Opcje magazynu danych (tworzenie aplikacji w chmurze Real-World za pomocą platformy Azure)
Autor : Rick Anderson, Tom Dykstra
Pobierz naprawę projektu lub pobierz książkę elektroniczną
Książka elektroniczna Building Real World Cloud Apps with Azure (Tworzenie rzeczywistych aplikacji w chmurze za pomocą platformy Azure ) jest oparta na prezentacji opracowanej przez Scotta Guthrie. Wyjaśniono w nim 13 wzorców i rozwiązań, które mogą pomóc w pomyślnym tworzeniu aplikacji internetowych dla chmury. Aby uzyskać informacje na temat książki e-book, zobacz pierwszy rozdział.
Większość osób jest używana do relacyjnych baz danych i zwykle pomija inne opcje przechowywania danych podczas projektowania aplikacji w chmurze. Wynikiem może być nieoptymalna wydajność, wysokie wydatki lub gorzej, ponieważ bazy danych NoSQL (nierelacyjne) mogą obsługiwać niektóre zadania wydajniej niż relacyjne bazy danych. Gdy klienci proszą nas o pomoc w rozwiązaniu krytycznego problemu z magazynem danych, często jest to spowodowane tym, że mają relacyjną bazę danych, w której jedna z opcji NoSQL działała lepiej. W takich sytuacjach klient byłby lepiej, gdyby zaimplementował rozwiązanie NoSQL przed wdrożeniem aplikacji w środowisku produkcyjnym.
Z drugiej strony błędem byłoby również założenie, że baza danych NoSQL może zrobić wszystko dobrze lub wystarczająco dobrze. Nie ma jednego najlepszego wyboru zarządzania danymi dla wszystkich zadań magazynu danych; różne rozwiązania do zarządzania danymi są zoptymalizowane pod kątem różnych zadań. Większość rzeczywistych aplikacji w chmurze ma różne wymagania dotyczące magazynu danych i często jest obsługiwana przez kombinację wielu rozwiązań do przechowywania danych.
Celem tego rozdziału jest zapewnienie szerszego poczucia opcji przechowywania danych dostępnych dla aplikacji w chmurze oraz podstawowych wskazówek dotyczących wybierania tych, które pasują do danego scenariusza. Przed opracowaniem aplikacji najlepiej jest znać dostępne opcje i zastanowić się nad ich mocnymi i słabymi stronami. Zmiana opcji przechowywania danych w aplikacji produkcyjnej może być niezwykle trudna, na przykład konieczność zmiany silnika odrzutowego podczas lotu samolotu.
Opcje magazynu danych na platformie Azure
Chmura ułatwia korzystanie z różnych magazynów danych relacyjnych i NoSQL. Poniżej przedstawiono niektóre platformy magazynu danych, których można używać na platformie Azure.
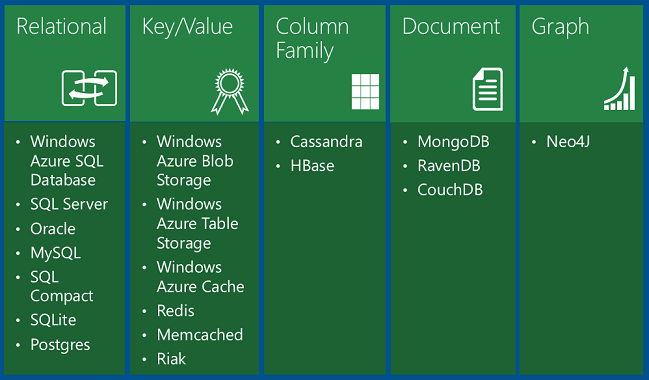
W tabeli przedstawiono cztery typy baz danych NoSQL:
Bazy danych klucz/wartość przechowują pojedynczy serializowany obiekt dla każdej wartości klucza. Są one przydatne do przechowywania dużych ilości danych, w których chcesz uzyskać jeden element dla danej wartości klucza i nie trzeba wykonywać zapytań na podstawie innych właściwości elementu.
Azure Blob Storage to baza danych klucz/wartość, która działa jak magazyn plików w chmurze, z wartościami kluczy odpowiadającymi nazwam folderów i plików. Pobierasz plik według jego folderu i nazwy pliku, a nie wyszukując wartości w zawartości pliku.
Usługa Azure Table Storage jest również bazą danych klucz/wartość. Każda wartość jest nazywana jednostką (podobną do wiersza identyfikowaną przez klucz partycji i klucz wiersza) i zawiera wiele właściwości (podobnie jak kolumny, ale nie wszystkie jednostki w tabeli muszą współdzielić te same kolumny). Wykonywanie zapytań dotyczących kolumn innych niż klucz jest niezwykle nieefektywne i należy unikać ich. Można na przykład przechowywać dane profilu użytkownika z jedną partycją przechowującą informacje o jednym użytkowniku. Możesz przechowywać dane, takie jak nazwa użytkownika, skrót hasła, data urodzenia itd., w oddzielnych właściwościach jednej jednostki lub w osobnych jednostkach w tej samej partycji. Nie chcesz jednak wykonywać zapytań dotyczących wszystkich użytkowników z danym zakresem dat urodzenia i nie można wykonać zapytania sprzężenia między tabelą profilu a inną tabelą. Usługa Table Storage jest bardziej skalowalna i tańsza niż relacyjna baza danych, ale nie umożliwia złożonych zapytań ani sprzężeń.
Bazy danych dokumentów to bazy danych klucz/wartość, w których wartości są dokumentami. "Dokument" w tym miejscu nie jest używany w sensie Word lub dokumentu programu Excel, ale oznacza kolekcję nazwanych pól i wartości, z których każdy może być dokumentem podrzędnym. Na przykład w tabeli historii zamówień dokument zamówienia może zawierać pola numer zamówienia, data zamówienia i klient; pole klienta może mieć pola nazwy i adresu. Baza danych koduje dane pól w formacie, takim jak XML, YAML, JSON lub BSON; lub może używać zwykłego tekstu. Jedną z funkcji ustawiających bazy danych dokumentów poza bazami danych klucz/wartość jest możliwość wykonywania zapytań dotyczących pól innych niż kluczowe i definiowania indeksów pomocniczych w celu zwiększenia wydajności wykonywania zapytań. Dzięki temu baza danych dokumentów jest bardziej odpowiednia dla aplikacji, które muszą pobierać dane na podstawie kryteriów bardziej złożonych niż wartość klucza dokumentu. Na przykład w bazie danych dokumentów historii zamówień sprzedaży można wykonywać zapytania dotyczące różnych pól, takich jak identyfikator produktu, identyfikator klienta, nazwa klienta i tak dalej. MongoDB to popularna baza danych dokumentów.
