Access Lake-databases met behulp van een serverloze SQL-pool in Azure Synapse Analytics
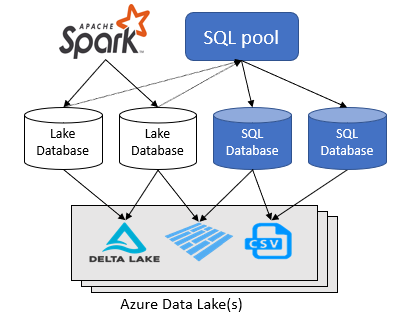
Met de Azure Synapse Analytics-werkruimte kunt u twee typen databases maken boven op een Spark-data lake:
- Lake-databases waar u tabellen op Lake-gegevens kunt definiëren met behulp van Apache Spark-notebooks, databasesjablonen of Microsoft Dataverse (voorheen Common Data Service). Deze tabellen zijn beschikbaar voor het uitvoeren van query's met behulp van de T-SQL-taal (Transact-SQL) met behulp van de serverloze SQL-pool.
- SQL-databases waar u uw eigen databases en tabellen rechtstreeks kunt definiëren met behulp van de serverloze SQL-pools. U kunt T-SQL CREATE DATABASE, CREATE EXTERNAL TABLE gebruiken om de objecten te definiëren en extra SQL-weergaven, procedures en inline-tabelwaardefuncties toe te voegen boven op de tabellen.
Dit artikel is gericht op lake-databases in een serverloze SQL-pool in Azure Synapse Analytics.
Met Azure Synapse Analytics kunt u lake-databases en -tabellen maken met spark- of databaseontwerper en vervolgens gegevens in de Lake-databases analyseren met behulp van de serverloze SQL-pool. De Lake-databases en de tabellen (parquet of CSV-ondersteuning) die zijn gemaakt in de Apache Spark-pools, databasesjablonen of Dataverse, zijn automatisch beschikbaar voor het uitvoeren van query's met de serverloze SQL-poolengine. De lake-databases en -tabellen die na enige tijd worden gewijzigd, zijn na enige tijd beschikbaar in een serverloze SQL-pool. Er is een vertraging totdat de wijzigingen die zijn aangebracht in Spark of Database die zijn ontworpen, worden weergegeven in serverloos.
Lake-database beheren
Als u Met Spark gemaakte Lake-databases wilt beheren, kunt u Apache Spark-pools of databaseontwerper gebruiken. Maak of verwijder bijvoorbeeld een Lake-database via een Spark-pooltaak. U kunt geen lake-database of de objecten in de lake-databases maken met behulp van de serverloze SQL-pool.
De Spark-database default is beschikbaar in de context van de serverloze SQL-pool als een Lake-database met de naam default.
Notitie
U kunt geen lake en een SQL-database maken in de serverloze SQL-pool met dezelfde naam.
Tabellen in de Lake-databases kunnen niet worden gewijzigd vanuit een serverloze SQL-pool. Gebruik de databaseontwerper of Apache Spark-pools om een Lake-database te wijzigen. Met de serverloze SQL-pool kunt u de volgende wijzigingen aanbrengen in een lake-database met behulp van Transact-SQL-opdrachten:
- Weergaven, procedures, inline tabelwaardefuncties toevoegen, wijzigen en verwijderen in een lake-database.
- Microsoft Entra-gebruikers met databasebereik toevoegen en verwijderen.
- Microsoft Entra-databasegebruikers toevoegen aan of verwijderen uit de db_datareader rol. Microsoft Entra-databasegebruikers in de rol db_datareader zijn gemachtigd om alle tabellen in de Lake-database te lezen, maar kunnen geen gegevens van andere databases lezen.
Beveiligingsmodel
De Lake-databases en -tabellen worden op twee niveaus beveiligd:
- De onderliggende opslaglaag door een van de volgende gebruikers toe te wijzen aan Microsoft Entra:
- op rollen gebaseerd toegangsbeheer van Azure (Azure RBAC)
- Azure ABAC-rol (op kenmerken gebaseerd toegangsbeheer)
- ACL-machtigingen
- De SQL-laag waar u een Microsoft Entra-gebruiker kunt definiëren en SQL-machtigingen kunt verlenen voor SELECT-gegevens uit tabellen die verwijzen naar de lake-gegevens.
