Ophalen van gegevensstroom generatie 1 naar gegevensstroom generatie 2
Gegevensstroom Gen2 is de nieuwe generatie van gegevensstromen. De nieuwe generatie gegevensstromen bevindt zich naast de Power BI-gegevensstroom (Gen1) en biedt nieuwe functies en verbeterde ervaringen. In de volgende sectie vindt u een vergelijking tussen Gegevensstroom Gen1 en Dataflow Gen2.
Overzicht van de functies
| Functie | Gegevensstroom Gen2 | Gegevensstroom Gen1 |
|---|---|---|
| Gegevensstromen ontwerpen met Power Query | ✓ | ✓ |
| Kortere ontwerpstroom | ✓ | |
| Automatisch opslaan en achtergrondpublicatie | ✓ | |
| Gegevensbestemmingen | ✓ | |
| Verbeterde bewakings- en vernieuwingsgeschiedenis | ✓ | |
| Integratie met gegevenspijplijnen | ✓ | |
| Grootschalige rekenkracht | ✓ | |
| Gegevens ophalen via de connector voor gegevensstromen | ✓ | ✓ |
| Directe query via de connector voor gegevensstromen | ✓ | |
| Incrementele vernieuwing | ✓ | |
| ondersteuning voor AI-inzichten | ✓ |
Kortere ontwerpervaring
Werken met Dataflow Gen2 voelt als thuiskomen. We hebben de volledige Power Query-ervaring bewaard die u gewend bent in Power BI-gegevensstromen. Wanneer u de ervaring invoert, wordt u stapsgewijs begeleid bij het ophalen van de gegevens in uw gegevensstroom. We verkorten ook de ontwerpervaring om het aantal benodigde stappen voor het maken van gegevensstromen te verminderen en een aantal nieuwe functies toe te voegen om uw ervaring nog beter te maken.

Nieuwe ervaring voor het opslaan van gegevensstromen
Met Dataflow Gen2 hebben we gewijzigd hoe het opslaan van een gegevensstroom werkt. Wijzigingen in een gegevensstroom worden automatisch opgeslagen in de cloud. U kunt de ontwerpervaring dus op elk gewenst moment afsluiten en doorgaan vanaf waar u op een later tijdstip was gebleven. Zodra u klaar bent met het ontwerpen van uw gegevensstroom, publiceert u uw wijzigingen en worden deze wijzigingen gebruikt wanneer de gegevensstroom wordt vernieuwd. Als u de gegevensstroom publiceert, worden uw wijzigingen opgeslagen en worden validaties uitgevoerd die op de achtergrond moeten worden uitgevoerd. Met deze functie kunt u uw gegevensstroom opslaan zonder dat u hoeft te wachten tot de validatie is voltooid.
Ga naar Een concept van uw gegevensstroom opslaan voor meer informatie over de nieuwe opslagervaring.
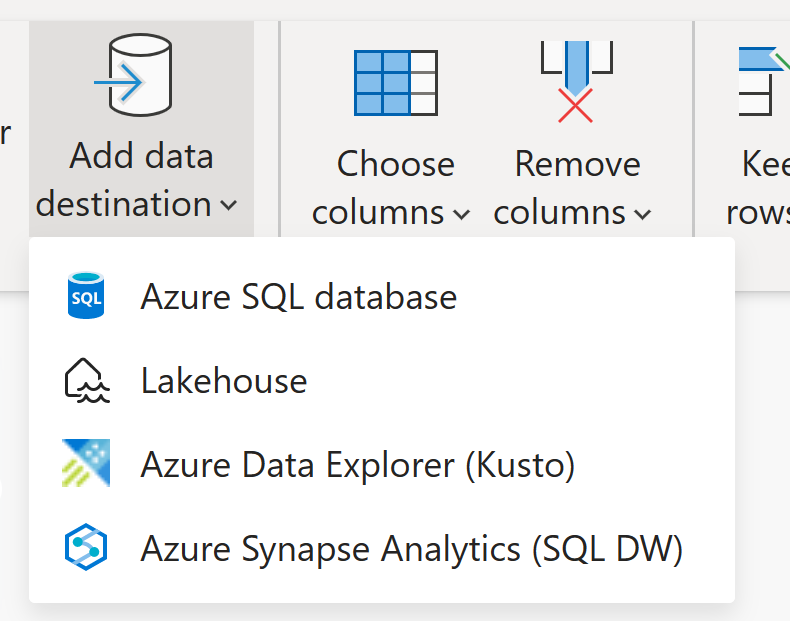
Gegevensbestemmingen
Net als bij Dataflow Gen1 kunt u met Dataflow Gen2 uw gegevens transformeren in de interne/faseringsopslag van de gegevensstroom, waar deze kan worden geopend met behulp van de gegevensstroomconnector. Met Gegevensstroom Gen2 kunt u ook een gegevensbestemming voor uw gegevens opgeven. Met deze functie kunt u nu uw ETL-logica en doelopslag scheiden. Deze functie profiteert op veel manieren van u. U kunt nu bijvoorbeeld een gegevensstroom gebruiken om gegevens in een lakehouse te laden en vervolgens een notebook gebruiken om de gegevens te analyseren. U kunt ook een gegevensstroom gebruiken om gegevens te laden in een Azure SQL-database en vervolgens een gegevenspijplijn gebruiken om de gegevens in een datawarehouse te laden.
