'Oefening: een gegevensstroom voor toewijzingsgegevens van Azure Data Factory ontwerpen'
Gegevens transformeren met de toewijzings-Gegevensstroom
U kunt systeemeigen gegevenstransformaties uitvoeren met Azure Data Factory-code gratis met behulp van de toewijzing Gegevensstroom taak. Toewijzingen Gegevensstroom bieden een volledig visuele ervaring zonder dat codering is vereist. Uw gegevensstromen worden uitgevoerd op uw eigen uitvoeringscluster voor uitgeschaalde gegevensverwerking. Activiteiten voor gegevensstromen kunnen worden ge operationeel via bestaande data factory-plannings-, controle-, stroom- en bewakingsmogelijkheden.
Wanneer u gegevensstromen bouwt, kunt u de foutopsporingsmodus inschakelen, waardoor een klein interactief Spark-cluster wordt ingeschakeld. Schakel de foutopsporingsmodus in door de schuifregelaar boven aan de ontwerpmodule in te schakelen. Het kan enkele minuten duren voordat foutopsporingsclusters zijn opgewarmd, maar kan worden gebruikt om interactief een voorbeeld te bekijken van de uitvoer van uw transformatielogica.

Wanneer de toewijzing Gegevensstroom toegevoegd en het Spark-cluster wordt uitgevoerd, kunt u hiermee de transformatie uitvoeren en de gegevens uitvoeren en bekijken. Er is geen codering vereist omdat Azure Data Factory alle codeomzetting, padoptimalisatie en uitvoering van uw gegevensstroomtaken afhandelt.
Brongegevens toevoegen aan de toewijzings-Gegevensstroom
Open het canvas toewijzing Gegevensstroom. Klik op de knop Bron toevoegen in het Gegevensstroom canvas. Selecteer uw gegevensbron in de vervolgkeuzelijst voor de brongegevensset. In dit geval wordt de ADLS Gen2-gegevensset in dit voorbeeld gebruikt
Er zijn enkele punten die u moet noteren:
- Als uw gegevensset verwijst naar een map met andere bestanden en u slechts één bestand wilt gebruiken, moet u mogelijk een andere gegevensset maken of parameterisatie gebruiken om ervoor te zorgen dat alleen een specifiek bestand wordt gelezen
- Als u uw schema niet in uw ADLS hebt geïmporteerd, maar uw gegevens al hebt opgenomen, gaat u naar het tabblad Schema van de gegevensset en klikt u op Schema importeren, zodat uw gegevensstroom de schemaprojectie kent.
Toewijzing Gegevensstroom volgt een ELT-benadering (extract, load, transform) en werkt met faseringsgegevenssets die zich allemaal in Azure bevinden. Momenteel kunnen de volgende gegevenssets worden gebruikt in een brontransformatie:
- Azure Blob Storage (JSON, Avro, Text, Parquet)
- Azure Data Lake Storage Gen1 (JSON, Avro, Text, Parquet)
- Azure Data Lake Storage Gen2 (JSON, Avro, Text, Parquet)
- Azure Synapse Analytics
- Azure SQL Database
- Azure Cosmos DB
Azure Data Factory heeft toegang tot meer dan 80 systeemeigen connectors. Als u gegevens uit die andere bronnen in uw gegevensstroom wilt opnemen, gebruikt u de kopieeractiviteit om die gegevens te laden in een van de ondersteunde faseringsgebieden.
