AI met gegevensstromen
In dit artikel wordt beschreven hoe u kunstmatige intelligentie (AI) kunt gebruiken met gegevensstromen. In dit artikel wordt het volgende beschreven:
- Cognitive Services
- Geautomatiseerde machine learning
- Azure Machine Learning-integratie
Cognitive Services in Power BI
Met Cognitive Services in Power BI kunt u verschillende algoritmen van Azure Cognitive Services toepassen om uw gegevens te verrijken in de selfservice voor gegevensvoorbereiding voor gegevensstromen.
De services die momenteel worden ondersteund, zijn sentimentanalyse, sleuteltermextractie, taaldetectie en afbeeldingstags. De transformaties worden uitgevoerd op de Power BI-service en vereisen geen Azure Cognitive Services-abonnement. Voor deze functie is Power BI Premium vereist.
AI-functies inschakelen
Cognitive Services worden ondersteund voor Premium-capaciteitsknooppunten EM2, A2 of P1 en andere knooppunten met meer resources. Cognitive Services zijn ook beschikbaar met een PPU-licentie (Premium Per User). Er wordt een afzonderlijke AI-workload voor de capaciteit gebruikt om cognitieve services uit te voeren. Voordat u cognitive services in Power BI gebruikt, moet de AI-workload zijn ingeschakeld in de capaciteitsinstellingen van de Beheer-portal. U kunt de AI-workload inschakelen in de sectie Workloads en de maximale hoeveelheid geheugen definiëren die u wilt gebruiken voor deze workload. De aanbevolen geheugenlimiet is 20%. Als u deze limiet overschrijdt, wordt de query vertraagd.

Aan de slag met Cognitive Services in Power BI
Cognitive Services-transformaties maken deel uit van de selfservice voor gegevensvoorbereiding voor gegevensstromen. Als u uw gegevens wilt verrijken met Cognitive Services, begint u met het bewerken van een gegevensstroom.

Selecteer de knop AI-inzichten op het bovenste lint van de Power Query-editor.

Selecteer in het pop-upvenster de functie die u wilt gebruiken en de gegevens die u wilt transformeren. In dit voorbeeld wordt het gevoel beoordeeld van een kolom die beoordelingstekst bevat.

LanguageISOCode is een optionele invoer om de taal van de tekst op te geven. In deze kolom wordt een ISO-code verwacht. U kunt een kolom gebruiken als invoer voor LanguageISOCode of u kunt een statische kolom gebruiken. In dit voorbeeld wordt de taal opgegeven als Engels (en) voor de hele kolom. Als u deze kolom leeg laat, detecteert Power BI automatisch de taal voordat u de functie toepast. Selecteer vervolgens Aanroepen.

Nadat u de functie hebt aangeroepen, wordt het resultaat toegevoegd als een nieuwe kolom aan de tabel. De transformatie wordt ook toegevoegd als een toegepaste stap in de query.

Als de functie meerdere uitvoerkolommen retourneert, wordt met het aanroepen van de functie een nieuwe kolom met een rij van de meerdere uitvoerkolommen toegevoegd.
Gebruik de optie uitvouwen om een of beide waarden als kolommen aan uw gegevens toe te voegen.

