Apache Spark Advisor in Azure Synapse Analytics (preview)
De Apache Spark-adviseur analyseert opdrachten en code die door Spark worden uitgevoerd en geeft realtime advies weer voor Notebook-uitvoeringen. De Spark-adviseur heeft ingebouwde patronen om gebruikers te helpen veelvoorkomende fouten te voorkomen, aanbevelingen te doen voor codeoptimalisatie, foutanalyses uit te voeren en de hoofdoorzaak van fouten te vinden.
Ingebouwd advies
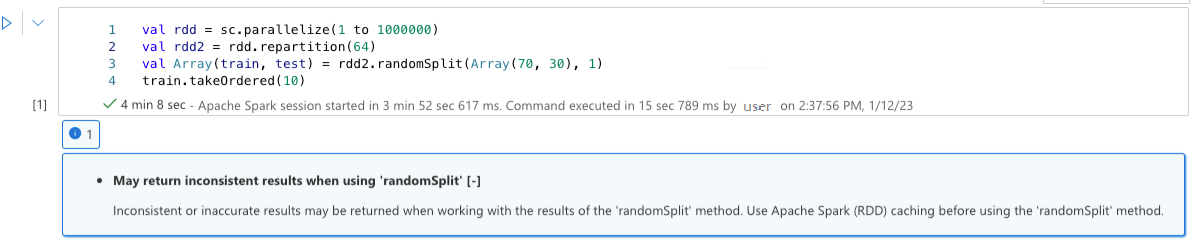
Kan inconsistente resultaten retourneren bij gebruik van 'randomSplit'
Inconsistente of onnauwkeurige resultaten kunnen worden geretourneerd wanneer u werkt met de resultaten van de methode 'randomSplit'. Gebruik Apache Spark -caching (RDD) voordat u de methode randomSplit gebruikt.
Methode randomSplit() is gelijk aan het meerdere keren uitvoeren van sample() in uw gegevensframe, waarbij elk voorbeeld uw gegevensframe opnieuw binnen partities op de pagina zet, partitioneert en sorteert. De gegevensdistributie over partities en sorteervolgorde is belangrijk voor zowel randomSplit() als sample(). Als de gegevens worden gewijzigd bij het terugbrengen van gegevens, kunnen er duplicaten zijn of ontbrekende waarden in splitsingen en kan hetzelfde monster met hetzelfde seed andere resultaten opleveren.
Deze inconsistenties gebeuren mogelijk niet bij elke uitvoering, maar om ze volledig te elimineren, moet u uw gegevensframe opslaan in de cache, opnieuw partitioneren op een of meer kolommen of statistische functies zoals groupBy toepassen.
Tabel-/weergavenaam wordt al gebruikt
Er bestaat al een weergave met dezelfde naam als de gemaakte tabel of er bestaat al een tabel met dezelfde naam als de gemaakte weergave. Wanneer deze naam wordt gebruikt in query's of toepassingen, wordt alleen de weergave geretourneerd, ongeacht welke weergave het eerst is gemaakt. Als u conflicten wilt voorkomen, wijzigt u de naam van de tabel of de weergave.
Kan een hint niet herkennen
De geselecteerde query bevat een hint die niet wordt herkend. Controleer of de hint juist is gespeld.
spark.sql("SELECT /*+ unknownHint */ * FROM t1")
Kan een of meer opgegeven relatienamen niet vinden
Kan de relatie(s) die zijn opgegeven in de hint niet vinden. Controleer of de relatie(en) correct zijn gespeld en toegankelijk zijn binnen het bereik van de hint.
spark.sql("SELECT /*+ BROADCAST(unknownTable) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Een hint in de query voorkomt dat een andere hint wordt toegepast
De geselecteerde query bevat een hint die voorkomt dat een andere hint wordt toegepast.
spark.sql("SELECT /*+ BROADCAST(t1), MERGE(t1, t2) */ * FROM t1 INNER JOIN t2 ON t1.str = t2.str")
Schakel spark.advise.divisionExprConvertRule.enable in om de doorgifte van afrondingsfouten te verminderen
Deze query bevat de expressie met het type Double. U wordt aangeraden de configuratie spark.advise.divisionExprConvertRule.enable in te schakelen, waarmee u de verdelingsexpressies kunt verminderen en de doorgifte van afrondingsfouten kunt verminderen.
"t.a/t.b/t.c" convert into "t.a/(t.b * t.c)"
Schakel spark.advise.nonEqJoinConvertRule.enable in om de queryprestaties te verbeteren
Deze query bevat tijdrovende join vanwege de 'Of'-voorwaarde in de query. U wordt aangeraden de configuratie spark.advise.nonEqJoinConvertRule.enable in te schakelen. Dit kan helpen bij het converteren van de join die wordt geactiveerd door de 'Or'-voorwaarde naar SMJ of BHJ om deze query te versnellen.