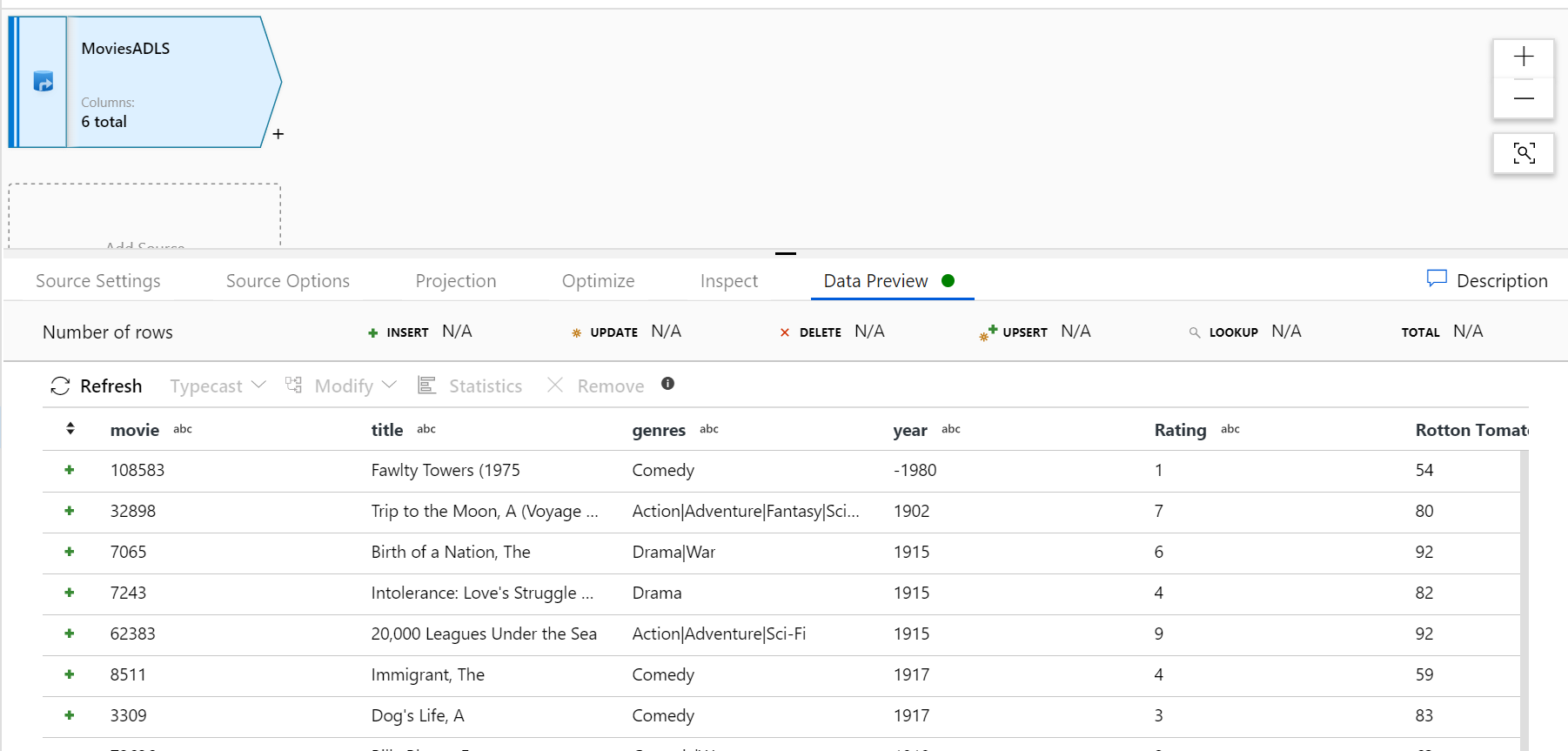
Zodra uw foutopsporingscluster is opgewarmd, controleert u of uw gegevens correct zijn geladen via het tabblad Gegevensvoorbeeld. Zodra u op de knop Vernieuwen klikt, wordt Gegevensstroom een momentopname weergegeven van hoe uw gegevens eruit zien wanneer deze zich bij elke transformatie bevindt.
Transformaties gebruiken in de toewijzings-Gegevensstroom
Nu u de gegevens naar Azure Data Lake Store Gen2 hebt verplaatst, bent u klaar om een toewijzings-Gegevensstroom te bouwen waarmee uw gegevens op schaal worden getransformeerd via een spark-cluster en deze vervolgens in een datawarehouse laden.
De belangrijkste taken hiervoor zijn als volgt:
De omgeving voorbereiden
Een gegevensbron toevoegen
Toewijzing Gegevensstroom transformatie gebruiken
Schrijven naar een gegevenssink
Taak 1: De omgeving voorbereiden
Schakel Gegevensstroom Foutopsporing in: schakel de schuifregelaar voor Gegevensstroom foutopsporing boven aan de ontwerpmodule in.