Bazy danych rodziny kolumn to magazyny danych klucz/wartość, które umożliwiają tworzenie struktury magazynu danych w kolekcjach powiązanych kolumn nazywanych rodzinami kolumn. Na przykład baza danych spisu może mieć jedną grupę kolumn dla nazwiska osoby (imię, środek, ostatni), jedną grupę adresu osoby i jedną grupę informacji o profilu osoby (DOB, płeć itp.). Baza danych może następnie przechowywać każdą rodzinę kolumn w oddzielnej partycji, zachowując jednocześnie wszystkie dane dla jednej osoby powiązanej z tym samym kluczem. Następnie można odczytać wszystkie informacje o profilu bez konieczności odczytywania wszystkich informacji o nazwie i adresie. Cassandra to popularna baza danych rodziny kolumn.
Grafowe bazy danych przechowują informacje jako kolekcję obiektów i relacji. Celem grafowej bazy danych jest umożliwienie aplikacji wydajnego wykonywania zapytań przechodzących przez sieć obiektów i relacji między nimi. Na przykład obiekty mogą być pracownikami w bazie danych zasobów ludzkich i warto ułatwić wykonywanie zapytań, takich jak "znajdowanie wszystkich pracowników, którzy bezpośrednio lub pośrednio pracują dla Scotta". Neo4j to popularna grafowa baza danych.
W porównaniu z relacyjnymi bazami danych opcje NoSQL oferują znacznie większą skalowalność i opłacalność przechowywania i analizowania danych bez struktury. Kompromis polega na tym, że nie zapewniają one rozbudowanej możliwości zapytań i niezawodnej integralności danych relacyjnych baz danych. Program NoSQL dobrze sprawdza się w przypadku danych dzienników usług IIS, co obejmuje dużą ilość bez potrzeby tworzenia zapytań sprzężenia. Program NoSQL nie działa tak dobrze w przypadku transakcji bankowych, co wymaga bezwzględnej integralności danych i wiąże się z wieloma relacjami z innymi danymi związanymi z kontem.
Istnieje również nowsza kategoria platformy bazy danych o nazwie NewSQL, która łączy skalowalność bazy danych NoSQL z możliwościami zapytań i integralnością transakcyjną relacyjnej bazy danych. Bazy danych NewSQL są przeznaczone do rozproszonego magazynu i przetwarzania zapytań, co często jest trudne do zaimplementowania w bazach danych "OldSQL". NuoDB to przykład bazy danych NewSQL, która może być używana na platformie Azure.
Usługi Hadoop i MapReduce
Duże ilości danych, które można przechowywać w bazach danych NoSQL, mogą być trudne do wydajnego analizowania w odpowiednim czasie. Aby to zrobić, można użyć platformy takiej jak Hadoop , która implementuje funkcję MapReduce . Zasadniczo proces MapReduce jest następujący:
- Ogranicz rozmiar danych, które należy przetworzyć, wybierając z magazynu danych tylko te dane, które faktycznie trzeba przeanalizować. Na przykład chcesz znać skład bazy użytkowników według roku urodzenia, więc wybierasz tylko lata urodzenia z magazynu danych profilu użytkownika.
- Podziel dane na części i wyślij je do różnych komputerów na potrzeby przetwarzania. Komputer A oblicza liczbę osób z datami 1950-1959, komputer B wykonuje 1960-1969 itd. Ta grupa komputerów jest nazywana klastrem hadoop.
- Po zakończeniu przetwarzania na części umieść wyniki każdej części z powrotem. Masz teraz stosunkowo krótką listę liczby osób dla każdego roku urodzenia, a zadanie obliczania wartości procentowych na tej ogólnej liście jest możliwe do zarządzania.
Na platformie Azure usługa HDInsight umożliwia przetwarzanie, analizowanie i uzyskiwanie nowych szczegółowych informacji na podstawie danych big data przy użyciu możliwości usługi Hadoop. Na przykład można go użyć do analizowania dzienników serwera internetowego:
Włącz rejestrowanie serwera internetowego na koncie magazynu. Spowoduje to skonfigurowanie platformy Azure do zapisywania dzienników w usłudze Blob Service dla każdego żądania HTTP do aplikacji. Usługa Blob Service jest zasadniczo magazynem plików w chmurze i dobrze integruje się z usługą HDInsight.

W miarę pobierania ruchu przez aplikację dzienniki usług IIS serwera internetowego są zapisywane w usłudze Blob Storage.
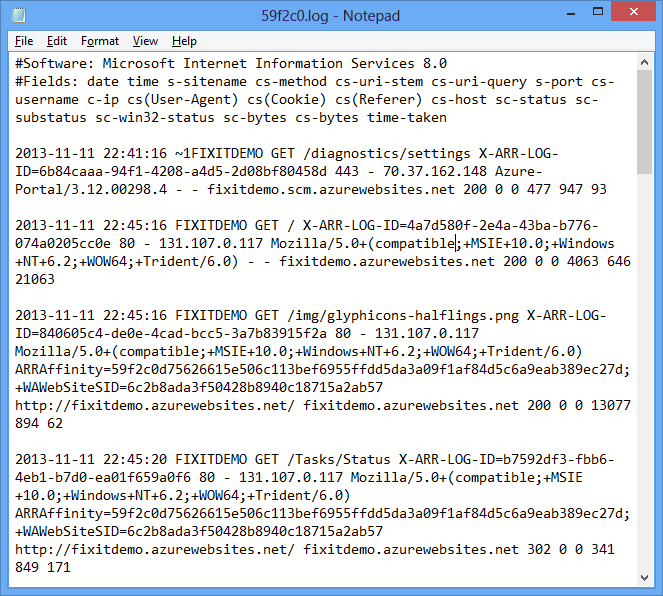
W portalu kliknij pozycję Nowe - usługi danych - HDInsight - — szybkie tworzenie i określ nazwę klastra usługi HDInsight, rozmiar klastra (liczbę węzłów danych klastra usługi HDInsight) oraz nazwę użytkownika i hasło klastra usługi HDInsight.
Teraz możesz skonfigurować zadania MapReduce w celu analizowania dzienników i uzyskiwania odpowiedzi na pytania, takie jak:
- O jakich porach dnia moja aplikacja uzyskuje największy lub najmniejszy ruch?
- Z jakich krajów pochodzi mój ruch?
- Jaki jest średni dochód sąsiedztwa obszarów, z których pochodzi mój ruch. (Istnieje publiczny zestaw danych, który daje dochód sąsiedztwa według adresu IP i można je dopasować do adresu IP w dziennikach serwera internetowego).
- Jak dochód z sąsiedztwa jest skorelowany z określonymi stronami lub produktami w witrynie?
Następnie możesz użyć odpowiedzi na pytania, takie jak te, aby kierować reklamy na podstawie prawdopodobieństwa, że klient będzie zainteresowany lub prawdopodobnie kupi określony produkt.