Beschikbare functies
In deze sectie worden de beschikbare functies in Cognitive Services in Power BI beschreven.
Taal detecteren
De functie taaldetectie evalueert tekstinvoer en retourneert voor elke kolom de taalnaam en ISO-id. Deze functie is handig voor gegevenskolommen die willekeurige tekst verzamelen, waarbij de taal onbekend is. De functie verwacht gegevens in tekstindeling als invoer.
Text Analytics herkent maximaal 120 talen. Zie Wat is taaldetectie in Azure Cognitive Service for Language voor meer informatie.
Sleuteltermen extraheren
De functie Sleuteltermextractie evalueert ongestructureerde tekst en retourneert voor elke tekstkolom een lijst met sleuteltermen. De functie vereist een tekstkolom als invoer en accepteert een optionele invoer voor LanguageISOCode. Zie aan de slag voor meer informatie.
Sleuteltermextractie werkt het beste wanneer u het grotere stukken tekst geeft om aan te werken, tegenovergestelde van sentimentanalyse. Sentimentanalyse presteert beter op kleinere tekstblokken. Overweeg dienovereenkomstig herstructurering van de invoer voor de beste resultaten uit beide bewerkingen.
Gevoel scoren
De functie Gevoel beoordelen evalueert tekstinvoer en retourneert een gevoelsscore voor elk document, variërend van 0 (negatief) tot 1 (positief). Deze functie is handig voor het detecteren van positieve en negatieve gevoelens in sociale media, klantbeoordelingen en discussieforums.
Text Analytics maakt gebruik van een machine learning-classificatiealgoritme voor het genereren van een gevoelsscore tussen 0 en 1. Scores dichter bij 1 wijzen op een positief gevoel. Scores dichter bij 0 geven een negatief gevoel aan. Het model is vooraf getraind met een uitgebreide hoofdtekst met sentimentkoppelingen. Op dit moment is het niet mogelijk om uw eigen trainingsgegevens op te geven. Het model gebruikt een combinatie van technieken tijdens de tekstanalyse, met inbegrip van de verwerking van tekst, analyse van woordsoorten, woordplaatsing en woordkoppelingen. Zie Machine Learning en Text Analytics voor meer informatie over het algoritme.
Sentimentanalyse wordt uitgevoerd op de hele invoerkolom, in tegenstelling tot het extraheren van sentiment voor een bepaalde tabel in de tekst. In de praktijk is er een tendens om de nauwkeurigheid van scores te verbeteren wanneer documenten een of twee zinnen bevatten in plaats van een groot tekstblok. Tijdens een objectiviteitsevaluatiefase bepaalt het model of een invoerkolom als geheel objectief is of sentiment bevat. Een invoerkolom die voornamelijk objectief is, leidt niet tot de gevoelsdetectiezin, wat resulteert in een score van 0,50, zonder verdere verwerking. Voor invoerkolommen die in de pijplijn worden voortgezet, genereert de volgende fase een score die groter of kleiner is dan 0,50, afhankelijk van de mate van gevoel dat in de invoerkolom is gedetecteerd.
Op dit moment ondersteunt Sentimentanalyse Engels, Duits, Spaans en Frans. Andere talen bevinden zich in preview-fase. Zie Wat is taaldetectie in Azure Cognitive Service for Language voor meer informatie.
Afbeeldingen taggen
De functie Tag Images retourneert tags op basis van meer dan 2000 herkenbare objecten, levende wezens, landschappen en acties. Wanneer tags ambigu of niet algemeen bekend zijn, biedt de uitvoer hints om de betekenis van de tag in de context van een bekende instelling te verduidelijken. Tags zijn niet geordend als taxonomie en er bestaan geen overnamehiërarchieën. Een verzameling inhoudstags vormt de basis voor een 'beschrijving van de afbeelding, weergegeven als voor mensen leesbare taal opgemaakt in volledige zinnen.
Na het uploaden van een afbeelding of het opgeven van een afbeeldings-URL, voeren Computer Vision-algoritmen tags uit op basis van de objecten, levende wezens en acties die in de afbeelding worden geïdentificeerd. U kunt tagging niet alleen gebruiken voor het hoofdonderwerp, zoals een persoon op de voorgrond, maar ook voor de omgeving (binnen of buiten), meubels, gereedschap, planten, dieren, accessoires, gadgets en enzovoort.
Voor deze functie is een afbeeldings-URL of een abase-64-kolom als invoer vereist. Op dit moment ondersteunt afbeeldingstags Engels, Spaans, Japans, Portugees en Vereenvoudigd Chinees. Zie ComputerVision Interface voor meer informatie.
Geautomatiseerde machine learning in Power BI
Met geautomatiseerde machine learning (AutoML) voor gegevensstromen kunnen bedrijfsanalisten machine learning-modellen (ML) rechtstreeks in Power BI trainen, valideren en aanroepen. Het bevat een eenvoudige ervaring voor het maken van een nieuw ML-model, waar analisten hun gegevensstromen kunnen gebruiken om de invoergegevens op te geven voor het trainen van het model. De service extraheert automatisch de meest relevante functies, selecteert een geschikt algoritme en valideert het ML-model. Nadat een model is getraind, genereert Power BI automatisch een prestatierapport dat de resultaten van de validatie bevat. Het model kan vervolgens worden aangeroepen voor nieuwe of bijgewerkte gegevens in de gegevensstroom.
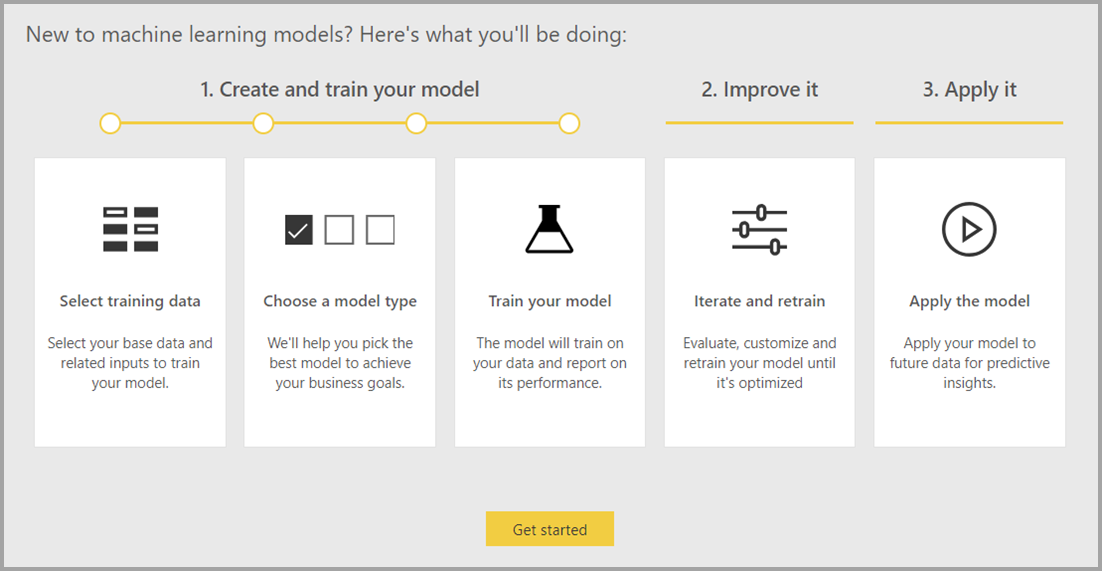
Geautomatiseerde machine learning is alleen beschikbaar voor gegevensstromen die worden gehost in Power BI Premium- en Embedded-capaciteiten.
Werken met AutoML
Machine learning en AI zien een ongekende toename van populariteit ten aanzien van industrieën en wetenschappelijk onderzoek. Bedrijven zijn ook op zoek naar manieren om deze nieuwe technologieën in hun activiteiten te integreren.
Gegevensstromen bieden selfservice voor gegevensvoorbereiding voor big data. AutoML is geïntegreerd in gegevensstromen en stelt u in staat om uw gegevensvoorbereiding te gebruiken voor het bouwen van machine learning-modellen, rechtstreeks in Power BI.
Met AutoML in Power BI kunnen gegevensanalisten gegevensstromen gebruiken om machine learning-modellen te bouwen met een vereenvoudigde ervaring door alleen Power BI-vaardigheden te gebruiken. Power BI automatiseert de meeste gegevenswetenschap achter het maken van de ML-modellen. Het heeft kaders om ervoor te zorgen dat het geproduceerde model een goede kwaliteit heeft en inzicht biedt in het proces dat wordt gebruikt om uw ML-model te maken.
AutoML ondersteunt het maken van binaire voorspellings-, classificatie- en regressiemodellen voor gegevensstromen. Deze functies zijn typen machine learning-technieken onder supervisie, wat betekent dat ze leren van de bekende resultaten van eerdere waarnemingen om de resultaten van andere waarnemingen te voorspellen. Het semantische invoermodel voor het trainen van een AutoML-model is een set rijen die zijn gelabeld met de bekende resultaten.
AutoML in Power BI integreert geautomatiseerde ML van Azure Machine Learning om uw ML-modellen te maken. U hebt echter geen Azure-abonnement nodig om AutoML te gebruiken in Power BI. De Power BI-service beheert het proces van het trainen en hosten van de ML-modellen volledig.
Nadat een ML-model is getraind, genereert AutoML automatisch een Power BI-rapport met een uitleg van de waarschijnlijke prestaties van uw ML-model. AutoML benadrukt de uitlegbaarheid door de belangrijkste beïnvloeders onder uw invoer te markeren die van invloed zijn op de voorspellingen die door uw model worden geretourneerd. Het rapport bevat ook belangrijke metrische gegevens voor het model.
Op andere pagina's van het gegenereerde rapport ziet u de statistische samenvatting van het model en de trainingsgegevens. De statistische samenvatting is van belang voor gebruikers die de standaardgegevenswetenschapmetingen van modelprestaties willen zien. De trainingsgegevens bevatten een overzicht van alle iteraties die zijn uitgevoerd om uw model te maken, met de bijbehorende modelleringsparameters. Ook wordt beschreven hoe elke invoer is gebruikt om het ML-model te maken.
Vervolgens kunt u uw ML-model toepassen op uw gegevens voor scoren. Wanneer de gegevensstroom wordt vernieuwd, worden uw gegevens bijgewerkt met voorspellingen van uw ML-model. Power BI bevat ook een geïndidialiseerde uitleg voor elke specifieke voorspelling die het ML-model produceert.
Een machine learning-model maken
In deze sectie wordt beschreven hoe u een AutoML-model maakt.
Gegevensvoorbereiding voor het maken van een ML-model
Als u een machine learning-model wilt maken in Power BI, moet u eerst een gegevensstroom maken voor de gegevens met de historische resultaatinformatie, die wordt gebruikt voor het trainen van het ML-model. U moet ook berekende kolommen toevoegen voor zakelijke metrische gegevens die sterke voorspellers kunnen zijn voor het resultaat dat u probeert te voorspellen. Zie Een gegevensstroom configureren en gebruiken voor meer informatie over het configureren van uw gegevensstroom.
AutoML heeft specifieke gegevensvereisten voor het trainen van een machine learning-model. Deze vereisten worden beschreven in de volgende secties, op basis van de respectieve modeltypen.
De invoer van het ML-model configureren
Als u een AutoML-model wilt maken, selecteert u het ML-pictogram in de kolom Acties van de gegevensstroomtabel en selecteert u Een machine learning-model toevoegen.
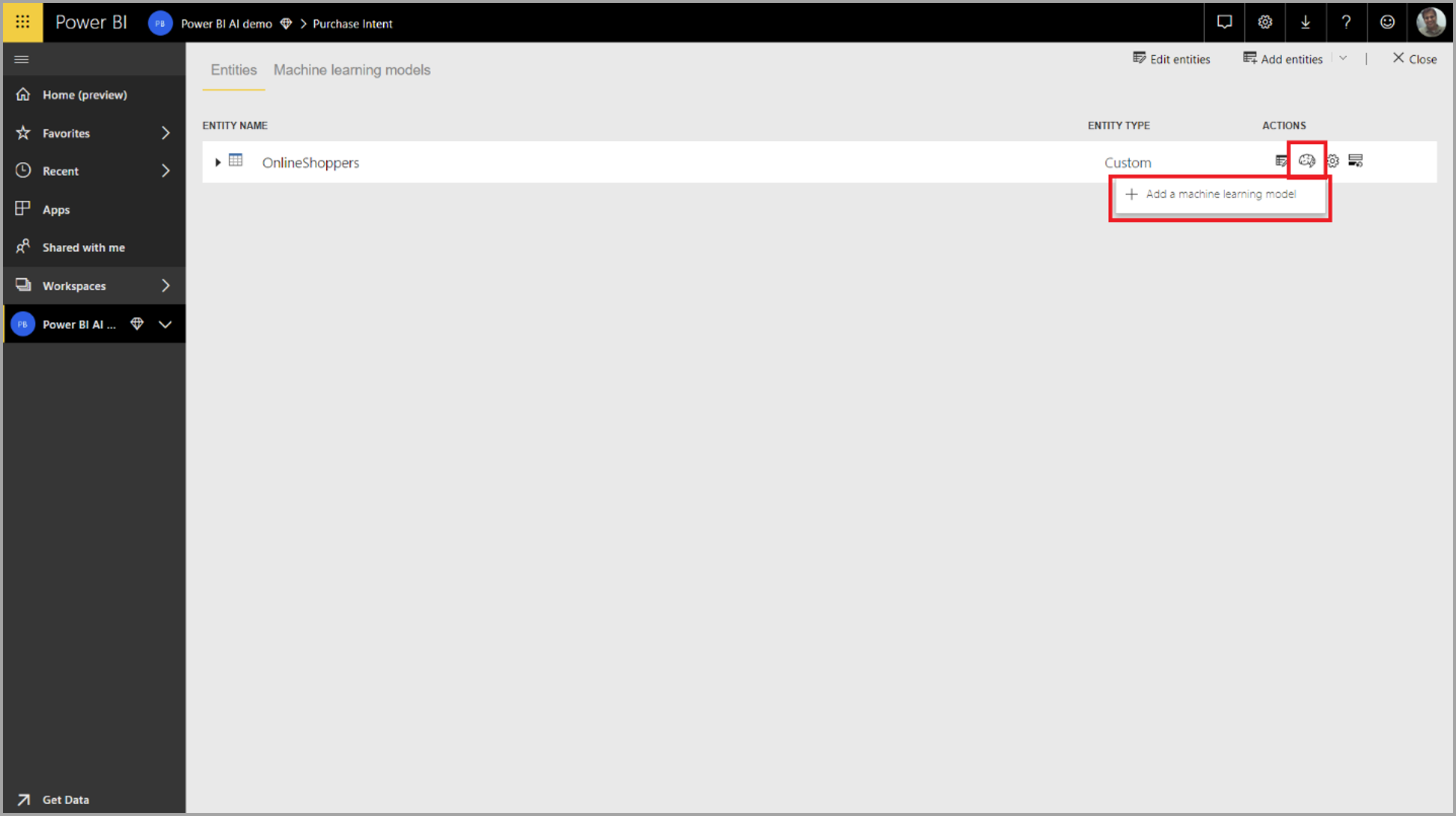
Een vereenvoudigde ervaring wordt gestart, bestaande uit een wizard die u begeleidt bij het maken van het ML-model. De wizard bevat de volgende eenvoudige stappen.
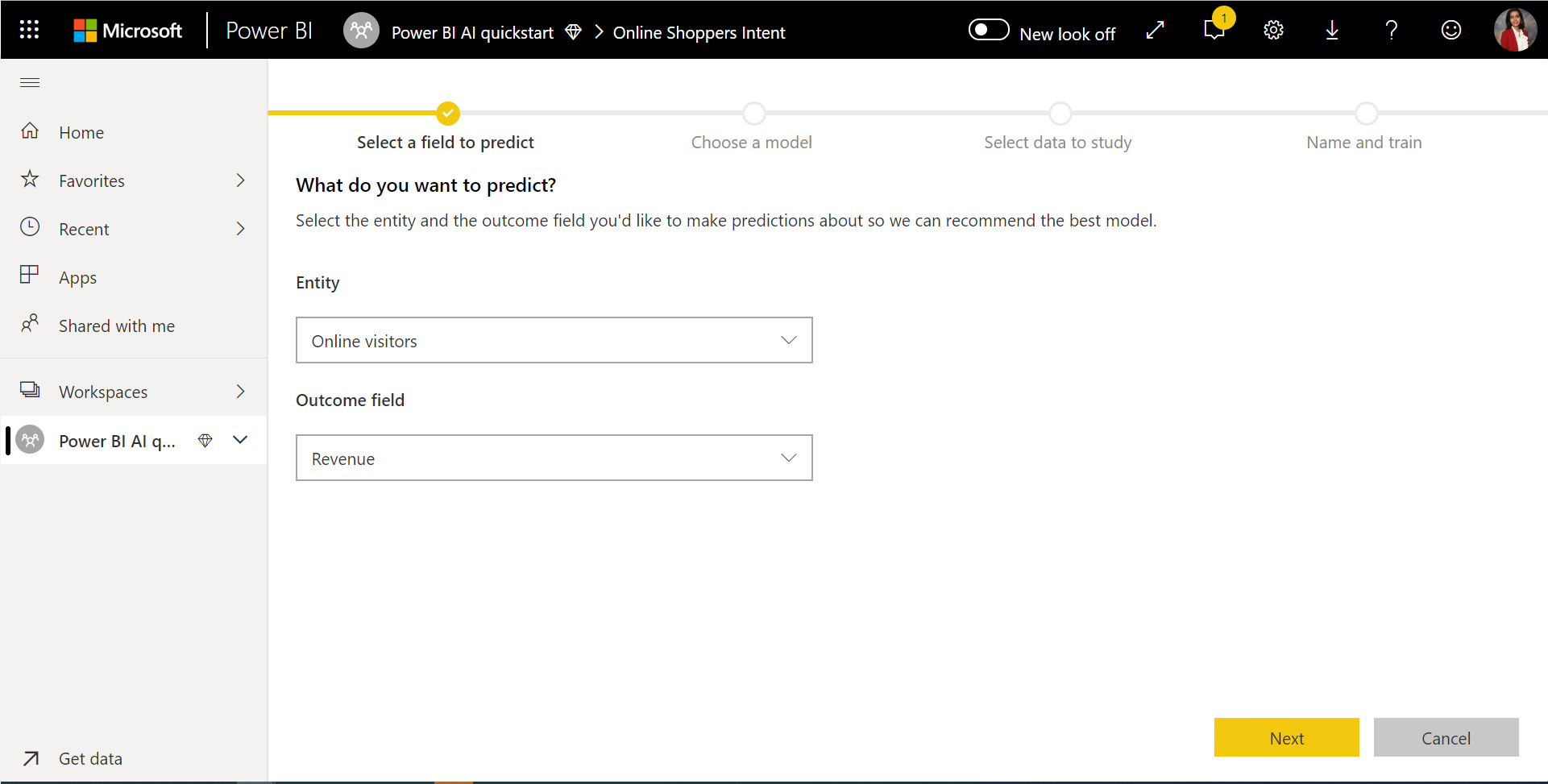
1. Selecteer de tabel met de historische gegevens en kies de resultaatkolom waarvoor u een voorspelling wilt
De resultaatkolom identificeert het labelkenmerk voor het trainen van het ML-model, weergegeven in de volgende afbeelding.
2. Kies een modeltype
Wanneer u de resultaatkolom opgeeft, analyseert AutoML de labelgegevens om het meest waarschijnlijke ML-modeltype aan te bevelen dat kan worden getraind. U kunt een ander modeltype kiezen, zoals wordt weergegeven in de volgende afbeelding door te klikken op Een model kiezen.

