Azure Kubernetes-netwerkbeleid
Netwerkbeleid biedt microsegmentatie voor pods, net zoals netwerkbeveiligingsgroepen (NSG's) bieden microsegmentatie voor VM's. De implementatie van Azure Network Policy Manager ondersteunt de standaardspecificatie van Kubernetes-netwerkbeleid. U kunt labels gebruiken om een groep pods te selecteren en een lijst met regels voor inkomend en uitgaand verkeer te definiëren om verkeer naar en van deze pods te filteren. Meer informatie over het Kubernetes-netwerkbeleid vindt u in de Kubernetes-documentatie.
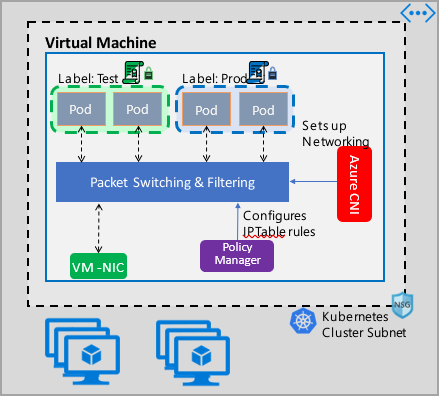
De implementatie van Azure Network Policy Management werkt met de Azure CNI die integratie van virtuele netwerken biedt voor containers. Network Policy Manager wordt ondersteund in Linux en Windows Server. De implementatie dwingt verkeer filteren af door IP-regels voor toestaan en weigeren te configureren op basis van het gedefinieerde beleid in Linux IPTables of Host Network Service (HNS) ACLPolicies voor Windows Server.
Beveiliging plannen voor uw Kubernetes-cluster
Wanneer u beveiliging voor uw cluster implementeert, gebruikt u netwerkbeveiligingsgroepen (NSG's) om verkeer te filteren dat uw clustersubnet binnenkomt en verlaat (noord-zuid-verkeer). Gebruik Azure Network Policy Manager voor verkeer tussen pods in uw cluster (oost-west-verkeer).
Azure Network Policy Manager gebruiken
Azure Network Policy Manager kan op de volgende manieren worden gebruikt om microsegmentatie te bieden voor pods.
Azure Kubernetes Service (AKS)
Network Policy Manager is systeemeigen beschikbaar in AKS en kan worden ingeschakeld op het moment dat het cluster wordt gemaakt.
Zie Verkeer tussen pods beveiligen met behulp van netwerkbeleid in Azure Kubernetes Service (AKS) voor meer informatie.
Doe het zelf (DIY) Kubernetes-clusters in Azure
Voor DIY-clusters installeert u eerst de CNI-invoegtoepassing en schakelt u deze in op elke virtuele machine in een cluster. Zie Deploy plug-in for a Kubernetes cluster (Invoegtoepassing implementeren voor een Kubernetes-cluster) voor gedetailleerde instructies.
Zodra het cluster is geïmplementeerd, voert u de volgende kubectl opdracht uit om de Azure Network Policy Manager-daemon die is ingesteld op het cluster te downloaden en toe te passen.
Voor Linux:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/azure-npm.yaml
Voor Windows:
kubectl apply -f https://raw.githubusercontent.com/Azure/azure-container-networking/master/npm/examples/windows/azure-npm.yaml
De oplossing is ook open source en de code is beschikbaar in de Azure Container Networking-opslagplaats.
Netwerkconfiguraties bewaken en visualiseren met Azure NPM
Azure Network Policy Manager bevat informatieve Prometheus-metrische gegevens waarmee u uw configuraties kunt bewaken en beter kunt begrijpen. Het biedt ingebouwde visualisaties in Azure Portal of Grafana Labs. U kunt beginnen met het verzamelen van deze metrische gegevens met behulp van Azure Monitor of een Prometheus-server.
Voordelen van metrische gegevens van Azure Network Policy Manager
Gebruikers konden eerder alleen meer te weten komen over hun netwerkconfiguratie met iptables en ipset opdrachten die worden uitgevoerd in een clusterknooppunt, wat een uitgebreide en moeilijk te begrijpen uitvoer oplevert.