Notitie
Gegevensstroom clusters duren 5-7 minuten om op te warmen.
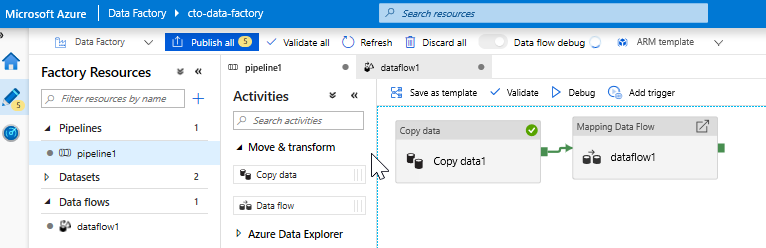
Voeg een Gegevensstroom activiteit toe. Open in het deelvenster Activiteiten de accordeon Verplaatsen en transformeren en sleep de Gegevensstroom-activiteit naar het pijplijncanvas. Klik op de blade die wordt weergegeven op Nieuwe Gegevensstroom maken en selecteer Gegevensstroom toewijzen en klik vervolgens op OK. Klik op het tabblad Pijplijn1 en sleep het groene vak van uw Copy-activiteit naar de Gegevensstroom-activiteit om een geslaagde voorwaarde te maken. U ziet het volgende op het canvas:
Taak 2: Een gegevensbron toevoegen
Voeg een ADLS-bron toe. Dubbelklik op het object Toewijzing Gegevensstroom op het canvas. Klik op de knop Bron toevoegen in het Gegevensstroom canvas. Selecteer in de vervolgkeuzelijst Brongegevensset uw ADLSG2-gegevensset die wordt gebruikt in uw Copy-activiteit
- Als uw gegevensset verwijst naar een map met andere bestanden, moet u mogelijk een andere gegevensset maken of parameterisatie gebruiken om ervoor te zorgen dat alleen het bestand moviesDB.csv wordt gelezen
- Als u uw schema niet in uw ADLS hebt geïmporteerd, maar uw gegevens al hebt opgenomen, gaat u naar het tabblad Schema van de gegevensset en klikt u op Schema importeren, zodat uw gegevensstroom de schemaprojectie kent.
Zodra uw foutopsporingscluster is opgewarmd, controleert u of uw gegevens correct zijn geladen via het tabblad Gegevensvoorbeeld. Zodra u op de knop Vernieuwen klikt, wordt Gegevensstroom een momentopname weergegeven van hoe uw gegevens eruit zien wanneer deze zich bij elke transformatie bevindt.
Taak 3: Toewijzing Gegevensstroom transformatie gebruiken
Voeg een transformatie selecteren toe om de naam van een kolom te wijzigen en neer te zetten. In de preview van de gegevens hebt u misschien gemerkt dat de kolom 'Rotton Tomatoes' onjuist is gespeld. Als u deze de juiste naam wilt geven en de kolom Ongebruikte classificatie wilt verwijderen, kunt u een transformatie Selecteren toevoegen door op het pluspictogram naast het ADLS-bronknooppunt te klikken en Selecteren onder Schema-modifier te kiezen.
