Używanie narzędzia DISKSPD do testowania wydajności magazynu pod obciążeniem
Dotyczy: Azure Stack HCI, wersje 22H2 i 21H2; Windows Server 2022, Windows Server 2019
Ten temat zawiera wskazówki dotyczące używania narzędzia DISKSPD do testowania wydajności magazynu obciążenia. Masz już skonfigurowany i gotowy klaster usługi Azure Stack HCI. Świetnie, ale jak sprawdzić obiecywane metryki wydajności dotyczące opóźnienia, przepływności czy liczby operacji we/wy na sekundę? W takiej sytuacji warto skorzystać z narzędzia DISKSPD. Po przeczytaniu tego tematu dowiesz się, jak uruchomić narzędzie DISKSPD, zrozumieć podzbiór parametrów, interpretować dane wyjściowe i uzyskać ogólną wiedzę na temat zmiennych wpływających na wydajność magazynu obciążenia.
Co to jest DISKSPD?
DISKSPD to narzędzie wiersza polecenia służące do generowania operacji we/wy na potrzeby mikro benchmarkingu. Świetnie, więc co oznaczają wszystkie te terminy? Każdy, kto konfiguruje klaster usługi Azure Stack HCI lub serwer fizyczny, ma powód. Może to być skonfigurowanie środowiska hostingu internetowego lub uruchamianie pulpitów wirtualnych dla pracowników. Niezależnie od rzeczywistego przypadku użycia, prawdopodobnie chcesz zasymulować test przed wdrożeniem rzeczywistej aplikacji. Jednak testowanie aplikacji w rzeczywistym scenariuszu jest często trudne — jest to miejsce, w którym jest dostępna funkcja DISKSPD.
DISKSPD to narzędzie, które można dostosować, aby tworzyć własne syntetyczne obciążenia i testować aplikację przed wdrożeniem. Fajną rzeczą w narzędziu jest to, że zapewnia swobodę konfigurowania i dostosowywania parametrów w celu utworzenia konkretnego scenariusza, który przypomina rzeczywiste obciążenie. DISKSPD może dać wgląd w to, co system jest w stanie przed wdrożeniem. Na jej podstawowym poziomie DISKSPD po prostu wystawia kilka operacji odczytu i zapisu.
Teraz wiesz, co to jest DISKSPD, ale kiedy należy go użyć? DISKSPD ma trudny czas emulacji złożonych obciążeń. Jednak narzędzie DISKSPD jest doskonałe, gdy obciążenie nie jest ściśle zbliżone do pojedynczego wątkowego kopiowania plików i potrzebujesz prostego narzędzia, które generuje akceptowalne wyniki punktu odniesienia.
Szybki start: instalowanie i uruchamianie narzędzia DISKSPD
Bez dalszego ado, zacznijmy:
Na komputerze zarządzania otwórz program PowerShell jako administrator, aby nawiązać połączenie z komputerem docelowym, który chcesz przetestować przy użyciu narzędzia DISKSPD, a następnie wpisz następujące polecenie i naciśnij klawisz Enter.
Enter-PSSession -ComputerName <TARGET_COMPUTER_NAME>W tym przykładzie uruchamiamy maszynę wirtualną o nazwie "node1".
Aby pobrać narzędzie DISKSPD, wpisz następujące polecenia i naciśnij klawisz Enter:
$client = new-object System.Net.WebClient$client.DownloadFile("https://github.com/microsoft/diskspd/releases/download/v2.0.21a/DiskSpd.zip","<ENTER_PATH>\DiskSpd-2.0.21a.zip")Użyj następującego polecenia, aby rozpakować pobrany plik:
Expand-Archive -LiteralPath <ENTERPATH>\DiskSpd-2.0.21a.zip -DestinationPath C:\DISKSPDZmień katalog na katalog DISKSPD i znajdź odpowiedni plik wykonywalny dla systemu operacyjnego Windows, na którym jest uruchomiony komputer docelowy.
W tym przykładzie używamy wersji amd64.