Jak wyjaśniono w rozdziale Automatyzowanie wszystkiego, większość funkcji, które można wykonać w portalu, może być zautomatyzowana i obejmuje konfigurowanie i wykonywanie zadań analizy usługi HDInsight. Typowy skrypt usługi HDInsight może zawierać następujące kroki:
- Aprowizuj klaster usługi HDInsight i połącz go z kontem magazynu na potrzeby danych wejściowych usługi Blob Storage.
- Przekaż pliki wykonywalne zadania MapReduce (pliki jar lub .exe) do klastra usługi HDInsight.
- Prześlij usługę MapReduce, która przechowuje dane wyjściowe w usłudze Blob Storage.
- Poczekaj na zakończenie zadania.
- Usuń klaster usługi HDInsight.
- Uzyskaj dostęp do danych wyjściowych z usługi Blob Storage.
Uruchamiając skrypt, który to robi, można zminimalizować czas aprowizacji klastra usługi HDInsight, co minimalizuje koszty.
Platforma jako usługa (PaaS) a infrastruktura jako usługa (IaaS)
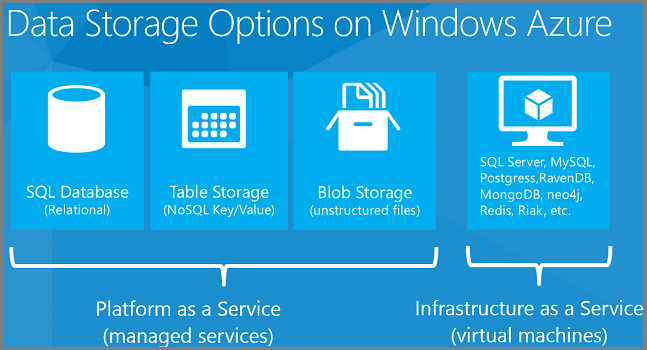
Wymienione wcześniej opcje magazynowania danych obejmują rozwiązania Typu platforma jako usługa (PaaS) i infrastruktury jako usługi (IaaS). Rozwiązanie PaaS oznacza, że zarządzamy infrastrukturą sprzętu i oprogramowania, a ty po prostu korzystasz z usługi. SQL Database to funkcja PaaS platformy Azure. Pytasz o bazy danych, a w tle platforma Azure konfiguruje i konfiguruje maszyny wirtualne oraz konfiguruje na nich bazy danych. Nie masz bezpośredniego dostępu do maszyn wirtualnych i nie musisz nimi zarządzać. Usługa IaaS oznacza, że konfigurujesz, konfigurujesz i zarządzasz maszynami wirtualnymi, które działają w naszej infrastrukturze centrum danych, i umieszczasz na nich dowolne elementy. Udostępniamy galerię wstępnie skonfigurowanych obrazów maszyn wirtualnych dla typowych konfiguracji maszyn wirtualnych. Można na przykład zainstalować wstępnie skonfigurowane obrazy maszyn wirtualnych dla systemu Windows Server 2008, Windows Server 2012, BizTalk Server, Oracle WebLogic Server, Oracle Database itp.
Rozwiązania danych PaaS, które oferuje platforma Azure, obejmują:
- Azure SQL Database (wcześniej znana jako Usługi SQL Azure). Relacyjna baza danych w chmurze oparta na SQL Server.
- Azure Table Storage. Baza danych NoSQL klucza/wartości.
- Azure Blob Storage. Magazyn plików w chmurze.
W przypadku usługi IaaS możesz uruchomić dowolne elementy, które można załadować na maszynę wirtualną, na przykład:
- Relacyjne bazy danych, takie jak SQL Server, Oracle, MySQL, SQL Compact, SQLite lub Postgres.
- Magazyny danych klucz/wartość, takie jak Memcached, Redis, Cassandra i Riak.
- Magazyny danych kolumn, takie jak HBase.
- Bazy danych dokumentów, takie jak MongoDB, RavenDB i CouchDB.
- Grafowe bazy danych, takie jak Neo4j.
Opcja IaaS zapewnia niemal nieograniczone opcje magazynowania danych, a wiele z nich jest szczególnie łatwych w użyciu, ponieważ można tworzyć maszyny wirtualne przy użyciu wstępnie skonfigurowanych obrazów. Na przykład w portalu zarządzania przejdź do Virtual Machines, kliknij kartę Obrazy, a następnie kliknij pozycję Przeglądaj magazyn maszyn wirtualnych.
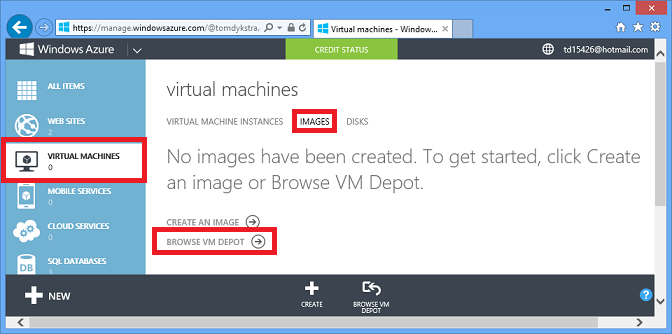
Następnie zostanie wyświetlona lista setek wstępnie skonfigurowanych obrazów maszyn wirtualnych i możesz utworzyć maszynę wirtualną na podstawie obrazu ze wstępnie zainstalowanym systemem zarządzania bazami danych, takimi jak MongoDB, Neo4J, Redis, Cassandra lub CouchDB:
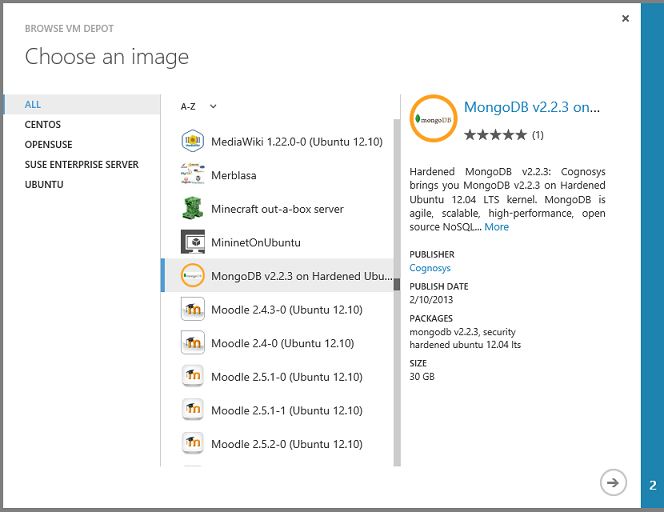
Platforma Azure ułatwia korzystanie z opcji magazynowania danych IaaS, ale oferty PaaS mają wiele zalet, które czynią je bardziej opłacalnymi i praktycznymi w wielu scenariuszach:
- Nie musisz tworzyć maszyn wirtualnych, wystarczy użyć portalu lub skryptu do skonfigurowania magazynu danych. Jeśli chcesz mieć 200 terabajtów magazynu danych, możesz po prostu kliknąć przycisk lub uruchomić polecenie, a w sekundach będzie gotowy do użycia.
