Ontwerprichtlijnen voor het gebruik van gerepliceerde tabellen in Synapse SQL-pool
Dit artikel bevat aanbevelingen voor het ontwerpen van gerepliceerde tabellen in uw Synapse SQL-poolschema. Gebruik deze aanbevelingen om de queryprestaties te verbeteren door gegevensverplaatsing en querycomplexiteit te verminderen.
Vereisten
In dit artikel wordt ervan uitgegaan dat u bekend bent met concepten voor gegevensdistributie en gegevensverplaatsing in SQL-pool. Zie het architectuurartikel voor meer informatie.
Als onderdeel van het tabelontwerp begrijpt u zoveel mogelijk over uw gegevens en hoe de gegevens worden opgevraagd. Denk bijvoorbeeld aan deze vragen:
- Hoe groot is de tabel?
- Hoe vaak wordt de tabel vernieuwd?
- Heb ik feiten- en dimensietabellen in een SQL-pool?
Wat is een gerepliceerde tabel?
Een gerepliceerde tabel heeft een volledige kopie van de tabel die toegankelijk is op elk rekenknooppunt. Als een tabel wordt gerepliceerd, hoeven de gegevens niet meer te worden overgedragen tussen rekenknooppunten voordat er sprake is van een samenvoeging of aggregatie. Omdat de tabel meerdere exemplaren heeft, werken gerepliceerde tabellen het beste wanneer de tabelgrootte kleiner is dan 2 GB. 2 GB is geen vaste limiet. Als de gegevens statisch zijn en niet worden gewijzigd, kunt u grotere tabellen repliceren.
In het volgende diagram ziet u een gerepliceerde tabel die toegankelijk is op elk rekenknooppunt. In de SQL-pool wordt de gerepliceerde tabel volledig gekopieerd naar een distributiedatabase op elk rekenknooppunt.

Gerepliceerde tabellen werken goed voor dimensietabellen in een stervormig schema. Dimensietabellen worden meestal gekoppeld aan feitentabellen, die anders worden verdeeld dan de dimensietabel. Dimensies zijn meestal van een grootte die het haalbaar maakt om meerdere kopieën op te slaan en te onderhouden. Dimensies slaan beschrijvende gegevens op die langzaam worden gewijzigd, zoals de naam en het adres van de klant, en productdetails. De langzaam veranderende aard van de gegevens leidt tot minder onderhoud van de gerepliceerde tabel.
Overweeg het gebruik van een gerepliceerde tabel wanneer:
- De tabelgrootte op schijf is kleiner dan 2 GB, ongeacht het aantal rijen. Als u de grootte van een tabel wilt vinden, kunt u de opdracht DBCC PDW_SHOWSPACEUSED gebruiken:
DBCC PDW_SHOWSPACEUSED('ReplTableCandidate'). - De tabel wordt gebruikt in joins waarvoor anders gegevensverplaatsing is vereist. Bij het samenvoegen van tabellen die niet in dezelfde kolom worden gedistribueerd, zoals een hash-gedistribueerde tabel naar een round robin-tabel, is gegevensverplaatsing vereist om de query te voltooien. Als een van de tabellen klein is, kunt u een gerepliceerde tabel overwegen. Het is raadzaam om in de meeste gevallen gerepliceerde tabellen te gebruiken in plaats van round robin-tabellen. Gebruik sys.dm_pdw_request_steps om bewerkingen voor gegevensverplaatsing in queryplannen weer te geven. BroadcastMoveOperation is de gebruikelijke bewerking voor gegevensverplaatsing die kan worden geëlimineerd met behulp van een gerepliceerde tabel.
Gerepliceerde tabellen leveren mogelijk niet de beste queryprestaties op wanneer:
- De tabel bevat veelgebruikte invoeg-, update- en verwijderbewerkingen. Voor de DML-bewerkingen (Data Manipulat Language) is een herbouw van de gerepliceerde tabel vereist. Het opnieuw opbouwen kan leiden tot tragere prestaties.
- De SQL-pool wordt regelmatig geschaald. Als u een SQL-pool schaalt, wordt het aantal rekenknooppunten gewijzigd, waardoor de gerepliceerde tabel opnieuw wordt opgebouwd.
