Service voor herstel na noodgeval
Herstel van gegevens waarvan een back-up is gemaakt, is om voor de hand liggende redenen een standaardfunctie van back-upservices. Een noodgeval is echter niet beperkt tot verlies van gegevens. Een onderbreking die verhindert dat de servers, echt of virtueel, of on-premises of in de cloud, van een organisatie beschikbaar zijn, heeft voor de organisatie negatieve, soms zelfs catastrofale, gevolgen. Het doel van een DR-service (Disaster Recovery, herstel na noodgeval) is om een back-up te maken van niet alleen gegevens en afzonderlijke resources, maar van volledige systemen. In het geval dat deze systemen uitvallen of offline gaan, kan service worden hervat door verkeer om te leiden naar replica's die stand-by staan om de belasting over te nemen.
Herstel na noodgevallen is het ware doel van de openbare cloud. Het is meer dan alleen een gigantisch groot tapestation. Aangezien cloudresources virtueel zijn, kunnen replica's heel snel worden geactiveerd om resources te vervangen die plotseling verdwijnen. Replica's kunnen zelfs worden gehost in andere delen van de wereld dan op de systemen waarvan ze een mirror zijn om zo onderbreking in het hele gebied te omzeilen. Als u dit vergelijkt met de kosten van het onderhouden van fysieke replica's van fysieke informatiesystemen (in geografisch verspreide locaties), wordt de waarde van de cloud bij het onderhouden van de continuïteit van deze systemen begint duidelijk.
Toonaangevende cloudproviders bieden Disaster-Recovery-as-a-Service (DRaaS), maar deze services moeten bewust worden gepland en geconfigureerd om de failover-ondersteuning te bieden die klanten wensen. Daarom beginnen we met het onderzoeken van de doelstellingen en metrische gegevens die in een dergelijke planning moeten worden opgenomen.
Doelstellingen en metrische gegevens
Tijdens een noodgeval kunnen een organisatie en haar klanten de toegang tot meerdere klassen digitale activa tegelijk verliezen. De belangrijkste daarvan zijn:
Databases en gegevensarchieven, die naast het vastleggen van belangrijke informatie over klanten en goederen en/of services in de inventaris, de actieve status van zakelijke transacties en processen voor de hele organisatie onderhouden
Bulkgegevens, inclusief documenten, mediabestanden en andere opgeslagen records die de producten zijn van de toepassingen die mensen gebruiken
Communicatie en connectiviteit met mensen en zakelijke services, dus bestaande uit de essentie van elke economische activiteit die kan worden uitgevoerd
Toepassingen die de webwinkels van de organisatie voor klanten en gebruikers vertegenwoordigen, evenals voor hun eigen belanghebbenden
Hoewel DR als één service aan klanten wordt gepresenteerd, is het herstelproces voor elk van deze klassen gescheiden van de andere. In het client/servertijdperk voerden veel organisaties hun dagelijkse werk uit op pc's. Als een pc uitviel en er een back-upinstallatiekopie bestond van de lokale opslag, kon deze in theorie worden hersteld naar een nieuwe pc en kon het werk worden voortgezet. Met de eerste netwerk-pc's die waren gekoppeld met LAN-besturingssystemen en Ethernet-kabels, kon een back-upinstallatiekopie worden teruggezet op elke pc en kon het netwerk zelf worden hervat.
De cloud werkt niet op deze manier. Zelfs een virtuele machine die fungeert als een server voor de toepassingen van een organisatie, kapselt niet al het werk dat het doet volledig in. Back-upservices bieden veiligheidsnetten voor bulkgegevens en, in beperkte mate, transactionele gegevens en databases. Toch zijn elk van deze entiteiten hun eigen component. Dus om de bedrijfsfuncties tijdens een noodgeval te herstellen, moet de meeste, zo niet alle, functionaliteit van al deze onderdelen vanaf een veilige en beveiligde locatie opnieuw worden ingesteld.
Voor het noodherstelproces is daarom coördinatie vereist tussen elk van de procedures die wordt ondernomen om een organisatie weer volledig operationeel te laten zijn. De aard van het werk dat tijdens deze periode wordt uitgevoerd, wordt belangrijker vanwege het bestaan van het noodgeval zelf. Een gebeurtenis die een kritieke infrastructuur kan platleggen, heeft waarschijnlijk ook andere functionele aspecten van het bedrijf beschadigd, zoals opslag, verzending, productie en levering. Het is aannemelijk dat de werking die wordt hersteld geen naadloze hervatting is van de werking zoals het was vóór het noodgeval.