- Nie musisz zarządzać maszynami wirtualnymi używanymi przez usługę ani stosować ich poprawek; Firma Microsoft robi to automatycznie.- Nie musisz martwić się o konfigurowanie infrastruktury pod kątem skalowania lub wysokiej dostępności; Firma Microsoft obsługuje to wszystko za Ciebie.
- Nie musisz kupować licencji; opłaty za korzystanie z licencji są uwzględniane w opłatach za korzystanie z usług.
- Płaci się wyłącznie za użyte zasoby.
Opcje magazynowania danych PaaS na platformie Azure obejmują oferty dostawców innych firm.
Wybieranie opcji magazynu danych
Żadne podejście nie jest odpowiednie dla wszystkich scenariuszy. Jeśli ktoś mówi, że ta technologia jest odpowiedzią, pierwszą rzeczą, którą należy zadać, jest "Co to jest pytanie?", ponieważ różne rozwiązania są zoptymalizowane pod kątem różnych rzeczy. Istnieją pewne zalety modelu relacyjnego; dlatego tak długo było. Ale istnieją również strony w dół do języka SQL, które można rozwiązać za pomocą rozwiązania NoSQL.
Często to, co widzimy najlepiej, to podejście komponacyjne, w którym używasz języka SQL i NoSQL w jednym rozwiązaniu. Nawet wtedy, gdy ludzie mówią, że korzystają z bazy danych NoSQL, jeśli przejdziesz do szczegółów tego, co robią, często okaże się, że używają kilku różnych struktur NoSQL: używają couchDB i Redis i Riak dla różnych rzeczy. Nawet Facebook, który intensywnie korzysta z noSQL, używa różnych struktur NoSQL w różnych częściach usługi. Elastyczność łączenia i dopasowywania podejścia do przechowywania danych jest jedną z rzeczy, które są miłe w chmurze, ponieważ łatwo jest używać wielu rozwiązań do obsługi danych i integrować je w jednej aplikacji.
Poniżej przedstawiono kilka pytań, które należy wziąć pod uwagę podczas wybierania podejścia:
| Semantyka danych | — Jaki jest podstawowy magazyn danych i semantyka dostępu do danych (czy przechowujesz dane relacyjne lub nieustrukturyzowane)? Dane bez struktury, takie jak pliki multimedialne, najlepiej pasują do magazynu obiektów blob; kolekcja powiązanych danych, takich jak produkty, zapasy, dostawcy, zamówienia klientów itp., najlepiej pasuje do relacyjnej bazy danych. |
|---|---|
| Obsługa zapytań | — Jak łatwo jest wykonywać zapytania o dane? — Jakie typy pytań można skutecznie zadać? Magazyny danych klucz/wartość są bardzo dobre w uzyskiwaniu pojedynczego wiersza z wartością klucza, ale nie tak dobre dla złożonych zapytań. W przypadku magazynu danych profilu użytkownika, w którym dane są zawsze wyświetlane dla jednego konkretnego użytkownika, magazyn danych klucz/wartość może działać dobrze; w przypadku katalogu produktów, w którym chcesz uzyskać różne grupy na podstawie różnych atrybutów produktu, relacyjna baza danych może działać lepiej. Bazy danych NoSQL mogą wydajnie przechowywać duże ilości danych, ale trzeba strukturę bazy danych wokół sposobu wykonywania zapytań dotyczących danych przez aplikację, co utrudnia wykonywanie zapytań ad hoc. Za pomocą relacyjnej bazy danych można utworzyć niemal dowolny rodzaj zapytania. |
| Projekcja funkcjonalna | — Czy pytania, agregacje itp., mogą być wykonywane po stronie serwera? Jeśli uruchamiam polecenie SELECT COUNT(*) z tabeli w języku SQL, bardzo wydajnie wykona całą pracę na serwerze i zwróci szukaną liczbę. Jeśli chcę wykonać to samo obliczenie z magazynu danych NoSQL, które nie obsługuje agregacji, jest to nieefektywne "niezwiązane zapytanie" i prawdopodobnie upłynął limit czasu. Nawet jeśli zapytanie powiedzie się, muszę pobrać wszystkie dane z serwera do klienta i policzyć wiersze na kliencie. — Jakich języków lub typów wyrażeń można używać? W przypadku relacyjnej bazy danych mogę użyć języka SQL. W przypadku niektórych baz danych NoSQL, takich jak Azure Table Storage, będę używać usługi OData, a wszystko, co mogę zrobić, to filtrować klucz podstawowy i pobierać projekcje (wybierz podzbiór dostępnych pól). |
| Łatwość skalowalności | — Jak często i ile danych będą musiały być skalowane? — Czy platforma natywnie implementuje skalowanie w poziomie? - Jak łatwo jest dodać/usunąć pojemność (rozmiar i przepływność)? Relacyjne bazy danych i tabele nie są automatycznie partycjonowane, aby były skalowalne, więc trudno je skalować poza pewne ograniczenia. Magazyny danych NoSQL, takie jak Azure Table Storage, są z natury podzielone na partycje i prawie nie ma limitu dodawania partycji. Możesz łatwo skalować usługę Table Storage do 200 terabajtów, ale maksymalny rozmiar bazy danych dla usługi Azure SQL Database wynosi 500 gigabajtów. Dane relacyjne można skalować, partycjonując je na wiele baz danych, ale skonfigurowanie aplikacji do obsługi tego modelu wymaga dużej ilości pracy programistycznej. |
| Instrumentacja i łatwość zarządzania | - Jak łatwo jest instrumentować, monitorować i zarządzać platformą? Konieczne będzie informowanie o kondycji i wydajności magazynu danych, więc musisz wiedzieć z góry, jakie metryki zapewnia platforma za darmo i co musisz opracować samodzielnie. |