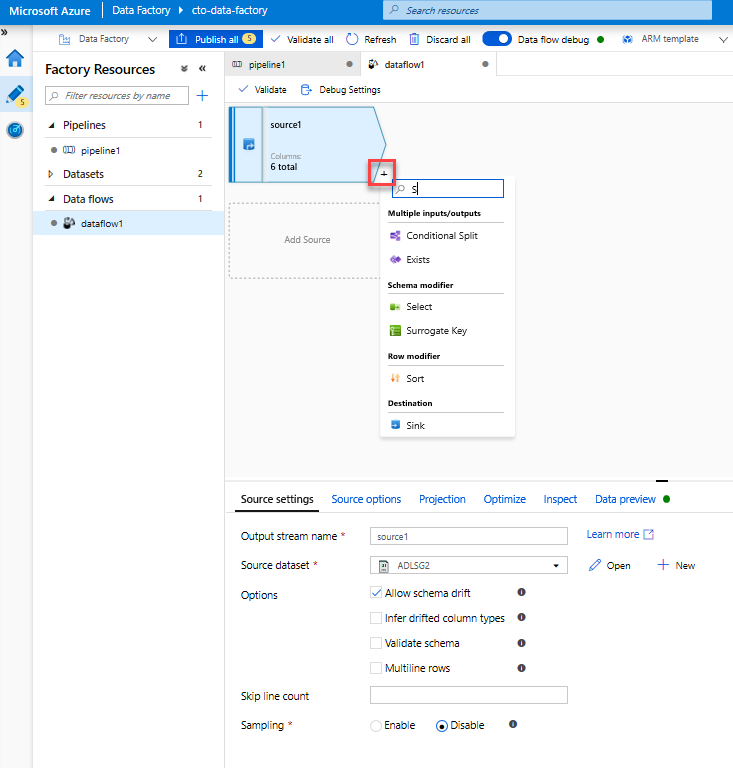
Wijzig in het veld Naam als 'Rotton' in 'Rotten'. Als u de kolom Classificatie wilt verwijderen, plaatst u de muisaanwijzer erop en klikt u op het prullenbakpictogram.
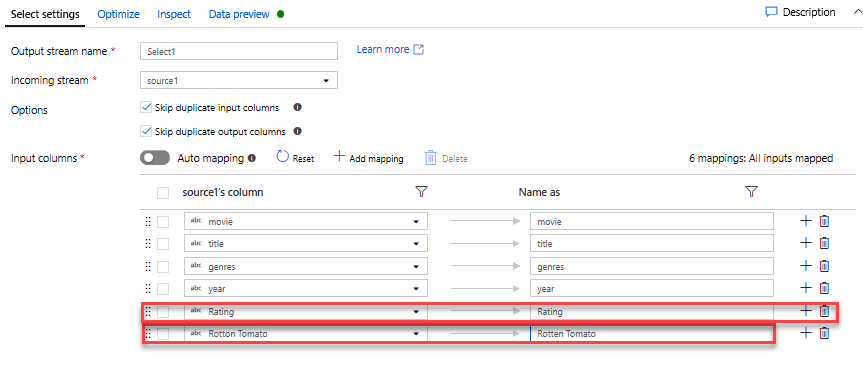
Voeg een filtertransformatie toe om ongewenste jaren uit te filteren. Stel dat u alleen geïnteresseerd bent in films die na 1951 zijn gemaakt. U kunt een filtertransformatie toevoegen om een filtervoorwaarde op te geven door op het +-pictogram naast de transformatie Selecteren te klikken en Filter te kiezen onder Rijaanpassing. Klik op het expressievak om de opbouwfunctie voor expressies te openen en voer de filtervoorwaarde in. Met behulp van de syntaxis van de expressietaal Toewijzing Gegevensstroom converteert toInteger(year) > 1950 de waarde van het tekenreeksjaar naar een geheel getal en filtert u rijen als deze waarde hoger is dan 1950.
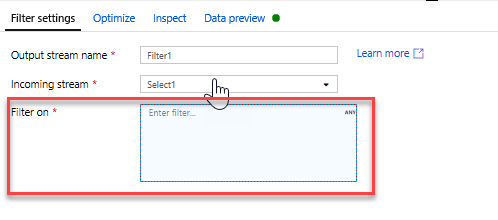
U kunt het ingesloten deelvenster Gegevensvoorbeeld van de opbouwfunctie voor expressies gebruiken om te controleren of uw voorwaarde goed werkt
Voeg een afgeleide transformatie toe om het primaire genre te berekenen. Zoals u misschien hebt opgemerkt, is de kolom genres een tekenreeks die wordt gescheiden door een |-teken. Als u alleen om het eerste genre in elke kolom geeft, kunt u een nieuwe kolom met de naam PrimaryGenre afleiden via de transformatie Afgeleide kolom door te klikken op het pictogram + naast de filtertransformatie en afgeleide te kiezen onder Schema Modifier. Net als bij de filtertransformatie maakt de afgeleide kolom gebruik van de opbouwfunctie voor toewijzingen Gegevensstroom expressies om de waarden van de nieuwe kolom op te geven.