Notitie
Sommige modeltypen worden mogelijk niet ondersteund voor de gegevens die u hebt geselecteerd en dus worden deze uitgeschakeld. In het vorige voorbeeld is Regressie uitgeschakeld, omdat een tekstkolom is geselecteerd als resultaatkolom.
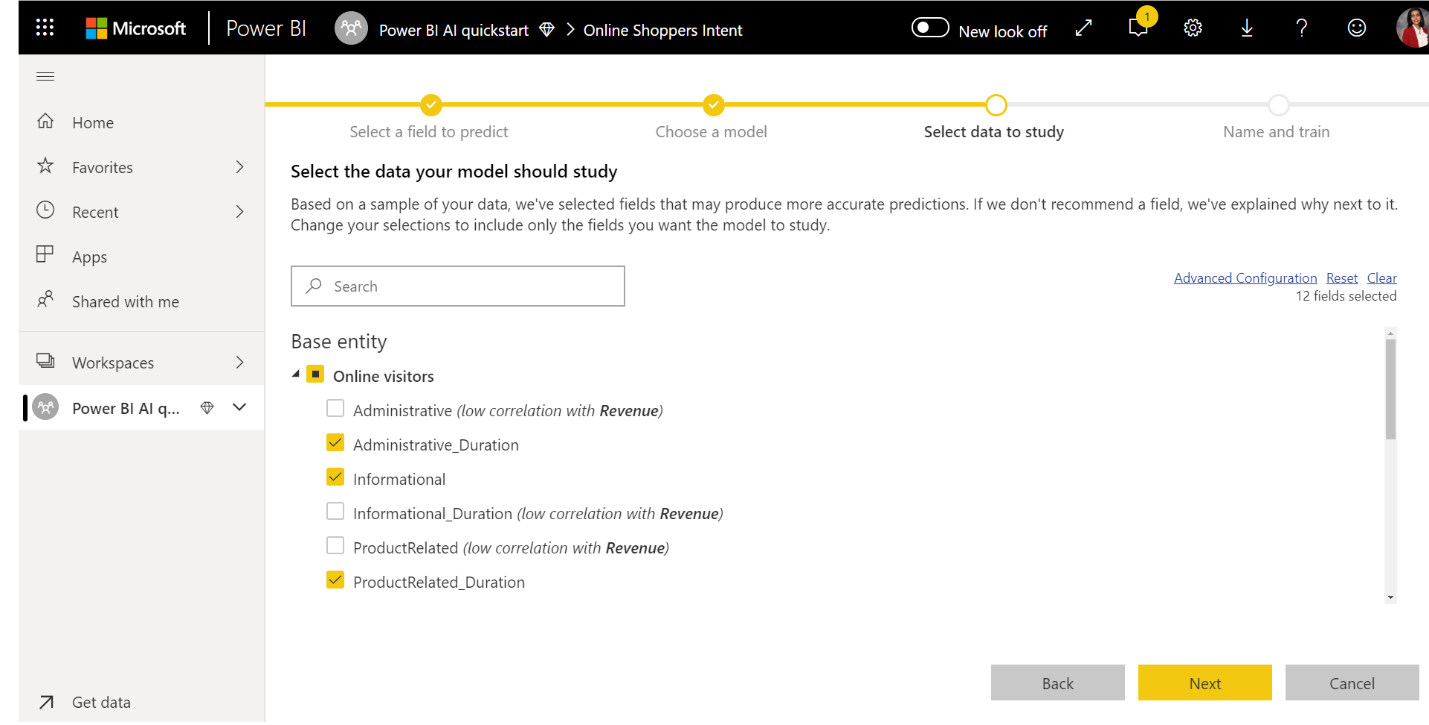
3. Selecteer de invoer die u het model wilt gebruiken als voorspellende signalen
AutoML analyseert een voorbeeld van de geselecteerde tabel om de invoer voor te stellen die kan worden gebruikt voor het trainen van het ML-model. Er worden verklaringen gegeven naast kolommen die niet zijn geselecteerd. Als een bepaalde kolom te veel afzonderlijke waarden of slechts één waarde of slechts één waarde of een lage of hoge correlatie met de uitvoerkolom heeft, wordt dit niet aanbevolen.
Invoer die afhankelijk is van de resultaatkolom (of de labelkolom) mag niet worden gebruikt voor het trainen van het ML-model, omdat deze van invloed zijn op de prestaties. Dergelijke kolommen worden gemarkeerd als 'verdacht hoge correlatie met uitvoerkolom'. Als u deze kolommen in de trainingsgegevens introduceert, wordt labellekken veroorzaakt, waarbij het model goed presteert op de validatie- of testgegevens, maar die prestaties niet kunnen vinden wanneer ze in productie worden gebruikt voor scoren. Labellekken kunnen een mogelijke zorg zijn in AutoML-modellen wanneer de prestaties van het trainingsmodel te goed zijn om waar te zijn.
Deze functieaanveling is gebaseerd op een voorbeeld van een gegevens, dus u moet de gebruikte invoer controleren. U kunt de selecties wijzigen zodat alleen de kolommen worden opgenomen die het model moet bestuderen. U kunt ook alle kolommen selecteren door het selectievakje naast de tabelnaam in te schakelen.
4. Geef uw model een naam en sla uw configuratie op
In de laatste stap kunt u het model een naam geven, Opslaan selecteren en kiezen welke begint met het trainen van het ML-model. U kunt ervoor kiezen om de trainingstijd te verkorten om snelle resultaten te zien of de hoeveelheid tijd die in de training is besteed te verhogen om het beste model te krijgen.

ML-modeltraining
De training van AutoML-modellen maakt deel uit van het vernieuwen van de gegevensstroom. AutoML bereidt uw gegevens eerst voor op training. AutoML splitst de historische gegevens die u opgeeft in trainings- en test semantische modellen. Het semantische testmodel is een bewaringsset die wordt gebruikt voor het valideren van de modelprestaties na de training. Deze sets worden gerealiseerd als trainings- en testtabellen in de gegevensstroom. AutoML maakt gebruik van kruisvalidatie voor de modelvalidatie.
Vervolgens wordt elke invoerkolom geanalyseerd en wordt de imputatie toegepast, waardoor eventuele ontbrekende waarden worden vervangen door vervangende waarden. Een aantal verschillende imputatiestrategieën worden gebruikt door AutoML. Voor invoerkenmerken die worden behandeld als numerieke kenmerken, wordt het gemiddelde van de kolomwaarden gebruikt voor de imputatie. Voor invoerkenmerken die als categorische functies worden behandeld, gebruikt AutoML de modus van de kolomwaarden voor imputatie. Het AutoML-framework berekent het gemiddelde en de modus van waarden die worden gebruikt voor de inbreking van het semantische trainingsmodel met subsampled.
Vervolgens worden steekproeven en normalisatie naar behoefte toegepast op uw gegevens. Voor classificatiemodellen voert AutoML de invoergegevens uit via gelaagde steekproeven en balanceerd de klassen om ervoor te zorgen dat het aantal rijen voor iedereen gelijk is.
AutoML past verschillende transformaties toe op elke geselecteerde invoerkolom op basis van het gegevenstype en de statistische eigenschappen. AutoML gebruikt deze transformaties om functies te extraheren voor gebruik bij het trainen van uw ML-model.
Het trainingsproces voor AutoML-modellen bestaat uit maximaal 50 iteraties met verschillende modelleringsalgoritmen en hyperparameterinstellingen om het model te vinden met de beste prestaties. Training kan vroeg eindigen met minder iteraties als AutoML merkt dat er geen prestatieverbetering wordt waargenomen. AutoML beoordeelt de prestaties van elk van deze modellen door het semantische model van de holdouttest te valideren. Tijdens deze trainingsstap maakt AutoML verschillende pijplijnen voor het trainen en valideren van deze iteraties. Het proces voor het beoordelen van de prestaties van de modellen kan enige tijd in beslag nemen, overal van enkele minuten tot een paar uur, tot de trainingstijd die in de wizard is geconfigureerd. De tijd die nodig is, is afhankelijk van de grootte van uw semantische model en de beschikbare capaciteitsbronnen.
In sommige gevallen kan het uiteindelijke gegenereerde model gebruikmaken van ensemble learning, waarbij meerdere modellen worden gebruikt om betere voorspellende prestaties te leveren.
Uitleg over AutoML-modellen
Nadat het model is getraind, analyseert AutoML de relatie tussen de invoerfuncties en de modeluitvoer. Het evalueert de omvang van de wijziging in de modeluitvoer voor het semantische model voor de holdouttest voor elke invoerfunctie. Deze relatie wordt het belang van de functie genoemd. Deze analyse vindt plaats als onderdeel van de vernieuwing nadat de training is voltooid. Daarom kan het vernieuwen langer duren dan de trainingstijd die in de wizard is geconfigureerd.