Uwaga
Narzędzie DISKSPD można również pobrać bezpośrednio z repozytorium GitHub zawierającego kod open source oraz stronę typu wiki ze szczegółami wszystkich parametrów i specyfikacji. W repozytorium w obszarze Wydania wybierz link, aby automatycznie pobrać plik ZIP.
W pliku ZIP zobaczysz trzy podfoldery: amd64 (systemy 64-bitowe), x86 (systemy 32-bitowe) i ARM64 (systemy ARM). Te opcje umożliwiają uruchamianie narzędzia w każdej wersji klienta lub serwera z systemem Windows.

Uruchom narzędzie DISKSPD za pomocą następującego polecenia programu PowerShell. Zastąp wszystkie elementy wewnątrz nawiasów kwadratowych, w tym nawiasy kwadratowe odpowiednimi ustawieniami.
.\[INSERT_DISKSPD_PATH] [INSERT_SET_OF_PARAMETERS] [INSERT_CSV_PATH_FOR_TEST_FILE] > [INSERT_OUTPUT_FILE.txt]Oto przykładowe polecenie, które można uruchomić:
.\diskspd -t2 -o32 -b4k -r4k -w0 -d120 -Sh -D -L -c5G C:\ClusterStorage\test01\targetfile\IO.dat > test01.txtUwaga
Jeśli nie masz pliku testowego, użyj parametru -c , aby go utworzyć. Jeśli używasz tego parametru, pamiętaj o dołączeniu nazwy pliku testowego podczas definiowania ścieżki. Na przykład: [INSERT_CSV_PATH_FOR_TEST_FILE] = C:\ClusterStorage\CSV01\IO.dat. W przykładowym poleceniu IO.dat jest nazwą pliku testowego, a test01.txt jest nazwą pliku wyjściowego DISKSPD.

Określanie parametrów klucza
Cóż, to było proste? Niestety, jest do tego więcej. Rozpakujmy to, co zrobiliśmy. Po pierwsze, istnieją różne parametry, które można majstrować i może uzyskać konkretne. Użyliśmy jednak następującego zestawu parametrów punktu odniesienia:
Uwaga
W parametrach DISKSPD jest rozróżniana wielkość liter.
-t2: Wskazuje liczbę wątków na plik docelowy/testowy. Ta liczba jest często oparta na liczbie rdzeni procesora CPU. W tym przypadku dwa wątki zostały użyte do przeciążenia wszystkich rdzeni procesora CPU.
-o32: Wskazuje to liczbę zaległych żądań we/wy na obiekt docelowy na wątek. Jest to również znane jako głębokość kolejki, a w tym przypadku 32 zostało użytych do obciążenia procesora CPU.
-b4K: wskazuje rozmiar bloku w bajtach, KiB, MiB lub GiB. W tym przypadku rozmiar bloku 4K został użyty do symulowania losowego testu we/wy.
-r4K: wskazuje losowy we/wy wyrównany do określonego rozmiaru w bajtach, KiB, MiB, Gib lub blokach (zastępuje parametr -s ). Typowy rozmiar bajtu 4K był używany do prawidłowego dopasowania do rozmiaru bloku.
-w0: Określa procent operacji, które są żądaniami zapisu (-w0 jest odpowiednikiem 100% odczytu). W tym przypadku do celów prostego testu użyto 0% operacji zapisu.
-d120: Określa czas trwania testu, a nie w tym ochładzanie lub rozgrzewkę. Wartość domyślna to 10 sekund, ale zalecamy użycie co najmniej 60 sekund dla dowolnego poważnego obciążenia. W tym przypadku użyto 120 sekund, aby zminimalizować wszelkie wartości odstające.
-Suw: wyłącza buforowanie zapisu oprogramowania i sprzętu (równoważne -Sh).
-D: przechwytuje statystyki liczby operacji we/wy na sekundę, takie jak odchylenie standardowe, w interwałach milisekund (na wątek, na cel).
-L: Mierzy statystyki opóźnień.
-c5g: Ustawia rozmiar pliku próbki używany w teście. Można go ustawić w bajtach, KiB, MiB, GiB lub blokach. W tym przypadku użyto pliku docelowego o rozmiarze 5 GB.