| Operacje | — Jak łatwo jest wdrożyć i uruchomić platformę na platformie Azure? Paas? Iaas? Linux? Usługi Table Storage i SQL Database można łatwo skonfigurować na platformie Azure. Platformy, które nie są wbudowanymi rozwiązaniami PaaS platformy Azure, wymagają większego nakładu pracy. |
| Obsługa interfejsu API | - Czy interfejs API jest dostępny, który ułatwia pracę z platformą? W przypadku usługi Azure Table Service istnieje zestaw SDK z interfejsem API platformy .NET, który obsługuje asynchroniczny model programowania platformy .NET 4.5. Jeśli piszesz aplikację platformy .NET, znacznie łatwiej będzie napisać i przetestować kod dla usługi Azure Table Service w porównaniu z inną platformą magazynu danych kolumn klucz/wartość, która nie ma interfejsu API lub mniej kompleksowego. |
| Integralność transakcyjna i spójność danych | - Czy ważne jest, aby platforma obsługiwała transakcje w celu zagwarantowania spójności danych? Śledzenie wysyłanych zbiorczych wiadomości e-mail, wydajności i niskich kosztów magazynowania danych może być ważniejsze niż automatyczna obsługa transakcji lub więzów integralności na platformie danych, dzięki czemu usługa Azure Table Service jest dobrym wyborem. W przypadku śledzenia sald kont bankowych lub zamówień zakupu platforma relacyjnej bazy danych zapewniająca silne gwarancje transakcyjne byłaby lepszym wyborem. |
| Ciągłość działalności biznesowej | - Jak łatwo jest tworzyć kopie zapasowe, przywracać i odzyskiwanie po awarii? Wcześniej lub później dane produkcyjne zostaną uszkodzone i będzie potrzebna funkcja cofania. Relacyjne bazy danych często mają bardziej szczegółowe możliwości przywracania, takie jak możliwość przywracania do punktu w czasie. Zrozumienie, jakie funkcje przywracania są dostępne na każdej rozważanym platformie, jest ważnym czynnikiem do rozważenia. |
| Koszty | — Jeśli więcej niż jedna platforma może obsługiwać obciążenie danych, jak można porównać koszty? Jeśli na przykład używasz ASP.NET Identity, możesz przechowywać dane profilu użytkownika w usłudze Azure Table Service lub Azure SQL Database. Jeśli nie potrzebujesz zaawansowanych funkcji zapytań SQL Database, możesz wybrać tabele platformy Azure częściowo, ponieważ kosztuje znacznie mniej dla danej ilości miejsca do magazynowania. |
Ogólnie zalecamy zapoznanie się z odpowiedzią na pytania w każdej z tych kategorii przed wybraniem rozwiązań do przechowywania danych.
Ponadto obciążenie może mieć określone wymagania, które niektóre platformy mogą obsługiwać lepiej niż inne. Na przykład:
- Czy aplikacja wymaga możliwości inspekcji?
- Jakie są wymagania dotyczące długowieczności danych — czy potrzebujesz zautomatyzowanych możliwości archiwizacji lub przeczyszczania?
- Czy masz wyspecjalizowane potrzeby w zakresie zabezpieczeń? Na przykład dane obejmują dane osobowe (dane osobowe), ale musisz mieć możliwość upewnienia się, że dane osobowe są wykluczone z wyników zapytania.
- Jeśli masz dane, których nie można przechowywać w chmurze ze względów prawnych lub technologicznych, może być potrzebna platforma magazynu danych w chmurze, która ułatwia integrację z magazynem lokalnym.
Pokaz — używanie SQL Database na platformie Azure
Aplikacja Fix It używa relacyjnej bazy danych do przechowywania zadań. Skrypt tworzenia środowiska Windows PowerShell pokazany w rozdziale Automate Everything (Automatyzowanie wszystkiego) tworzy dwa wystąpienia SQL Database. Te karty można wyświetlić w portalu, klikając kartę Bazy danych SQL .

Można również łatwo tworzyć bazy danych przy użyciu portalu.
Kliknij pozycję Nowe — Usługi -- danych SQL Database -- Quick Utwórz, wprowadź nazwę bazy danych, wybierz serwer, który już masz na koncie lub utwórz nowy, a następnie kliknij przycisk Utwórz SQL Database.
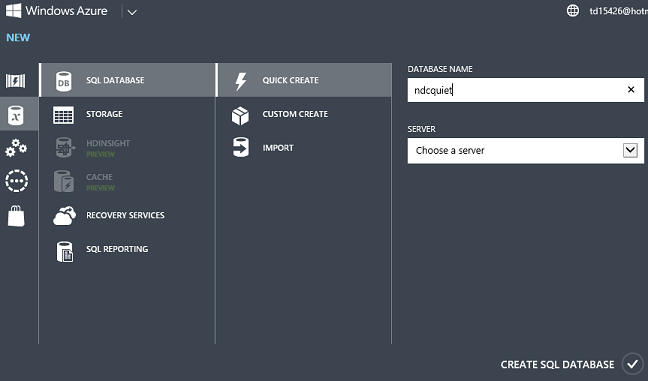
Zaczekaj kilka sekund i masz bazę danych na platformie Azure gotową do użycia.
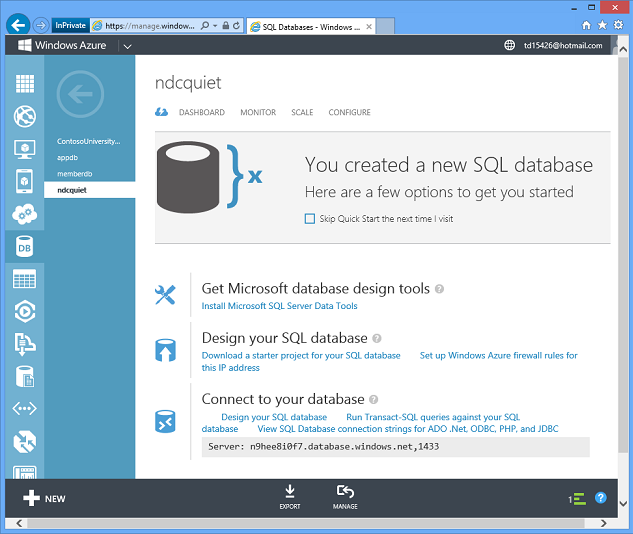
Platforma Azure wykonuje w ciągu kilku sekund, co może potrwać dzień lub tydzień lub dłużej w środowisku lokalnym. Ponieważ można równie łatwo tworzyć bazy danych w skryscie lub przy użyciu interfejsu API zarządzania, można dynamicznie skalować w poziomie, rozkładając dane w wielu bazach danych, tak długo, jak aplikacja została zaprogramowana.
Jest to przykład naszego modelu platformy jako usługi. Nie musisz zarządzać serwerami, robimy to. Nie musisz martwić się o kopie zapasowe, robimy to. Działa w wysokiej dostępności — dane w bazie danych są replikowane automatycznie na trzech serwerach. Jeśli maszyna przestanie działać, automatycznie przejdą w tryb failover i nie utracisz żadnych danych. Serwer jest regularnie poprawiany, nie musisz się tym martwić.
Kliknij przycisk i uzyskasz dokładne potrzebne parametry połączenia i możesz natychmiast rozpocząć korzystanie z nowej bazy danych.
