Oefening: gegevens opschonen en voorbereiden
Voordat u een gegevensset kunt voorbereiden, is het belangrijk dat u de inhoud en structuur ervan begrijpt. In het vorige lab hebt u een set gegevens over de tijdige aankomst van vluchten voor een grote Amerikaanse luchtvaartmaatschappij geïmporteerd. Deze gegevens bevatten 26 kolommen en duizenden rijen, waarbij elke rij één vlucht voorstelt en informatie bevat zoals de herkomst, de bestemming en de geplande vertrektijd van de vlucht. U hebt de gegevens ook in een Jupyter-notebook geladen en een eenvoudig Python-script gebruikt om er een Pandas DataFrame van te maken.
Een Dataframe is een tweedimensionale gelabelde gegevensstructuur. De kolommen in een DataFrame kunnen van verschillende typen zijn, net als kolommen in een spreadsheet of databasetabel. Het is het meest gebruikte object in Pandas. In deze oefening gaat u het DataFrame en de hierin opgenomen gegevens nauwkeuriger bekijken.
Ga terug naar het Azure-notebook dat u in de vorige sectie hebt gemaakt. Als u het notitieblok hebt gesloten, kunt u zich weer aanmelden bij de Microsoft Azure Notebooks-portal, uw notitieblok openen en de Cel ->Alles uitvoeren gebruiken om alle cellen in het notebook opnieuw uit te voeren nadat u het hebt geopend.
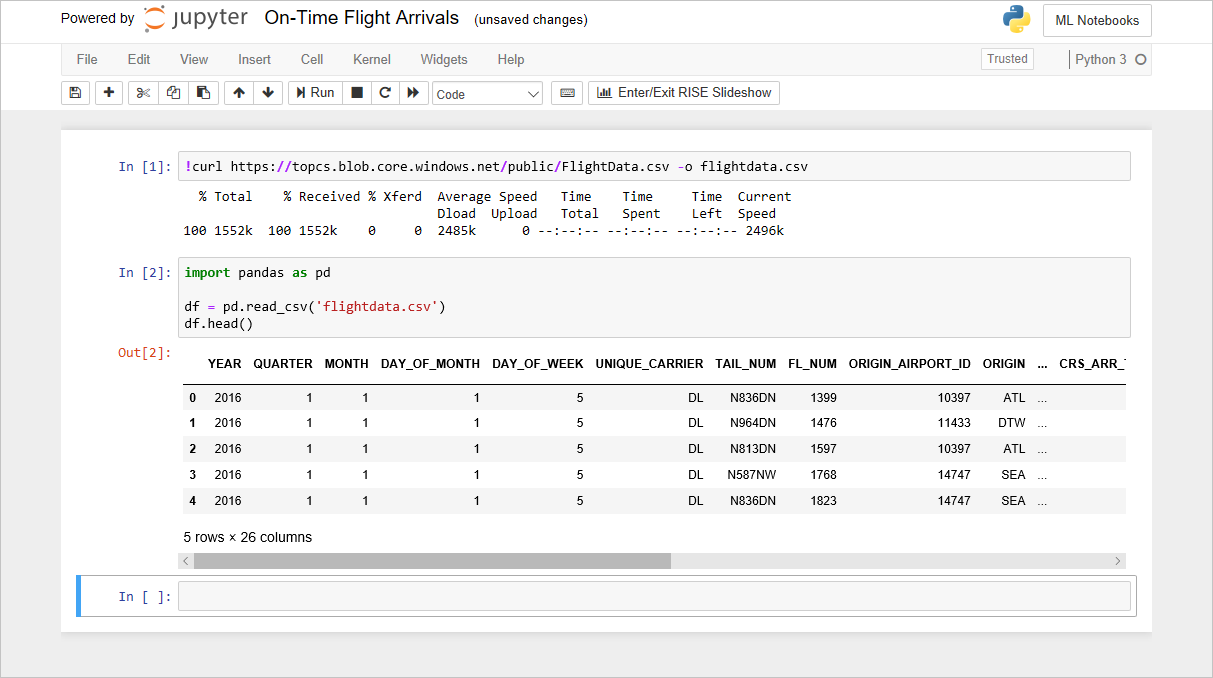
Het notebook FlightData
Met de code die u in het vorige lab aan het notebook hebt toegevoegd, wordt een DataFrame gemaakt van flightdata.csv en wordt DataFrame.head aangeroepen om de eerste vijf rijen weer te geven. Een van de eerste dingen die u gewoonlijk wilt weten over een gegevensset, is hoeveel rijen deze bevat. U haalt het aantal op door de volgende instructie in een lege cel aan het einde van het notebook te typen en uit te voeren:
df.shapeControleer of het DataFrame 11.231 rijen en 26 kolommen bevat:

Het aantal rijen en kolommen ophalen
Neem nu even de tijd om de 26 kolommen in de gegevensset te bekijken. Ze bevatten belangrijke informatie, zoals de datum waarop de vlucht heeft plaatsgevonden (YEAR, MONTH en DAY_OF_MONTH), de herkomst en bestemming (ORIGIN en DEST), de geplande vertrek- en aankomsttijd (CRS_DEP_TIME en CRS_ARR_TIME), het verschil tussen de geplande aankomsttijd en de werkelijke aankomsttijd in minuten (ARR_DELAY), en of de vlucht 15 minuten of meer vertraagd was (ARR_DEL15).
Hier volgt een volledige lijst van de kolommen in de gegevensset. Tijden worden uitgedrukt in 24 uursnotatie. 1130 is bijvoorbeeld gelijk aan 11:30 uur en 1500 is gelijk aan 13:00 uur.
Kolom Beschrijving YEAR Het jaar waarin de vlucht heeft plaatsgevonden QUARTER Het kwartaal waarin de vlucht heeft plaatsgevonden (1-4) MONTH De maand waarin de vlucht heeft plaatsgevonden (1-12) DAY_OF_MONTH De dag van de maand waarop de vlucht heeft plaatsgevonden (1-31) DAY_OF_WEEK De dag van de week waarop de vlucht heeft plaatsgevonden (1 = maandag, 2 = dinsdag, enzovoort) UNIQUE_CARRIER De code van de luchtvaartmaatschappij (bijvoorbeeld DL) TAIL_NUM Het staartnummer van het vliegtuig FL_NUM Het vluchtnummer ORIGIN_AIRPORT_ID De id van de luchthaven van herkomst ORIGIN De code van de luchthaven van herkomst (ATL, DFW, SEA enzovoort) DEST_AIRPORT_ID De id van de bestemmingsluchthaven DEST De code van de bestemmingsluchthaven (ATL, DFW, SEA enzovoort.) CRS_DEP_TIME De geplande vertrektijd DEP_TIME De werkelijke vertrektijd DEP_DELAY Het aantal minuten dat het vertrek was vertraagd DEP_DEL15 0 = Het vertrek was minder dan 15 minuten vertraagd, 1 = Het vertrek was 15 minuten of meer vertraagd CRS_ARR_TIME De geplande aankomsttijd ARR_TIME De werkelijke aankomsttijd ARR_DELAY Het aantal minuten dat de vlucht te laat is aangekomen ARR_DEL15 0 = De aankomst was minder dan 15 minuten te laat, 1 = De aankomst was 15 minuten of meer te laat CANCELLED 0 = De vlucht is niet geannuleerd, 1 = De vlucht is geannuleerd DIVERTED 0 = De vlucht is niet omgeleid, 1 = De vlucht is omgeleid CRS_ELAPSED_TIME De geplande vluchttijd in minuten ACTUAL_ELAPSED_TIME De werkelijke vluchttijd in minuten DISTANCE De afgelegde afstand in mijlen
De gegevensset bevat een vrijwel gelijkmatige verdeling van datums in het jaar, wat belangrijk is omdat een vlucht uit Minneapolis in juli minder kans heeft op vertraging door een winterstorm dan in januari. Deze gegevensset is echter verre van opgeschoond en klaar voor gebruik. Laten we Pandas-code schrijven om de gegevensset op te schonen.
Een van de belangrijkste aspecten van het voorbereiden van een gegevensset voor machine learning is om de juiste functiekolommen te selecteren die relevant zijn voor de resultaten die u probeert te voorspellen. Tegelijkertijd kan het uitfilteren van kolommen die geen invloed hebben op de resultaten, negatieve gevolgen hebben of leiden tot multicollineariteit. Een andere belangrijke taak is het elimineren van ontbrekende waarden, door rijen of kolommen die ze bevatten te verwijderen of door deze ontbrekende waarden te vervangen door zinvolle waarden. In deze oefening gaat u overbodige kolommen verwijderen en ontbrekende waarden in de resterende kolommen vervangen.
Een van de eerste dingen waar gegevenswetenschappers gewoonlijk naar zoeken in een gegevensset, zijn ontbrekende waarden. In Pandas kunt u eenvoudig ontbrekende waarden vinden. Voer bijvoorbeeld de volgende code uit in een cel aan het einde van het notebook:
df.isnull().values.any()Controleer of de uitvoer 'True' is, wat aangeeft dat er ergens in de gegevensset ten minste één waarde ontbreekt.