- De tabel heeft een groot aantal kolommen, maar gegevensbewerkingen hebben doorgaans slechts een klein aantal kolommen. In dit scenario kan het in plaats van het repliceren van de hele tabel effectiever zijn om de tabel te distribueren en vervolgens een index te maken voor de veelgebruikte kolommen. Wanneer voor een query gegevensverplaatsing is vereist, worden in SQL-pool alleen gegevens voor de aangevraagde kolommen verplaatst.
Tip
Zie het cheatsheet voor toegewezen SQL-pool (voorheen SQL DW) in Azure Synapse Analytics voor meer informatie over het indexeren en repliceren van tabellen.
Gerepliceerde tabellen gebruiken met eenvoudige querypredicaten
Voordat u ervoor kiest om een tabel te distribueren of te repliceren, moet u nadenken over de typen query's die u wilt uitvoeren op de tabel. Waar mogelijk,
- Gebruik gerepliceerde tabellen voor query's met eenvoudige querypredicaten, zoals gelijkheid of ongelijkheid.
- Gebruik gedistribueerde tabellen voor query's met complexe querypredicaten, zoals LIKE of NOT LIKE.
CPU-intensieve query's presteren het beste wanneer het werk wordt verdeeld over alle rekenknooppunten. Query's die berekeningen uitvoeren op elke rij van een tabel, presteren bijvoorbeeld beter voor gedistribueerde tabellen dan gerepliceerde tabellen. Omdat een gerepliceerde tabel volledig wordt opgeslagen op elk rekenknooppunt, wordt een CPU-intensieve query op een gerepliceerde tabel uitgevoerd op de hele tabel op elk rekenknooppunt. De extra berekening kan de queryprestaties vertragen.
Deze query heeft bijvoorbeeld een complex predicaat. Deze wordt sneller uitgevoerd wanneer de gegevens zich in een gedistribueerde tabel bevinden in plaats van een gerepliceerde tabel. In dit voorbeeld kunnen de gegevens round robin worden gedistribueerd.
SELECT EnglishProductName
FROM DimProduct
WHERE EnglishDescription LIKE '%frame%comfortable%';
Bestaande round robin-tabellen converteren naar gerepliceerde tabellen
Als u al round robin-tabellen hebt, raden we u aan deze tabellen te converteren naar gerepliceerde tabellen als ze voldoen aan de criteria die in dit artikel worden beschreven. Gerepliceerde tabellen verbeteren de prestaties van round robin-tabellen omdat ze de noodzaak van gegevensverplaatsing elimineren. Voor een round robin-tabel is altijd gegevensverplaatsing voor joins vereist.
In dit voorbeeld wordt CTAS gebruikt om de DimSalesTerritory tabel te wijzigen in een gerepliceerde tabel. Dit voorbeeld werkt ongeacht of DimSalesTerritory hash-gedistribueerd of round robin is.
CREATE TABLE [dbo].[DimSalesTerritory_REPLICATE]
WITH
(
HEAP,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory]
OPTION (LABEL = 'CTAS : DimSalesTerritory_REPLICATE')
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[DimSalesTerritory_REPLICATE] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Voorbeeld van queryprestaties voor round robin versus gerepliceerd
Voor een gerepliceerde tabel is geen gegevensverplaatsing voor joins vereist, omdat de hele tabel al aanwezig is op elk rekenknooppunt. Als de dimensietabellen round robin worden gedistribueerd, kopieert een join de dimensietabel volledig naar elk rekenknooppunt. Als u de gegevens wilt verplaatsen, bevat het queryplan een bewerking met de naam BroadcastMoveOperation. Dit type bewerking voor gegevensverplaatsing vertraagt de queryprestaties en wordt geëlimineerd met behulp van gerepliceerde tabellen. Gebruik de sys.dm_pdw_request_steps systeemcatalogusweergave om de stappen voor het queryplan weer te geven.