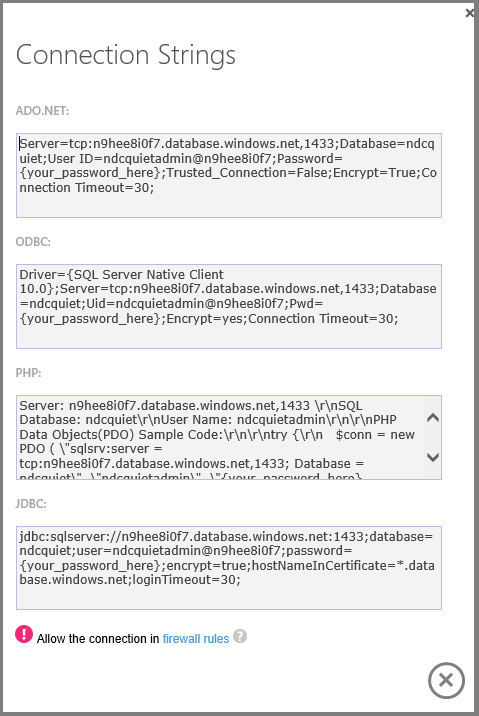
Na pulpicie nawigacyjnym jest wyświetlana historia połączeń i ilość używanego miejsca do magazynowania.
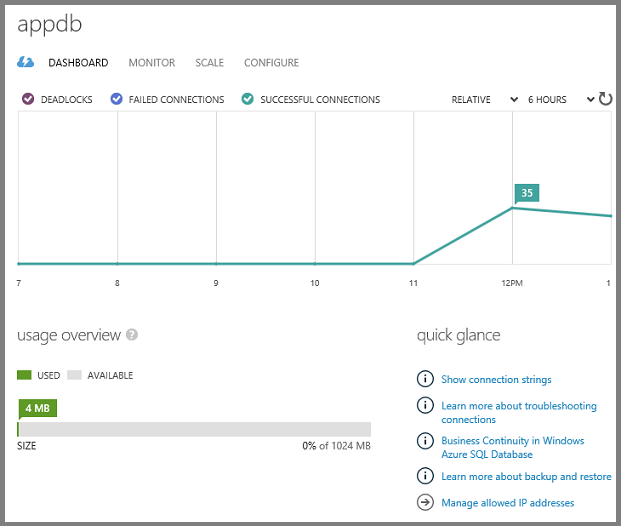
Bazy danych można zarządzać w portalu lub przy użyciu narzędzi SQL Server, które już znasz, w tym SQL Server Management Studio (SSMS) i narzędzi programu Visual Studio SQL Server Eksplorator obiektów (SSOX) i Eksploratora serwera.
Kolejną fajną rzeczą jest model cen. Możesz rozpocząć programowanie z bezpłatną bazą danych o pojemności 20 MB, a produkcyjna baza danych rozpoczyna się od około 5 USD miesięcznie. Płacisz tylko za ilość danych przechowywanych w bazie danych, a nie za maksymalną pojemność. Nie musisz kupować licencji.
SQL Database można łatwo skalować. W przypadku aplikacji Fix It baza danych tworzona w skrycie automatyzacji jest ograniczona do 1 koncertu. Jeśli chcesz skalować go do 150 koncertów, możesz po prostu przejść do portalu i zmienić to ustawienie lub wykonać polecenie interfejsu API REST, a w sekundach masz 150 gig bazy danych, do której można wdrożyć dane.
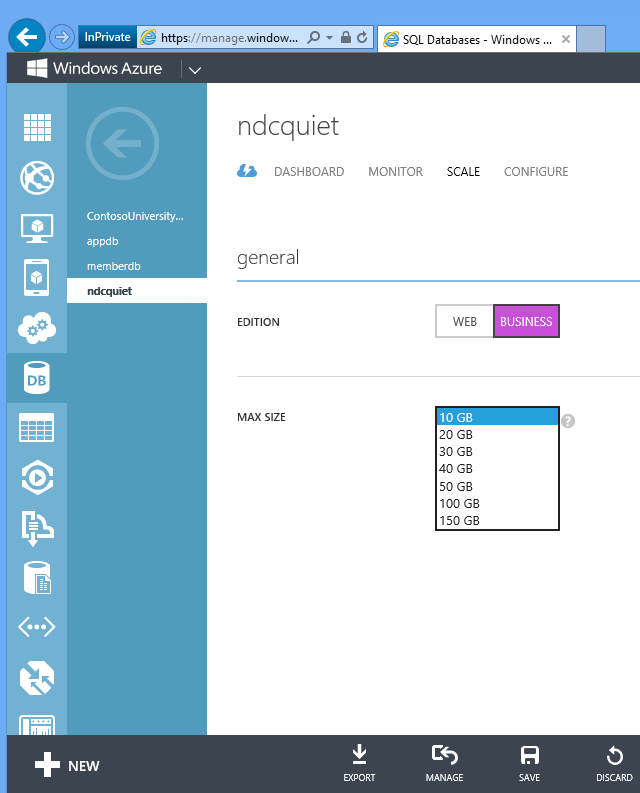
Jest to moc chmury do szybkiego i łatwego tworzenia infrastruktury i natychmiastowego korzystania z niej.
Aplikacja Fix It używa dwóch baz danych SQL, jednej dla członkostwa (uwierzytelniania i autoryzacji) i jednego dla danych, a to wszystko, co musisz zrobić, aby go aprowizować i skalować. Wcześniej pokazano, jak aprowizować bazy danych za pomocą skryptów Windows PowerShell, a teraz zobaczyliśmy również, jak łatwo jest to zrobić w portalu.
Program Entity Framework a bezpośredni dostęp do bazy danych przy użyciu ADO.NET
Aplikacja Fix It uzyskuje dostęp do tych baz danych przy użyciu programu Entity Framework, zalecanego przez firmę Microsoft (mapera relacyjnego obiektu) dla aplikacji platformy .NET. OrM to doskonałe narzędzie, które ułatwia produktywność deweloperów, ale produktywność wiąże się z kosztem obniżonej wydajności w niektórych scenariuszach. W rzeczywistej aplikacji w chmurze nie będziesz wybierać między korzystaniem z platformy EF lub bezpośrednio przy użyciu ADO.NET — użyjesz obu tych opcji. W większości przypadków pisania kodu, który współpracuje z bazą danych, uzyskanie maksymalnej wydajności nie jest krytyczne i można skorzystać z uproszczonego kodowania i testowania, które otrzymujesz z platformy Entity Framework. W sytuacjach, w których obciążenie ef spowodowałoby niedopuszczalną wydajność, można napisać i wykonać własne zapytania przy użyciu ADO.NET, najlepiej przez wywołanie procedur składowanych.
