Zelfstudie: Een machine learning-app bouwen met Apache Spark MLlib en Azure Synapse Analytics
In dit artikel leert u hoe u Apache Spark MLlib kunt gebruiken om een machine learning-toepassing te maken die eenvoudige voorspellende analyse uitvoert voor Azure Open Datasets. Spark biedt ingebouwde machine learning-bibliotheken. In dit voorbeeld wordt gebruikgemaakt van classificatie via logistieke regressie.
SparkML en MLlib zijn kernbibliotheken van Spark die veel hulpprogramma's bieden die nuttig zijn voor machine learning-taken, waaronder hulpprogramma's die geschikt zijn voor:
- Classificatie
- Regressie
- Clustering
- Modellering van onderwerpen
- SVD (Singular Value Decomposition) en PCA (Principal Component Snalysis)
- Hypothesen voor het testen en berekenen van voorbeeldstatistieken
Classificatie en logistieke regressie begrijpen
Classificatie, een populaire machine learning-taak, is het proces waarbij invoergegevens worden gesorteerd in categorieën. Het is de taak van een classificatie-algoritme om erachter te komen hoe labels kunnen worden toegewezen aan invoergegevens die u opgeeft. U kunt bijvoorbeeld een machine learning-algoritme bedenken dat aandeleninformatie accepteert als invoer en het aandeel opsplitst in twee categorieën: aandelen die u moet verkopen en aandelen die u moet behouden.
Logistieke regressie is een algoritme dat u kunt gebruiken voor classificatie. De logistieke regressie-API van Spark is handig voor binaire classificatie, of voor het classificeren van invoergegevens in één van twee groepen. Zie Wikipedia voor meer informatie over logistieke regressie.
Samengevat produceert het proces van logistieke regressie een logistieke functie die u kunt gebruiken om de waarschijnlijkheid te voorspellen dat een invoervector in de ene groep of de andere hoort.
Voorbeeld van voorspellende analyse over taxigegevens in NYC
In dit voorbeeld gebruikt u Spark om een voorspellende analyse uit te voeren op gegevens van taxirittips uit New York. De gegevens zijn beschikbaar via Azure Open Datasets. Deze subset van de gegevensset bevat informatie over taxiritten, waaronder informatie over elke rit, de begin- en eindtijd en locaties, de kosten, en andere interessante kenmerken.
Belangrijk
Er kunnen extra kosten gelden voor het ophalen van deze gegevens uit de opslaglocatie.
In de volgende stappen ontwikkelt u een model om te voorspellen of voor een bepaalde trip een fooi is betaald of niet.
Een Apache Spark-machine learning-model maken
Maak een notebook met behulp van de PySpark-kernel. Zie Een notebook maken voor instructies.
Importeer de typen die zijn vereist voor deze toepassing. Kopieer en plak de volgende code in een lege cel en druk op Shift+Enter. Of voer de cel uit met behulp van het blauwe afspeelpictogram links van de code.
import matplotlib.pyplot as plt from datetime import datetime from dateutil import parser from pyspark.sql.functions import unix_timestamp, date_format, col, when from pyspark.ml import Pipeline from pyspark.ml import PipelineModel from pyspark.ml.feature import RFormula from pyspark.ml.feature import OneHotEncoder, StringIndexer, VectorIndexer from pyspark.ml.classification import LogisticRegression from pyspark.mllib.evaluation import BinaryClassificationMetrics from pyspark.ml.evaluation import BinaryClassificationEvaluatorVanwege de PySpark-kernel hoeft u niet expliciet contexten te maken. De Spark-context wordt automatisch voor u gemaakt wanneer u de eerste codecel uitvoert.
De invoer-DataFrame maken
Omdat de onbewerkte gegevens een Parquet-indeling hebben, kunt u de Spark-context gebruiken om het bestand rechtstreeks als een DataFrame in het geheugen op te halen. Hoewel de code in de volgende stappen gebruikmaakt van de standaardopties, is het mogelijk om toewijzing van gegevenstypen en andere schemakenmerken af te dwingen, indien nodig.
Voer de volgende regels uit om een Spark DataFrame te maken door de code in een nieuwe cel te plakken. Met deze stap worden de gegevens opgehaald via de Open Datasets-API. Het ophalen van deze gegevens genereert bijna 1,5 miljard rijen.
Afhankelijk van de grootte van uw serverloze Apache Spark-pool zijn de onbewerkte gegevens mogelijk te groot of duurt het te veel tijd om te werken. U kunt deze gegevens filteren naar een kleinere hoeveelheid. In het volgende codevoorbeeld wordt en
end_dategebruiktstart_dateom een filter toe te passen dat één maand aan gegevens retourneert.from azureml.opendatasets import NycTlcYellow from datetime import datetime from dateutil import parser end_date = parser.parse('2018-05-08 00:00:00') start_date = parser.parse('2018-05-01 00:00:00') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) filtered_df = spark.createDataFrame(nyc_tlc.to_pandas_dataframe())Het nadeel van eenvoudig filteren is dat het, vanuit een statistisch perspectief, vooroordelen in de gegevens kan veroorzaken. Een andere aanpak is het gebruik van de steekproeven die zijn ingebouwd in Spark.