Wat deze procedures bij elkaar brengt, is de aanwezigheid van algemene, duidelijk gedefinieerde serviceniveaudoelstellingen. DR-services van AWS en Azure, en van services van derden die zijn gebouwd op Google Cloud, herkennen het volgende:
Recovery Point Objective (RPO): de minimaal toegestane hoeveelheid gegevens die moet worden teruggestuurd aan clients voor de service op basis van de back-upassets die als hersteld moeten worden beschouwd. Deze hoeveelheid kan daarentegen worden beschouwd als het maximaal acceptabele gegevensverlies, uitgedrukt als een percentage afgetrokken van 100.
Recovery Time Objective (RTO): de maximale tijdspanne waarin een herstelproces moet worden toegepast. Dit kan ook worden gezien als een meting van de hoeveelheid downtime die de organisatie zich wil veroorloven.
Retentieperopde: de maximaal toegestane periode dat een back-upset kan worden bewaard voordat deze moet worden vernieuwd en vervangen.
RTO en RPO kunnen tegen elkaar worden afgewogen, zodat een klant kan besluiten langere hersteltijden toe te staan om hogere herstelpunten te realiseren. Als hersteltijd een probleem is voor een klant vanwege de beschikbare bandbreedte of het risico van downtime, kan de klant mogelijk geen hoge RPO bereiken.
Een professionele risicoadviseur of bedrijfscontinuïteitsadviseur zal er waarschijnlijk op staan dat deze drie variabelen worden gebruikt om een noodherstelbeleid te formuleren. In de meeste BIA-rapporten (Business Impact Analysis) staan RTO en RPO centraal. Dit zijn kritieke variabelen in beoordelingen door adviseurs van mogelijke verliezen die voortvloeien uit noodgevallen. Sommige adviseurs gebruiken een geaggregeerde variabele met de naam serviceniveaudoelstelling (SLO), hoewel er nog geen formule is om SLO te bereiken. De mogelijkheden van CSP's om hun serviceniveaus op te geven met terminologie die risicoadviseurs al erkennen en waarderen, maakt het voor de twee partijen eenvoudiger om samen te werken. Dit is vaak de manier waarop organisaties uiteindelijk een DR-provider kiezen.
Methodologieën en procedures
In de vorige les werd de meest eenvoudige vorm van herstel van informatiesystemen behandeld, waarbij back-ups van relevante bestanden, opslagvolumes en installatiekopieën van virtuele machines zijn betrokken. Hoewel dit nog steeds wordt gepresenteerd als een DR-serviceoptie, is deze in de praktijk van toepassing op steeds minder organisaties, voornamelijk omdat RTO-doelstellingen niet adequaat kunnen worden beheerd.
Professionele DR-services bieden verschillende methodologieën voor implementatie en beheer, waarvan sommige serviceonderhoud vóór een noodgeval betreffen. Deze methodologieën worden hierna samengevat. Ze zijn alle drie gebaseerd op de varianten van de back-upopties die in de vorige les zijn besproken, en ze zijn van toepassing op alle serviceproviders. Een klant die een van deze herstelmodi wil inschakelen, kiest de replicatie-, geolocatie- en opslagklassen die het meest geschikt zijn voor die modus.
Pilot Light
Met deze methodologie (afbeelding 5) bestaat er ruimte voor een volledig stand-by datacentrum. Hier worden bepaalde kernservices en -toepassingen, samen met de gegevens die deze ondersteunen, onderhoudt in een failovercluster dat kan worden 'aangezwengeld' zodra een noodgeval wordt geactiveerd, vaak automatisch. In de tussentijd worden virtuele servers geïmplementeerd met alleen de basisfunctionaliteit die nodig is om ze actief te laten zijn, indien ze ooit nodig zijn. Deze getrapte servers kunnen zijn uitgerust met e-mail- en webfunctionaliteit, waardoor communicatie mogelijk is met klanten en binnen de organisatie zelf. Als u een Pilot Light-herstelmodus inschakelt, moeten vluchtige gegevensarchieven, zoals transactionele databases en e-mailvolumes, mogelijk continu moeten worden gesynchroniseerd.
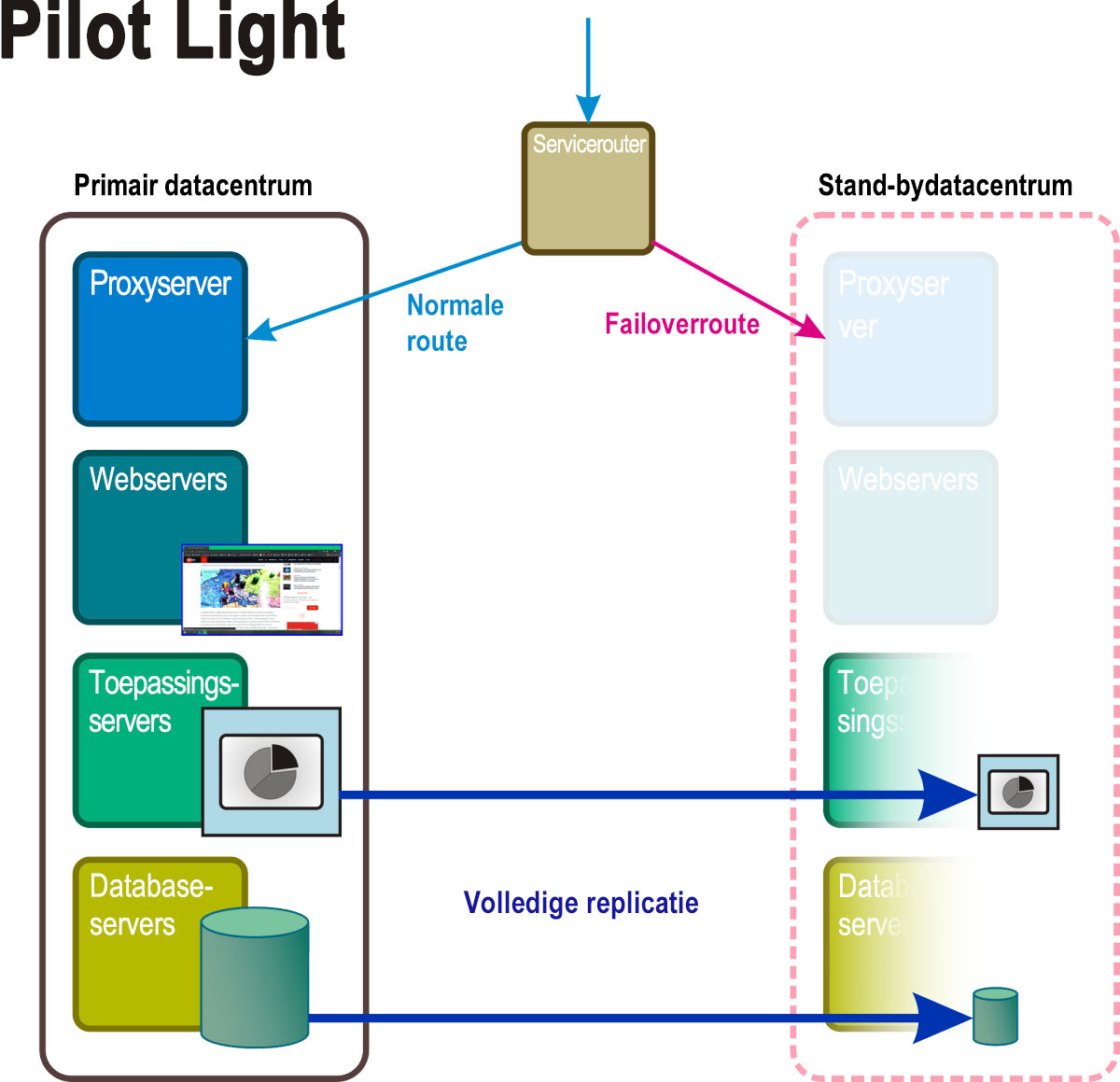
Afbeelding 5: De actieve en passieve onderdelen van een Pilot Light-herstelscenario.
Warme stand-by
In deze herstelmodus, afgebeeld in afbeelding 6, worden continu uitgevoerde replica's van alle systeemservices en toepassingen en alle kritieke bedrijfsgegevens onderhouden op ten minste één afzonderlijke geolocatie. Toegang tot deze volledige replica wordt overgeslagen door de actieve router totdat het noodgeval een regel activeert die het adres van het actieve netwerk vervangt door het adres van de bypass-route.
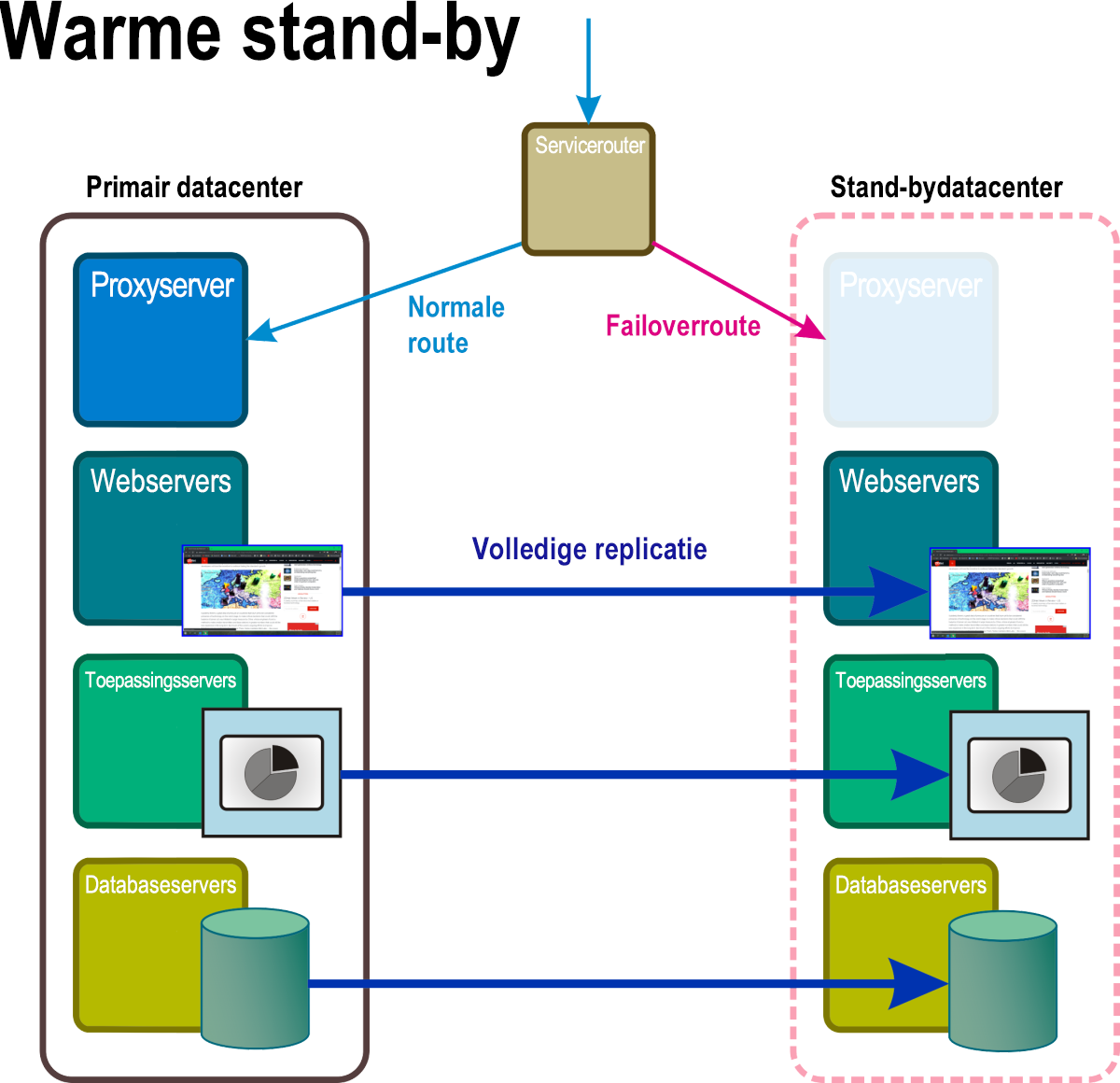
Afbeelding 6: Een warm stand-byherstelscenario met sommige onderdelen in de stand-bynaamruimte volledig operationeel.
Hot stand-by
In dit scenario (afbeelding 7) zijn er altijd ten minste twee volledige replica's van alle services en toepassingen actief, met volledige en continue gegevenssynchronisatie ertussen. Een masterrouter fungeert als een soort voornaamste load balancer en distribueert aanvragen naar alle serverlocaties in ongeveer gelijke verhouding. Door het optreden van een noodgeval wordt een firewall-achtig proces geactiveerd, waarbij het adres van het getroffen systeem wordt verwijderd uit de routeringstabel.
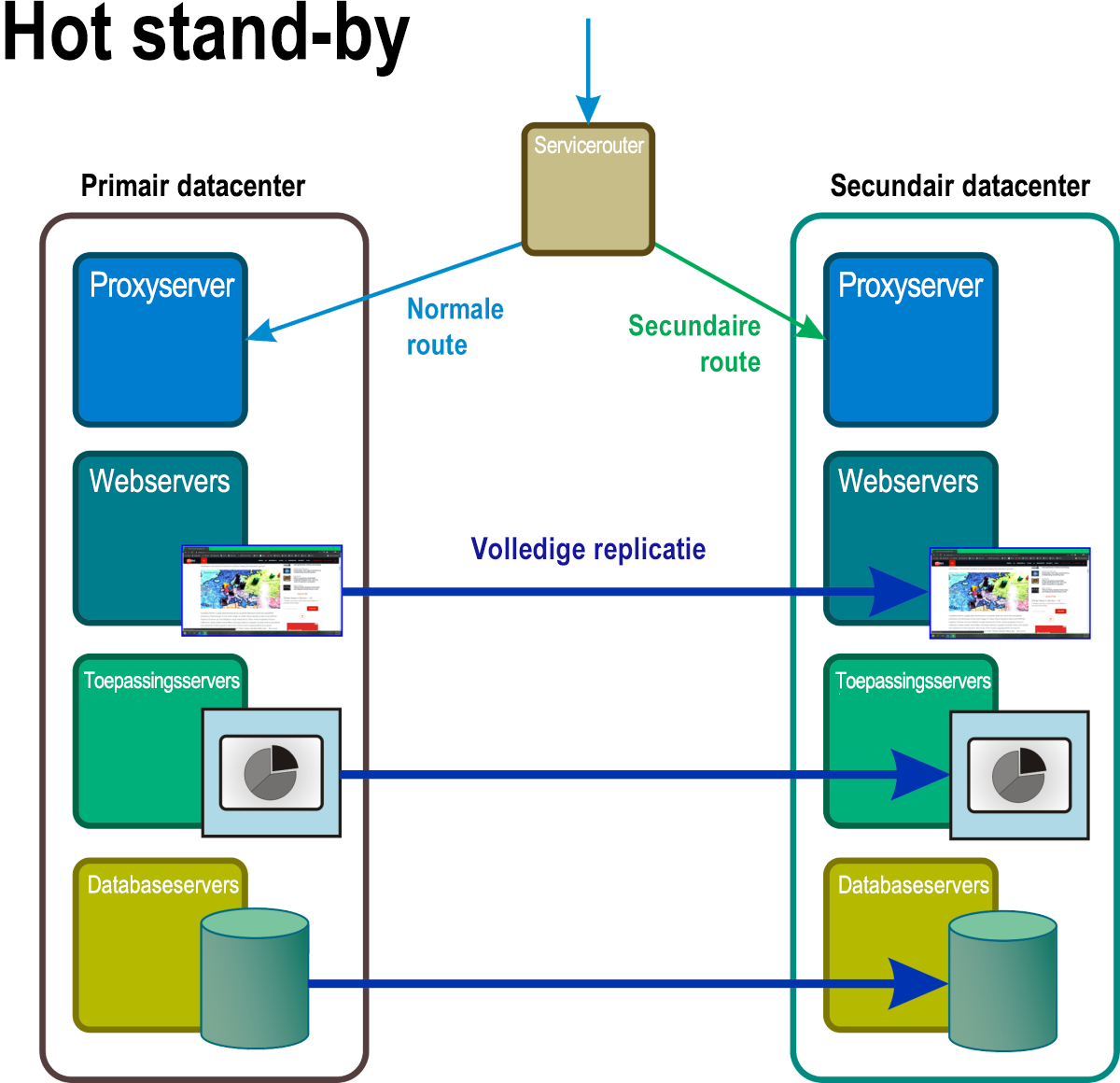
Afbeelding 7: Met hot stand-by zijn alle onderdelen in de naamruimte van wat normaal gesproken de reserve, stand-byruimte, actieve, volledig operationele en verwerkingsreplica's van de primaire gegevens in realtime zijn.
Cloudeigen apps
Het is theoretisch mogelijk dat een organisatie de noodherstelservice van één provider kiest als een veiligheidsnet voor services die worden gehost door een andere provider. Met andere woorden, gezien het juiste aandachtsniveau door IT-medewerkers, kan de infrastructuur van een CSP (bijvoorbeeld die van Google) fungeren als een failover-bestemming voor een warme stand-byprocedure die wordt gehost in de infrastructuur van een andere CSP (zoals Azure). Dit type setup kan noodzakelijk zijn om accountingredenen, of als computingresources binnen een onderneming worden beheerd door afzonderlijke afdelingen in verschillende delen van de wereld.
De aanwezigheid van een containerinfrastructuur in het on-premises datacentrum, en in de cloud, kan een aanzienlijke invloed hebben op al deze DR-methoden. Een zogeheten cloudeigen toepassing, uitsluitend ontwikkeld voor gebruik op een openbaar cloudplatform, of een platform dat precies zo werkt (bijvoorbeeld Microsoft Azure Stack), distribueert functies in meerdere replicacontainers, waarvan een deel of alles tegelijkertijd functioneel kan zijn. De reden is niet zo zeer om een nieuwe klasse DR-scenario mogelijk maken als wel om workloads te distribueren tussen processors.
Een ander aspect van cloudeigen architecturen is de mogelijkheid voor databases waarvan de inhoud al automatisch wordt gerepliceerd om te worden gecontacteerd via een netwerkadres waarvan de toewijzing exclusief is voor de betreffende toepassing. (Met andere woorden, hoewel het internetprotocol wordt gebruikt, is het adres geen locatie op het bredere openbare internet.) Op deze manier, tijdens een noodgeval, terwijl sommige knooppunten die aan de database zijn gekoppeld, mogelijk uitvalt, blijven velen behouden en vinden andere de plaats van de niet-beschikbare knooppunten. Dit wordt mogelijk nog niet gekwalificeerd als ingebouwd herstel na noodgeval, hoewel het zeker kan worden omschreven als bestendigheid tegen noodgevallen.
Disaster-Recovery-as-a-Service (DRaaS)
Voor een openbare cloudserviceprovider is herstel na noodgevallen een manier om de essentiële back-ups en gegevensoverdrachtservices in gebruik te nemen. Elk van de grote CSP's implementeert een andere strategie om DR te faciliteren boven op de back-upservices.
AWS CloudEndure
Servicemigratie heeft betrekking op het verplaatsen van virtuele workloads vanaf een privé, on-premises infrastructuur naar openbare cloudinfrastructuur. Deze overplaatsing is noodzakelijk voor sommige services voor herstel na noodgevallen die in de openbare cloud worden uitgevoerd, om in het geval van een noodgeval hun missiedoelstellingen van failover en herstel binnen een paar minuten te bereiken.
In januari 2019 heeft Amazon de privéservice voor migratie CloudEndure overgenomen, die al AWS als de infrastructuurprovider gebruikte. Sindsdien heeft het CloudEndure geïntegreerd in de belangrijkste servicelijn, waarbij servicemigratie aan klanten van Amazon gratis wordt aangeboden. AWS implementeert nu servicemigratie als een manier om snel een warm of hot stand-byproces in te schakelen. AWS brengt klanten geen kosten in rekening voor het migratieproces, maar wel voor de redundante resources die worden ingericht voor elk DR-scenario. Door het ontbreken van extra kosten is CloudEndure een directe concurrent van een overvloed aan externe DR-services.
Azure Site Recovery
De DR-service van Microsoft, Azure Site Recovery, is een beheerde implementatie van een warme stand-by herstelmethode voor op VM gebaseerde omgevingen en voor fysieke (on-premises) servers waarop Linux of Windows wordt uitgevoerd. VM's worden actief gerepliceerd naar een secundaire regio (afbeelding 9.8), waarnaar een failover kan worden gestart met een eenvoudige klik op de knop. Klanten betalen een maandelijks bedrag (momenteel ongeveer $ 25) voor elke server of VM die wordt beveiligd door Azure Site Recovery.
