Beschikbaarheid van SAP HANA binnen één Azure-regio
In dit artikel worden verschillende beschikbaarheidsscenario's beschreven voor SAP HANA binnen één Azure-regio. Azure heeft veel regio's, verspreid over de hele wereld. Zie Azure-regio's voor de lijst met Azure-regio's. Voor het implementeren van SAP HANA op VM's binnen één Azure-regio biedt Microsoft implementatie van één VIRTUELE machine met een HANA-exemplaar. Voor een hogere beschikbaarheid kunt u twee VM's met twee HANA-exemplaren implementeren met behulp van een flexibele schaalset met FD=1, beschikbaarheidszones of een beschikbaarheidsset die gebruikmaakt van HANA-systeemreplicatie voor beschikbaarheid.
Azure-regio's die Beschikbaarheidszones bestaan uit meerdere datacenters, elk met een eigen voedingsbron, koeling en netwerkinfrastructuur. Het doel van het aanbieden van verschillende zones binnen één Azure-regio is het inschakelen van de implementatie van toepassingen in twee of drie beschikbare Beschikbaarheidszones. Als u uw toepassingsimplementatie over zones distribueert, kunnen energie- of netwerkproblemen die van invloed zijn op een specifieke Infrastructuur voor azure-beschikbaarheidszones de functionaliteit van uw toepassing in de Azure-regio niet volledig verstoren. Hoewel er mogelijk minder capaciteit is, zoals het potentiële verlies van VM's in één zone, blijven de VM's in de resterende zones zonder onderbreking werken. Als u twee HANA-exemplaren wilt instellen in afzonderlijke VM's die zich in verschillende zones bevinden, hebt u de mogelijkheid om VM's te implementeren met behulp van de flexibele schaalset met de implementatieoptie FD=1 of beschikbaarheidszones .
Voor een grotere beschikbaarheid binnen een regio is het raadzaam om twee VM's met twee HANA-exemplaren te implementeren met behulp van een beschikbaarheidsset. Een Azure-beschikbaarheidsset is een logische groeperingsmogelijkheid die ervoor zorgt dat de VM-resources die in de beschikbaarheidsset zijn geconfigureerd, gescheiden zijn van elkaar wanneer ze worden geïmplementeerd in een Azure-datacenter. Azure zorgt ervoor dat de VM's die u in een beschikbaarheidsset plaatst, op meerdere fysieke servers, rekenrekken, opslageenheden en netwerkswitches worden uitgevoerd. In sommige Azure-documentatie wordt deze configuratie aangeduid als plaatsingen in verschillende update- en foutdomeinen. Deze plaatsingen bevinden zich meestal in een Azure-datacenter. Ervan uitgaande dat energiebron- en netwerkproblemen van invloed zijn op het datacenter dat u implementeert, worden al uw capaciteit in één Azure-regio beïnvloed.
De plaatsing van datacenters die Azure Beschikbaarheidszones vertegenwoordigen, is een compromis tussen het leveren van acceptabele netwerklatentie tussen services die in verschillende zones zijn geïmplementeerd en een afstand tussen datacenters. Natuurrampen zouden in het ideale ideaal geen invloed hebben op de voeding, netwerktoevoer en infrastructuur voor alle Beschikbaarheidszones in deze regio. Zoals echter blijkt uit monumentale natuurrampen, biedt Beschikbaarheidszones mogelijk niet altijd de gewenste beschikbaarheid binnen één regio. Denk aan Orkaan Maria die op 20 september 2017 het eiland Puerto Rico heeft geraakt. De orkaan veroorzaakte in principe een blackout van bijna 100 procent op het eiland van 90 mijl.
Scenario met één VM
In een scenario met één VM maakt u een Azure-VM voor het SAP HANA-exemplaar. U gebruikt Azure Premium Storage om de besturingssysteemschijf en al uw gegevensschijven te hosten. De SLA voor azure-uptime van 99,9 procent en de SLA's van andere Azure-onderdelen is voldoende voor u om te voldoen aan uw beschikbaarheids-SLA's voor uw klanten. In dit scenario hoeft u geen Azure-beschikbaarheidsset te gebruiken voor VM's waarop de DBMS-laag wordt uitgevoerd. In dit scenario vertrouwt u op twee verschillende functies:
- Automatisch opnieuw opstarten van Azure-VM 's (ook wel azure-serviceherstel genoemd)
- Automatisch opnieuw opstarten van SAP HANA
Automatisch opnieuw opstarten van Azure-VM of herstel van services is een functionaliteit in Azure die op twee niveaus werkt:
- De Azure-serverhost controleert de status van een virtuele machine die wordt gehost op de serverhost.