Pełną listę parametrów można znaleźć w repozytorium GitHub.
Omówienie środowiska
Wydajność w dużym stopniu zależy od środowiska. Co to jest nasze środowisko? Nasza specyfikacja obejmuje klaster rozwiązania Azure Stack HCI z pulą magazynów i Bezpośrednie miejsca do magazynowania (S2D). Mówiąc dokładniej, istnieje pięć maszyn wirtualnych: DC, node1, node2, node3 i węzeł zarządzania. Sam klaster jest klastrem z trzema węzłami ze strukturą odporności dublowanej trzystopniowo. W związku z tym przechowywane są trzy kopie danych. Każdy "węzeł" w klastrze jest maszyną wirtualną Standard_B2ms z maksymalnym limitem liczby operacji we/wy na sekundę wynoszącym 1920. W każdym węźle istnieją cztery dyski SSD W warstwie Premium P30 z maksymalnym limitem liczby operacji we/wy na sekundę wynoszącym 5000. Na koniec każdy dysk SSD ma 1 TB pamięci.
Plik testowy jest generowany w ujednoliconej przestrzeni nazw udostępnianej przez klaster udostępniony wolumin (CSV) (C:\ClusteredStorage) do korzystania z całej puli dysków.
Uwaga
Przykładowe środowisko nie ma funkcji Hyper-V ani zagnieżdżonej struktury wirtualizacji.
Jak zobaczysz, jest całkowicie możliwe niezależne osiągnięcie limitu liczby operacji we/wy na sekundę lub przepustowości na maszynie wirtualnej lub dysku. Dlatego ważne jest, aby zrozumieć rozmiar i typ dysku maszyny wirtualnej, ponieważ oba mają maksymalny limit liczby operacji we/wy na sekundę i limit przepustowości. Ta wiedza pomaga zlokalizować wąskie gardła i zrozumieć wyniki wydajności. Aby dowiedzieć się więcej o rozmiarze, który może być odpowiedni dla obciążenia, zobacz następujące zasoby:
Informacje o danych wyjściowych
Mając wiedzę na temat parametrów i środowiska, możesz interpretować dane wyjściowe. Najpierw celem wcześniejszego testu było maksymalne użycie liczby operacji we/wy na sekundę bez względu na opóźnienie. Dzięki temu możesz wizualnie sprawdzić, czy osiągniesz limit liczby operacji we/wy na sekundę na platformie Azure. Jeśli chcesz graficznie zwizualizować łączną liczbę operacji we/wy na sekundę, użyj Windows Admin Center lub Menedżera zadań.
Na poniższym diagramie przedstawiono wygląd procesu DISKSPD w naszym przykładowym środowisku. Przedstawia on przykład 1 operacji zapisu MiB z węzła niekordynanego. Trójkierunkowa struktura odporności wraz z operacją z węzła niedyskrypcyjnego prowadzi do dwóch przeskoków sieciowych, co zmniejsza wydajność. Jeśli zastanawiasz się, jaki jest węzeł koordynatora, nie martw się! Poznasz ją w sekcji Rzeczy do rozważenia . Czerwone kwadraty reprezentują maszynę wirtualną i napędzają wąskie gardła.

Teraz, gdy masz wiedzę wizualną, przeanalizujmy cztery główne sekcje danych wyjściowych pliku .txt:
Ustawienia danych wejściowych
W tej sekcji opisano uruchomione polecenie, parametry wejściowe i dodatkowe szczegóły dotyczące przebiegu testu.

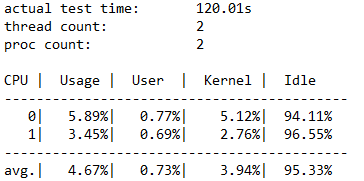
Szczegóły użycia procesora CPU
W tej sekcji przedstawiono informacje, takie jak czas testu, liczba wątków, liczba dostępnych procesorów oraz średnie wykorzystanie każdego rdzenia procesora CPU podczas testu. W tym przypadku istnieją dwa rdzenie procesora CPU, które średnio około 4,67% użycia.