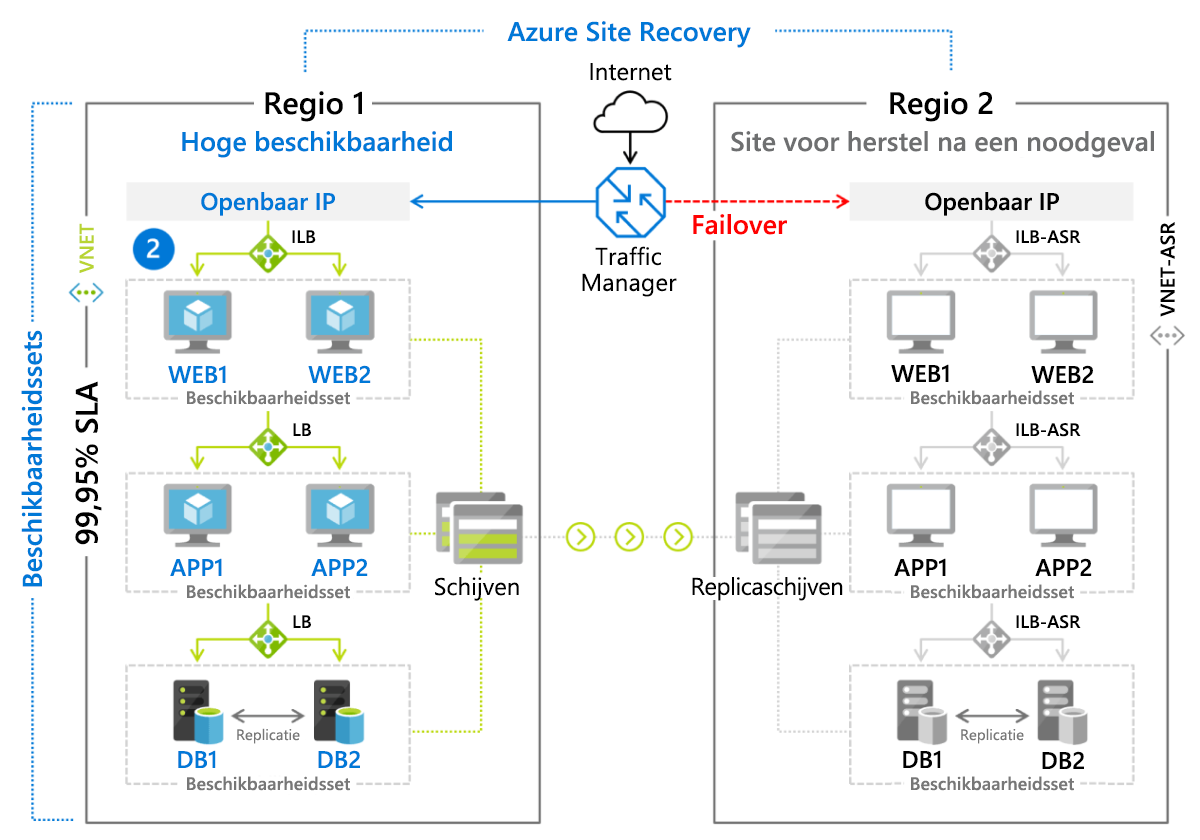
Afbeelding 8: Failoverscenario geïmplementeerd met behulp van Azure Site Recovery.
Google Cloud DR
Net als bij back-up's biedt Google geen eigen service speciaal voor herstel na noodgevallen. In plaats daarvan worden de benodigde hulpprogramma's en bronnen voor gegevensopslag en gegevensoverdracht beschikbaar gesteld, en worden klanten geadviseerd met betrekking tot wat ze het beste kunnen gebruiken voor verschillende DR-scenario's.
Omdat Google Coldline-opslagopties biedt en daar korting op geeft, is GCP van toepassing op een breed scala aan scenario's. Coldline is een aantrekkelijke optie voor organisaties die een grote hoeveelheid bulkgegevens onderhouden. Ronddraaiende magnetische schijven worden onpraktische instrumenten voor mediabestanden waarvan de gemiddelde omvang in de tientallen gigabytes loopt. NAS-onderdelen (Network Attached Storage) bieden een oplossing voor toegankelijkheid en beheerbaarheid voor organisaties die media maken, maar alleen op lokaal niveau. Ze hebben interne redundantie, maar zijn niet noodgevalresistent. En een DR-scenario zoals een van de drie die eerder in een diagram werden afgebeeld, zou niet praktisch (of zelfs niet betaalbaar) zijn voor dergelijke klanten. Coldline presenteert ten minste één uitvoerbare methode voor deze klant om enig nominaal niveau van bedrijfscontinuïteitsgarantie te krijgen.