In dit scenario probeert u het eerste genre op te halen uit de kolom genres, die is opgemaakt als 'genre1|genre2|...|genreN'. Gebruik de zoekfunctie om de eerste op 1 gebaseerde index van de | op te halen in de genresreeks. Als deze index groter is dan 1, kan het primaire genre worden berekend met behulp van de functie iif, die alle tekens in een tekenreeks links van een index retourneert. Anders is de waarde PrimaryGenre gelijk aan het genreveld. U kunt de uitvoer controleren via het deelvenster Gegevensvoorbeeld van de opbouwfunctie voor expressies.
Rangschik films via een venstertransformatie. Stel dat u geïnteresseerd bent in de positie van een film binnen het jaar voor het specifieke genre. U kunt een venstertransformatie toevoegen om aggregaties op basis van vensters te definiëren door te klikken op het pictogram + naast de transformatie van de afgeleide kolom en te klikken op Venster onder Schemaaanpassing. Hiertoe geeft u op waarop u venstert, waarop u sorteert, wat u wilt sorteren, wat het bereik is en hoe u de nieuwe vensterkolommen berekent. In dit voorbeeld gaan we vensters uitvoeren op PrimaryGenre en jaar met een niet-gebonden bereik, sorteren op Rotten Tomato aflopend en een nieuwe kolom met de naam RatingsRank berekenen die gelijk is aan de positie die elke film binnen het specifieke genrejaar heeft.

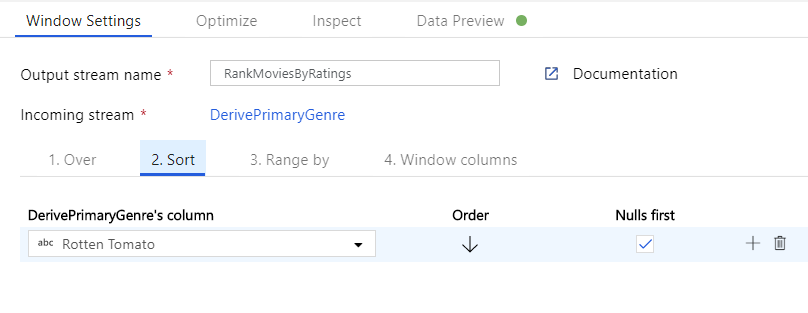
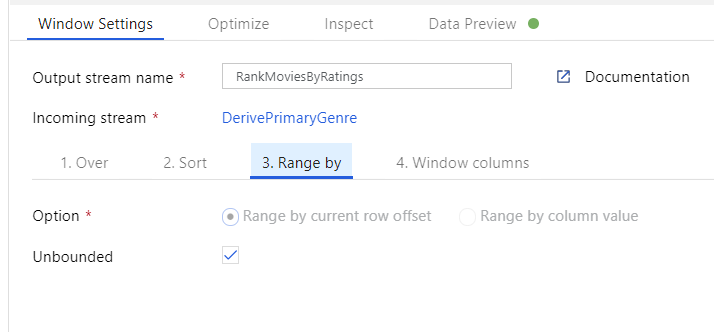
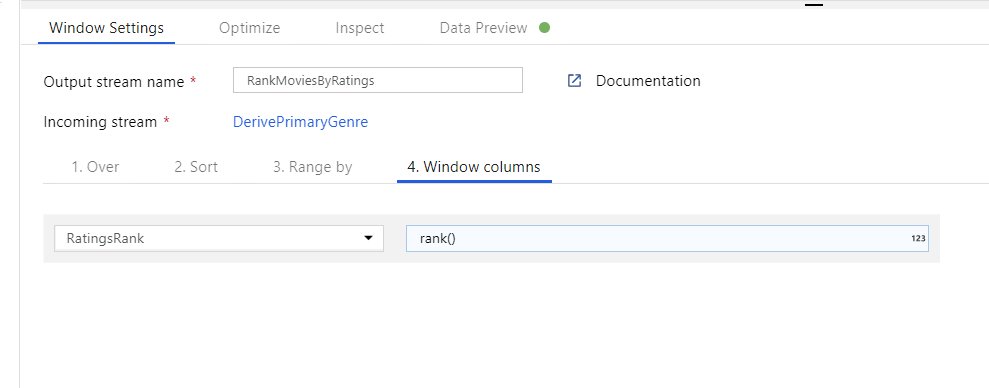
Classificaties aggregeren met een statistische transformatie. Nu u al uw vereiste gegevens hebt verzameld en afgeleid, kunnen we een statistische transformatie toevoegen om metrische gegevens te berekenen op basis van een gewenste groep door te klikken op het pictogram + naast de venstertransformatie en te klikken op Aggregeren onder Schemaaanpassing. Zoals u hebt gedaan in de venstertransformatie, kunt u films groeperen op PrimaryGenre en jaar