Łączna liczba operacji we/wy
Ta sekcja zawiera trzy podsekcje. Pierwsza sekcja wyróżnia ogólne dane wydajności, w tym operacje odczytu i zapisu. W drugiej i trzeciej sekcji podzielono operacje odczytu i zapisu na oddzielne kategorie.
W tym przykładzie widać, że łączna liczba operacji we/wy była 234408 w ciągu 120 sekund. W związku z tym operacje we/wy na sekundę = 234408 /120 = 1953,30. Średnie opóźnienie wynosiło 32,763 milisekund, a przepływność wynosiła 7,63 milisekund. Z wcześniejszych informacji wiemy, że 1953.30 operacji we/wy na sekundę zbliża się do ograniczenia liczby operacji we/wy na sekundę 1920 dla naszej maszyny wirtualnej Standard_B2ms. Nie wierzcie? Jeśli ponownie uruchomisz ten test przy użyciu różnych parametrów, takich jak zwiększenie głębokości kolejki, okaże się, że wyniki są nadal ograniczone do tej liczby.
W ostatnich trzech kolumnach przedstawiono odchylenie standardowe liczby operacji we/wy na sekundę na poziomie 17,72 (od -D parametru), odchylenie standardowe opóźnienia na poziomie 20,994 milisekund (z parametru -L) i ścieżkę pliku.

Z wyników można szybko określić, że konfiguracja klastra jest straszna. Widać, że osiągnęło ograniczenie maszyny wirtualnej 1920 przed ograniczeniem dysków SSD 5000. Jeśli dysk SSD jest ograniczony, a nie maszyna wirtualna, można było skorzystać z maksymalnie 20000 operacji we/wy na sekundę (4 dyski * 5000), łącząc plik testowy na wielu dyskach.
W końcu musisz zdecydować, jakie wartości są dopuszczalne dla określonego obciążenia. Na poniższej ilustracji przedstawiono kilka ważnych relacji, które pomogą Ci rozważyć kompromisy:

Druga relacja na rysunku jest ważna i czasami jest nazywana Prawem Little's. Prawo wprowadza ideę, że istnieją trzy cechy, które rządzą zachowaniem procesów i że wystarczy zmienić jeden, aby wpłynąć na pozostałe dwa, a tym samym cały proces. I tak, jeśli jesteś niezadowolony z wydajności systemu, masz trzy wymiary swobody wpływania na niego. Little's Law określa, że w naszym przykładzie liczba operacji we/wy na sekundę to "przepływność" (operacje wyjściowe wejściowe na sekundę), opóźnienie to "czas kolejki", a głębokość kolejki to "spis".
Analiza percentylu opóźnienia
Ta ostatnia sekcja zawiera szczegółowe informacje o opóźnieniach percentylu na typ operacji wydajności magazynu z wartości minimalnej do maksymalnej.
Ta sekcja jest ważna, ponieważ określa "jakość" liczby operacji we/wy na sekundę. Pokazuje, ile operacji we/wy było w stanie osiągnąć pewną wartość opóźnienia. Decydujesz o akceptowalnym opóźnieniu dla tego percentylu.
Co więcej, "dziewiątki" odnoszą się do liczby dziewiątek. Na przykład wartość "3-nines" jest równoważna 99. percentylowi. Liczba dziewiątek uwidacznia liczbę operacji we/wy uruchomionych w tym percentylu. W końcu osiągniesz punkt, w którym nie ma już sensu poważnie traktować wartości opóźnień. W tym przypadku można zobaczyć, że wartości opóźnienia pozostają stałe po "4-dziewiątkach". W tym momencie wartość opóźnienia jest oparta na tylko jednej operacji we/wy poza operacjami 234408.






Zagadnienia do rozważenia
Teraz, po rozpoczęciu korzystania z narzędzia DISKSPD, należy wziąć pod uwagę kilka kwestii, aby uzyskać rzeczywiste wyniki testów. Obejmują one szczególną uwagę na ustawione parametry, kondycję miejsca do magazynowania i zmienne, własność CSV oraz różnicę między dyskami DISKSPD i kopiowaniem plików.