In Dataflow Gen2 hebben we ondersteuning toegevoegd voor de volgende bestemmingen en nog veel meer zijn binnenkort beschikbaar:
- Fabric Lakehouse
- Azure Data Explorer (Kusto)
- Azure Synapse Analytics(SQL-DW)
- Azure SQL-database
Notitie
Als u uw gegevens wilt laden in het Fabric Warehouse, kunt u de Azure Synapse Analytics-connector (SQL DW) gebruiken door de SQL-verbindingsreeks op te halen. Meer informatie: Verbinding maken iviteit van datawarehousing in Microsoft Fabric
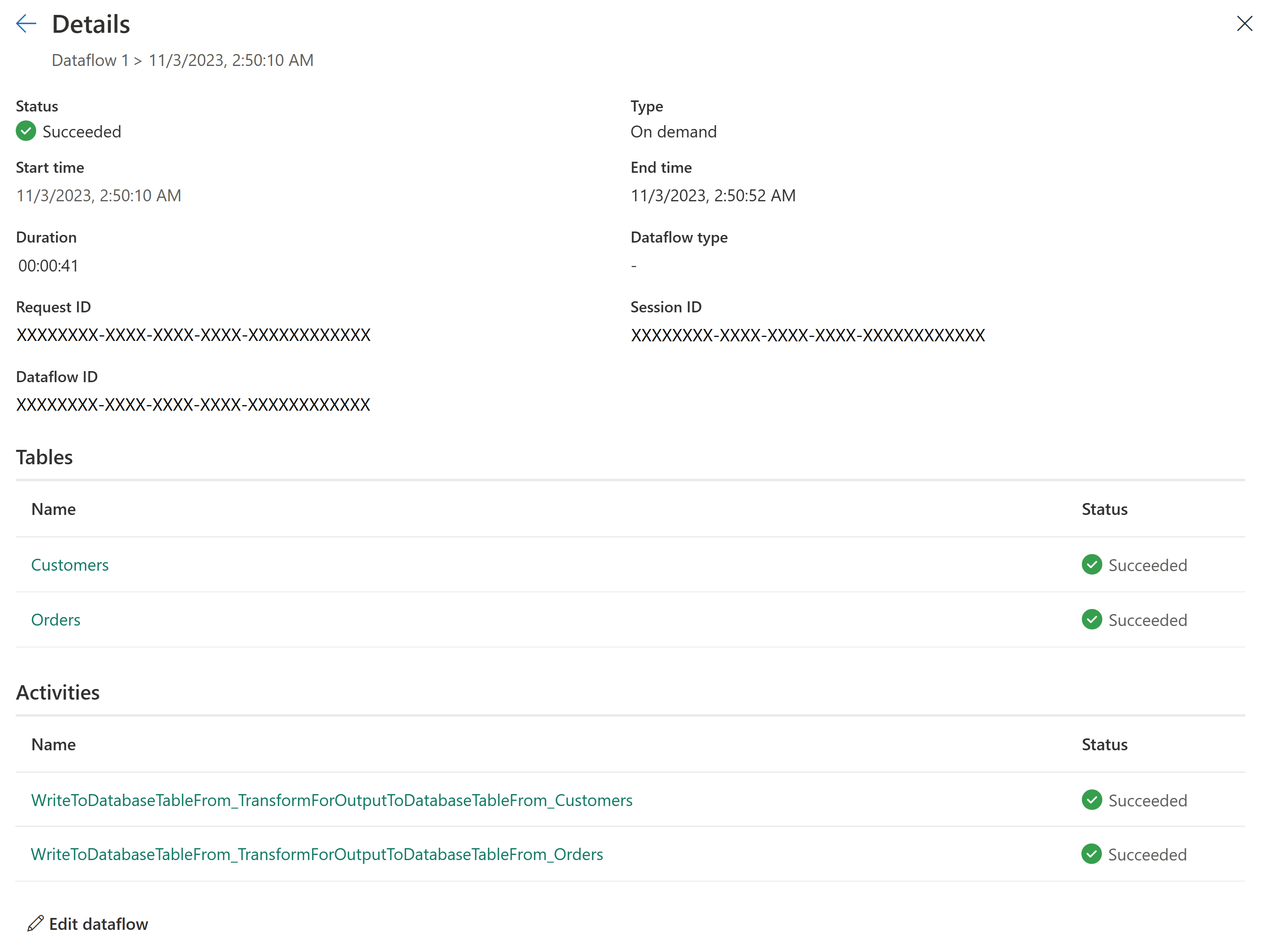
Nieuwe vernieuwingsgeschiedenis en bewaking
Met Dataflow Gen2 introduceren we een nieuwe manier om uw gegevensstroomvernieuwing te bewaken. We integreren ondersteuning voor Monitoring Hub en geven onze vernieuwingsgeschiedenis een belangrijke upgrade.