Lake-beveiligingsmodel
Toegang tot lake-databasebestanden wordt beheerd met behulp van de lake-machtigingen voor de opslaglaag. Alleen Microsoft Entra-gebruikers kunnen tabellen in de Lake-databases gebruiken en ze hebben toegang tot de gegevens in de lake met hun eigen identiteiten.
U kunt toegang verlenen tot de onderliggende gegevens die voor externe tabellen worden gebruikt voor een beveiligingsprincipaal, zoals: een gebruiker, een Microsoft Entra-toepassing met toegewezen service-principal of een beveiligingsgroep. Voor gegevenstoegang verleent u beide van de volgende machtigingen:
- Machtigingen verlenen
read (R)voor bestanden (zoals de onderliggende gegevensbestanden van de tabel). - Verdeel
execute (X)machtigingen voor de map waarin de bestanden zijn opgeslagen en op elke bovenliggende map tot aan de hoofdmap. Meer informatie over deze machtigingen vindt u op de pagina Toegangsbeheerlijsten (ACL's ).
In https://<storage-name>.dfs.core.windows.net/<fs>/synapse/workspaces/<synapse_ws>/warehouse/mytestdb.db/myparquettable/bijvoorbeeld, hebben beveiligingsprinciplen het volgende nodig:
execute (X)machtigingen voor alle mappen die beginnen bij de<fs>myparquettablemap .read (R)machtigingen voormyparquettableen bestanden in die map om een tabel in een database te kunnen lezen (gesynchroniseerd of origineel).
Als voor een beveiligingsprincipal is vereist dat objecten moeten kunnen worden gemaakt of verwijderd in een database, zijn aanvullende write (W)-machtigingen vereist voor de mappen en bestanden in de map warehouse. Het wijzigen van objecten in een database is niet mogelijk vanuit een serverloze SQL-pool, alleen vanuit Spark-pools of de databaseontwerper.
SQL-beveiligingsmodel
De Azure Synapse-werkruimte biedt een T-SQL-eindpunt waarmee u een query kunt uitvoeren op de Lake-database met behulp van de serverloze SQL-pool. Naast de gegevenstoegang kunt u met de SQL-interface bepalen wie toegang heeft tot de tabellen. U moet een gebruiker toegang geven tot de gedeelde Lake-databases met behulp van de serverloze SQL-pool. Er zijn twee typen gebruikers die toegang hebben tot de Lake-databases:
- Beheer istrators: wijs de Synapse SQL Beheer istrator-werkruimterol of sysadmin-serverrol in de serverloze SQL-pool. Deze rol heeft volledige controle over alle databases. De rollen Synapse Beheer istrator en Synapse SQL Beheer istrator hebben standaard ook alle machtigingen voor alle objecten in een serverloze SQL-pool.
- Werkruimtelezers: Verken de machtigingen op serverniveau GRANT CONNECT ANY DATABASE en GRANT SELECT ALL USER SECURABLES in een serverloze SQL-pool aan een aanmelding waarmee de aanmelding toegang krijgt tot en alle databases kan lezen. Dit kan een goede keuze zijn voor het toewijzen van lezer-/niet-beheerderstoegang aan een gebruiker.
- Databaselezers: Maak databasegebruikers van Microsoft Entra ID in uw Lake-database en voeg ze toe aan db_datareader rol, zodat ze gegevens in de Lake-database kunnen lezen.
Meer informatie over het instellen van toegangsbeheer voor gedeelde databases vindt u hier.
Aangepaste SQL-objecten in Lake-databases
Met Lake-databases kunt u aangepaste T-SQL-objecten maken, zoals schema's, procedures, weergaven en de inline-tabelwaardefuncties (iTVF's). Als u aangepaste SQL-objecten wilt maken, moet u een schema maken waarin u de objecten wilt plaatsen. Aangepaste SQL-objecten kunnen niet in dbo het schema worden geplaatst omdat deze zijn gereserveerd voor de Lake-tabellen die zijn gedefinieerd in Spark, databaseontwerper of Dataverse.
