN sys.pdw_nodes_tables AS Ntables ON pnp.object_id = NTables.object_id AND pnp.pdw_node_id = NTables.pdw_node_id
JOIN sys.pdw_table_mappings AS Tmap ON NTables.name = TMap.physical_name AND substring(TMap.physical_name,40, 10) = pnp.distribution_id
JOIN sys.objects AS o ON TMap.object_id = o.object_id
JOIN sys.pdw_nodes_column_store_segments AS cls ON pnp.partition_id = cls.partition_id AND pnp.distribution_id = cls.distribution_id
JOIN sys.columns as cols ON o.object_id = cols.object_id AND cls.column_id = cols.column_id
WHERE o.name = '<Table Name>' and cols.name = '<Column Name>' and TMap.physical_name not like '%HdTable%'
ORDER BY o.name, pnp.distribution_id, cls.min_data_id;
Notitie
In een geordende CCI-tabel worden de nieuwe gegevens die het resultaat zijn van dezelfde batch DML- of gegevenslaadbewerkingen binnen die batch gesorteerd. Er is geen globale sortering voor alle gegevens in de tabel. Gebruikers kunnen de bestelde CCI opnieuw opbouwen om alle gegevens in de tabel te sorteren. In een toegewezen SQL-pool is de columnstore-index REBUILD een offlinebewerking. Voor een gepartitioneerde tabel wordt DE REBUILD gepartitioneerd met één partitie tegelijk. Gegevens in de partitie die opnieuw wordt opgebouwd, zijn 'offline' en niet beschikbaar totdat de REBUILD voor die partitie is voltooid.
Queryprestaties
De prestatieverbetering van een query met een geordende CCI is afhankelijk van de querypatronen, de grootte van gegevens, hoe goed de gegevens zijn gesorteerd, de fysieke structuur van segmenten en de DWU en resourceklasse die zijn gekozen voor de uitvoering van de query. Gebruikers moeten al deze factoren controleren voordat ze de volgordekolommen kiezen bij het ontwerpen van een geordende CCI-tabel.
Query's met al deze patronen worden doorgaans sneller uitgevoerd met geordende CCI.
- De query's hebben gelijkheid, ongelijkheid of bereikpredicaten
- De predicaatkolommen en de geordende CCI-kolommen zijn hetzelfde.
In dit voorbeeld bevat tabel T1 een geclusterde columnstore-index die is gerangschikt in de volgorde van Col_C, Col_B en Col_A.
CREATE CLUSTERED COLUMNSTORE INDEX MyOrderedCCI ON T1
ORDER (Col_C, Col_B, Col_A);
De prestaties van query 1 en query 2 kunnen meer profiteren van geordende CCI dan de andere query's, omdat ze verwijzen naar alle geordende CCI-kolommen.
-- Query #1:
SELECT * FROM T1 WHERE Col_C = 'c' AND Col_B = 'b' AND Col_A = 'a';
-- Query #2
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_C = 'c' AND Col_A = 'a';
-- Query #3
SELECT * FROM T1 WHERE Col_B = 'b' AND Col_A = 'a';
-- Query #4
SELECT * FROM T1 WHERE Col_A = 'a' AND Col_C = 'c';
Prestaties bij het laden van gegevens
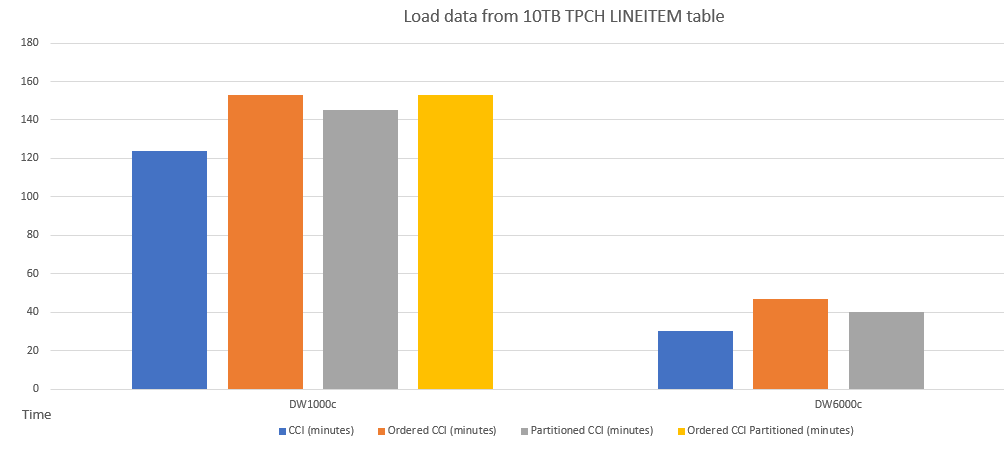
De prestaties van het laden van gegevens in een geordende CCI-tabel zijn vergelijkbaar met een gepartitioneerde tabel. Het laden van gegevens in een geordende CCI-tabel kan langer duren dan een niet-geordende CCI-tabel vanwege de gegevenssorteerbewerking, maar query's kunnen daarna sneller worden uitgevoerd met geordende CCI.