- De Azure-infrastructuurcontroller bewaakt de status en beschikbaarheid van de serverhost.
Een statuscontrolefunctie bewaakt de status van elke VIRTUELE machine die wordt gehost op een Azure-serverhost. Als een VIRTUELE machine in een niet-goede status valt, kan een herstart van de VIRTUELE machine worden gestart door de Azure-hostagent die de status van de VIRTUELE machine controleert. De infrastructuurcontroller controleert de status van de host door veel verschillende parameters te controleren die mogelijk problemen met de hosthardware aangeven. Ook wordt gecontroleerd op de toegankelijkheid van de host via het netwerk. Een indicatie van problemen met de host kan leiden tot de volgende gebeurtenissen:
- Als de host een slechte status aangeeft, wordt het opnieuw opstarten van de host en het opnieuw opstarten van de VM's die op de host werden uitgevoerd, geactiveerd.
- Als de host na het opnieuw opstarten niet in orde is, wordt een herverdeling van de VM's die zich oorspronkelijk op het nu beschadigde knooppunt op een goede hostserver bevonden, geïnitieerd. In dit geval is de oorspronkelijke host gemarkeerd als niet in orde. Deze wordt pas gebruikt voor verdere implementaties als deze is gewist of vervangen.
- Als de beschadigde host problemen ondervindt tijdens het opnieuw opstarten, wordt een onmiddellijke herstart van de VM's op een goede host geactiveerd.
Met de host- en VM-bewaking die wordt geleverd door Azure, worden azure-VM's die hostproblemen ondervinden, automatisch opnieuw opgestart op een goede Azure-host.
Belangrijk
Azure-serviceherstel start linux-VM's niet opnieuw, waarbij het gastbesturingssystemen een kernel-paniekstatus hebben. De standaardinstellingen van de veelgebruikte Linux-releases worden niet automatisch opnieuw opgestart op VM's of servers waarop de Linux-kernel in paniek is. In plaats daarvan voorziet de standaardinstelling dat het besturingssysteem in paniekstatus van kernel blijft om een kernelfoutopsporingsprogramma te kunnen koppelen om te analyseren. Azure eert dit gedrag door een VIRTUELE machine niet automatisch opnieuw op te starten met het gastbesturingssystemen in een dergelijke status. Veronderstelling is dat dergelijke gebeurtenissen zeer zeldzaam zijn. U kunt het standaardgedrag overschrijven om het opnieuw opstarten van de virtuele machine in te schakelen. Als u het standaardgedrag wilt wijzigen, schakelt u de parameter kernel.panic in /etc/sysctl.conf in. De tijd die u voor deze parameter hebt ingesteld, duurt in seconden. Algemene aanbevolen waarden moeten 20-30 seconden wachten voordat de herstart via deze parameter wordt geactiveerd. Zie sysctl.conf voor meer informatie.
De tweede functie die u in dit scenario gebruikt, is het feit dat de HANA-service die wordt uitgevoerd op een opnieuw opgestarte VM automatisch wordt gestart nadat de VM opnieuw is opgestart. U kunt automatische herstart van de HANA-service instellen via de watchdog-services van de verschillende HANA-services.
U kunt dit scenario met één VM verbeteren door een koud failoverknooppunt toe te voegen aan een SAP HANA-configuratie. In de SAP HANA-documentatie wordt deze installatie autofailover van de host genoemd. Deze configuratie kan zinvol zijn in een on-premises implementatiesituatie waarbij de serverhardware beperkt is en u een knooppunt met één server toedraagt als het hostknooppunt voor automatischefailover voor een set productiehosts. Maar in Azure, waar de onderliggende infrastructuur van Azure een gezonde doelserver biedt voor een geslaagde VM-herstart, is het niet zinvol om automatisch opnieuw opstarten van SAP HANA-hosts te implementeren. Vanwege herstel van azure-services is er geen referentiearchitectuur die voorziet in een stand-byknooppunt voor automatischefailover van de HANA-host.