Met de volgende code wordt de gegevensset teruggebracht tot ongeveer 2000 rijen, als deze wordt toegepast na de voorgaande code. U kunt deze steekproefstap gebruiken in plaats van het eenvoudige filter of in combinatie met het eenvoudige filter.
# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234)Het is nu mogelijk om de gegevens te bekijken om te zien wat er is gelezen. Het is normaal gesproken beter om gegevens te controleren met een subset in plaats van de volledige set, afhankelijk van de grootte van de gegevensset.
De volgende code biedt twee manieren om de gegevens weer te geven. De eerste manier is eenvoudig. De tweede manier biedt een veel rijkere rasterervaring, samen met de mogelijkheid om de gegevens grafisch te visualiseren.
#sampled_taxi_df.show(5) display(sampled_taxi_df)Afhankelijk van de grootte van de gegenereerde gegevensset en uw behoefte om te experimenteren of het notebook meerdere keren uit te voeren, wilt u de gegevensset mogelijk lokaal in de cache opslaan in de werkruimte. Er zijn drie manieren om expliciete caching uit te voeren:
- Sla het DataFrame lokaal op als een bestand.
- Sla het DataFrame op als een tijdelijke tabel of weergave.
- Sla het DataFrame op als een permanente tabel.
De eerste twee van deze benaderingen zijn opgenomen in de volgende codevoorbeelden.
Het maken van een tijdelijke tabel of weergave biedt verschillende toegangspaden tot de gegevens, maar deze duurt alleen voor de duur van de sessie van het Spark-exemplaar.
sampled_taxi_df.createOrReplaceTempView("nytaxi")
De gegevens voorbereiden
De gegevens in de onbewerkte vorm zijn vaak niet geschikt om rechtstreeks aan een model door te geven. U moet een reeks acties uitvoeren op de gegevens om deze in een toestand te krijgen waarin het model deze kan gebruiken.
In de volgende code voert u vier klassen bewerkingen uit:
- Het verwijderen van uitbijters of onjuiste waarden door filteren.
- Onnodige kolommen verwijderen.
- Het maken van nieuwe kolommen die zijn afgeleid van de onbewerkte gegevens om het model effectiever te laten werken. Deze bewerking wordt ook wel featurization genoemd.
- Labeling. Omdat u binaire classificatie uitvoert (is er een fooi of niet op een bepaalde reis), moet u het fooibedrag converteren naar een waarde van 0 of 1.
taxi_df = sampled_taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'rateCodeId', 'passengerCount'\
, 'tripDistance', 'tpepPickupDateTime', 'tpepDropoffDateTime'\
, date_format('tpepPickupDateTime', 'hh').alias('pickupHour')\
, date_format('tpepPickupDateTime', 'EEEE').alias('weekdayString')\
, (unix_timestamp(col('tpepDropoffDateTime')) - unix_timestamp(col('tpepPickupDateTime'))).alias('tripTimeSecs')\
, (when(col('tipAmount') > 0, 1).otherwise(0)).alias('tipped')
)\
.filter((sampled_taxi_df.passengerCount > 0) & (sampled_taxi_df.passengerCount < 8)\
& (sampled_taxi_df.tipAmount >= 0) & (sampled_taxi_df.tipAmount <= 25)\
& (sampled_taxi_df.fareAmount >= 1) & (sampled_taxi_df.fareAmount <= 250)\
& (sampled_taxi_df.tipAmount < sampled_taxi_df.fareAmount)\
& (sampled_taxi_df.tripDistance > 0) & (sampled_taxi_df.tripDistance <= 100)\
& (sampled_taxi_df.rateCodeId <= 5)
& (sampled_taxi_df.paymentType.isin({"1", "2"}))
)
Vervolgens voert u een tweede doorgang over de gegevens om de uiteindelijke functies toe te voegen.
taxi_featurised_df = taxi_df.select('totalAmount', 'fareAmount', 'tipAmount', 'paymentType', 'passengerCount'\
, 'tripDistance', 'weekdayString', 'pickupHour','tripTimeSecs','tipped'\
, when((taxi_df.pickupHour <= 6) | (taxi_df.pickupHour >= 20),"Night")\
.when((taxi_df.pickupHour >= 7) & (taxi_df.pickupHour <= 10), "AMRush")\
.when((taxi_df.pickupHour >= 11) & (taxi_df.pickupHour <= 15), "Afternoon")\
.when((taxi_df.pickupHour >= 16) & (taxi_df.pickupHour <= 19), "PMRush")\
.otherwise(0).alias('trafficTimeBins')
)\
.filter((taxi_df.tripTimeSecs >= 30) & (taxi_df.tripTimeSecs <= 7200))
Een logistiek regressiemodel maken
De laatste taak bestaat uit het converteren van de gelabelde gegevens naar een indeling die kan worden geanalyseerd via logistieke regressie. De invoer voor een logistiek regressie-algoritme moet een set label-/functievectorparen zijn, waarbij de functievector een vector is van getallen die het invoerpunt vertegenwoordigen.