Hier volgt een voorbeeld van een vergelijking van prestaties van het laden van gegevens in tabellen met verschillende schema's.
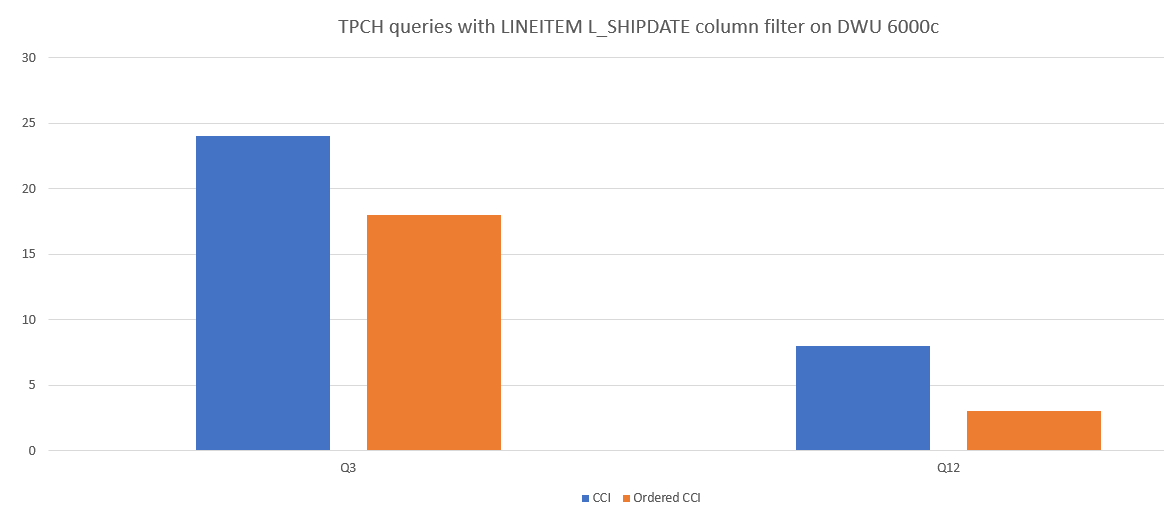
Hier volgt een voorbeeld van een vergelijking van queryprestaties tussen CCI en geordende CCI.
Overlappende segmenten verminderen
Het aantal overlappende segmenten is afhankelijk van de grootte van de gegevens die moeten worden gesorteerd, het beschikbare geheugen en de maximale mate van parallelle uitvoering (MAXDOP) tijdens het maken van geordende CCI. De volgende strategieën verminderen segmentovereen bij het maken van geordende CCI.
Gebruik
xlargercresourceklasse op een hogere DWU om meer geheugen toe te staan voor het sorteren van gegevens voordat de opbouwfunctie voor indexen de gegevens in segmenten comprimeert. Eenmaal in een indexsegment kan de fysieke locatie van de gegevens niet worden gewijzigd. Er is geen gegevenssorteerbewerking binnen een segment of tussen segmenten.Maak een geordende CCI met
OPTION (MAXDOP = 1). Elke thread die wordt gebruikt voor het maken van geordende CCI, werkt op een subset van gegevens en sorteert deze lokaal. Er is geen globale sortering op gegevens gesorteerd op verschillende threads. Het gebruik van parallelle threads kan de tijd verminderen om een geordende CCI te maken, maar genereert meer overlappende segmenten dan het gebruik van één thread. Het gebruik van één schroefdraadbewerking levert de hoogste compressiekwaliteit op. Bijvoorbeeld:
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Notitie
Op dit moment wordt in toegewezen SQL-pools in Azure Synapse Analytics de optie MAXDOP alleen ondersteund bij het maken van een geordende CCI-tabel met behulp van CREATE TABLE AS SELECT de opdracht . Het maken van een geordende CCI via CREATE INDEX of CREATE TABLE biedt geen ondersteuning voor de maxdop-optie. Deze beperking is niet van toepassing op SQL Server 2022 en latere versies, waar u MAXDOP kunt opgeven met de CREATE INDEX opdrachten ofCREATE TABLE.
- Sorteer de gegevens vooraf op de sorteersleutel(s) voordat u ze in tabellen laadt.
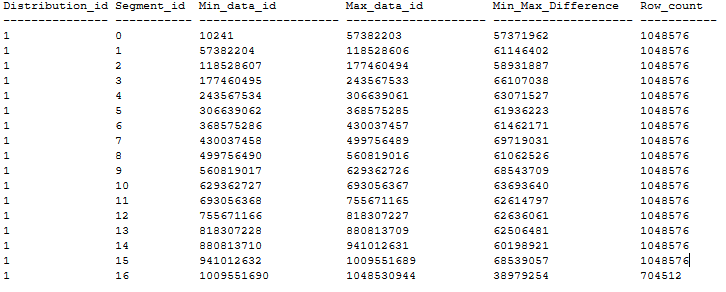
Hier volgt een voorbeeld van een geordende CCI-tabeldistributie met nul overlappende segmenten volgens de bovenstaande aanbevelingen. De geordende CCI-tabel wordt gemaakt in een DWU1000c-database via CTAS op basis van een heaptabel van 20 GB met behulp van MAXDOP 1 en xlargerc. De CCI is geordend in een BIGINT-kolom zonder duplicaten.
Geordende CCI maken voor grote tabellen
Het maken van een geordende CCI is een offlinebewerking. Voor tabellen zonder partities zijn de gegevens pas toegankelijk voor gebruikers als het geordende proces voor het maken van de CCI is voltooid. Omdat de engine voor gepartitioneerde tabellen de geordende CCI-partitie per partitie maakt, hebben gebruikers nog steeds toegang tot de gegevens in partities waar geordende CCI-creatie niet wordt uitgevoerd. U kunt deze optie gebruiken om de downtime tijdens het maken van bestelde CCI op grote tabellen te minimaliseren:
- Maak partities op de grote doeltabel (genaamd
Table_A). - Maak een lege geordende CCI-tabel (met de naam
Table_B) met dezelfde tabel en hetzelfde partitieschema alsTable_A. - Schakel één partitie over van
Table_AnaarTable_B. - Voer uit
ALTER INDEX <Ordered_CCI_Index> ON <Table_B> REBUILD PARTITION = <Partition_ID>om de ingeschakelde partitie opnieuw te bouwen opTable_B. - Herhaal stap 3 en 4 voor elke partitie in
Table_A. - Zodra alle partities zijn overgeschakeld van
Table_AnaarTable_Ben opnieuw zijn opgebouwd, verwijdertTable_Au en wijzigt u de naamTable_BinTable_A.
Tip
Voor een toegewezen SQL-pooltabel met een geordende CCI sorteert ALTER INDEX REBUILD de gegevens opnieuw met behulp van tempdb. Bewaken tempdb tijdens herbouwbewerkingen. Als u meer tempdb ruimte nodig hebt, schaalt u de pool omhoog. Schaal terug zodra het opnieuw opbouwen van de index is voltooid.
Voor een toegewezen SQL-pooltabel met een geordende CCI sorteert ALTER INDEX REORGANIZE de gegevens niet opnieuw. Als u gegevens wilt gebruiken, gebruikt u ALTER INDEX REBUILD.
Zie Geclusterde columnstore-indexen optimaliseren voor meer informatie over geordende CCI-onderhoud.
Functieverschillen in SQL Server 2022-mogelijkheden
SQL Server 2022 (16.x) introduceerde geordende geclusterde columnstore-indexen die vergelijkbaar zijn met de functie in Azure Synapse toegewezen SQL-pools.
- Op dit moment ondersteunen alleen SQL Server 2022 (16.x) en latere versies geclusterde columnstore verbeterde segment-eliminatiemogelijkheden voor gegevenstypen tekenreeks, binair en GUID, en het gegevenstype datetimeoffset voor schaalgrootte groter dan twee. Voorheen was deze segmentuitschakeling van toepassing op numerieke gegevenstypen, datum- en tijdgegevenstypen en het gegevenstype datetimeoffset met een schaal kleiner dan of gelijk aan twee.
- Momenteel bieden alleen SQL Server 2022 (16.x) en latere versies ondersteuning voor het verwijderen van geclusterde columnstore-rijengroep voor het voorvoegsel van
LIKEpredicaten, bijvoorbeeldcolumn LIKE 'string%'. Segmentverwijdering wordt niet ondersteund voor het gebruik van LIKE zonder voorvoegsel, zoalscolumn LIKE '%string'.
Zie Wat is er nieuw in Columnstore-indexen voor meer informatie.
Voorbeelden
A. Controleren op geordende kolommen en volgordevolgorde:
SELECT object_name(c.object_id) table_name, c.name column_name, i.column_store_order_ordinal
FROM sys.index_columns i
JOIN sys.columns c ON i.object_id = c.object_id AND c.column_id = i.column_id
WHERE column_store_order_ordinal <>0;
B. Ga als volgende te werk om de kolomvolgorde te wijzigen, kolommen toe te voegen aan of te verwijderen uit de volgordelijst, of om van CCI naar geordende CCI te wijzigen:
CREATE CLUSTERED COLUMNSTORE INDEX InternetSales ON dbo.InternetSales
ORDER (ProductKey, SalesAmount)
WITH (DROP_EXISTING = ON);
Volgende stappen
- Zie Overzicht van ontwikkeling voor meer tips voor ontwikkeling.
- Columnstore-indexen: overzicht
- Wat is er nieuw in columnstore-indexen?
- Columnstore-indexen - Ontwerpadviezen
- Columnstore-indexen - Queryprestaties