Speciaal geval van uitschaalconfiguraties van SAP HANA in Azure
Architecturen met hoge beschikbaarheid op basis van stand-byknooppunt of HANA-systeemreplicatie vindt u in de volgende documenten. In gevallen waarin stand-byknooppunten of hoge beschikbaarheid van HANA-systeemreplicatie niet worden gebruikt in uitschaalconfiguraties van SAP HANA, kunt u afhankelijk zijn van de herstelmogelijkheden van azure-VM's en de automatische herstart van het SAP HANA-exemplaar zodra de VM weer operationeel is.
- RedHat Enterprise Linux
- SUSE Linux Enterprise Server
Beschikbaarheidsscenario's voor twee verschillende VM's
Om ervoor te zorgen dat het HANA-systeem binnen een specifieke regio beschikbaar is, hebt u de mogelijkheid om twee VM's te configureren in de beschikbaarheidszones van de regio of binnen de regio. Om dit doel te bereiken, kunt u de VM's configureren met behulp van een flexibele schaalset, beschikbaarheidszones of implementatieoptie voor beschikbaarheidssets. De basisinstallatie in Azure ziet er als volgt uit:
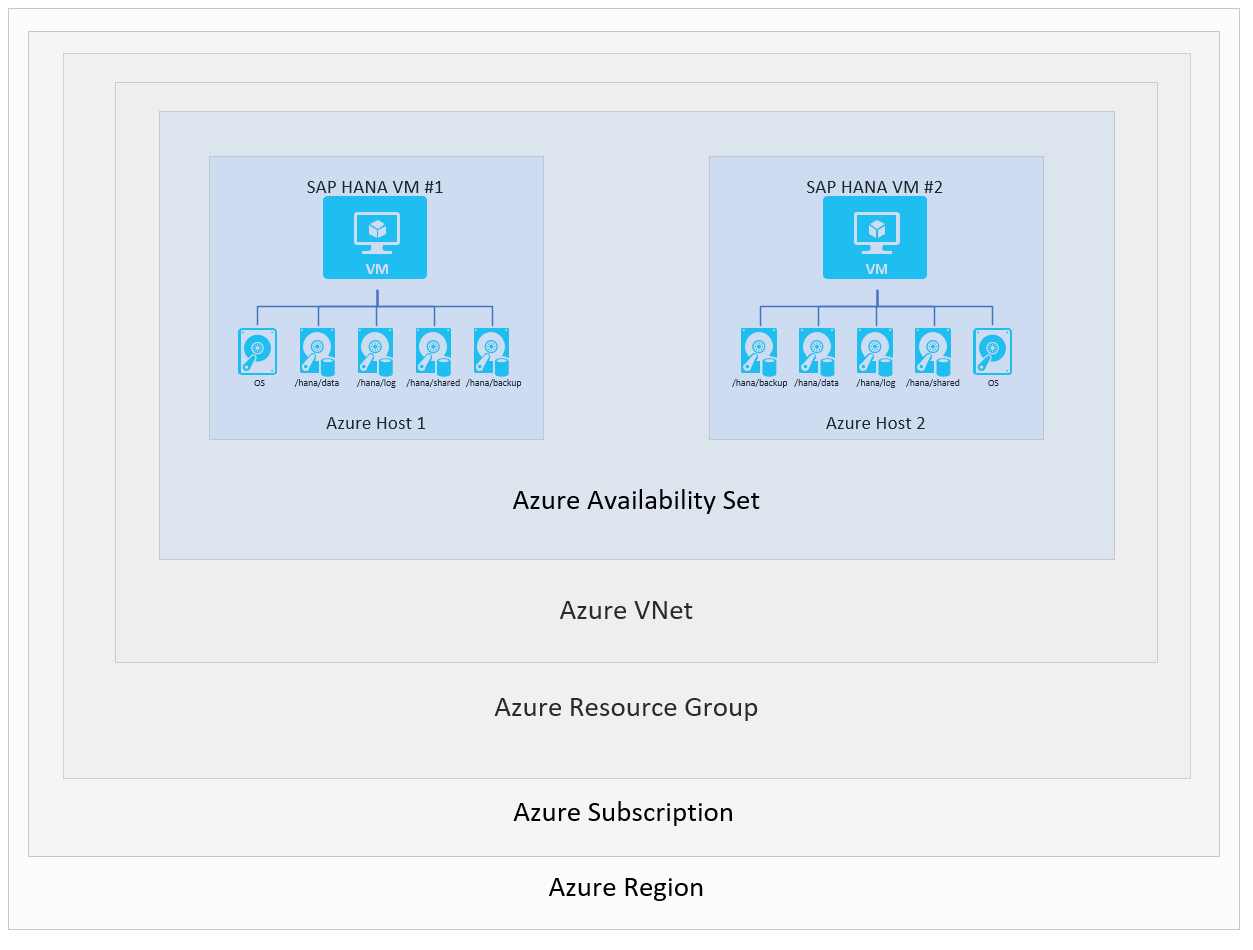
Ter illustratie van de verschillende SAP HANA-beschikbaarheidsscenario's worden enkele lagen in het diagram weggelaten. In het diagram ziet u alleen lagen met VM's, hosts, beschikbaarheidssets en Azure-regio's. Azure Virtual Network-exemplaren, resourcegroepen en abonnementen spelen geen rol in de scenario's die in deze sectie worden beschreven.