DISKSPD a real-world
Sztuczny test DISKSPD daje stosunkowo porównywalne wyniki dla rzeczywistego obciążenia. Należy jednak zwrócić szczególną uwagę na ustawione parametry i to, czy są one zgodne z rzeczywistym scenariuszem. Ważne jest, aby zrozumieć, że syntetyczne obciążenia nigdy nie będą idealnie reprezentować rzeczywiste obciążenie aplikacji podczas wdrażania.
Przygotowanie
Przed uruchomieniem testu DISKSPD istnieje kilka zalecanych akcji. Obejmują one weryfikowanie kondycji miejsca do magazynowania, sprawdzanie użycia zasobów, aby inny program nie zakłócał testu i przygotowywał menedżera wydajności, jeśli chcesz zebrać dodatkowe dane. Jednak ze względu na to, że celem tego tematu jest szybkie uruchomienie narzędzia DISKSPD, nie zawiera on szczegółowych informacji o tych akcjach. Aby dowiedzieć się więcej, zobacz Testowanie wydajności Miejsca do magazynowania przy użyciu syntetycznych obciążeń w systemie Windows Server.
Zmienne wpływające na wydajność
Wydajność magazynu to delikatna rzecz. Oznacza to, że istnieje wiele zmiennych, które mogą mieć wpływ na wydajność. I tak, prawdopodobnie może wystąpić liczba, która jest niezgodna z oczekiwaniami. Poniżej przedstawiono niektóre zmienne, które wpływają na wydajność, chociaż nie jest to kompleksowa lista:
- Przepustowość sieci
- Wybór odporności
- Konfiguracja dysku magazynu: NVME, SSD, HDD
- Bufor we/wy
- Pamięć podręczna
- Konfiguracja macierzy RAID
- Przeskoki sieciowe
- Prędkość wrzeciona dysku twardego
Własność csv
Węzeł jest znany jako właściciel woluminu lub węzeł koordynatora (węzeł niebędący koordynatorem to węzeł, który nie jest właścicielem określonego woluminu). Każdy wolumin standardowy jest przypisany do węzła, a inne węzły mogą uzyskiwać dostęp do tego woluminu standardowego za pośrednictwem przeskoków sieciowych, co powoduje spowolnienie wydajności (większe opóźnienie).
Podobnie udostępniony wolumin klastra (CSV) ma również "właściciela". Jednak wolumin CSV jest "dynamiczny" w sensie, że będzie przeskoczyć i zmienić własność za każdym razem, gdy ponownie uruchomisz system (RDP). W związku z tym ważne jest, aby upewnić się, że narzędzie DISKSPD jest uruchamiane z węzła koordynatora, który jest właścicielem pliku CSV. W przeciwnym razie może być konieczne ręczne zmianę własności woluminu CSV.
Aby potwierdzić własność csv:
Sprawdź własność, uruchamiając następujące polecenie programu PowerShell:
Get-ClusterSharedVolumeJeśli własność woluminu CSV jest nieprawidłowa (na przykład jesteś właścicielem węzła Node1, ale węzeł Node2 jest właścicielem woluminu CSV), przenieś plik CSV do poprawnego węzła, uruchamiając następujące polecenie programu PowerShell:
Get-ClusterSharedVolume <INSERT_CSV_NAME> | Move-ClusterSharedVolume <INSERT _NODE_NAME>
Kopiowanie plików a DISKSPD
Niektórzy uważają, że mogą "przetestować wydajność magazynu", kopiując i wklejając gigantyczny plik i mierząc, jak długo trwa ten proces. Głównym powodem tego podejścia jest najbardziej prawdopodobne, ponieważ jest to proste i szybkie. Pomysł nie jest niewłaściwy w sensie, że testuje określone obciążenie, ale trudno jest kategoryzować tę metodę jako "testowanie wydajności magazynu".
Jeśli rzeczywistym celem jest przetestowanie wydajności kopiowania plików, może to być doskonały powód, aby użyć tej metody. Jeśli jednak twoim celem jest mierzenie wydajności magazynu, zalecamy, aby nie używać tej metody. Proces kopiowania plików można traktować jako inny zestaw "parametrów" (takich jak kolejka, równoległość itd.), który jest specyficzny dla usług plików.