Over het algemeen bieden de metrische gegevens het volgende:
Aantal beleidsregels, ACL-regels, ipsets, ipset-vermeldingen en vermeldingen in een bepaalde ipset
Uitvoeringstijden voor afzonderlijke aanroepen van het besturingssysteem en voor het verwerken van kubernetes-resource-gebeurtenissen (mediaan, 90e percentiel en 99e percentiel)
Foutinformatie voor het verwerken van kubernetes-resource-gebeurtenissen (deze resource-gebeurtenissen mislukken wanneer een aanroep van het besturingssysteem mislukt)
Gebruiksvoorbeelden voor metrische gegevens
Waarschuwingen via een Prometheus AlertManager
Bekijk als volgt een configuratie voor deze waarschuwingen .
Waarschuwing wanneer Network Policy Manager een fout heeft met een besturingssysteemaanroep of bij het vertalen van een netwerkbeleid.
Waarschuwing wanneer de mediaantijd voor het toepassen van wijzigingen voor een create-gebeurtenis meer dan 100 milliseconden bedroeg.
Visualisaties en foutopsporing via ons Grafana-dashboard of Azure Monitor-werkmap
Bekijk hoeveel IPTables-regels uw beleid maakt (met een groot aantal IPTables-regels kan de latentie enigszins toenemen).
Koppel clusteraantallen (bijvoorbeeld ACL's) aan uitvoeringstijden.
Haal de mensvriendelijke naam van een ipset op in een bepaalde IPTables-regel (bijvoorbeeld
azure-npm-487392vertegenwoordigt).podlabel-role:database
Alle ondersteunde metrische gegevens
De volgende lijst bevat ondersteunde metrische gegevens. Elk quantile label heeft mogelijke waarden 0.5, 0.9en 0.99. Elk had_error label heeft mogelijke waarden false en truegeeft aan of de bewerking is geslaagd of mislukt.
| Naam meetwaarde | Beschrijving | Prometheus Metric Type | Etiketten |
|---|---|---|---|
npm_num_policies |
aantal netwerkbeleidsregels | Meter | - |
npm_num_iptables_rules |
aantal IPTables-regels | Meter | - |
npm_num_ipsets |
aantal IPSets | Meter | - |
npm_num_ipset_entries |
aantal IP-adresvermeldingen in alle IPSets | Meter | - |
npm_add_iptables_rule_exec_time |
runtime voor het toevoegen van een IPTables-regel | Samenvatting | quantile |
npm_add_ipset_exec_time |
runtime voor het toevoegen van een IPSet | Samenvatting | quantile |
npm_ipset_counts (geavanceerd) |
aantal vermeldingen binnen elke afzonderlijke IPSet | MeterVec | set_name & set_hash |
npm_add_policy_exec_time |
runtime voor het toevoegen van een netwerkbeleid | Samenvatting | quantile & had_error |
npm_controller_policy_exec_time |
runtime voor het bijwerken/verwijderen van een netwerkbeleid | Samenvatting | quantileoperation & had_error (met waarden update of delete) |
npm_controller_namespace_exec_time |
runtime voor het maken/bijwerken/verwijderen van een naamruimte | Samenvatting | quantile&& operation ( had_error met waardencreate, updateof delete) |
npm_controller_pod_exec_time |
runtime voor het maken/bijwerken/verwijderen van een pod | Samenvatting | quantile&& operation ( had_error met waardencreate, updateof delete) |
Er zijn ook metrische gegevens 'exec_time_count' en 'exec_time_sum' voor elke metrische samenvattingswaarde 'exec_time'.
De metrische gegevens kunnen worden geschraapt via Azure Monitor voor containers of via Prometheus.
Instellen voor Azure Monitor
De eerste stap is het inschakelen van Azure Monitor voor containers voor uw Kubernetes-cluster. De stappen vindt u in Azure Monitor voor containers, overzicht. Zodra Azure Monitor voor containers is ingeschakeld, configureert u de Azure Monitor voor containers ConfigMap om integratie van Network Policy Manager en verzameling van metrische gegevens van Prometheus Network Policy Manager in te schakelen.
Azure Monitor voor containers ConfigMap bevat een integrations sectie met instellingen voor het verzamelen van metrische gegevens van Network Policy Manager.
Deze instellingen zijn standaard uitgeschakeld in de ConfigMap. Als u de basisinstelling collect_basic_metrics = trueinschakelt, worden metrische basisgegevens van Network Policy Manager verzameld. Bij het inschakelen van de geavanceerde instelling collect_advanced_metrics = true worden geavanceerde metrische gegevens verzameld naast basisgegevens.