AutoML-modelrapport
AutoML genereert een Power BI-rapport met een overzicht van de prestaties van het model tijdens de validatie, samen met het belang van de globale functie. Dit rapport kan worden geopend vanaf het tabblad Machine Learning-modellen nadat de gegevensstroom is vernieuwd. Het rapport bevat een overzicht van de resultaten van het toepassen van het ML-model op de testgegevens voor bewaring en het vergelijken van de voorspellingen met de bekende resultaatwaarden.
U kunt het modelrapport bekijken om inzicht te hebben in de prestaties. U kunt ook valideren dat de belangrijkste beïnvloeders van het model overeenkomen met de zakelijke inzichten over de bekende resultaten.
De grafieken en metingen die worden gebruikt om de modelprestaties in het rapport te beschrijven, zijn afhankelijk van het modeltype. Deze prestatiegrafieken en metingen worden beschreven in de volgende secties.
Andere pagina's in het rapport kunnen statistische metingen over het model beschrijven vanuit het perspectief van gegevenswetenschap. Het rapport Binaire voorspelling bevat bijvoorbeeld een winstgrafiek en de ROC-curve voor het model.
De rapporten bevatten ook een pagina Trainingsgegevens met een beschrijving van hoe het model is getraind en een grafiek met een beschrijving van de modelprestaties voor elk van de iteraties.

In een andere sectie op deze pagina wordt het gedetecteerde type van de invoerkolom en de imputatiemethode beschreven die wordt gebruikt voor het invullen van ontbrekende waarden. Het bevat ook de parameters die worden gebruikt door het uiteindelijke model.
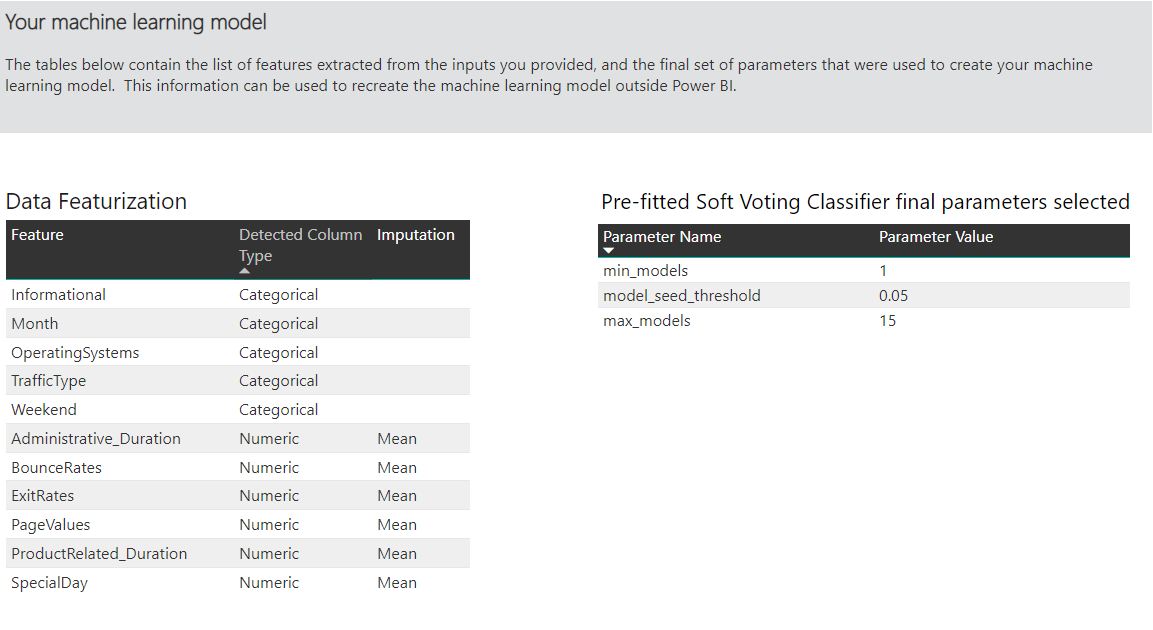
Als het geproduceerde model gebruikmaakt van ensemble learning, bevat de pagina Trainingsgegevens ook een grafiek met het gewicht van elk samenstellend model in het ensemble en de bijbehorende parameters.

Het AutoML-model toepassen
Als u tevreden bent over de prestaties van het gemaakte ML-model, kunt u het toepassen op nieuwe of bijgewerkte gegevens wanneer uw gegevensstroom wordt vernieuwd. Selecteer in het modelrapport de knop Toepassen in de rechterbovenhoek of de knop ML-model toepassen onder acties op het tabblad Machine Learning-modellen .
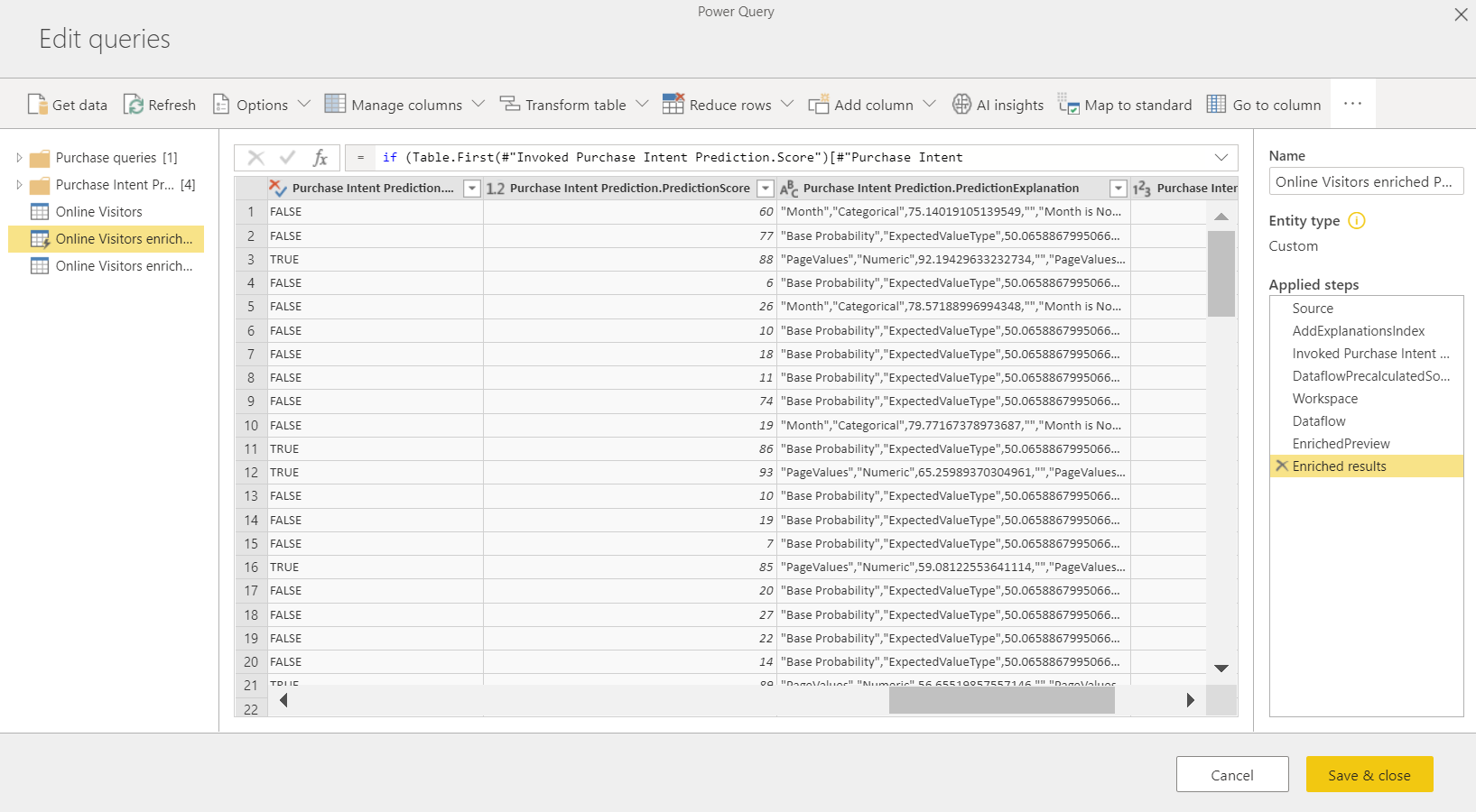
Als u het ML-model wilt toepassen, moet u de naam opgeven van de tabel waarop het moet worden toegepast en een voorvoegsel voor de kolommen die worden toegevoegd aan deze tabel voor de modeluitvoer. Het standaardvoorvoegsel voor de kolomnamen is de modelnaam. De functie Toepassen kan meer parameters bevatten die specifiek zijn voor het modeltype.
Als u het ML-model toepast, worden twee nieuwe gegevensstroomtabellen gemaakt die de voorspellingen en geïnitialiseerde uitleg bevatten voor elke rij die in de uitvoertabel wordt gescored. Als u bijvoorbeeld het PurchaseIntent-model toepast op de tabel OnlineShoppers, genereert de uitvoer de tabellen met verrijkte PurchaseIntent- en OnlineShoppers verrijkte PurchaseIntent-uitlegtabellen. Voor elke rij in de verrijkte tabel worden de uitleg onderverdeeld in meerdere rijen in de tabel met verrijkte uitleg op basis van de invoerfunctie. Een ExplanationIndex helpt de rijen van de tabel met verrijkte uitleg toe te wijzen aan de rij in een verrijkte tabel.
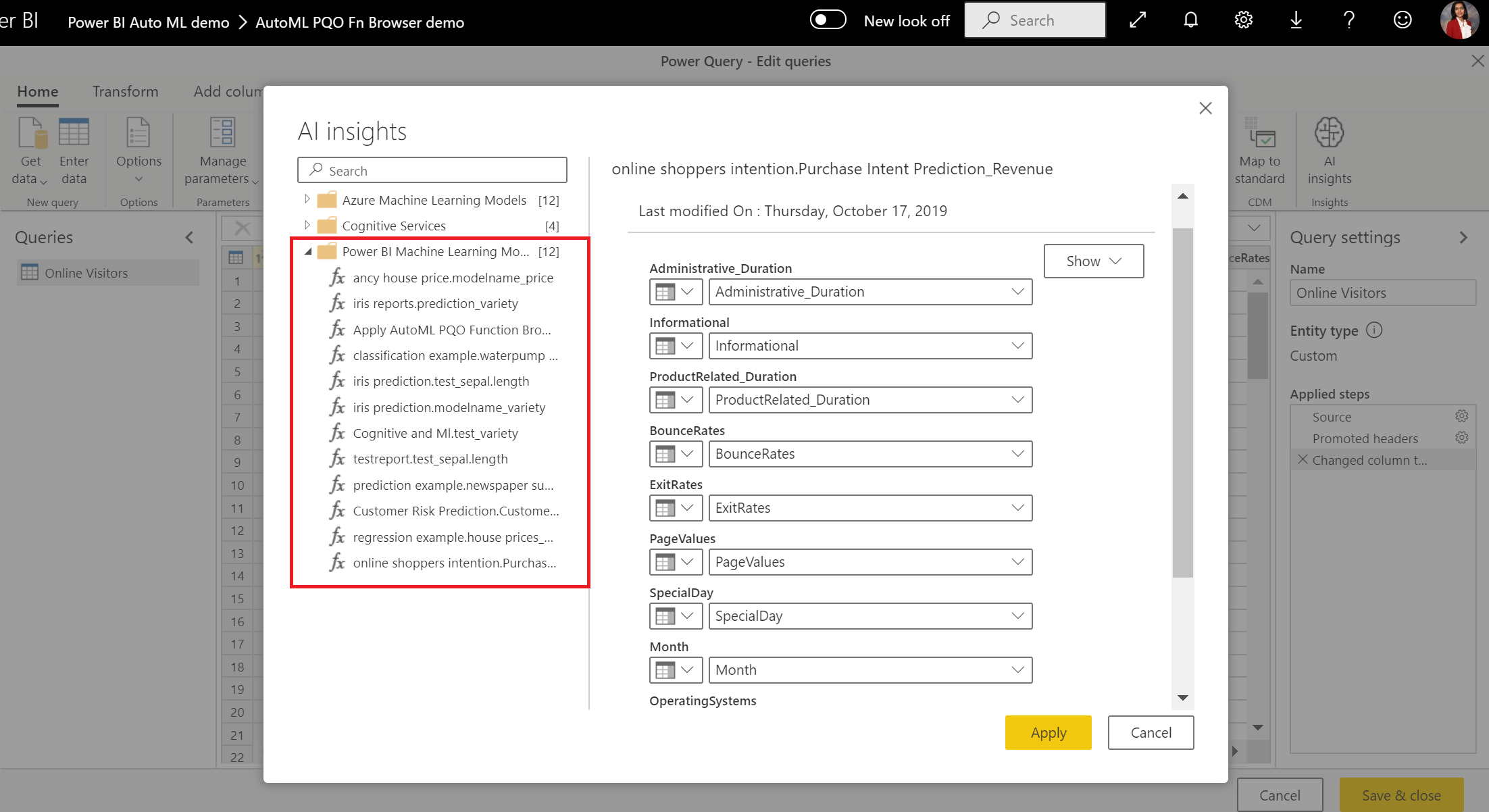
U kunt ook elk Power BI AutoML-model toepassen op tabellen in elke gegevensstroom in dezelfde werkruimte met behulp van AI-inzichten in de PQO-functiebrowser. Op deze manier kunt u modellen gebruiken die door anderen in dezelfde werkruimte zijn gemaakt zonder dat u eigenaar hoeft te zijn van de gegevensstroom die het model heeft. Power Query detecteert alle Power BI ML-modellen in de werkruimte en maakt deze beschikbaar als dynamische Power Query-functies. U kunt deze functies aanroepen door ze te openen vanaf het lint in Power Query-editor of door de functie M rechtstreeks aan te roepen. Deze functionaliteit wordt momenteel alleen ondersteund voor Power BI-gegevensstromen en voor Power Query Online in de Power BI-service. Dit proces verschilt van het toepassen van ML-modellen binnen een gegevensstroom met behulp van de AutoML-wizard. Er is geen uitlegtabel gemaakt met behulp van deze methode. Tenzij u de eigenaar van de gegevensstroom bent, hebt u geen toegang tot modeltrainingsrapporten of kunt u het model opnieuw trainen. Als het bronmodel wordt bewerkt door invoerkolommen toe te voegen of te verwijderen, of als het model of de brongegevensstroom wordt verwijderd, wordt deze afhankelijke gegevensstroom verbroken.
Nadat u het model hebt toegepast, houdt AutoML uw voorspellingen altijd up-to-date wanneer de gegevensstroom wordt vernieuwd.
Als u de inzichten en voorspellingen van het ML-model in een Power BI-rapport wilt gebruiken, kunt u verbinding maken met de uitvoertabel vanuit Power BI Desktop met behulp van de gegevensstroomconnector .
Binaire voorspellingsmodellen
Binaire voorspellingsmodellen, formeel bekend als binaire classificatiemodellen, worden gebruikt om een semantisch model in twee groepen te classificeren. Ze worden gebruikt om gebeurtenissen te voorspellen die een binair resultaat kunnen hebben. Bijvoorbeeld, of een verkoopkans wordt geconverteerd, of een account wordt verloop, of een factuur op tijd wordt betaald, of een transactie frauduleus is, enzovoort.
De uitvoer van een binair voorspellingsmodel is een waarschijnlijkheidsscore, die de kans identificeert dat het doelresultaat wordt bereikt.
Een binair voorspellingsmodel trainen
Vereisten:
- Er zijn minimaal 20 rijen met historische gegevens vereist voor elke klasse met resultaten
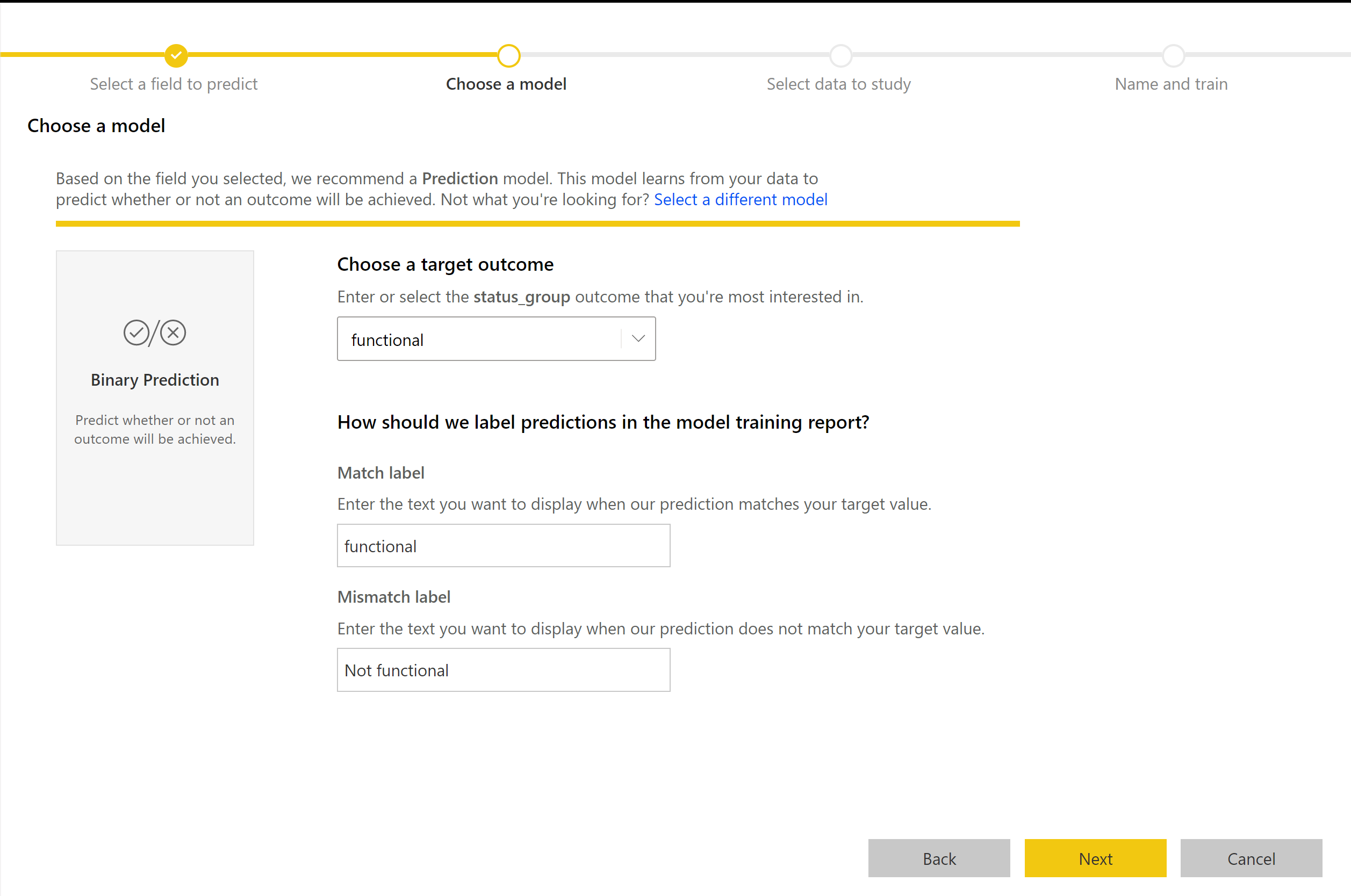
Het proces voor het maken van een binair voorspellingsmodel volgt dezelfde stappen als andere AutoML-modellen, zoals beschreven in de vorige sectie, de invoer van het ML-model configureren. Het enige verschil is in de stap Een model kiezen waarin u de doelresultaatwaarde kunt selecteren waarin u het meest geïnteresseerd bent. U kunt ook beschrijvende labels opgeven voor de resultaten die moeten worden gebruikt in het automatisch gegenereerde rapport waarin de resultaten van de modelvalidatie worden samengevat.
Rapport binair voorspellingsmodel
Het binaire voorspellingsmodel produceert als uitvoer een kans dat een rij het doelresultaat bereikt. Het rapport bevat een slicer voor de waarschijnlijkheidsdrempel, die van invloed is op de manier waarop de scores groter en kleiner zijn dan de waarschijnlijkheidsdrempel.
In het rapport worden de prestaties van het model beschreven in termen van terecht-positieven, fout-positieven, terecht-negatieven en fout-negatieven. Terecht-positieven en Terecht-negatieven zijn correct voorspelde resultaten voor de twee klassen in de resultaatgegevens. Fout-positieven zijn rijen die zijn voorspeld dat ze het doelresultaat hebben, maar dat niet. Fout-negatieven zijn daarentegen rijen met doelresultaten, maar werden voorspeld als niet.
Metingen, zoals Precisie en Relevante overeenkomsten, beschrijven het effect van de waarschijnlijkheidsdrempel op de voorspelde resultaten. U kunt de slicer voor waarschijnlijkheidsdrempels gebruiken om een drempelwaarde te selecteren waarmee een evenwichtige compromis tussen Precisie en Relevante overeenkomsten wordt bereikt.