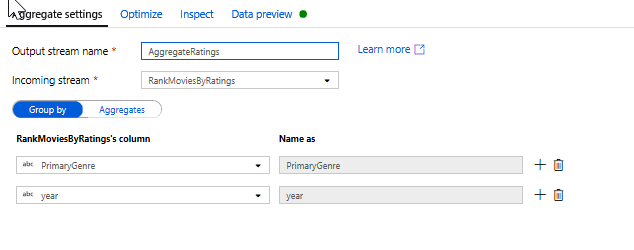
Op het tabblad Aggregaties kunt u aggregaties maken die worden berekend over de opgegeven groep op kolommen. Voor elk genre en jaar kunnen we de gemiddelde Rotten Tomatoes-classificatie krijgen, de hoogste en laagste beoordeelde film (met behulp van de vensterfunctie) en het aantal films dat zich in elke groep bevindt. Aggregatie vermindert het aantal rijen in uw transformatiestroom aanzienlijk en doorgeeft alleen de groep op en aggregatiekolommen die zijn opgegeven in de transformatie.
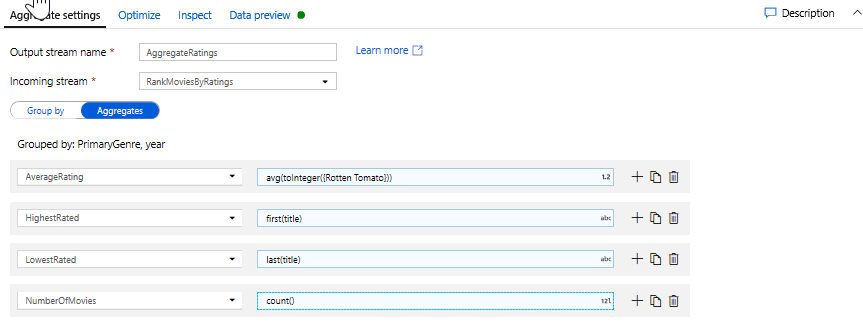
- Als u wilt zien hoe de samengevoegde transformatie uw gegevens wijzigt, gebruikt u het tabblad Gegevensvoorbeeld
Geef de upsert-voorwaarde op via een wijzigingsrijtransformatie. Als u naar een sink in tabelvorm schrijft, kunt u beleidsregels voor invoegen, verwijderen, bijwerken en upsert opgeven voor rijen met behulp van de transformatie Rij wijzigen door te klikken op het pictogram + naast de statistische transformatie en te klikken op Rij wijzigen onder rijaanpassing. Omdat u altijd invoegt en bijwerkt, kunt u opgeven dat alle rijen altijd worden geupert.

Taak 4: Schrijven naar een gegevenssink
- Schrijf naar een Azure Synapse Analytics-sink. Nu u al uw transformatielogica hebt voltooid, bent u klaar om naar een sink te schrijven.
Voeg een sink toe door te klikken op het +-pictogram naast uw Upsert-transformatie en op Sink onder Bestemming te klikken.
Maak op het tabblad Sink een nieuwe datawarehouse-gegevensset via de knop + Nieuw.
Selecteer Azure Synapse Analytics in de tegellijst.
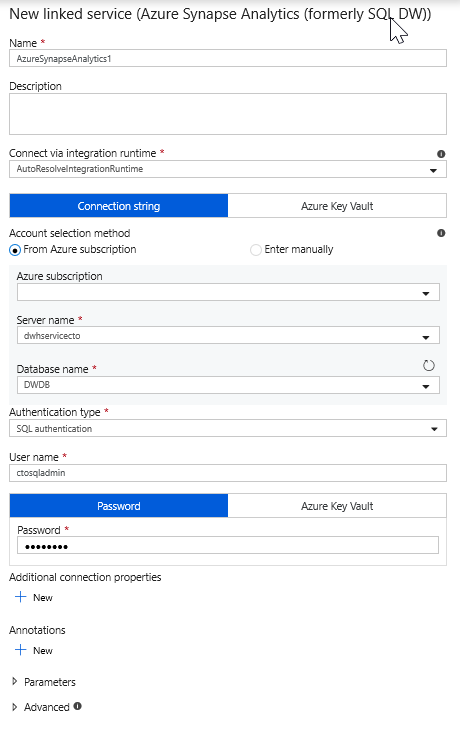
Selecteer een nieuwe gekoppelde service en configureer uw Azure Synapse Analytics-verbinding om verbinding te maken met de DWDB-database. Klik op Maken als u klaar bent.
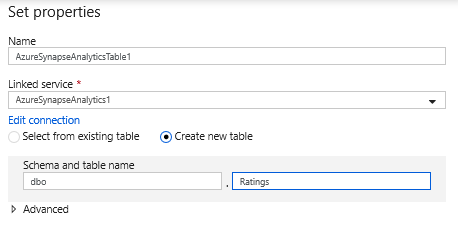
Selecteer in de configuratie van de gegevensset nieuwe tabel maken en voer het schema van Dbo en de tabelnaam classificaties in. Klik op OK zodra dit is voltooid.
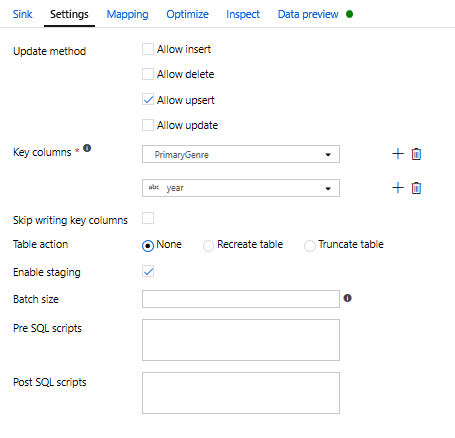
Omdat een upsert-voorwaarde is opgegeven, moet u naar het tabblad Instellingen gaan en upsert toestaan selecteren op basis van sleutelkolommen PrimaryGenre en year.
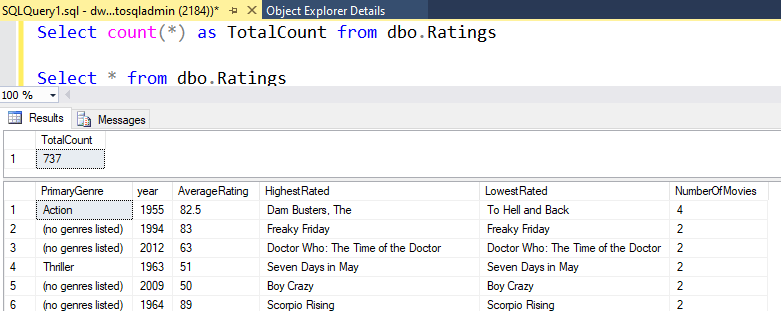
Op dit moment hebt u klaar met het bouwen van de toewijzing van 8 transformaties Gegevensstroom. Het is tijd om de pijplijn uit te voeren en de resultaten te bekijken.