Poniższe krótkie podsumowanie wyjaśnia, dlaczego używanie kopii plików do mierzenia wydajności magazynu może nie dostarczyć wyników, których szukasz:
Kopie plików mogą nie być zoptymalizowane, Istnieją dwa poziomy równoległości, jeden wewnętrzny i drugi zewnętrzny. Wewnętrznie, jeśli kopia pliku jest kierowana do zdalnego obiektu docelowego, aparat CopyFileEx stosuje pewne równoległe działanie. Zewnętrznie istnieją różne sposoby wywoływania aparatu CopyFileEx. Na przykład kopie z Eksplorator plików są pojedyncze wątkowe, ale Robocopy jest wielowątkowa. Z tych powodów ważne jest, aby zrozumieć, czy implikacje testu są tym, czego szukasz.
Każda kopia ma dwie strony. Podczas kopiowania i wklejania pliku może być używany dwa dyski: dysk źródłowy i dysk docelowy. Jeśli jedna z nich jest wolniejsza niż druga, zasadniczo mierzysz wydajność wolniejszego dysku. Istnieją inne przypadki, w których komunikacja między źródłem, miejscem docelowym i aparatem kopiowania może mieć wpływ na wydajność w unikatowy sposób.
Aby dowiedzieć się więcej, zobacz Używanie kopiowania plików do mierzenia wydajności magazynu.
Eksperymenty i typowe obciążenia
Ta sekcja zawiera kilka innych przykładów, eksperymentów i typów obciążeń.
Potwierdzanie węzła koordynacji
Jak wspomniano wcześniej, jeśli obecnie testowana maszyna wirtualna nie jest właścicielem woluminu CSV, zobaczysz spadek wydajności (liczba operacji we/wy na sekundę, przepływność i opóźnienie) w przeciwieństwie do testowania, gdy węzeł jest właścicielem woluminu CSV. Jest to spowodowane tym, że za każdym razem, gdy wykonujesz operację we/wy, system wykonuje przeskok sieciowy do węzła koordynacji w celu wykonania tej operacji.
W przypadku sytuacji z dublowaniem trzystopniowym operacje zapisu zawsze powodują przeskok sieciowy, ponieważ musi przechowywać dane na wszystkich dyskach w trzech węzłach. W związku z tym operacje zapisu tworzą przeskok sieciowy niezależnie od tego. Jeśli jednak używasz innej struktury odporności, może to ulec zmianie.
Oto przykład:
- Uruchamianie w węźle lokalnym: .\DiskSpd-2.0.21a\amd64\diskspd.exe -t4 -o32 -b4k -r4k -w0 -Sh -D -L C:\ClusterStorage\test01\targetfile\IO.dat
- Uruchomione w nielokalny węźle: .\DiskSpd-2.0.21a\amd64\diskspd.exe -t4 -o32 -b4k -r4k -w0 -Sh -D -L C:\ClusterStorage\test01\targetfile\IO.dat
W tym przykładzie widać wyraźnie w wynikach poniższej ilustracji, że opóźnienie zmniejszyło się, zwiększono liczbę operacji we/wy na sekundę i zwiększono przepływność, gdy węzeł koordynacji jest właścicielem woluminu CSV.

Obciążenie przetwarzania transakcji online (OLTP)
Zapytania obciążenia przetwarzania transakcyjnego online (OLTP) (Update, Insert, Delete) koncentrują się na zadaniach zorientowanych na transakcje. W porównaniu z przetwarzaniem analitycznym online (OLAP) przetwarzanie OLTP jest zależne od opóźnienia magazynu. Ponieważ każda operacja ma niewielkie problemy z operacjami we/wy, zależy ci na tym, ile operacji na sekundę można utrzymać.
Możesz zaprojektować test obciążenia OLTP, aby skoncentrować się na losowej, małej wydajności we/wy. W przypadku tych testów skoncentruj się na tym, jak daleko można wypchnąć przepływność przy zachowaniu akceptowalnych opóźnień.