In de volgende query op basis van het AdventureWorks schema is de FactInternetSales tabel bijvoorbeeld hash-gedistribueerd. De DimDate tabellen en DimSalesTerritory tabellen zijn kleinere dimensietabellen. Deze query retourneert de totale verkoop in Noord-Amerika voor fiscaal jaar 2004:
SELECT [TotalSalesAmount] = SUM(SalesAmount)
FROM dbo.FactInternetSales s
INNER JOIN dbo.DimDate d
ON d.DateKey = s.OrderDateKey
INNER JOIN dbo.DimSalesTerritory t
ON t.SalesTerritoryKey = s.SalesTerritoryKey
WHERE d.FiscalYear = 2004
AND t.SalesTerritoryGroup = 'North America'
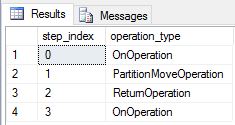
We zijn opnieuw gemaakt DimDate en DimSalesTerritory als round robin-tabellen. Als gevolg hiervan heeft de query het volgende queryplan weergegeven, met meerdere verplaatsingsbewerkingen voor broadcasts:

We zijn opnieuw gemaakt DimDate en DimSalesTerritory als gerepliceerde tabellen en hebben de query opnieuw uitgevoerd. Het resulterende queryplan is veel korter en heeft geen broadcast-verplaatsingen.
Prestatieoverwegingen voor het wijzigen van gerepliceerde tabellen
Sql-pool implementeert een gerepliceerde tabel door een hoofdversie van de tabel te onderhouden. De hoofdversie wordt gekopieerd naar de eerste distributiedatabase op elk rekenknooppunt. Wanneer er een wijziging is, wordt de hoofdversie eerst bijgewerkt en worden de tabellen op elk rekenknooppunt opnieuw opgebouwd. Een herbouw van een gerepliceerde tabel omvat het kopiëren van de tabel naar elk rekenknooppunt en het bouwen van de indexen. Een gerepliceerde tabel op een DW2000c heeft bijvoorbeeld vijf kopieën van de gegevens. Een hoofdkopie en een volledige kopie op elk rekenknooppunt. Alle gegevens worden opgeslagen in distributiedatabases. SQL-pool gebruikt dit model om snellere instructies voor gegevenswijziging en flexibele schaalbewerkingen te ondersteunen.
Asynchrone herbouwbewerkingen worden geactiveerd door de eerste query voor de gerepliceerde tabel na:
- Gegevens worden geladen of gewijzigd
- Het Synapse SQL-exemplaar wordt geschaald naar een ander niveau
- Tabeldefinitie wordt bijgewerkt
Herbouwen zijn niet vereist na:
- Bewerking onderbreken
- Hervattingsbewerking
De herbouw vindt niet direct plaats nadat de gegevens zijn gewijzigd. In plaats daarvan wordt het opnieuw opbouwen geactiveerd wanneer een query voor het eerst in de tabel wordt geselecteerd. De query die de herbouw heeft geactiveerd, leest direct uit de hoofdversie van de tabel, terwijl de gegevens asynchroon naar elk rekenknooppunt worden gekopieerd. Totdat het kopiëren van gegevens is voltooid, blijven volgende query's de hoofdversie van de tabel gebruiken. Als er activiteit plaatsvindt op basis van de gerepliceerde tabel die een andere herbouwing dwingt, wordt de gegevenskopie ongeldig gemaakt en wordt met de volgende select-instructie opnieuw gegevens gekopieerd.
Indexen conservatief gebruiken
Standaardindexeringsprocedures zijn van toepassing op gerepliceerde tabellen. Sql-pool bouwt elke gerepliceerde tabelindex opnieuw op als onderdeel van de herbouw. Gebruik alleen indexen wanneer de prestatiewinst opweegt tegen de kosten van het herbouwen van de indexen.
Batchgegevens laden
Wanneer u gegevens in gerepliceerde tabellen laadt, probeert u het aantal herbouwbewerkingen te minimaliseren door samen te laden. Voer alle batchbelastingen uit voordat u select-instructies uitvoert.
Met dit laadpatroon worden bijvoorbeeld gegevens uit vier bronnen geladen en worden vier herbouwingen aangeroepen.
- Laden vanaf bron 1.
- Selecteer instructietriggers herbouwen 1.
- Laden vanaf bron 2.