Niezależnie od metody używanej do uzyskiwania dostępu do bazy danych, chcesz zminimalizować "czattiness" jak najwięcej. Innymi słowy, jeśli możesz uzyskać wszystkie potrzebne dane w jednym większym zestawie wyników zapytania, a nie dziesiątkach lub setkach mniejszych, zwykle najlepiej. Jeśli na przykład musisz wyświetlić listę uczniów i kursy, w których się zarejestrowali, zwykle lepiej jest uzyskać wszystkie dane w jednym zapytaniu sprzężenia, a nie otrzymywać uczniów w jednym zapytaniu i wykonywać oddzielne zapytania dla kursów każdego ucznia.
Bazy danych SQL i platforma Entity Framework w aplikacji Fix It
W aplikacji FixItContext Fix It klasa, która pochodzi z klasy Entity Framework DbContext , identyfikuje bazę danych i określa tabele w bazie danych. Kontekst określa zestaw jednostek (tabela) dla zadań, a kod przechodzi do kontekstu nazwy parametrów połączenia. Ta nazwa odwołuje się do parametrów połączenia zdefiniowanych w pliku Web.config.
public class MyFixItContext : DbContext
{
public MyFixItContext()
: base("name=appdb")
{
}
public DbSet<MyFixIt.Persistence.FixItTask> FixItTasks { get; set; }
}
Parametry połączenia w pliku Web.config nosi nazwę appdb (tutaj wskazuje lokalną bazę danych deweloperów):
<connectionStrings>
<add name="DefaultConnection" connectionString="Data Source=(LocalDb)\v11.0;Initial Catalog=aspnet-MyFixIt-20130604091232_4;Integrated Security=True" providerName="System.Data.SqlClient" />
<add name="appdb" connectionString="Data Source=(localdb)\v11.0; Initial Catalog=MyFixItContext-20130604091609_11;Integrated Security=True; MultipleActiveResultSets=True" providerName="System.Data.SqlClient" />
</connectionStrings>
Struktura Entity Framework tworzy tabelę FixItTasks na podstawie właściwości uwzględnionych w FixItTask klasie jednostek. Jest to prosta klasa POCO (zwykły stary obiekt CLR), co oznacza, że nie dziedziczy ani nie ma żadnych zależności od platformy Entity Framework. Jednak program Entity Framework wie, jak utworzyć tabelę na podstawie niej i wykonać operacje CRUD (create-read-update-delete).
public class FixItTask
{
public int FixItTaskId { get; set; }
public string CreatedBy { get; set; }
[Required]
public string Owner { get; set; }
[Required]
public string Title { get; set; }
public string Notes { get; set; }
public string PhotoUrl { get; set; }
public bool IsDone { get; set; }
}
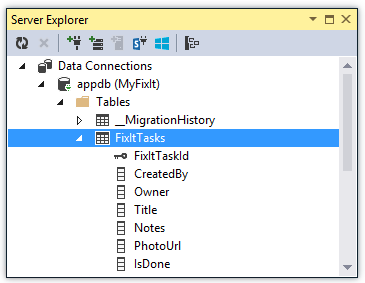
Aplikacja Fix It zawiera interfejs repozytorium używany do operacji CRUD pracujących z magazynem danych.
public interface IFixItTaskRepository
{
Task<List<FixItTask>> FindOpenTasksByOwnerAsync(string userName);
Task<List<FixItTask>> FindTasksByCreatorAsync(string userName);
Task<MyFixIt.Persistence.FixItTask> FindTaskByIdAsync(int id);
Task CreateAsync(FixItTask taskToAdd);
Task UpdateAsync(FixItTask taskToSave);
Task DeleteAsync(int id);
}
Zwróć uwagę, że metody repozytorium są asynchroniczne, więc cały dostęp do danych można wykonać w całkowicie asynchroniczny sposób.
Implementacja repozytorium wywołuje metody asynchroniczne platformy Entity Framework do pracy z danymi, w tym zapytania LINQ, a także operacje wstawiania, aktualizowania i usuwania. Oto przykład kodu do wyszukania zadania Fix It.
public async Task<FixItTask> FindTaskByIdAsync(int id)
{
FixItTask fixItTask = null;
Stopwatch timespan = Stopwatch.StartNew();
try
{
fixItTask = await db.FixItTasks.FindAsync(id);
timespan.Stop();
log.TraceApi("SQL Database", "FixItTaskRepository.FindTaskByIdAsync", timespan.Elapsed, "id={0}", id);
}
catch(Exception e)
{
log.Error(e, "Error in FixItTaskRepository.FindTaskByIdAsynx(id={0})", id);
}
return fixItTask;
}
Zauważysz również, że w tym miejscu znajduje się kod rejestrowania chronometrażu i błędów. Przyjrzymy się temu w dalszej części rozdziału Monitorowanie i telemetria.
Wybieranie SQL Database (PaaS) i SQL Server na maszynie wirtualnej (IaaS) na platformie Azure
Dobrą rzeczą w SQL Server i Azure SQL Database jest to, że podstawowy model programowania dla obu z nich jest identyczny. Większość tych samych umiejętności można używać w obu środowiskach. Można nawet użyć bazy danych SQL Server podczas tworzenia i wystąpienia SQL Database w chmurze, co jest sposobem skonfigurowania aplikacji Fix It.
Alternatywnie możesz uruchomić te same SQL Server w chmurze, która jest uruchamiana lokalnie, instalując ją na maszynach wirtualnych IaaS. W przypadku niektórych starszych aplikacji uruchomienie SQL Server na maszynie wirtualnej może być lepszym rozwiązaniem. Ponieważ baza danych SQL Server działa na dedykowanej maszynie wirtualnej, ma ona więcej zasobów niż baza danych SQL Database uruchomiona na serwerze udostępnionym. Oznacza to, że baza danych SQL Server może być większa i nadal działa dobrze. Ogólnie rzecz biorąc, mniejszy rozmiar bazy danych i rozmiar tabeli, tym lepiej działa przypadek użycia dla SQL Database (PaaS).