Taak 5: De pijplijn uitvoeren
Ga naar het tabblad Pijplijn1 op het canvas. Omdat Azure Synapse Analytics in Gegevensstroom Gebruikmaakt van PolyBase, moet u een blob- of ADLS-faseringsmap opgeven. Open op het tabblad Instellingen van execute Gegevensstroom-activiteit de PolyBase-accordion en selecteer uw gekoppelde ADLS-service en geef een pad naar de faseringsmap op.
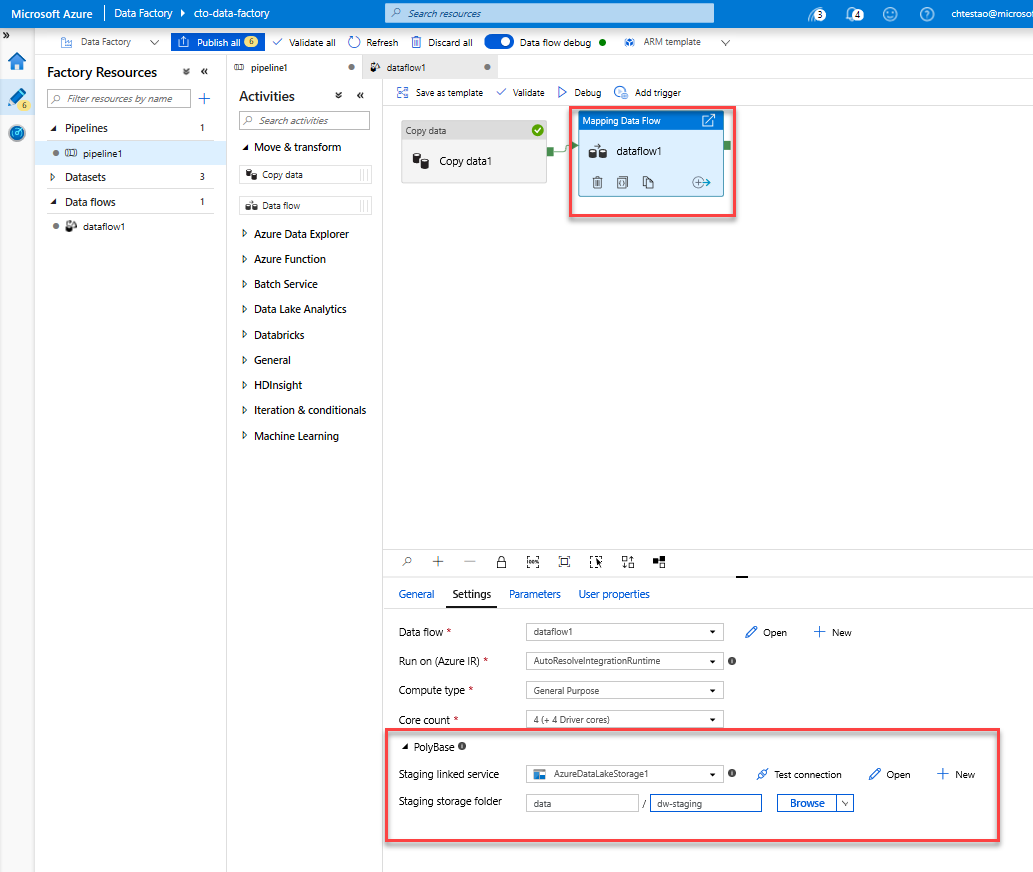
Voordat u uw pijplijn publiceert, voert u een andere foutopsporingsuitvoering uit om te bevestigen dat deze werkt zoals verwacht. Als u naar het tabblad Uitvoer kijkt, kunt u de status van beide activiteiten controleren terwijl ze worden uitgevoerd.
Zodra beide activiteiten zijn voltooid, kunt u op het brilpictogram naast de Gegevensstroom activiteit klikken om een uitgebreider overzicht te krijgen van de Gegevensstroom uitvoering.
Als u dezelfde logica hebt gebruikt die in dit lab wordt beschreven, schrijft uw Gegevensstroom 737 rijen naar uw SQL DW. U kunt naar SQL Server Management Studio gaan om te controleren of de pijplijn correct heeft gewerkt en kunt zien wat er is geschreven.