Nadat u de ConfigMap hebt bewerkt, slaat u deze lokaal op en past u de ConfigMap als volgt toe op uw cluster.
kubectl apply -f container-azm-ms-agentconfig.yaml
Het volgende codefragment is afkomstig van azure Monitor voor containers ConfigMap, waarin de integratie van Network Policy Manager is ingeschakeld met geavanceerde verzameling metrische gegevens.
integrations: |-
[integrations.azure_network_policy_manager]
collect_basic_metrics = false
collect_advanced_metrics = true
Geavanceerde metrische gegevens zijn optioneel en als u ze inschakelt, worden metrische basisgegevens automatisch ingeschakeld. Geavanceerde metrische gegevens bevatten momenteel alleen Network Policy Manager_ipset_counts.
Meer informatie over verzamelingsinstellingen voor Azure Monitor voor containers in configuratietoewijzing.
Visualisatieopties voor Azure Monitor
Zodra de verzameling metrische gegevens van Network Policy Manager is ingeschakeld, kunt u de metrische gegevens in Azure Portal bekijken met behulp van containerinzichten of in Grafana.
Weergeven in Azure Portal onder inzichten voor het cluster
Open Azure Portal. Ga in de inzichten van uw cluster naar Workbooks en open Network Policy Manager (Network Policy Manager) Configuration.
Naast het weergeven van de werkmap kunt u ook rechtstreeks query's uitvoeren op de metrische Prometheus-gegevens in Logboeken onder de sectie Inzichten. Deze query retourneert bijvoorbeeld alle metrische gegevens die worden verzameld.
| where TimeGenerated > ago(5h)
| where Name contains "npm_"
U kunt ook rechtstreeks query's uitvoeren op Log Analytics voor de metrische gegevens. Zie Aan de slag met Log Analytics-query's voor meer informatie.
Weergeven in Grafana-dashboard
Stel uw Grafana Server in en configureer een log analytics-gegevensbron, zoals hier wordt beschreven. Importeer vervolgens Grafana Dashboard met een Log Analytics-back-end in uw Grafana Labs.
Het dashboard heeft visuals die vergelijkbaar zijn met de Azure-werkmap. U kunt deelvensters toevoegen om metrische gegevens van Network Policy Manager uit de insightsmetrics-tabel te visualiseren.
Instellen voor Prometheus-server
Sommige gebruikers kunnen ervoor kiezen om metrische gegevens te verzamelen met een Prometheus-server in plaats van Azure Monitor voor containers. U hoeft slechts twee taken toe te voegen aan uw scrape-configuratie om metrische gegevens van Network Policy Manager te verzamelen.
Als u een Prometheus-server wilt installeren, voegt u deze Helm-opslagplaats toe aan uw cluster:
helm repo add stable https://kubernetes-charts.storage.googleapis.com
helm repo update
voeg vervolgens een server toe
helm install prometheus stable/prometheus -n monitoring \
--set pushgateway.enabled=false,alertmanager.enabled=false, \
--set-file extraScrapeConfigs=prometheus-server-scrape-config.yaml
waarbij prometheus-server-scrape-config.yaml bestaat uit:
- job_name: "azure-npm-node-metrics"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
- job_name: "azure-npm-cluster-metrics"
metrics_path: /cluster-metrics
kubernetes_sd_configs:
- role: service
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_service_name]
regex: npm-metrics-cluster-service
action: keep
# Comment from here to the end to collect advanced metrics: number of entries for each IPSet
metric_relabel_configs:
- source_labels: [__name__]
regex: npm_ipset_counts
action: drop
U kunt de azure-npm-node-metrics taak ook vervangen door de volgende inhoud of opnemen in een bestaande taak voor Kubernetes-pods:
- job_name: "azure-npm-node-metrics-from-pod-config"
metrics_path: /node-metrics
kubernetes_sd_configs:
- role: pod
relabel_configs:
- source_labels: [__meta_kubernetes_namespace]
regex: kube-system
action: keep
- source_labels: [__meta_kubernetes_pod_annotationpresent_azure_Network Policy Manager_scrapeable]
action: keep
- source_labels: [__address__]
action: replace
regex: ([^:]+)(?::\d+)?