- Selecteer instructietriggers herbouwen 2.
- Laden vanaf bron 3.
- Selecteer instructietriggers herbouwen 3.
- Laden vanaf bron 4.
- Selecteer instructietriggers herbouwen 4.
Met dit laadpatroon worden bijvoorbeeld gegevens uit vier bronnen geladen, maar wordt slechts één herbouwing aangeroepen.
- Laden vanaf bron 1.
- Laden vanaf bron 2.
- Laden vanaf bron 3.
- Laden vanaf bron 4.
- Selecteer instructietriggers herbouwen.
Een gerepliceerde tabel opnieuw opbouwen na een batchbelasting
Om consistente uitvoeringstijden voor query's te garanderen, kunt u overwegen om de build van de gerepliceerde tabellen na een batchbelasting af te dwingen. Anders gebruikt de eerste query nog steeds gegevensverplaatsing om de query te voltooien.
Met de bewerking 'Gerepliceerde tabelcache bouwen' kunnen maximaal twee bewerkingen tegelijk worden uitgevoerd. Als u bijvoorbeeld probeert de cache voor vijf tabellen opnieuw op te bouwen, maakt het systeem gebruik van een staticrc20 (die niet kan worden gewijzigd) om tegelijkertijd twee tabellen te bouwen. Daarom wordt het aangeraden om het gebruik van grote gerepliceerde tabellen van meer dan 2 GB te vermijden, omdat dit het opnieuw opbouwen van de cache op de nodes kan vertragen en de algehele tijd kan verlengen.
Deze query maakt gebruik van de sys.pdw_replicated_table_cache_state DMV om de gerepliceerde tabellen weer te geven die zijn gewijzigd, maar niet opnieuw opgebouwd.
SELECT SchemaName = SCHEMA_NAME(t.schema_id)
, [ReplicatedTable] = t.[name]
, [RebuildStatement] = 'SELECT TOP 1 * FROM ' + '[' + SCHEMA_NAME(t.schema_id) + '].[' + t.[name] +']'
FROM sys.tables t
JOIN sys.pdw_replicated_table_cache_state c
ON c.object_id = t.object_id
JOIN sys.pdw_table_distribution_properties p
ON p.object_id = t.object_id
WHERE c.[state] = 'NotReady'
AND p.[distribution_policy_desc] = 'REPLICATE'
Als u een herbouw wilt activeren, voert u de volgende instructie uit op elke tabel in de voorgaande uitvoer.
SELECT TOP 1 * FROM [ReplicatedTable]
Notitie
Als u van plan bent om de statistieken van de niet-in de cache gerepliceerde tabel opnieuw op te bouwen, moet u de statistieken bijwerken voordat u de cache activeert. Als u statistieken bijwerkt, wordt de cache ongeldig, zodat de volgorde belangrijk is.
Voorbeeld: Begin met UPDATE STATISTICSen activeer vervolgens de herbouw van de cache. In de volgende voorbeelden werkt het juiste voorbeeld de statistieken bij en wordt vervolgens de herbouw van de cache geactiveerd.
-- Incorrect sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
SELECT TOP 1 * FROM [ReplicatedTable]
UPDATE STATISTICS [ReplicatedTable]
END
-- Correct sequence. Ensure that the rebuild operation is the last statement within the batch.
BEGIN
UPDATE STATISTICS [ReplicatedTable]
SELECT TOP 1 * FROM [ReplicatedTable]
END
Als u het herbouwproces wilt bewaken, kunt u sys.dm_pdw_exec_requests gebruiken, waar de command begint met 'BuildReplicatedTableCache'. Voorbeeld:
-- Monitor Build Replicated Cache
SELECT *
FROM sys.dm_pdw_exec_requests
WHERE command like 'BuildReplicatedTableCache%'
Tip
Query's met tabelgrootte kunnen worden gebruikt om te controleren welke tabellen een gerepliceerd distributiebeleid hebben en welke groter zijn dan 2 GB.
Volgende stappen
Gebruik een van de volgende instructies om een gerepliceerde tabel te maken:
Zie gedistribueerde tabellen voor een overzicht van gedistribueerde tabellen.