Back-ups repliceren naar een tweede virtuele machine
Een van de meest elementaire instellingen is het gebruik van back-ups. Het is met name mogelijk dat er back-ups van transactielogboeken zijn verzonden van de ene VM naar een andere Azure-VM. U kunt het Azure Storage-type kiezen. In deze installatie bent u verantwoordelijk voor het uitvoeren van scripts voor de kopie van geplande back-ups die worden uitgevoerd op de eerste VM naar de tweede VM. Als u de tweede VM-exemplaren wilt gebruiken, moet u de volledige back-ups van incrementele/differentiële en transactielogboeken herstellen naar het punt dat u nodig hebt.
De architectuur ziet er als volgt uit:
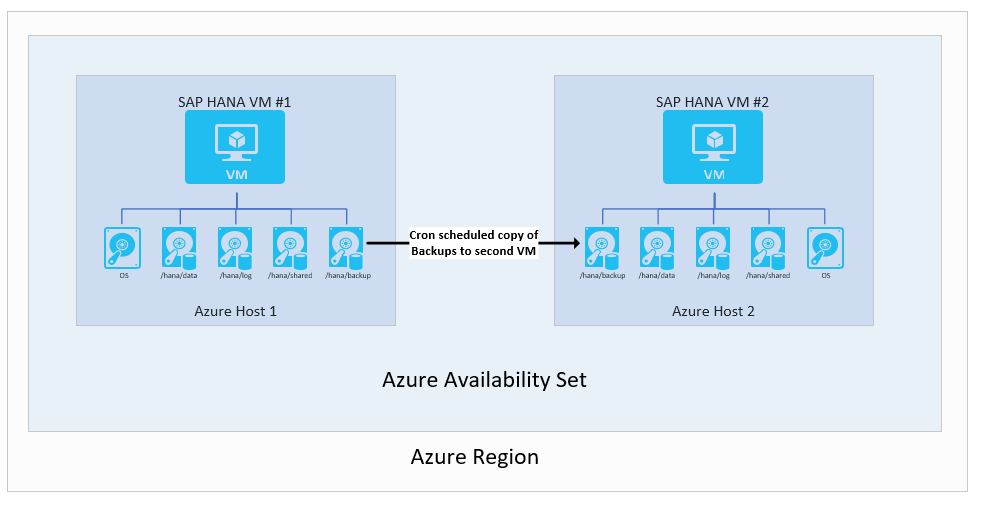
Deze installatie is niet geschikt voor het bereiken van goede RPO-tijden (Recovery Point Objective) en Recovery Time Objective (RTO). RTO-tijden hebben met name te maken met de noodzaak om de volledige database volledig te herstellen met behulp van de gekopieerde back-ups. Deze installatie is echter handig voor het herstellen van onbedoelde gegevensverwijdering op de hoofdexemplaren. Met deze installatie kunt u op elk gewenst moment herstellen naar een bepaald tijdstip, de gegevens extraheren en de verwijderde gegevens importeren in uw hoofdexemplaren. Daarom kan het zinvol zijn om een back-upkopiemethode te gebruiken in combinatie met andere functionaliteit voor hoge beschikbaarheid.
Tijdens het kopiëren van back-ups kunt u mogelijk een kleinere VM gebruiken dan de hoofd-VM waarop het SAP HANA-exemplaar wordt uitgevoerd. Houd er rekening mee dat u een kleiner aantal VHD's aan kleinere VM's kunt koppelen. Zie Grootten voor virtuele Linux-machines in Azure voor meer informatie over de limieten van afzonderlijke VM-typen.