Het rapport bevat ook een hulpprogramma voor kosten-batenanalyse om de subset van de populatie te identificeren waarop de hoogste winst moet worden behaald. Gezien de geschatte eenheidskosten van doelen en een eenheidsvoordeel van het bereiken van een doelresultaat, probeert cost-benefit-analyse de winst te maximaliseren. U kunt dit hulpprogramma gebruiken om uw waarschijnlijkheidsdrempel te kiezen op basis van het maximumpunt in de grafiek om de winst te maximaliseren. U kunt de grafiek ook gebruiken om de winst of kosten voor uw keuze van de waarschijnlijkheidsdrempel te berekenen.
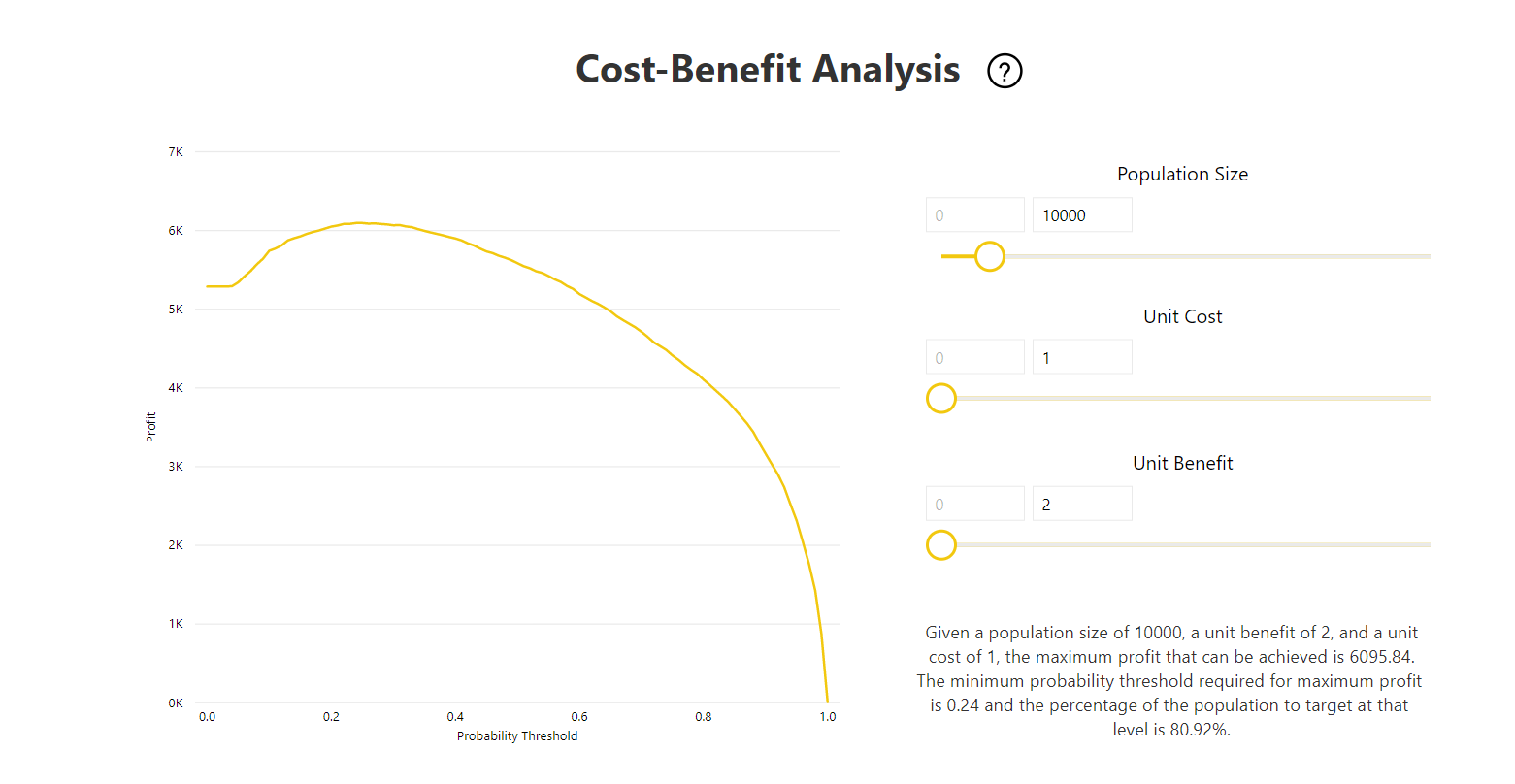
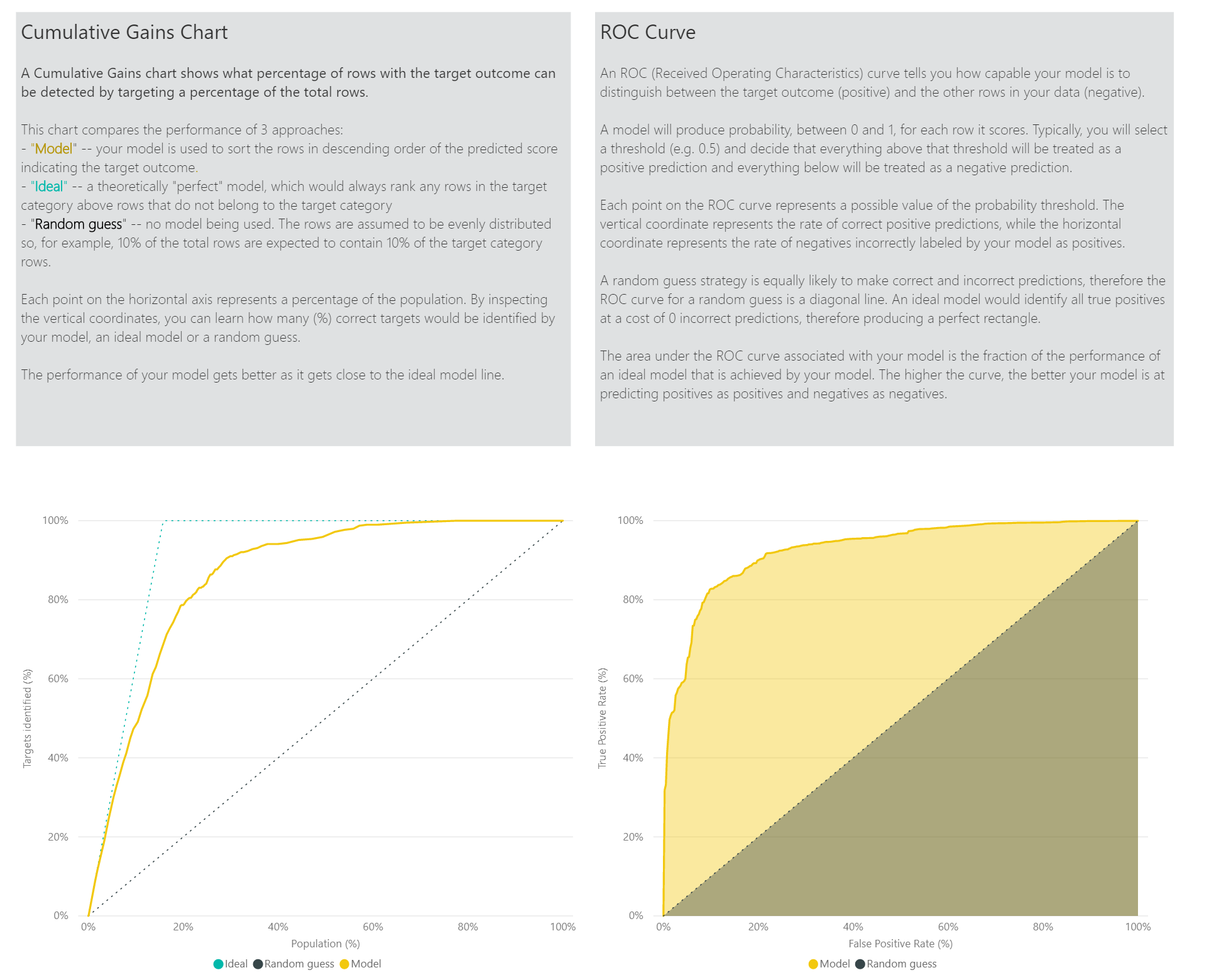
De pagina Nauwkeurigheidsrapport van het modelrapport bevat de grafiek Cumulatieve winsten en de ROC-curve voor het model. Deze gegevens bieden statistische metingen van de modelprestaties. De rapporten bevatten beschrijvingen van de weergegeven grafieken.
Een binair voorspellingsmodel toepassen
Als u een binair voorspellingsmodel wilt toepassen, moet u de tabel opgeven met de gegevens waarop u de voorspellingen van het ML-model wilt toepassen. Andere parameters omvatten het voorvoegsel voor de naam van de uitvoerkolom en de waarschijnlijkheidsdrempel voor het classificeren van het voorspelde resultaat.
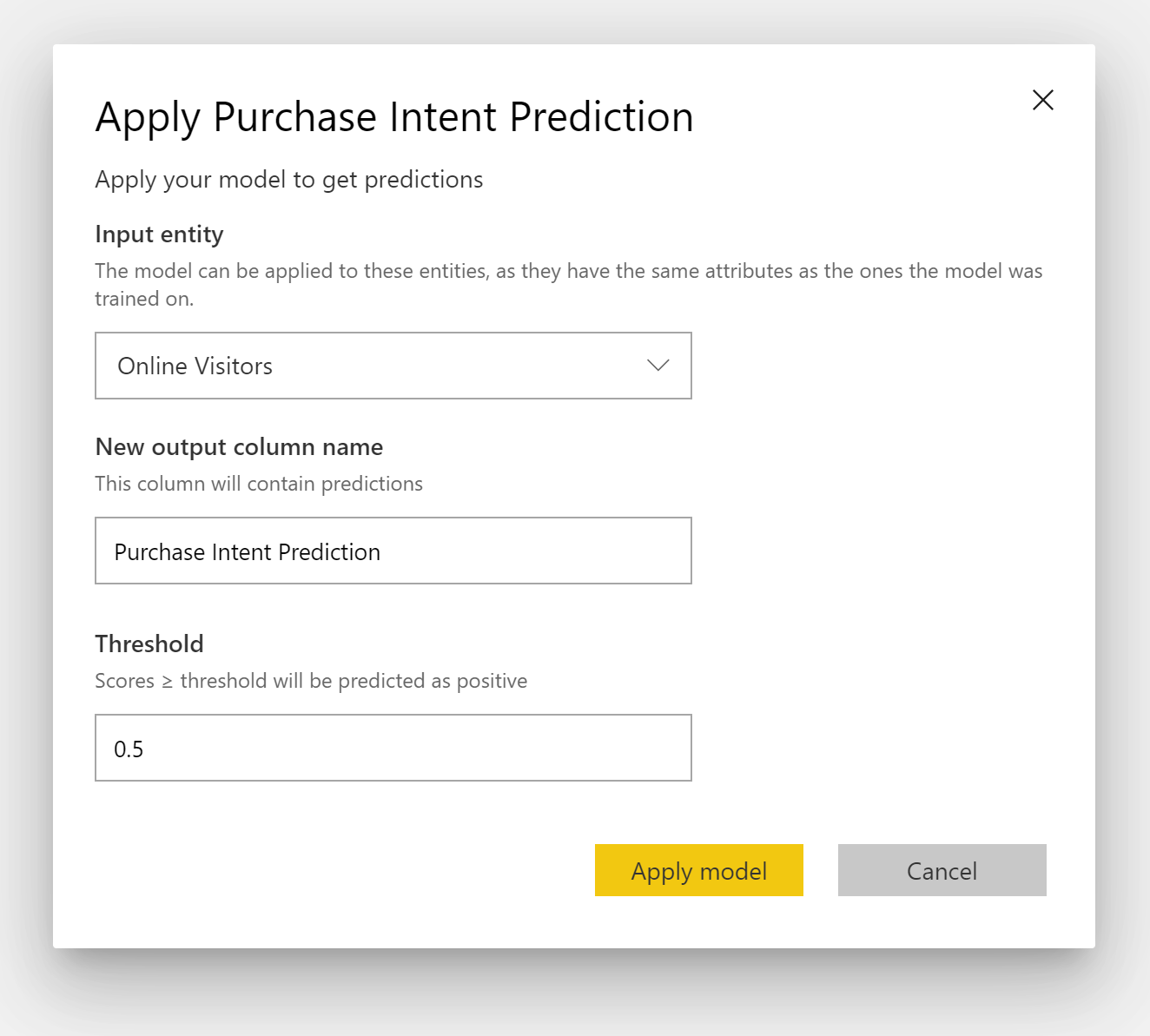
Wanneer een binair voorspellingsmodel wordt toegepast, worden er vier uitvoerkolommen toegevoegd aan de verrijkte uitvoertabel: Resultaat, PredictionScore, PredictionExplanation en ExplanationIndex. Voor de kolomnamen in de tabel is het voorvoegsel opgegeven wanneer het model wordt toegepast.
PredictionScore is een percentage waarschijnlijkheid, waarmee de kans wordt geïdentificeerd dat het doelresultaat wordt bereikt.
De kolom Resultaat bevat het voorspelde resultaatlabel. Records met waarschijnlijkheden die de drempelwaarde overschrijden, worden voorspeld als waarschijnlijk het doelresultaat te bereiken en worden gelabeld als Waar. Records die kleiner zijn dan de drempelwaarde, worden voorspeld als onwaarschijnlijk om het resultaat te bereiken en worden gelabeld als Onwaar.
De kolom PredictionExplanation bevat een uitleg met de specifieke invloed die de invoerfuncties op de PredictionScore hadden.
Classificatiemodellen
Classificatiemodellen worden gebruikt om een semantisch model te classificeren in meerdere groepen of klassen. Ze worden gebruikt om gebeurtenissen te voorspellen die een van de meerdere mogelijke resultaten kunnen hebben. Bijvoorbeeld, of een klant waarschijnlijk een hoge, gemiddelde of lage levensduurwaarde heeft. Ze kunnen ook voorspellen of het standaardrisico hoog, gemiddeld, laag, enzovoort is.
De uitvoer van een classificatiemodel is een waarschijnlijkheidsscore, die de kans identificeert dat een rij de criteria voor een bepaalde klasse bereikt.
Een classificatiemodel trainen
De invoertabel met uw trainingsgegevens voor een classificatiemodel moet een kolom met een tekenreeks of een geheel getal hebben als resultaatkolom, waarmee de eerdere bekende resultaten worden geïdentificeerd.
Vereisten:
- Er zijn minimaal 20 rijen met historische gegevens vereist voor elke klasse met resultaten
Het proces voor het maken van een classificatiemodel volgt dezelfde stappen als andere AutoML-modellen, zoals beschreven in de vorige sectie, de invoer van het ML-model configureren.
Rapport classificatiemodel
Power BI maakt het classificatiemodelrapport door het ML-model toe te passen op de testgegevens van de bewaring. Vervolgens wordt de voorspelde klasse voor een rij vergeleken met de werkelijke bekende klasse.
Het modelrapport bevat een grafiek met de uitsplitsing van de juiste en onjuist geclassificeerde rijen voor elke bekende klasse.
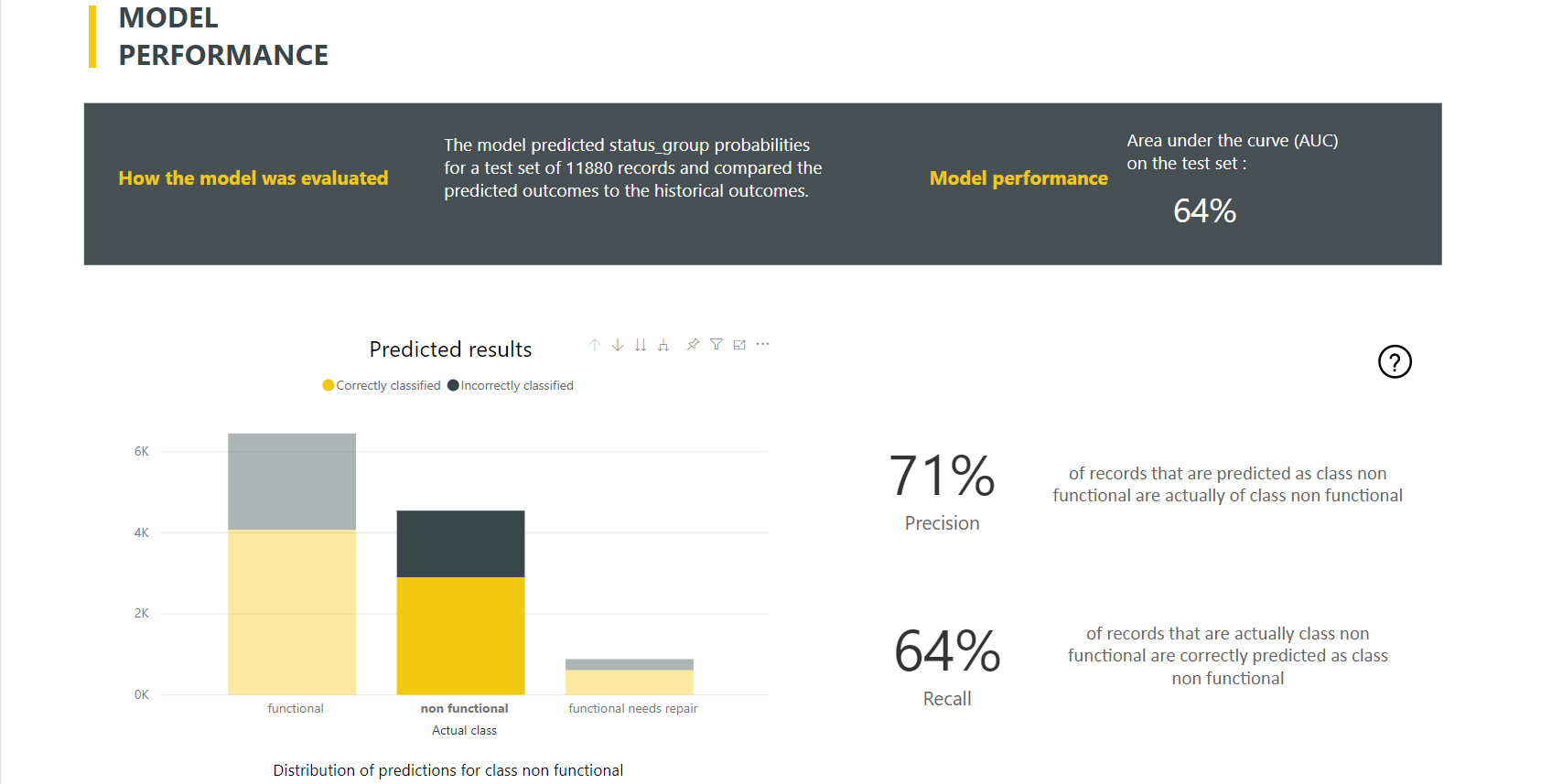
Een verdere klassespecifieke inzoomactie maakt een analyse mogelijk van hoe de voorspellingen voor een bekende klasse worden gedistribueerd. Deze analyse toont de andere klassen waarin rijen van die bekende klasse waarschijnlijk onjuist worden geclassificeerd.
De uitleg van het model in het rapport bevat ook de belangrijkste voorspellers voor elke klasse.
Het rapport classificatiemodel bevat ook een pagina trainingsgegevens die vergelijkbaar is met de pagina's voor andere modeltypen, zoals eerder beschreven in het AutoML-modelrapport.
Een classificatiemodel toepassen
Als u een classificatie-ML-model wilt toepassen, moet u de tabel opgeven met de invoergegevens en het voorvoegsel voor de naam van de uitvoerkolom.
Wanneer een classificatiemodel wordt toegepast, worden er vijf uitvoerkolommen toegevoegd aan de verrijkte uitvoertabel: ClassificationScore, ClassificationResult, ClassificationExplanation, ClassProbabilities en ExplanationIndex. Voor de kolomnamen in de tabel is het voorvoegsel opgegeven wanneer het model wordt toegepast.
De kolom ClassProbabilities bevat de lijst met waarschijnlijkheidsscores voor de rij voor elke mogelijke klasse.
De ClassificationScore is de percentagekans, die de kans identificeert dat een rij de criteria voor een bepaalde klasse bereikt.
De kolom ClassificationResult bevat de meest waarschijnlijk voorspelde klasse voor de rij.
De kolom ClassificationExplanation bevat een uitleg met de specifieke invloed die de invoerfuncties op de ClassificationScore hadden.
Regressiemodellen
Regressiemodellen worden gebruikt om een numerieke waarde te voorspellen en kunnen worden gebruikt in scenario's zoals het bepalen van:
- De omzet wordt waarschijnlijk gerealiseerd door een verkoopdeal.
- De levensduurwaarde van een account.
- Het bedrag van een debiteurenfactuur dat waarschijnlijk zal worden betaald
- De datum waarop een factuur kan worden betaald, enzovoort.
De uitvoer van een Regressiemodel is de voorspelde waarde.
Een regressiemodel trainen
De invoertabel met de trainingsgegevens voor een regressiemodel moet een numerieke kolom hebben als resultaatkolom, waarmee de bekende resultaatwaarden worden geïdentificeerd.
Vereisten:
- Er zijn minimaal 100 rijen met historische gegevens vereist voor een Regressiemodel.
Het proces voor het maken van een Regressiemodel volgt dezelfde stappen als andere AutoML-modellen, zoals beschreven in de vorige sectie, de invoer van het ML-model configureren.
Regressiemodelrapport
Net als de andere AutoML-modelrapporten is het regressierapport gebaseerd op de resultaten van het toepassen van het model op de testgegevens voor bewaring.
Het modelrapport bevat een grafiek waarmee de voorspelde waarden worden vergeleken met de werkelijke waarden. In deze grafiek geeft de afstand van de diagonale de fout in de voorspelling aan.
In het residufoutdiagram ziet u de verdeling van het percentage van de gemiddelde fout voor verschillende waarden in het semantische model voor de holdouttest. De horizontale as vertegenwoordigt het gemiddelde van de werkelijke waarde voor de groep. De grootte van de bel toont de frequentie of het aantal waarden in dat bereik. De verticale as is de gemiddelde restfout.
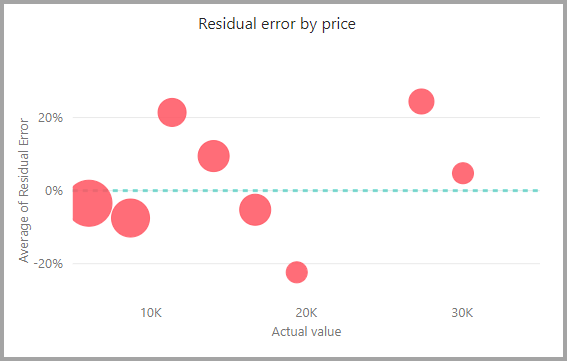
Het regressiemodelrapport bevat ook een pagina Trainingsgegevens, zoals de rapporten voor andere modeltypen, zoals beschreven in de vorige sectie, het AutoML-modelrapport.
Een regressiemodel toepassen
Als u een Regression ML-model wilt toepassen, moet u de tabel opgeven met de invoergegevens en het voorvoegsel voor de naam van de uitvoerkolom.

Wanneer een Regressiemodel wordt toegepast, worden er drie uitvoerkolommen toegevoegd aan de verrijkte uitvoertabel: RegressionResult, RegressionExplanation en ExplanationIndex. Voor de kolomnamen in de tabel is het voorvoegsel opgegeven wanneer het model wordt toegepast.
De kolom RegressionResult bevat de voorspelde waarde voor de rij op basis van de invoerkolommen. De kolom RegressionExplanation bevat een uitleg met de specifieke invloed die de invoerfuncties op regressionResult hadden.
Azure Machine Learning-integratie in Power BI
Veel organisaties gebruiken machine learning-modellen voor betere inzichten en voorspellingen over hun bedrijf. U kunt machine learning gebruiken met uw rapporten, dashboards en andere analyses om deze inzichten te verkrijgen. De mogelijkheid om inzichten uit deze modellen te visualiseren en aan te roepen, kan helpen deze inzichten te verspreiden aan de zakelijke gebruikers die dit het meest nodig hebben. Power BI maakt het nu eenvoudig om de inzichten op te nemen van modellen die worden gehost in Azure Machine Learning, met behulp van eenvoudige point-and-click-bewegingen.
Als u deze mogelijkheid wilt gebruiken, kan een data scientist via Azure Portal toegang verlenen tot het Azure Machine Learning-model aan de BI-analist. Vervolgens detecteert Power Query aan het begin van elke sessie alle Azure Machine Learning-modellen waartoe de gebruiker toegang heeft en beschikbaar maakt als dynamische Power Query-functies. De gebruiker kan deze functies vervolgens aanroepen door ze te openen vanaf het lint in Power Query-editor of door de functie M rechtstreeks aan te roepen. Power BI batcheert de toegangsaanvragen ook automatisch bij het aanroepen van het Azure Machine Learning-model voor een set rijen om betere prestaties te bereiken.
Deze functionaliteit wordt momenteel alleen ondersteund voor Power BI-gegevensstromen en voor Power Query online in de Power BI-service.
Zie Inleiding tot gegevensstromen en selfservice voor gegevensvoorbereiding voor meer informatie over gegevensstromen.
Zie voor meer informatie over Azure Machine Learning:
- Overzicht: Wat is Azure Machine Learning?
- Quick Starts en zelfstudies voor Azure Machine Learning: Documentatie voor Azure Machine Learning
Toegang verlenen tot het Azure Machine Learning-model aan een Power BI-gebruiker
Voor toegang tot een Azure Machine Learning-model vanuit Power BI moet de gebruiker leestoegang hebben tot het Azure-abonnement en de Machine Learning-werkruimte.
In de stappen in dit artikel wordt beschreven hoe u een Power BI-gebruiker toegang verleent tot een model dat wordt gehost in de Azure Machine Learning-service om toegang te krijgen tot dit model als een Power Query-functie. Zie voor meer informatie Azure-rollen toewijzen met behulp van de Azure-portal.
Meld u aan bij het Azure-portaal.
Ga naar de pagina Abonnementen . U vindt de pagina Abonnementen via de lijst Alle services in het navigatievenstermenu van Azure Portal.

Selecteer uw abonnement.

Selecteer Toegangsbeheer (IAM) en kies vervolgens de knop Toevoegen .

Selecteer Lezer als rol. Kies vervolgens de Power BI-gebruiker aan wie u toegang wilt verlenen tot het Azure Machine Learning-model.

Selecteer Opslaan.
Herhaal stap drie tot en met zes om lezer toegang te verlenen tot de gebruiker voor de specifieke machine learning-werkruimte die als host fungeert voor het model.




Schemadetectie voor machine learning-modellen
Gegevenswetenschappers gebruiken voornamelijk Python om hun machine learning-modellen voor machine learning te ontwikkelen en zelfs te implementeren. De data scientist moet het schemabestand expliciet genereren met behulp van Python.
Dit schemabestand moet worden opgenomen in de geïmplementeerde webservice voor machine learning-modellen. Als u het schema voor de webservice automatisch wilt genereren, moet u een voorbeeld van de invoer/uitvoer opgeven in het invoerscript voor het geïmplementeerde model. Zie Een machine learning-model implementeren en beoordelen met behulp van een online-eindpunt voor meer informatie. De koppeling bevat het voorbeeldinvoerscript met de instructies voor het genereren van het schema.
De functies @input_schema en @output_schema in het invoerscript verwijzen met name naar de indelingen voor invoer- en uitvoervoorbeelden in de variabelen input_sample en output_sample. De functies gebruiken deze voorbeelden voor het genereren van een OpenAPI-specificatie (Swagger) voor de webservice tijdens de implementatie.
Deze instructies voor het genereren van schema's door het invoerscript bij te werken, moeten ook worden toegepast op modellen die zijn gemaakt met behulp van geautomatiseerde machine learning-experimenten met de Azure Machine Learning SDK.
Notitie
Modellen die zijn gemaakt met behulp van de visuele interface van Azure Machine Learning bieden momenteel geen ondersteuning voor het genereren van schema's, maar wel in volgende releases.
Het Azure Machine Learning-model aanroepen in Power BI
U kunt elk Azure Machine Learning-model aanroepen waaraan u toegang hebt gekregen, rechtstreeks vanuit de Power Query-editor in uw gegevensstroom. Als u toegang wilt krijgen tot de Azure Machine Learning-modellen, selecteert u de knop Tabel bewerken voor de tabel die u wilt verrijken met inzichten uit uw Azure Machine Learning-model, zoals wordt weergegeven in de volgende afbeelding.

Als u de knop Tabel bewerken selecteert, wordt het Power Query-editor voor de tabellen in uw gegevensstroom geopend.

Selecteer de knop AI-inzichten op het lint en selecteer vervolgens de map Azure Machine Learning-modellen in het navigatievenstermenu. Alle Azure Machine Learning-modellen waartoe u toegang hebt, worden hier vermeld als Power Query-functies. De invoerparameters voor het Azure Machine Learning-model worden ook automatisch toegewezen als parameters van de bijbehorende Power Query-functie.
Als u een Azure Machine Learning-model wilt aanroepen, kunt u een van de kolommen van de geselecteerde tabel opgeven als invoer in de vervolgkeuzelijst. U kunt ook een constante waarde opgeven die als invoer moet worden gebruikt door het kolompictogram links van het invoerdialoogvenster te schakelen.

Selecteer Aanroepen om de preview van de uitvoer van het Azure Machine Learning-model weer te geven als een nieuwe kolom in de tabel. De aanroep van het model wordt weergegeven als een toegepaste stap voor de query.

Als het model meerdere uitvoerparameters retourneert, worden ze gegroepeerd als een rij in de uitvoerkolom. U kunt de kolom uitbreiden om afzonderlijke uitvoerparameters in afzonderlijke kolommen te produceren.

Nadat u de gegevensstroom hebt opgeslagen, wordt het model automatisch aangeroepen wanneer de gegevensstroom wordt vernieuwd, voor nieuwe of bijgewerkte rijen in de tabel.
Overwegingen en beperkingen
- Gegevensstromen Gen2 kan momenteel niet worden geïntegreerd met geautomatiseerde machine learning.
- AI-inzichten (Cognitive Services- en Azure Machine Learning-modellen) worden niet ondersteund op computers waarvoor proxyverificatie is ingesteld.
- Azure Machine Learning-modellen worden niet ondersteund voor gastgebruikers.
- Er zijn enkele bekende problemen met het gebruik van gateway met AutoML en Cognitive Services. Als u een gateway wilt gebruiken, raden we u aan eerst een gegevensstroom te maken waarmee de benodigde gegevens via de gateway worden geïmporteerd. Maak vervolgens een andere gegevensstroom die verwijst naar de eerste gegevensstroom om deze modellen en AI-functies te maken of toe te passen.
- Als uw AI-werk met gegevensstromen mislukt, moet u Mogelijk Fast Combine inschakelen bij het gebruik van AI met gegevensstromen. Nadat u de tabel hebt geïmporteerd en voordat u AI-functies gaat toevoegen, selecteert u Opties op het startlint en schakelt u in het venster dat wordt weergegeven het selectievakje in naast Gegevens uit meerdere bronnen toestaan om de functie in te schakelen. Selecteer vervolgens OK om uw selectie op te slaan. Vervolgens kunt u AI-functies toevoegen aan uw gegevensstroom.
Gerelateerde inhoud
Dit artikel bevat een overzicht van geautomatiseerde machine learning voor gegevensstromen in de Power BI-service. De volgende artikelen kunnen ook nuttig zijn.
- Zelfstudie: Een Machine Learning-model bouwen in Power BI
- Zelfstudie: Cognitive Services gebruiken in Power BI
De volgende artikelen bevatten meer informatie over gegevensstromen en Power BI:
- Inleiding in gegevensstromen en selfservice-gegevensvoorbereiding
- Een gegevensstroom maken
- Een gegevensstroom configureren en gebruiken
- Gegevensstroomopslag configureren voor het gebruik van Azure Data Lake Gen 2
- Premium-functies van gegevensstromen
- Overwegingen en beperkingen voor gegevensstromen
- Best practices voor gegevensstromen
Feedback
Binnenkort beschikbaar: in de loop van 2024 zullen we GitHub-problemen geleidelijk uitfaseren als het feedbackmechanisme voor inhoud en deze vervangen door een nieuw feedbacksysteem. Zie https://aka.ms/ContentUserFeedback voor meer informatie.
Feedback verzenden en weergeven voor