Belangrijk
U moet een aangepast SQL-schema maken waarin u uw SQL-objecten wilt plaatsen. De aangepaste SQL-objecten kunnen niet in het dbo schema worden geplaatst. Het dbo schema is gereserveerd voor de lake-tabellen die oorspronkelijk zijn gemaakt in Spark of databaseontwerper.
Voorbeelden
SQL-databaselezer maken in lake-database
In dit voorbeeld voegen we een Microsoft Entra-gebruiker toe in de Lake-database die gegevens kan lezen via gedeelde tabellen. De gebruikers worden toegevoegd in de Lake-database via de serverloze SQL-pool. Wijs vervolgens de gebruiker toe aan de rol db_datareader zodat ze gegevens kunnen lezen.
CREATE USER [customuser@contoso.com] FROM EXTERNAL PROVIDER;
GO
ALTER ROLE db_datareader
ADD MEMBER [customuser@contoso.com];
Gegevenslezer op werkruimteniveau maken
Een aanmelding met GRANT CONNECT ANY DATABASE en GRANT SELECT ALL USER SECURABLES machtigingen kan alle tabellen lezen met behulp van de serverloze SQL-pool, maar kan geen SQL-databases maken of de objecten hierin wijzigen.
CREATE LOGIN [wsdatareader@contoso.com] FROM EXTERNAL PROVIDER
GRANT CONNECT ANY DATABASE TO [wsdatareader@contoso.com]
GRANT SELECT ALL USER SECURABLES TO [wsdatareader@contoso.com]
Met dit script kunt u gebruikers maken zonder beheerdersbevoegdheden die elke tabel in Lake-databases kunnen lezen.
Een Spark-database maken en verbinden met een serverloze SQL-pool
Maak eerst een nieuwe Spark-database met de naam mytestdb een Spark-cluster dat u al in uw werkruimte hebt gemaakt. U kunt bijvoorbeeld een Spark C#-notebook gebruiken met de volgende .NET for Spark-instructie:
spark.sql("CREATE DATABASE mytestlakedb")
Na een korte vertraging ziet u de Lake-database uit een serverloze SQL-pool. Voer bijvoorbeeld de volgende instructie uit vanuit de serverloze SQL-pool.
SELECT * FROM sys.databases;
Controleer of mytestlakedb is opgenomen in de resultaten.
Aangepaste SQL-objecten maken in lake-database
In het volgende voorbeeld ziet u hoe u een aangepaste weergave, procedure en inline tabelwaardefunctie (iTVF) maakt in het reports schema:
CREATE SCHEMA reports
GO
CREATE OR ALTER VIEW reports.GreenReport
AS SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
GO
CREATE OR ALTER PROCEDURE reports.GreenReportSummary
AS BEGIN
SELECT puYear, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
GROUP BY puYear, puMonth
END
GO
CREATE OR ALTER FUNCTION reports.GreenDataReportMonthly(@year int)
RETURNS TABLE
RETURN ( SELECT puYear = @year, puMonth,
fareAmount = SUM(fareAmount),
tipAmount = SUM(tipAmount),
mtaTax = SUM(mtaTax)
FROM dbo.green
WHERE puYear = @year
GROUP BY puMonth )
GO
Volgende stappen
- Meer informatie over gedeelde Azure Synapse Analytics-metagegevens
- Meer informatie over gedeelde Azure Synapse Analytics-metagegevenstabellen
- Snel starten: Een nieuwe lake-database maken met behulp van databasesjablonen
- Zelfstudie: Serverloze SQL-pool gebruiken met Power BI Desktop en een rapport maken
- Apache Spark synchroniseren voor externe azure Synapse-tabeldefinities in een serverloze SQL-pool
- Zelfstudie: Data Lakes verkennen en analyseren met een serverloze SQL-pool