Deltatabel optimaliseren met kleine bestandscompressie
Deze query bevindt zich in een deltatabel met veel kleine bestanden. Als u de prestaties van query's wilt verbeteren, voert u de opdracht OPTIMALISEREN uit in de deltatabel. Meer informatie vindt u in dit artikel.
Delta-tabel optimaliseren met ZOrder
Deze query bevindt zich in een Delta-tabel en bevat een zeer selectief filter. Als u de prestaties van query's wilt verbeteren, voert u de opdracht OPTIMALISEREN ZORDER BY uit in de deltatabel. Meer informatie vindt u in dit artikel.
Gebruikerservaring
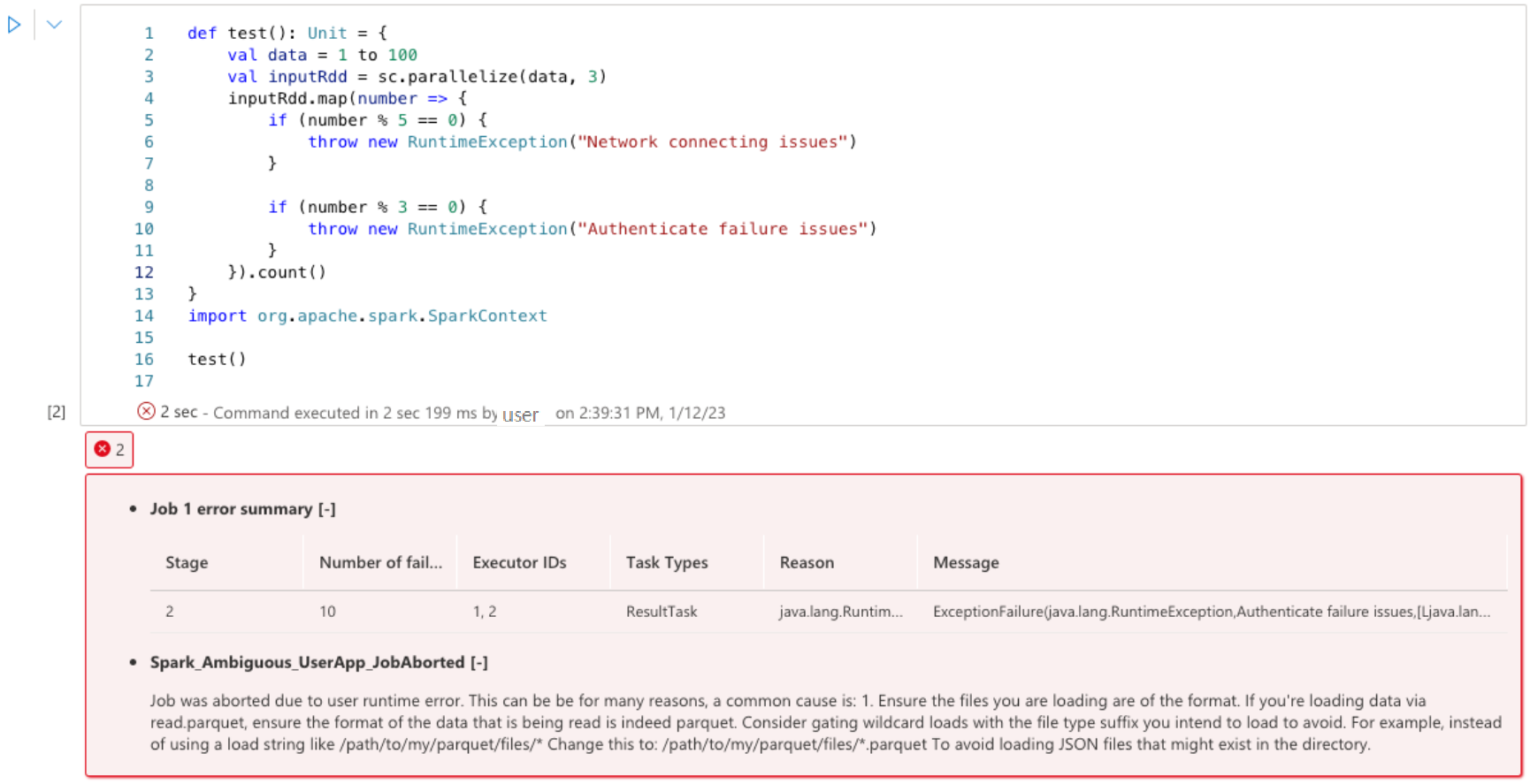
De Apache Spark-adviseur geeft de adviezen, inclusief informatie, waarschuwing en fouten, in notebookceluitvoer in realtime weer.
Info
Waarschuwing

Fouten
Volgende stappen
Zie het artikel Apache Spark-toepassingen bewaken met Synapse Studio voor meer informatie over het bewaken van Apache Spark-toepassingen.
Zie Synapse-notebooks gebruiken voor meer informatie over het maken van een notitieblok.