U moet de categorische kolommen dus converteren naar getallen. U moet met name de trafficTimeBins kolommen en weekdayString converteren naar weergaven met gehele getallen. Er zijn meerdere benaderingen voor het uitvoeren van de conversie. In het volgende voorbeeld wordt de OneHotEncoder methode gebruikt, die gebruikelijk is.
# Because the sample uses an algorithm that works only with numeric features, convert them so they can be consumed
sI1 = StringIndexer(inputCol="trafficTimeBins", outputCol="trafficTimeBinsIndex")
en1 = OneHotEncoder(dropLast=False, inputCol="trafficTimeBinsIndex", outputCol="trafficTimeBinsVec")
sI2 = StringIndexer(inputCol="weekdayString", outputCol="weekdayIndex")
en2 = OneHotEncoder(dropLast=False, inputCol="weekdayIndex", outputCol="weekdayVec")
# Create a new DataFrame that has had the encodings applied
encoded_final_df = Pipeline(stages=[sI1, en1, sI2, en2]).fit(taxi_featurised_df).transform(taxi_featurised_df)
Deze actie resulteert in een nieuw DataFrame met alle kolommen in de juiste indeling om een model te trainen.
Een logistiek regressiemodel trainen
De eerste taak is het splitsen van de gegevensset in een trainingsset en een test- of validatieset. De splitsing hier is willekeurig. Experimenteer met verschillende gesplitste instellingen om te zien of deze van invloed zijn op het model.
# Decide on the split between training and testing data from the DataFrame
trainingFraction = 0.7
testingFraction = (1-trainingFraction)
seed = 1234
# Split the DataFrame into test and training DataFrames
train_data_df, test_data_df = encoded_final_df.randomSplit([trainingFraction, testingFraction], seed=seed)
Nu er twee DataFrames zijn, is de volgende taak het maken van de modelformule en het uitvoeren ervan op basis van het DataFrame voor training. Vervolgens kunt u valideren op basis van het dataframe dat wordt getest. Experimenteer met verschillende versies van de modelformule om de impact van verschillende combinaties te zien.
Notitie
Als u het model wilt opslaan, wijst u de rol Inzender voor opslagblobgegevens toe aan het resourcebereik van de Azure SQL Database-server. Raadpleeg Azure-rollen toewijzen met de Azure Portal voor meer details. Alleen leden met eigenaarsbevoegdheden kunnen deze stap uitvoeren.
## Create a new logistic regression object for the model
logReg = LogisticRegression(maxIter=10, regParam=0.3, labelCol = 'tipped')
## The formula for the model
classFormula = RFormula(formula="tipped ~ pickupHour + weekdayVec + passengerCount + tripTimeSecs + tripDistance + fareAmount + paymentType+ trafficTimeBinsVec")
## Undertake training and create a logistic regression model
lrModel = Pipeline(stages=[classFormula, logReg]).fit(train_data_df)
## Saving the model is optional, but it's another form of inter-session cache
datestamp = datetime.now().strftime('%m-%d-%Y-%s')
fileName = "lrModel_" + datestamp
logRegDirfilename = fileName
lrModel.save(logRegDirfilename)
## Predict tip 1/0 (yes/no) on the test dataset; evaluation using area under ROC
predictions = lrModel.transform(test_data_df)
predictionAndLabels = predictions.select("label","prediction").rdd
metrics = BinaryClassificationMetrics(predictionAndLabels)
print("Area under ROC = %s" % metrics.areaUnderROC)
De uitvoer van deze cel is:
Area under ROC = 0.9779470729751403
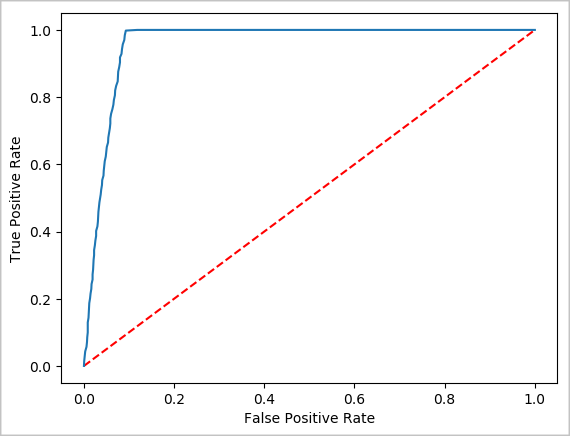
Een visuele weergave van de voorspelling maken
U kunt nu een definitieve visualisatie maken om u te helpen de testresultaten te beoordelen. Een ROC-curve is een manier om het resultaat te controleren.
## Plot the ROC curve; no need for pandas, because this uses the modelSummary object
modelSummary = lrModel.stages[-1].summary
plt.plot([0, 1], [0, 1], 'r--')
plt.plot(modelSummary.roc.select('FPR').collect(),
modelSummary.roc.select('TPR').collect())
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.show()
Het Spark-exemplaar afsluiten
Nadat u klaar bent met het uitvoeren van de toepassing, sluit u het notebook af om de resources vrij te geven door het tabblad te sluiten. Of selecteer Sessie beëindigen in het statusvenster onderaan het notitieblok.