Integratie met gegevenspijplijnen
Met gegevenspijplijnen kunt u activiteiten groeperen die samen een taak uitvoeren. Een activiteit is een werkeenheid die kan worden uitgevoerd. Een activiteit kan bijvoorbeeld gegevens van de ene locatie naar de andere kopiëren, een SQL-query uitvoeren, een opgeslagen procedure uitvoeren of een Python-notebook uitvoeren.
Een pijplijn kan een of meer activiteiten bevatten die zijn verbonden door afhankelijkheden. U kunt bijvoorbeeld een pijplijn gebruiken om gegevens op te nemen en op te schonen uit een Azure-blob en vervolgens een Dataflow Gen2 starten om de logboekgegevens te analyseren. U kunt ook een pijplijn gebruiken om gegevens van een Azure-blob naar een Azure SQL-database te kopiëren en vervolgens een opgeslagen procedure uit te voeren op de database.
Opslaan als concept
Met Dataflow Gen2 introduceren we een probleemloze ervaring door publicatie te verwijderen om uw wijzigingen op te slaan. Met opslaan als conceptfunctionaliteit slaan we elke keer dat u een wijziging aanbrengt een conceptversie van uw gegevensstroom op. Hebt u de internetverbinding verbroken? Hebt u uw browser per ongeluk gesloten? Geen zorgen; We hebben je rug. Zodra u terugkeert naar uw gegevensstroom, zijn uw recente wijzigingen er nog steeds en kunt u doorgaan waar u was gebleven. Dit is een naadloze ervaring en vereist geen invoer van u. Hierdoor kunt u aan uw gegevensstroom werken zonder dat u zich zorgen hoeft te maken over het verlies van uw wijzigingen of het oplossen van alle queryfouten voordat u uw wijzigingen kunt opslaan. Ga naar Een concept van uw gegevensstroom opslaan voor meer informatie over deze functie.
Rekenkracht op grote schaal
Net als bij Dataflow Gen1 beschikt Dataflow Gen2 ook over een verbeterde berekeningsengine om de prestaties van zowel transformaties van query's waarnaar wordt verwezen te verbeteren als gegevensscenario's op te halen. Hiervoor maakt Dataflow Gen2 zowel Lakehouse- als Warehouse-items in uw werkruimte en gebruikt deze om gegevens op te slaan en te openen om de prestaties voor al uw gegevensstromen te verbeteren.
Licentiegegevensstroom Gen1 versus Gen2
Gegevensstroom Gen2 is de nieuwe generatie gegevensstromen die zich naast de Power BI-gegevensstroom (Gen1) bevinden en nieuwe functies en verbeterde ervaringen biedt. Hiervoor is een Fabric-capaciteit of een Fabric-proefcapaciteit vereist. Lees het volgende artikel voor meer informatie over de werking van licenties voor gegevensstromen: Microsoft Fabric-concepten en -licenties
Dataflow Gen2 uitproberen door uw query's opnieuw te gebruiken vanuit Dataflow Gen1
U hebt waarschijnlijk veel Gegevensstroom Gen1-query's en u vraagt zich af hoe u ze kunt uitproberen in Dataflow Gen2. We hebben een aantal opties om uw Gen1-gegevensstromen opnieuw te maken als Gegevensstroom Gen2.
Exporteer uw Dataflow Gen1-query's en importeer ze in Dataflow Gen2
U kunt nu query's exporteren in zowel de creatie-ervaringen van Dataflow Gen1 als Gen2 en deze opslaan in een PQT-bestand dat u vervolgens kunt importeren in Dataflow Gen2. Ga voor meer informatie naar de functie Exportsjabloon gebruiken.
Kopiëren en plakken in Power Query
Als u een gegevensstroom in Power BI of Power Apps hebt, kunt u uw query's kopiëren en plakken in de editor van uw Dataflow Gen2. Met deze functionaliteit kunt u uw gegevensstroom migreren naar Gen2 zonder dat u uw query's opnieuw hoeft te schrijven. Ga naar Bestaande Gegevensstroom Gen1-query's kopiëren en plakken voor meer informatie.
Gerelateerde inhoud
Feedback
Binnenkort beschikbaar: In de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie voor meer informatie: https://aka.ms/ContentUserFeedback.
Feedback verzenden en weergeven voor