Controleren op ontbrekende waarden
De volgende stap is om erachter te komen waar de ontbrekende waarden zich bevinden. Voer hiertoe de volgende code uit:
df.isnull().sum()Controleer of u de volgende uitvoer krijgt met het aantal ontbrekende waarden in elke kolom:

Het aantal ontbrekende waarden in elke kolom
Nieuwsgierig bevat de 26e kolom ('Naamloos: 25') 11.231 ontbrekende waarden, die gelijk zijn aan het aantal rijen in de gegevensset. Deze kolom is per ongeluk gemaakt omdat het CSV-bestand dat u hebt geïmporteerd, een komma aan het einde van elke regel bevat. U verwijdert die kolom door de volgende code aan het notebook toe te voegen en uit te voeren:
df = df.drop('Unnamed: 25', axis=1) df.isnull().sum()Bekijk de uitvoer en controleer of kolom 26 is verdwenen uit het DataFrame:

Het DataFrame waaruit kolom 26 is verwijderd
Het DataFrame bevat nog steeds een groot aantal ontbrekende waarden, maar sommige ervan zijn niet nuttig omdat de kolommen waarin ze zitten niet relevant zijn voor het model dat u wilt maken. Het doel van dit model is om te voorspellen of de kans groot is dat de vlucht die u overweegt te boeken op tijd aankomt. Als u weet dat de kans op vertraging groot is, kunt u een andere vlucht boeken.
De volgende stap is daarom om de gegevensset te filteren om kolommen te verwijderen die niet relevant zijn voor een voorspellend model. Zo heeft het staartnummer van het vliegtuig waarschijnlijk weinig invloed op de aankomsttijd, en kunt u op de tijd waarop u een ticket boekt onmogelijk weten of een vlucht wordt geannuleerd, wordt omgeleid of vertraging krijgt. De geplande vertrektijd kan daarentegen veel invloed hebben op een tijdige aankomst. Vanwege het hub- en spoke-systeem dat bij de meeste luchtvaartmaatschappijen wordt gebruikt, zijn ochtendvluchten vaker op tijd dan middag- of avondvluchten. En op sommige grote luchthavens hoopt het verkeer zich in de loop van de dag op, waardoor de kans groter is dat latere vluchten vertraagd zijn.
In Pandas zijn ongewenste kolommen eenvoudig uit te filteren. Voer de volgende code uit in een cel aan het einde van het notebook:
df = df[["MONTH", "DAY_OF_MONTH", "DAY_OF_WEEK", "ORIGIN", "DEST", "CRS_DEP_TIME", "ARR_DEL15"]] df.isnull().sum()In de uitvoer ziet u dat het DataFrame nu alleen nog de kolommen bevat die relevant zijn voor het model en dat het aantal ontbrekende waarden aanzienlijk is beperkt:

Het gefilterde DataFrame
De enige kolom die nog ontbrekende waarden bevat, is de kolom ARR_DEL15, waarin nullen staan voor vluchten die op tijd aankwamen en enen voor vertraagde vluchten. Gebruik de volgende code om de eerste vijf rijen met ontbrekende waarden weer te geven:
df[df.isnull().values.any(axis=1)].head()In Pandas worden ontbrekende waarden weergegeven als
NaN, dat staat voor Not a Number (geen getal). In de uitvoer ziet u dat er in de kolom ARR_DEL15 van deze rijen inderdaad waarden ontbreken:
Rijen met ontbrekende waarden
De reden dat deze rijen geen ARR_DEL15-waarden bevatten is dat het vluchten betreft die zijn geannuleerd of omgeleid. U kunt dropna op het DataFrame aanroepen om deze rijen te verwijderen. Maar omdat een vlucht die is geannuleerd of omgeleid naar een andere luchthaven kan worden beschouwd als 'te laat', gebruiken we de methode fillna om de ontbrekende waarden te vervangen door enen.
Gebruik de volgende code om ontbrekende waarden in de kolom ARR_DEL15 te vervangen door enen en de rijen 177 tot 184 weer te geven:
df = df.fillna({'ARR_DEL15': 1}) df.iloc[177:185]Controleer of de
NaN-waarden in de rijen 177, 179 en 184 zijn vervangen door enen, waarmee wordt aangegeven dat de vluchten te laat zijn aangekomen:
NaN-waarden vervangen door 1's
De gegevensset is nu opgeschoond in die zin dat ontbrekende waarden zijn vervangen en de lijst met kolommen is beperkt tot de relevantste voor het model. Maar u bent nog niet klaar. Er is nog meer te doen om de gegevensset voor te bereiden op gebruik voor machine learning.
De kolom CRS_DEP_TIME van de gegevensset die u gebruikt, bevat de geplande vertrektijden. De granulariteit van de getallen in deze kolom, die meer dan 500 unieke waarden bevat, kan een negatieve invloed hebben op de nauwkeurigheid in een Machine Learning-model. Dit probleem kan worden opgelost met de techniek binning ofwel kwantisatie. Wat gebeurt er als u elk getal in deze kolom deelt door 100 en naar beneden afrondt op het dichtstbijzijnde gehele getal? 1030 zou dan 10 worden, 1925 zou 19 worden, enzovoort, en u zou maximaal 24 unieke waarden overhouden in deze kolom. Intuïtief, het is logisch, want het maakt waarschijnlijk niet veel uit of een vlucht om 10:30 uur of 10:40 uur vertrekt. Het maakt veel uit of het om 10:30 uur of om 17:30 uur vertrekt.
Daarnaast bevatten de kolommen ORIGIN en DEST van de gegevensset luchthavencodes die categorische machine learning-waarden vertegenwoordigen. Deze kolommen moeten worden geconverteerd naar verschillende kolommen met indicatorvariabelen, ook wel dummyvariabelen genoemd. Met andere woorden: de kolom ORIGIN, die vijf luchthavencodes bevat, moet worden geconverteerd naar vijf kolommen, een per luchthaven, waarbij elke kolom enen en nullen bevat om aan te geven of een vlucht wel of niet afkomstig is van de luchthaven waar die kolom voor staat. De kolom DEST moet op dezelfde manier worden verwerkt.
In deze oefening gaat u binning uitvoeren voor de vertrektijden in de kolom CRS_DEP_TIME en gaat u via de Pandas-methode get_dummies indicatorkolommen maken van de kolommen ORIGIN en DEST.
Gebruik de volgende opdracht om de eerste vijf rijen van het DataFrame weer te geven:
df.head()Zoals u ziet, bevat de kolom CRS_DEP_TIME waarden van 0 tot 2359 voor de 24 uursklok.

Het DataFrame met vertrektijden waarvoor nog geen binning is uitgevoerd
Gebruik de volgende instructies om binning uit te voeren voor de vertrektijden:
import math for index, row in df.iterrows(): df.loc[index, 'CRS_DEP_TIME'] = math.floor(row['CRS_DEP_TIME'] / 100) df.head()Controleer of de getallen in de kolom CRS_DEP_TIME nu binnen het bereik 0 tot 23 vallen:

Het DataFrame met vertrektijden waarvoor binning is uitgevoerd
Gebruik nu de volgende instructies om indicatorkolommen te maken van de kolommen ORIGIN en DEST, waarbij u de kolommen ORIGIN en DEST zelf laat vervallen:
df = pd.get_dummies(df, columns=['ORIGIN', 'DEST']) df.head()Bekijk het resulterende DataFrame en controleer of de kolommen ORIGIN en DEST zijn vervangen door kolommen die overeenkomen met de luchthavencodes uit de oorspronkelijke kolommen. De nieuwe kolommen bevatten enen en nullen om aan te geven of de herkomst of bestemming van de vlucht oorspronkelijk wel of niet bedoeld was voor de overeenkomstige luchthaven.

Het DataFrame met indicatorkolommen
Gebruik de opdracht Bestand ->Opslaan en Controlepunt om het notitieblok op te slaan.
De gegevensset ziet er heel anders uit dan aan het begin, maar is nu geoptimaliseerd voor machine learning.