Poniżej przedstawiono kilka wskazówek dotyczących wybierania między dwoma modelami.
| Usługa Azure SQL Database (PaaS) | SQL Server na maszynie wirtualnej (IaaS) |
|---|---|
| Pros — nie musisz tworzyć maszyn wirtualnych ani zarządzać nimi, aktualizować ani aktualizować ani poprawiać systemu operacyjnego ani programu SQL; Platforma Azure to robi dla Ciebie. — Wbudowana wysoka dostępność z umową SLA na poziomie bazy danych. — Niski całkowity koszt posiadania (TCO), ponieważ płacisz tylko za to, czego używasz (bez wymaganej licencji). — Dobra do obsługi dużej liczby mniejszych baz danych (<=500 GB każdy). — Dynamiczne tworzenie nowych baz danych w celu umożliwienia skalowania w poziomie. | Pros — funkcja zgodna z lokalnymi SQL Server. — Może zaimplementować SQL Server wysoką dostępność za pośrednictwem funkcji AlwaysOn na 2+ maszynach wirtualnych z umową SLA na poziomie maszyny wirtualnej. — Masz pełną kontrolę nad sposobem zarządzania programem SQL. — Możesz ponownie korzystać z licencji SQL, które już posiadasz, lub płacić za godzinę za jeden. — Dobra do obsługi mniejszej, ale większej (1 TB+) baz danych. |
| Wady — niektóre luki funkcji w porównaniu z lokalnymi SQL Server (brak integracji CLR, TDE, obsługa kompresji, SQL Server Reporting Services itp.) — limit rozmiaru bazy danych 500 GB. | Wady — Aktualizacje/poprawki (system operacyjny i SQL) są twoimi obowiązkami — Tworzenie i zarządzanie bazami danych to Twoja odpowiedzialność — operacje we/wy na sekundę dysku (operacje wejściowe/wyjściowe) ograniczone do około 8000 (za pośrednictwem 16 dysków danych). |
Jeśli chcesz użyć SQL Server na maszynie wirtualnej, możesz użyć własnej licencji SQL Server lub zapłacić za jedną godzinę. Na przykład w portalu lub za pośrednictwem interfejsu API REST można utworzyć nową maszynę wirtualną przy użyciu obrazu SQL Server.

Podczas tworzenia maszyny wirtualnej z obrazem SQL Server proporcjonalnie oceniamy koszt licencji SQL Server według godziny na podstawie użycia maszyny wirtualnej. Jeśli masz projekt, który będzie uruchamiany tylko przez kilka miesięcy, jest tańszy do zapłaty o godzinę. Jeśli uważasz, że projekt będzie trwał przez lata, tańszy jest zakup licencji tak, jak zwykle robisz.
Podsumowanie
Przetwarzanie w chmurze ułatwia mieszanie i dopasowywanie metod przechowywania danych do najlepszych potrzeb aplikacji. Jeśli tworzysz nową aplikację, zastanów się dokładnie nad pytaniami wymienionymi w tym miejscu, aby wybrać podejścia, które będą nadal działać dobrze, gdy aplikacja się rozwija. W następnym rozdziale wyjaśniono niektóre strategie partycjonowania, których można użyć do łączenia wielu metod przechowywania danych.
Zasoby
Więcej informacji zawierają poniższe zasoby.
Wybieranie platformy bazy danych:
- Dostęp do danych dla rozwiązań Highly-Scalable: używanie funkcji SQL, NoSQL i Polyglot Persistence. Książka elektroniczna firmy Microsoft Patterns and Practices, która szczegółowo zagłębia się w różne rodzaje magazynów danych dostępnych dla aplikacji w chmurze.
- Wzorce i praktyki firmy Microsoft — wskazówki dotyczące platformy Azure. Zobacz Podstawy spójności danych, Wskazówki dotyczące replikacji danych i synchronizacji, wzorzec tabeli indeksów, zmaterializowany wzorzec widoku.
- BASE: Alternatywa kwasu. Artykuł dotyczący kompromisów między spójnością danych a skalowalnością.
- Siedem baz danych w ciągu siedmiu tygodni: Przewodnik po nowoczesnych bazach danych i ruchu NoSQL. Książka Erica Redmonda i Jima R. Wilsona. Zdecydowanie zalecane do wprowadzenia się do zakresu dostępnych obecnie platform magazynowania danych.
Wybór między SQL Server a SQL Database:
- Wersja zapoznawcza Premium — wskazówki dotyczące SQL Database. Wprowadzenie do usługi SQL Database Premium i wskazówki dotyczące tego, kiedy należy wybrać ją w wersjach SQL Database Web and Business.
- Wytyczne i ograniczenia (Azure SQL Database). Strona portalu zawierająca linki do dokumentacji dotyczącej ograniczeń SQL Database, w tym tej, która koncentruje się na SQL Server funkcjach, które SQL Database nie są obsługiwane.
- SQL Server w usłudze Azure Virtual Machines. Strona portalu zawierająca linki do dokumentacji dotyczącej uruchamiania SQL Server na platformie Azure.
- Scott Guthrie wyjaśnia bazy danych SQL Database na platformie Azure. 6-minutowe wprowadzenie wideo do SQL Database przez Scotta Guthrie'a.
- Wzorce aplikacji i strategie programowania dla SQL Server w usłudze Azure Virtual Machines.
Używanie platformy Entity Framework i SQL Database w aplikacji internetowej ASP.NET
- Wprowadzenie z programem EF 6 przy użyciu wzorca MVC 5. Dziewięcioczęściowa seria samouczków, która przeprowadzi Cię przez proces tworzenia aplikacji MVC korzystającej z platformy EF i wdrażania bazy danych na platformie Azure i SQL Database.
- ASP.NET wdrażanie w Internecie przy użyciu programu Visual Studio. Dwunastoczęściowa seria samouczków, która bardziej szczegółowo opisuje sposób wdrażania bazy danych przy użyciu programu EF Code First.
- Wdróż aplikację Secure ASP.NET MVC 5 z członkostwem, OAuth i SQL Database w witrynie internetowej platformy Azure. Samouczek krok po kroku przedstawiający tworzenie aplikacji internetowej korzystającej z uwierzytelniania, przechowywanie tabel aplikacji w bazie danych członkostwa, modyfikowanie schematu bazy danych i wdrażanie aplikacji na platformie Azure.
- ASP.NET mapa zawartości dostępu do danych. Linki do zasobów do pracy z platformą EF i SQL Database.
Korzystanie z bazy danych MongoDB na platformie Azure:
- Usługa MongoDB Atlas na platformie Azure. Strona portalu zawierająca dokumentację dotyczącą uruchamiania usługi MongoDB Atlas na platformie Azure.
- Utwórz witrynę internetową platformy Azure, która łączy się z bazą danych MongoDB uruchomioną na maszynie wirtualnej na platformie Azure. Samouczek krok po kroku przedstawiający sposób używania bazy danych MongoDB w aplikacji internetowej ASP.NET.
HDInsight (Hadoop na platformie Azure):
- HDInsight. Dokumentacja portalu do usługi HDInsight w witrynie internetowej platformy Azure .
- Hadoop i HDInsight: dane big data na platformie Azure. Artykuł w witrynie MSDN Magazine autorstwa Bruno Terkaly'ego i Ricardo Villalobos, który przedstawia platformę Hadoop na platformie Azure.
- Wzorce i praktyki firmy Microsoft — wskazówki dotyczące platformy Azure. Zobacz Wzorzec MapReduce.
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla