Oefening: het machine learning-model visualiseren
Een van de voordelen van het gebruik van een beslissingsstructuurclassificatie is de visualisatie die u kunt gebruiken om beter te begrijpen hoe het model beslissingen neemt. Met graphviz en pydotplus kunt u snel zien hoe een beslissing wordt genomen. In toekomstige herhalingen kunt u zien hoe beslissingen worden gewijzigd.
De visuele structuur maken
Om een visuele voorstelling van het model te maken, maakt u een functie die de volgende parameters gebruikt:
- Gegevens:
tree, het machine learning-model - Kolommen:
feature_names, een lijst met de kolommen in de invoergegevens - Uitvoer:
class_nameseen lijst met de opties voor classificatie (in dit geval 'yes' of 'no') - Bestandsnaam:
png_file_to_savede naam van het bestand waarin u de visualisatie wilt opslaan
U roept de functie export_graphviz()van scikit-learn aan en retourneert dan een afbeeldingsweergave van het diagram dat scikit-learn bevat.
# Let's import a library for visualizing our decision tree.
from sklearn.tree import export_graphviz
def tree_graph_to_png(tree, feature_names,class_names, png_file_to_save):
tree_str = export_graphviz(tree, feature_names=feature_names, class_names=class_names,
filled=True, out_file=None)
graph = pydotplus.graph_from_dot_data(tree_str)
return Image(graph.create_png())
Het aanroepen van deze functie is vrij eenvoudig:
- Gegevens:
tree_model, het model dat u eerder hebt getraind en getest - Kolommen:
X.columns.valuesde lijst van kolommen in de invoer - Uitvoer: [
yes,no], de twee mogelijke resultaten - Bestandsnaam:
decision_tree.pngde naam van het bestand waarin u de afbeelding wilt opslaan
# This function takes a machine learning model and visualizes it.
tree_graph_to_png(tree=tree_model, feature_names=X.columns.values,class_names=['No Launch','Launch'], png_file_to_save='decision-tree.png')
Deze functie maakt de volgende afbeelding.
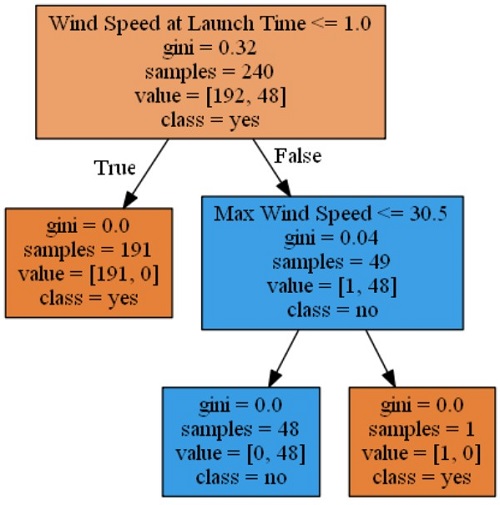
In totaal hebben we 240 monsters als we naar de gegevensset kijken:
- 192 ervan zijn lanceringen die niet door zijn gegaan
- 48 ervan zijn lanceringen
Dit resultaat is te wijten aan onze strategie voor het opschonen van gegevens, waarbij we ervan uitgingen dat alle niet-gelabelde dagen geen lanceringsdagen zijn.
Met behulp van de nieuwe labels kunnen we zeggen: "Als de windsnelheid minder dan 1,0 was, dan 191 van de 240 monsters vermoedden dat er op die dag geen lancering mogelijk was." Dit resultaat lijkt misschien vreemd, maar op basis van de gegevens is het juist. Hier volgt het bewijs: We hebben de lancering getekend versus de distributie zonder lancering voor dagen dat de windsnelheid op launch Time <= 1 voordat we de kolom eerder in dit notebook neerhalen. Het laat zien dat we voor vrijwel alle tijden niet starten:
Meer informatie over de visualisatie
Deze eenvoudige structuur toont dat de belangrijkste functie van de gegevens Wind Speed at Launch Time is. Als de windsnelheid minder dan 1,0 was, werd er in 191 van de 240 monsters goed geraden dat er geen lancering was. We zien dat 191 van die monsters alleen nodig hadden dat de waarde van Wind Speed at Launch Time minder was dan 1,0 om het juiste resultaat te raden, terwijl er boven 1,0 meer informatie nodig is.
Dit inzicht is niet goed. We hebben eerder alle waarden die leeg waren op 0 gezet. We weten ook dat veel van de waarden met betrekking tot de tijd van de lancering 0 waren, omdat 60% van onze gegevens niet was gerelateerd aan een daadwerkelijke lancering of poging daartoe.
Als u naar de structuur kijkt, dan kunt u zien dat Max Wind Speed de volgende meest belangrijke functie van de gegevens is. Hier ziet u dat van de resterende 49 dagen, wanneer de maximale windsnelheid lager was dan 30,5, 48 dagen een juiste lanceringsuitvoer oplevert en één een uitvoer zonder lancering heeft opgeleverd.
Deze gegevens zijn mogelijk interessanter met context uit de praktijk. Er was maar één dag dat er een lancering was gepland en de waarde Max Wind Speed groter was dan 30, 5, namelijk 27 mei 2020. De lancering van de Space X Dragon is toen uitgesteld tot 30 mei 2020. Hier is het bewijs:
launch_data[(launch_data['Wind Speed at Launch Time'] > 1) & (launch_data['Max Wind Speed'] > 30.5)]

De resultaten verbeteren
Met deze visualisatie kunt u zien dat bepaalde functies belangrijk werden. Maar deze nadruk is gebaseerd op onjuiste informatie.
Eén verbetering die kan worden aangebracht is om de relatie tussen Max Wind Speed en Wind Speed at Launch Time vast te stellen voor de rijen die die informatie bevatten. Vervolgens had, in plaats van Wind Speed at Launch Time op 0 in te stellen voor dagen dat er geen lancering was, het de schatting gemaakt kunnen worden van wat het zou zijn bij een gewone lanceertijd. Deze wijziging geeft mogelijk de gegevens beter weer.
Kunt u andere manieren bedenken om de gegevens te verbeteren?