SAP HANA-systeemreplicatie zonder automatische failover
In de scenario's die in deze sectie worden beschreven, wordt sap HANA-systeemreplicatie gebruikt. Zie Systeemreplicatie voor de SAP-documentatie. Scenario's zonder automatische failover zijn niet gebruikelijk voor configuraties binnen één Azure-regio. Een configuratie zonder automatische failover, maar vermijdt een Pacemaker-installatie, verplicht u handmatig te controleren en failover uit te voeren. Omdat dit ook in beslag neemt en de inspanningen zijn, vertrouwen de meeste klanten in plaats daarvan op herstel van Azure-services. Er zijn enkele edge-gevallen waarin deze configuratie kan helpen bij foutscenario's. Of in sommige gevallen wil een klant mogelijk meer efficiëntie realiseren.
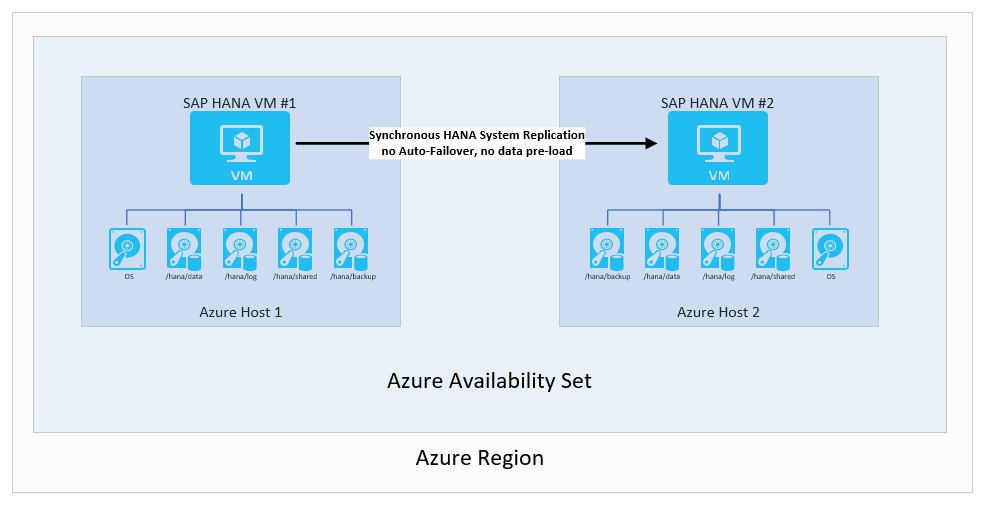
SAP HANA-systeemreplicatie zonder automatische failover en zonder gegevens vooraf laden
In dit scenario gebruikt u SAP HANA-systeemreplicatie om gegevens synchroon te verplaatsen om een RPO van 0 te bereiken. Aan de andere kant hebt u een lang genoeg RTO die u niet nodig hebt voor failover of het vooraf laden van gegevens in de cache van het HANA-exemplaar. In dit geval is het mogelijk om een verdere economie in uw configuratie te bereiken door de volgende acties uit te voeren:
- Voer een ander SAP HANA-exemplaar uit op de tweede VM. Het SAP HANA-exemplaar in de tweede VM neemt het grootste deel van het geheugen van de virtuele machine in beslag. Als u een failover naar de tweede VIRTUELE machine uitvoert, moet u het actieve SAP HANA-exemplaar afsluiten waarop de gegevens volledig zijn geladen in de tweede VM, zodat de gerepliceerde gegevens in de cache van het beoogde HANA-exemplaar in de tweede VM kunnen worden geladen.
- Gebruik een kleinere VM-grootte op de tweede VM. Als er een failover optreedt, hebt u een extra stap vóór de handmatige failover. In deze stap wijzigt u het formaat van de VIRTUELE machine in de grootte van de bron-VM.
Het scenario ziet er als volgt uit:
Notitie
Zelfs als u geen gegevens vooraf laadt in het replicatiedoel van het HANA-systeem, hebt u ten minste 64 GB geheugen nodig. U hebt ook voldoende geheugen nodig naast 64 GB om de rijopslaggegevens in het geheugen van het doelexemplaren te bewaren.