replacement: "$1:10091"
target_label: __address__
Waarschuwingen instellen voor AlertManager
Als u een Prometheus-server gebruikt, kunt u een AlertManager zo instellen. Hier volgt een voorbeeldconfiguratie voor de twee eerder beschreven waarschuwingsregels:
groups:
- name: npm.rules
rules:
# fire when Network Policy Manager has a new failure with an OS call or when translating a Network Policy (suppose there's a scraping interval of 5m)
- alert: AzureNetwork Policy ManagerFailureCreatePolicy
# this expression says to grab the current count minus the count 5 minutes ago, or grab the current count if there was no data 5 minutes ago
expr: (npm_add_policy_exec_time_count{had_error='true'} - (npm_add_policy_exec_time_count{had_error='true'} offset 5m)) or npm_add_policy_exec_time_count{had_error='true'}
labels:
severity: warning
addon: azure-npm
annotations:
summary: "Azure Network Policy Manager failed to handle a policy create event"
description: "Current failure count since Network Policy Manager started: {{ $value }}"
# fire when the median time to apply changes for a pod create event is more than 100 milliseconds.
- alert: AzurenpmHighControllerPodCreateTimeMedian
expr: topk(1, npm_controller_pod_exec_time{operation="create",quantile="0.5",had_error="false"}) > 100.0
labels:
severity: warning
addon: azure-Network Policy Manager
annotations:
summary: "Azure Network Policy Manager controller pod create time median > 100.0 ms"
# could have a simpler description like the one for the alert above,
# but this description includes the number of pod creates that were handled in the past 10 minutes,
# which is the retention period for observations when calculating quantiles for a Prometheus Summary metric
description: "value: [{{ $value }}] and observation count: [{{ printf `(npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} - (npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'} offset 10m)) or npm_controller_pod_exec_time_count{operation='create',pod='%s',had_error='false'}` $labels.pod $labels.pod $labels.pod | query | first | value }}] for pod: [{{ $labels.pod }}]"
Visualisatieopties voor Prometheus
Wanneer u een Prometheus-server gebruikt, wordt alleen het Grafana-dashboard ondersteund.
Als u dat nog niet hebt gedaan, stelt u uw Grafana-server in en configureert u een Prometheus-gegevensbron. Importeer vervolgens ons Grafana-dashboard met een Prometheus-back-end in uw Grafana Labs.
De visuals voor dit dashboard zijn identiek aan het dashboard met een back-end voor containerinzichten/log analytics.
Voorbeelddashboards
Hieronder vindt u een voorbeelddashboard voor metrische gegevens van Network Policy Manager in CONTAINER Insights (CI) en Grafana.
AANTAL CI-samenvattingen
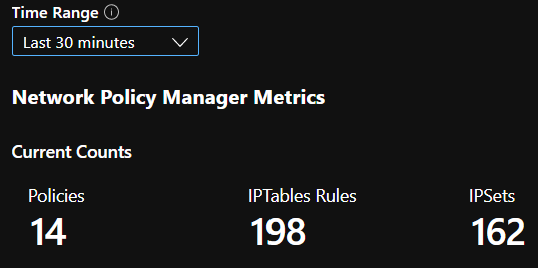
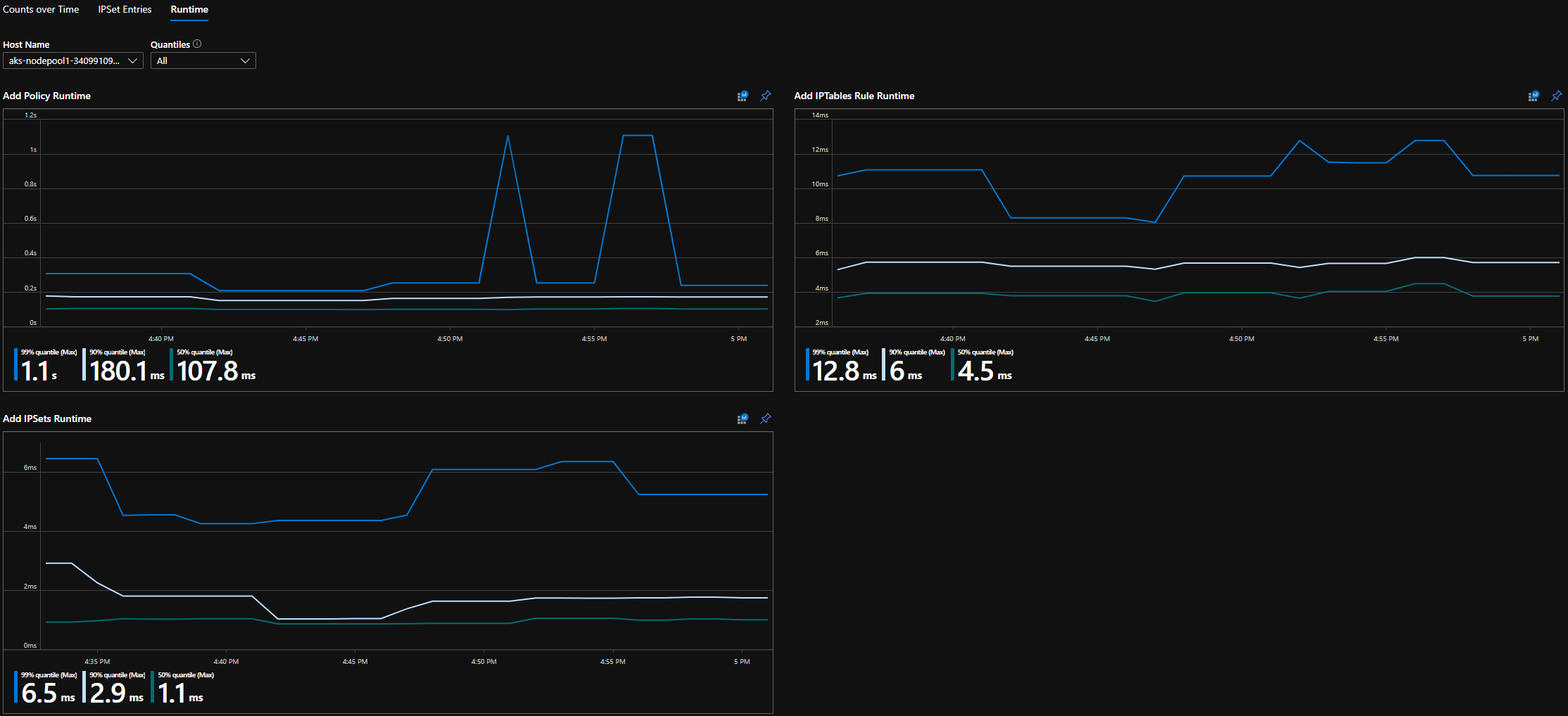
AANTAL CI's in de loop van de tijd

CI IPSet-vermeldingen

CI Runtime-kwantielen
Samenvattingen van Grafana-dashboards
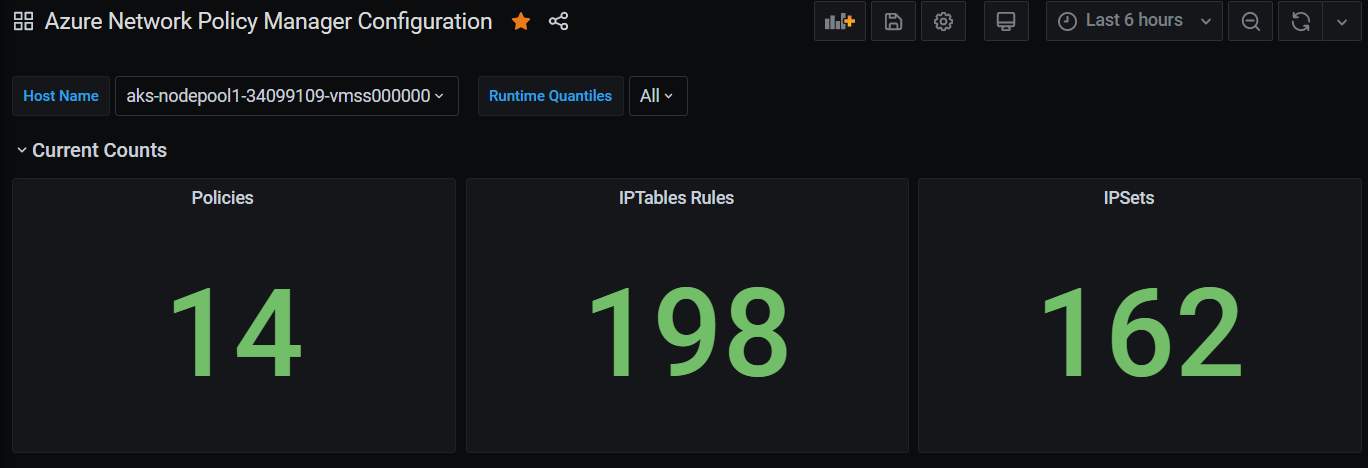
Grafana-dashboard telt in de loop van de tijd

IPSet-vermeldingen voor Grafana-dashboard

Kwantielen van grafana-dashboardruntime

Volgende stappen
Meer informatie over Azure Kubernetes Service.
Meer informatie over containernetwerken.
Implementeer de invoegtoepassing voor Kubernetes-clusters of Docker-containers .