Podstawowy wybór projektu dla tego testu obciążenia powinien obejmować co najmniej:
- Rozmiar bloku o rozmiarze 8 KB => przypomina rozmiar strony, który SQL Server używany dla plików danych
- 70% odczyt, 30% zapis => przypomina typowe zachowanie OLTP
Obciążenie przetwarzania analitycznego online (OLAP)
Obciążenia OLAP koncentrują się na pobieraniu i analizie danych, umożliwiając użytkownikom wykonywanie złożonych zapytań w celu wyodrębniania danych wielowymiarowych. W przeciwieństwie do olTP te obciążenia nie są wrażliwe na opóźnienia magazynu. Podkreślają one kolejkowanie wielu operacji bez dbania o przepustowość. W związku z tym obciążenia OLAP często powodują dłuższy czas przetwarzania.
Możesz zaprojektować test obciążenia OLAP, aby skoncentrować się na sekwencyjnej, dużej wydajności operacji we/wy. W przypadku tych testów skoncentruj się na ilości przetwarzanych danych na sekundę, a nie na liczbę operacji we/wy na sekundę. Wymagania dotyczące opóźnień są również mniej ważne, ale jest to subiektywne.
Podstawowy wybór projektu dla tego testu obciążenia powinien obejmować co najmniej:
Rozmiar bloku 512 KB => przypomina rozmiar operacji we/wy, gdy SQL Server ładuje partię 64 stron danych na potrzeby skanowania tabeli przy użyciu techniki odczytu z wyprzedzeniem.
1 wątek na plik => obecnie należy ograniczyć testowanie do jednego wątku na plik, ponieważ problemy mogą występować w środowisku DISKSPD podczas testowania wielu wątków sekwencyjnych. Jeśli używasz więcej niż jednego wątku, powiedzmy dwa, a parametr -s , wątki zaczną niedeterministycznie wystawiać operacje we/wy nawzajem w tej samej lokalizacji. Wynika to z tego, że każda z nich śledzi własne przesunięcie sekwencyjne.
Istnieją dwa "rozwiązania", które umożliwiają rozwiązanie tego problemu:
Pierwsze rozwiązanie obejmuje użycie parametru -si . W przypadku tego parametru oba wątki współdzielą jednosprzężone przesunięcie, tak aby wątki wspólnie wystawiały pojedynczy sekwencyjny wzorzec dostępu do pliku docelowego. Dzięki temu nikt w pliku nie może być uruchamiany więcej niż raz. Jednak ponieważ nadal ścigają się nawzajem, aby wydać operację we/wy do kolejki, operacje mogą pojawić się poza kolejnością.
To rozwiązanie działa dobrze, jeśli jeden wątek stanie się ograniczony. Możesz chcieć zaangażować drugi wątek na drugim rdzeniu procesora CPU, aby zapewnić więcej operacji we/wy magazynu do systemu procesora CPU, aby jeszcze bardziej go usycać.
Drugie rozwiązanie obejmuje użycie przesunięcia> -T<. Dzięki temu można określić rozmiar przesunięcia (odstęp między we/wy) między operacjami we/wy wykonywanymi na tym samym pliku docelowym przez różne wątki. Na przykład wątki zwykle zaczynają się od przesunięcia 0, ale ta specyfikacja pozwala na odległość dwóch wątków, aby nie nakładały się na siebie nawzajem. W każdym środowisku wielowątkowym wątki będą prawdopodobnie znajdować się w różnych częściach docelowego działania i jest to sposób symulowania tej sytuacji.
Następne kroki
Aby uzyskać więcej informacji i szczegółowe przykłady dotyczące optymalizacji ustawień odporności, zobacz również:
Opinia
Dostępne już wkrótce: W 2024 r. będziemy stopniowo wycofywać zgłoszenia z serwisu GitHub jako mechanizm przesyłania opinii na temat zawartości i zastępować go nowym systemem opinii. Aby uzyskać więcej informacji, sprawdź: https://aka.ms/ContentUserFeedback.
Prześlij i wyświetl opinię dla