SAP HANA-systeemreplicatie zonder automatische failover en met vooraf laden van gegevens
In dit scenario worden gegevens die worden gerepliceerd naar het HANA-exemplaar in de tweede VM vooraf geladen. Dit elimineert de twee voordelen van het niet vooraf laden van gegevens. In dit geval kunt u geen ander SAP HANA-systeem uitvoeren op de tweede VIRTUELE machine. U kunt ook geen kleinere VM-grootte gebruiken. Daarom implementeren klanten dit scenario zelden.
SAP HANA-systeemreplicatie met automatische failover
In de standaard- en meest voorkomende beschikbaarheidsconfiguratie binnen één Azure-regio hebben twee Azure-VM's met Linux met HA-pakketten een failovercluster gedefinieerd. Het Linux-cluster ha is gebaseerd op het Pacemaker framework met behulp van SLES of RHEL met eenfencing device SLES of RHEL als voorbeeld.
Vanuit het perspectief van SAP HANA wordt de gebruikte replicatiemodus gesynchroniseerd en wordt een automatische failover geconfigureerd. In de tweede VIRTUELE machine fungeert het SAP HANA-exemplaar als een hot standby-knooppunt. Het stand-byknooppunt ontvangt een synchrone stroom van wijzigingsrecords van het primaire SAP HANA-exemplaar. Wanneer transacties worden doorgevoerd door de toepassing op het primaire KNOOPPUNT van HANA, wacht het primaire HANA-knooppunt om de doorvoering naar de toepassing te bevestigen totdat het secundaire SAP HANA-knooppunt bevestigt dat het de doorvoerrecord heeft ontvangen. SAP HANA biedt twee synchrone replicatiemodi. Zie het SAP-artikel Replicatiemodi voor SAP HANA-systeemreplicatie voor meer informatie en een beschrijving van de verschillen tussen deze twee synchrone replicatiemodi.
De algehele configuratie ziet er als volgt uit:
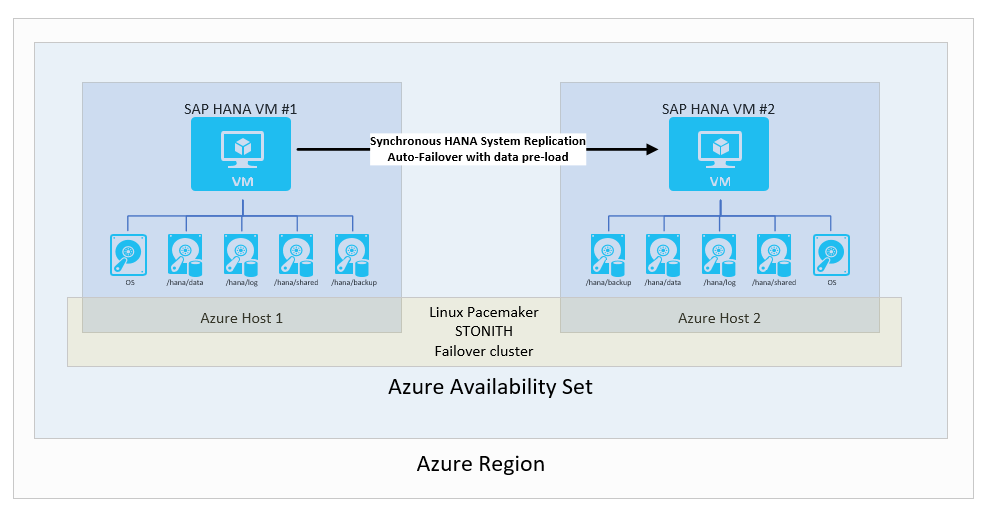
U kunt deze oplossing kiezen omdat u hiermee een RPO=0 en een lage RTO kunt bereiken. Configureer de SAP HANA-clientconnectiviteit zodat de SAP HANA-clients het virtuele IP-adres gebruiken om verbinding te maken met de replicatieconfiguratie van het HANA-systeem. Een dergelijke configuratie elimineert de noodzaak om de toepassing opnieuw te configureren als er een failover naar het secundaire knooppunt plaatsvindt. In dit scenario moeten de Azure VM-SKU's voor de primaire en secundaire VM's hetzelfde zijn.
Volgende stappen
Zie voor stapsgewijze instructies voor het instellen van deze configuraties in Azure:
- SAP HANA-systeemreplicatie instellen in Virtuele Azure-machines
- Hoge beschikbaarheid voor SAP HANA met behulp van systeemreplicatie
Zie voor meer informatie over de beschikbaarheid van SAP HANA in Azure-regio's: